 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Exact information propagation through fully-connected feed forward neural networks
Jun 17, 2018
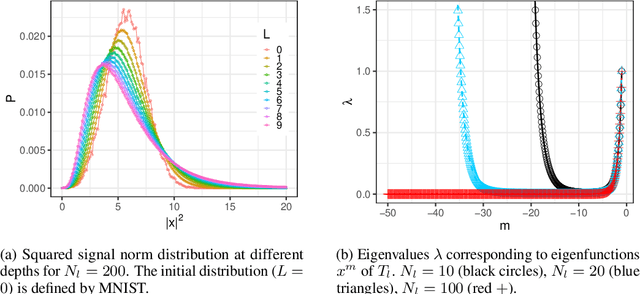
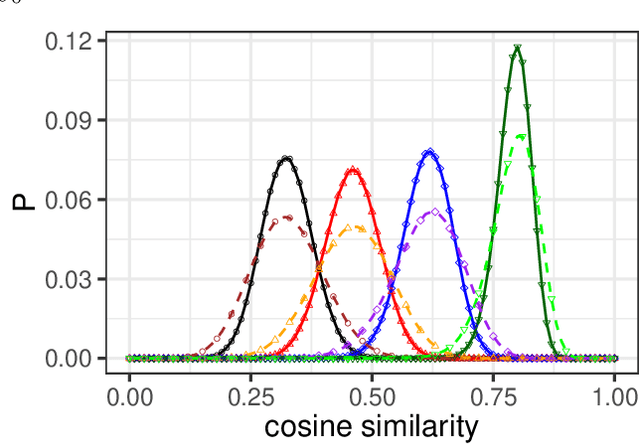
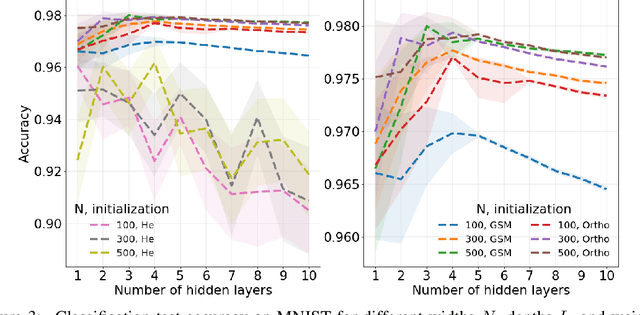
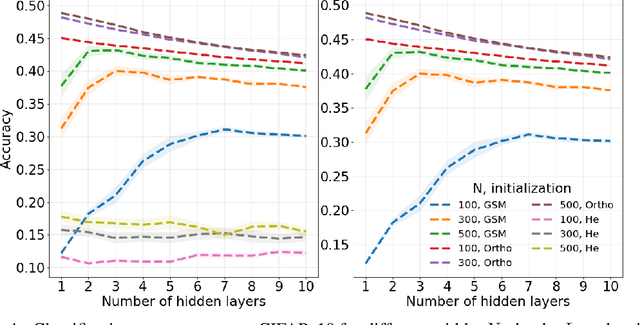
Neural network ensembles at initialisation give rise to the trainability and training speed of neural networks and thus support parameter choices at initialisation. These insights rely so far on mean field approximations that assume infinite layer width and study average squared signals. Thus, information about the full output distribution gets lost. Therefore, we derive the output distribution exactly (without mean field assumptions), for fully-connected networks with Gaussian weights and biases. The layer-wise transition of the signal distribution is guided by a linear integral operator, whose kernel has a closed form solution in case of rectified linear units for nonlinear activations. This enables us to analyze some of its spectral properties, for instance, the shape of the stationary distribution for different parameter choices and the dynamics of signal propagation.
