 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An Adaptive Memory Multi-Batch L-BFGS Algorithm for Neural Network Training
Dec 14, 2020


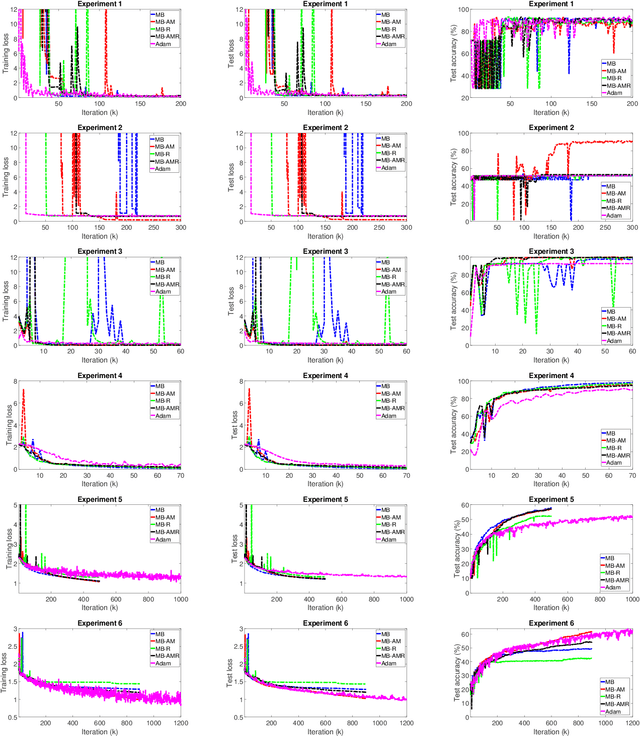
Motivated by the potential for parallel implementation of batch-based algorithms and the accelerated convergence achievable with approximated second order information a limited memory version of the BFGS algorithm has been receiving increasing attention in recent years for large neural network training problems. As the shape of the cost function is generally not quadratic and only becomes approximately quadratic in the vicinity of a minimum, the use of second order information by L-BFGS can be unreliable during the initial phase of training, i.e. when far from a minimum. Therefore, to control the influence of second order information as training progresses, we propose a multi-batch L-BFGS algorithm, namely MB-AM, that gradually increases its trust in the curvature information by implementing a progressive storage and use of curvature data through a development-based increase (dev-increase) scheme. Using six discriminative modelling benchmark problems we show empirically that MB-AM has slightly faster convergence and, on average, achieves better solutions than the standard multi-batch L-BFGS algorithm when training MLP and CNN models.
Real-time Outdoor