Macro-Average: Rare Types Are Important Too
Apr 12, 2021
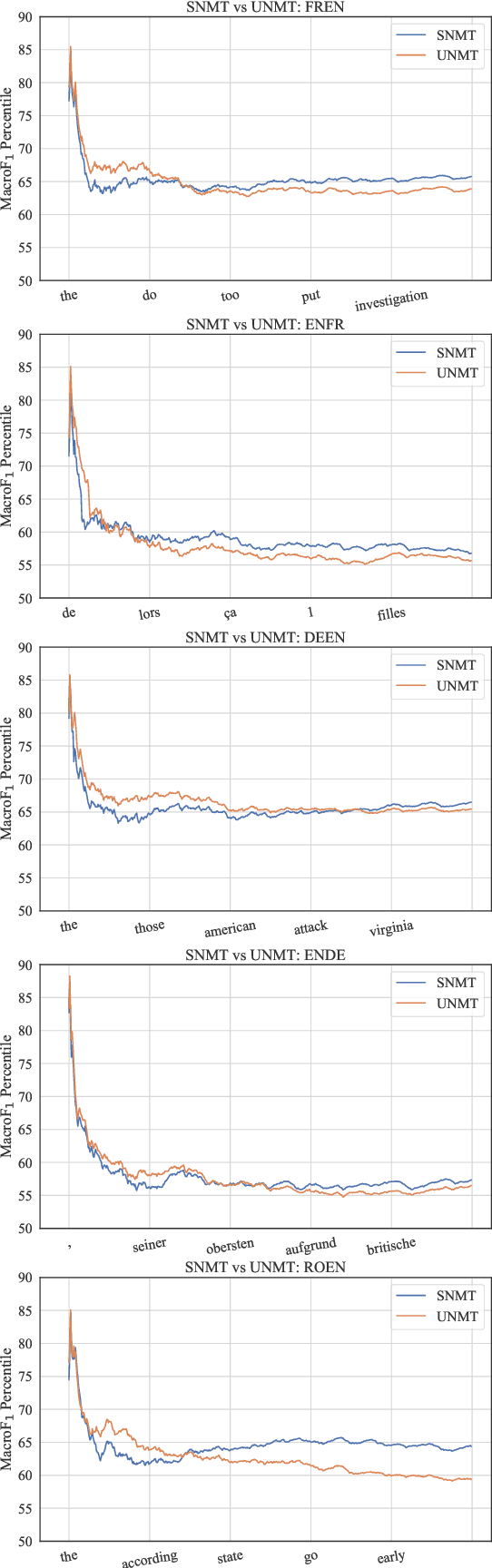
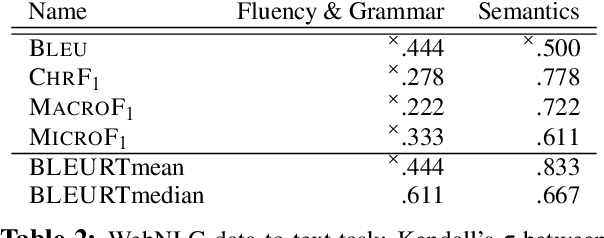
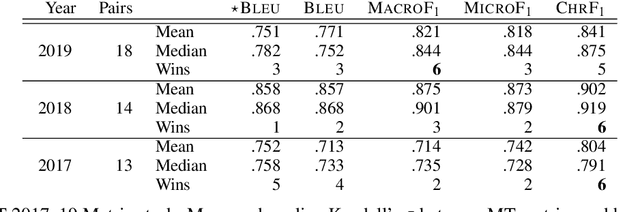
While traditional corpus-level evaluation metrics for machine translation (MT) correlate well with fluency, they struggle to reflect adequacy. Model-based MT metrics trained on segment-level human judgments have emerged as an attractive replacement due to strong correlation results. These models, however, require potentially expensive re-training for new domains and languages. Furthermore, their decisions are inherently non-transparent and appear to reflect unwelcome biases. We explore the simple type-based classifier metric, MacroF1, and study its applicability to MT evaluation. We find that MacroF1 is competitive on direct assessment, and outperforms others in indicating downstream cross-lingual information retrieval task performance. Further, we show that MacroF1 can be used to effectively compare supervised and unsupervised neural machine translation, and reveal significant qualitative differences in the methods' outputs.
A Spatio-temporal Attention-based Model for Infant Movement Assessment from Videos
May 20, 2021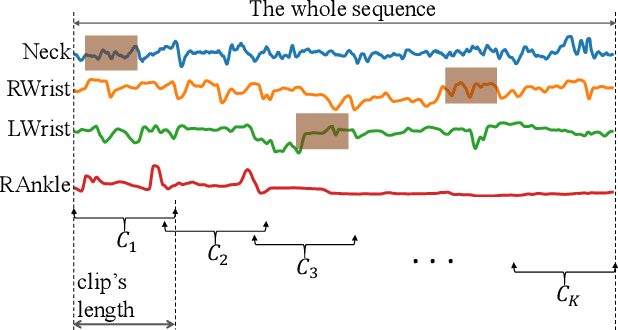
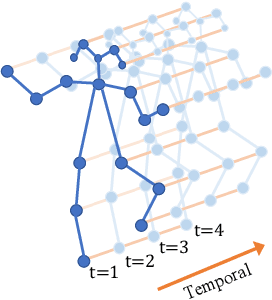

The absence or abnormality of fidgety movements of joints or limbs is strongly indicative of cerebral palsy in infants. Developing computer-based methods for assessing infant movements in videos is pivotal for improved cerebral palsy screening. Most existing methods use appearance-based features and are thus sensitive to strong but irrelevant signals caused by background clutter or a moving camera. Moreover, these features are computed over the whole frame, thus they measure gross whole body movements rather than specific joint/limb motion. Addressing these challenges, we develop and validate a new method for fidgety movement assessment from consumer-grade videos using human poses extracted from short clips. Human poses capture only relevant motion profiles of joints and limbs and are thus free from irrelevant appearance artifacts. The dynamics and coordination between joints are modeled using spatio-temporal graph convolutional networks. Frames and body parts that contain discriminative information about fidgety movements are selected through a spatio-temporal attention mechanism. We validate the proposed model on the cerebral palsy screening task using a real-life consumer-grade video dataset collected at an Australian hospital through the Cerebral Palsy Alliance, Australia. Our experiments show that the proposed method achieves the ROC-AUC score of 81.87%, significantly outperforming existing competing methods with better interpretability.
Framing Unpacked: A Semi-Supervised Interpretable Multi-View Model of Media Frames
Apr 22, 2021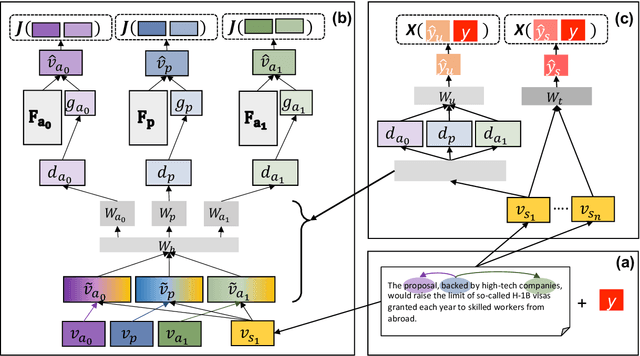
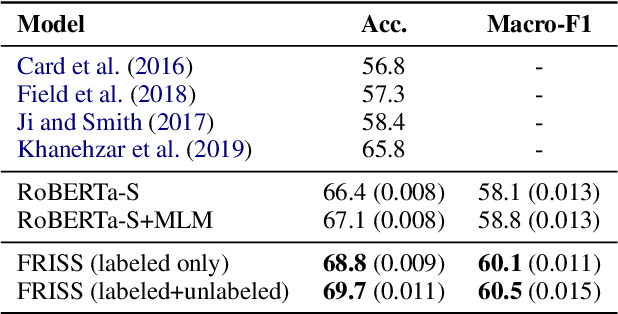
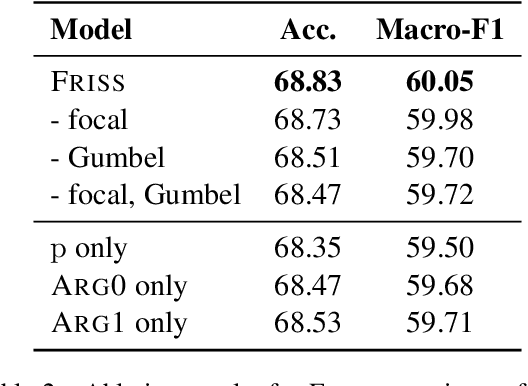
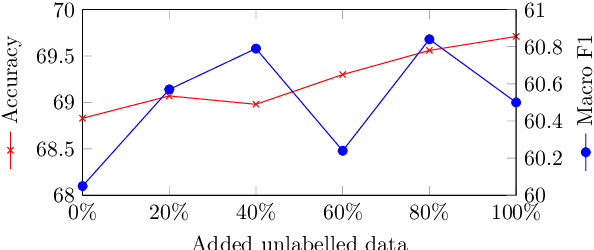
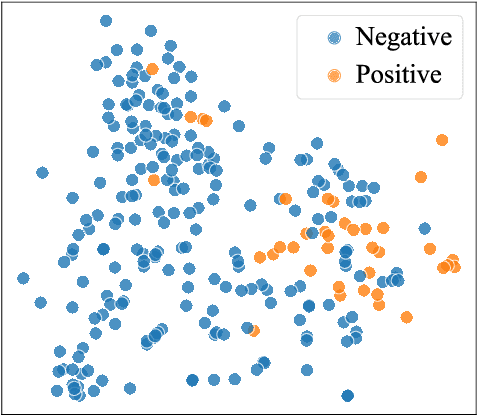
Understanding how news media frame political issues is important due to its impact on public attitudes, yet hard to automate. Computational approaches have largely focused on classifying the frame of a full news article while framing signals are often subtle and local. Furthermore, automatic news analysis is a sensitive domain, and existing classifiers lack transparency in their predictions. This paper addresses both issues with a novel semi-supervised model, which jointly learns to embed local information about the events and related actors in a news article through an auto-encoding framework, and to leverage this signal for document-level frame classification. Our experiments show that: our model outperforms previous models of frame prediction; we can further improve performance with unlabeled training data leveraging the semi-supervised nature of our model; and the learnt event and actor embeddings intuitively corroborate the document-level predictions, providing a nuanced and interpretable article frame representation.
Image Classification with Rejection using Contextual Information
Sep 03, 2015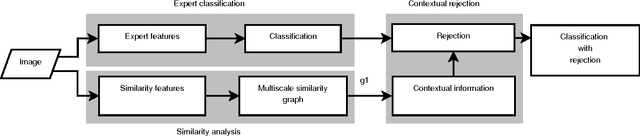
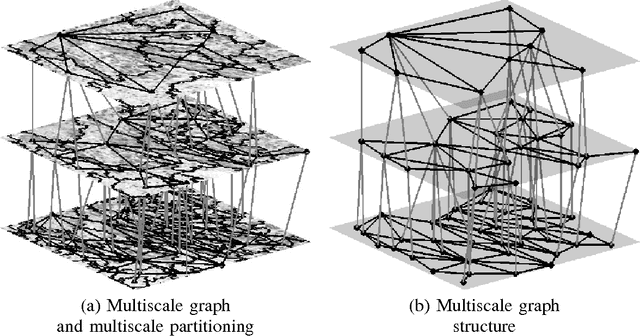
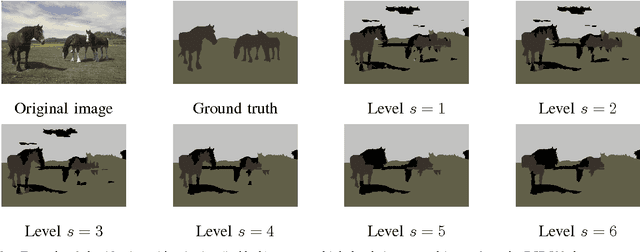
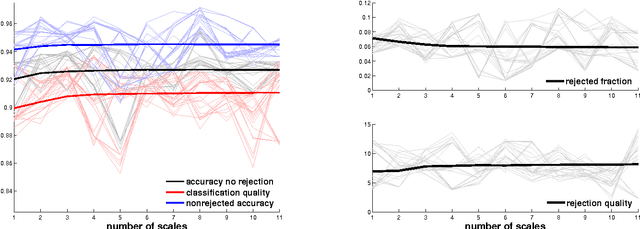
We introduce a new supervised algorithm for image classification with rejection using multiscale contextual information. Rejection is desired in image-classification applications that require a robust classifier but not the classification of the entire image. The proposed algorithm combines local and multiscale contextual information with rejection, improving the classification performance. As a probabilistic model for classification, we adopt a multinomial logistic regression. The concept of rejection with contextual information is implemented by modeling the classification problem as an energy minimization problem over a graph representing local and multiscale similarities of the image. The rejection is introduced through an energy data term associated with the classification risk and the contextual information through an energy smoothness term associated with the local and multiscale similarities within the image. We illustrate the proposed method on the classification of images of H&E-stained teratoma tissues.
Be Causal: De-biasing Social Network Confounding in Recommendation
May 20, 2021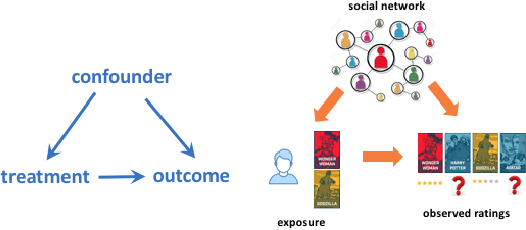
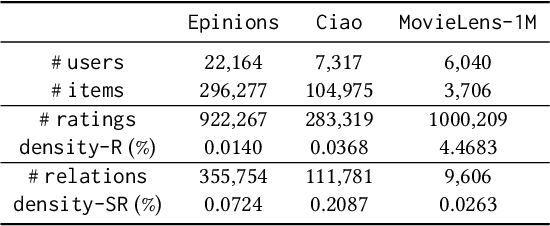
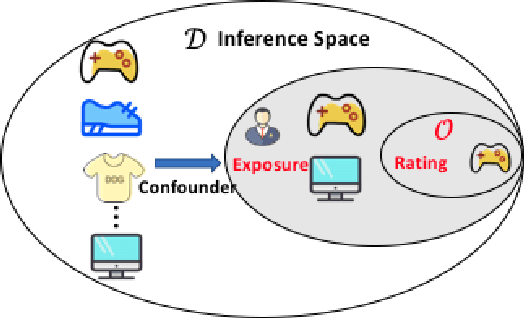
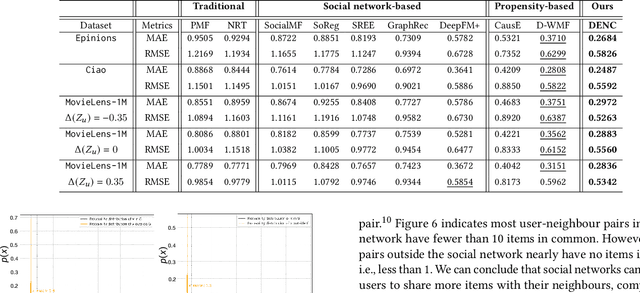
In recommendation systems, the existence of the missing-not-at-random (MNAR) problem results in the selection bias issue, degrading the recommendation performance ultimately. A common practice to address MNAR is to treat missing entries from the so-called "exposure" perspective, i.e., modeling how an item is exposed (provided) to a user. Most of the existing approaches use heuristic models or re-weighting strategy on observed ratings to mimic the missing-at-random setting. However, little research has been done to reveal how the ratings are missing from a causal perspective. To bridge the gap, we propose an unbiased and robust method called DENC (De-bias Network Confounding in Recommendation) inspired by confounder analysis in causal inference. In general, DENC provides a causal analysis on MNAR from both the inherent factors (e.g., latent user or item factors) and auxiliary network's perspective. Particularly, the proposed exposure model in DENC can control the social network confounder meanwhile preserves the observed exposure information. We also develop a deconfounding model through the balanced representation learning to retain the primary user and item features, which enables DENC generalize well on the rating prediction. Extensive experiments on three datasets validate that our proposed model outperforms the state-of-the-art baselines.
Enabling Content-Centric Device-to-Device Communication in the Millimeter-Wave Band
Apr 12, 2021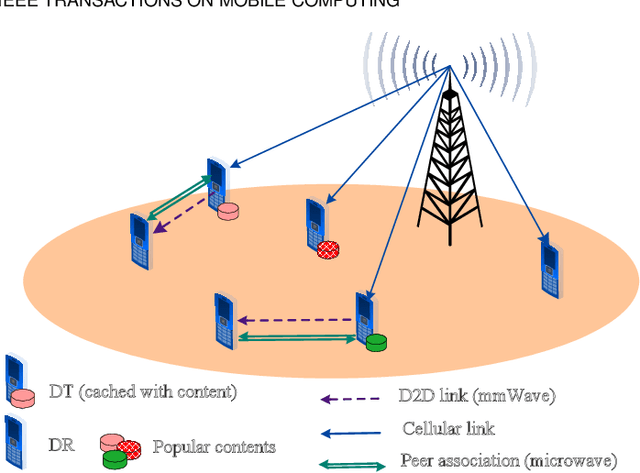

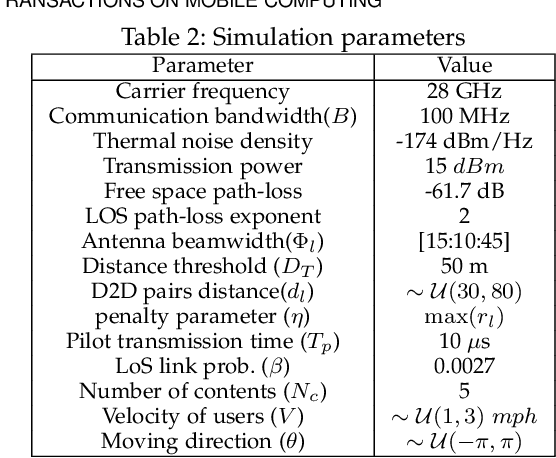
The growth in wireless traffic and mobility of devices have congested the core network significantly. This bottleneck, along with spectrum scarcity, made the conventional cellular networks insufficient for the dissemination of large contents. In this paper, we propose a novel scheme that enables efficient initialization of CCN-based D2D networks in the mmWave band through addressing decentralized D2D peer association and antenna beamwidth selection. The proposed scheme considers mmWave characteristics such as directional communication and blockage susceptibility. We propose a heuristic peer association algorithm to associate D2D users using context information, including link stability time and content availability. The performance of the proposed scheme in terms of data throughput and transmission efficiency is evaluated through extensive simulations. Simulation results show that the proposed scheme improves network performance significantly and outperforms other methods in the literature.
Neuro-inspired edge feature fusion using Choquet integrals
Apr 22, 2021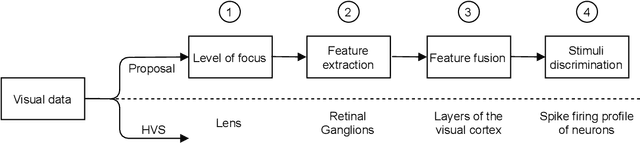


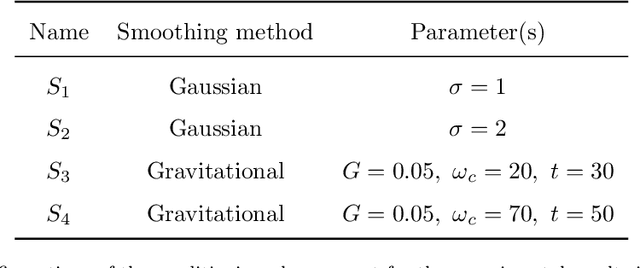
It is known that the human visual system performs a hierarchical information process in which early vision cues (or primitives) are fused in the visual cortex to compose complex shapes and descriptors. While different aspects of the process have been extensively studied, as the lens adaptation or the feature detection, some other,as the feature fusion, have been mostly left aside. In this work we elaborate on the fusion of early vision primitives using generalizations of the Choquet integral, and novel aggregation operators that have been extensively studied in recent years. We propose to use generalizations of the Choquet integral to sensibly fuse elementary edge cues, in an attempt to model the behaviour of neurons in the early visual cortex. Our proposal leads to a full-framed edge detection algorithm, whose performance is put to the test in state-of-the-art boundary detection datasets.
Classification of Building Information Model (BIM) Structures with Deep Learning
Aug 01, 2018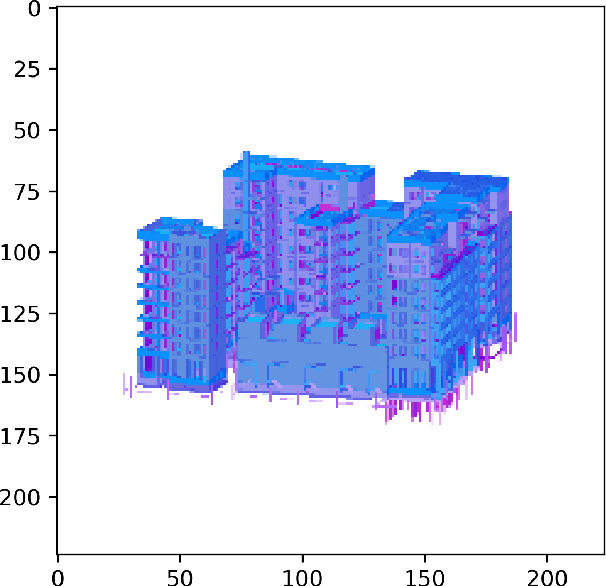

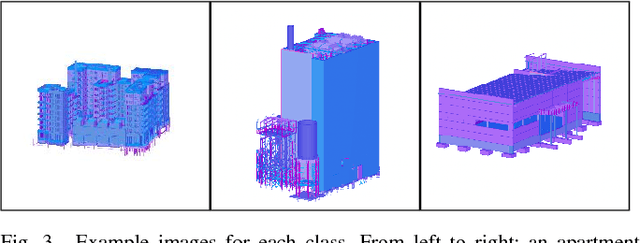

In this work we study an application of machine learning to the construction industry and we use classical and modern machine learning methods to categorize images of building designs into three classes: Apartment building, Industrial building or Other. No real images are used, but only images extracted from Building Information Model (BIM) software, as these are used by the construction industry to store building designs. For this task, we compared four different methods: the first is based on classical machine learning, where Histogram of Oriented Gradients (HOG) was used for feature extraction and a Support Vector Machine (SVM) for classification; the other three methods are based on deep learning, covering common pre-trained networks as well as ones designed from scratch. To validate the accuracy of the models, a database of 240 images was used. The accuracy achieved is 57% for the HOG + SVM model, and above 89% for the neural networks.
Multiview Pseudo-Labeling for Semi-supervised Learning from Video
Apr 01, 2021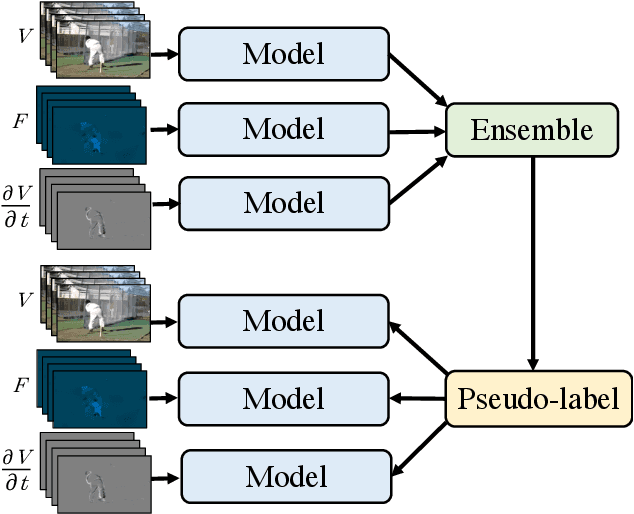
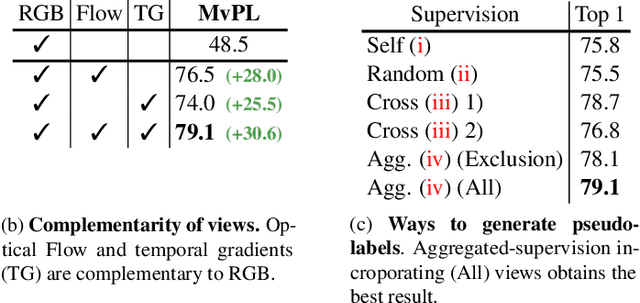
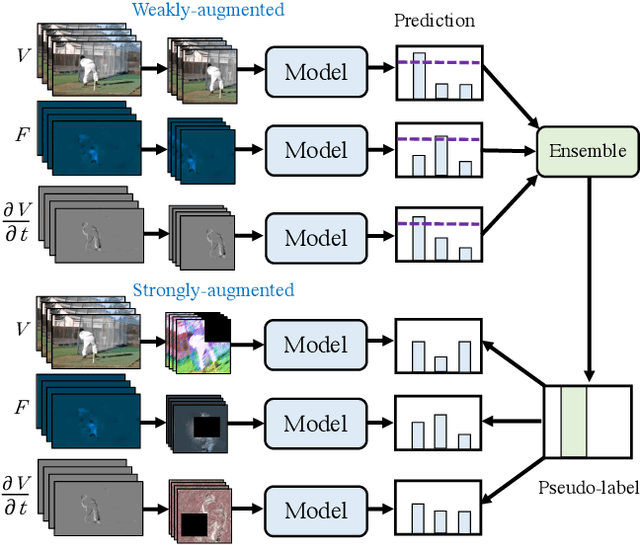

We present a multiview pseudo-labeling approach to video learning, a novel framework that uses complementary views in the form of appearance and motion information for semi-supervised learning in video. The complementary views help obtain more reliable pseudo-labels on unlabeled video, to learn stronger video representations than from purely supervised data. Though our method capitalizes on multiple views, it nonetheless trains a model that is shared across appearance and motion input and thus, by design, incurs no additional computation overhead at inference time. On multiple video recognition datasets, our method substantially outperforms its supervised counterpart, and compares favorably to previous work on standard benchmarks in self-supervised video representation learning.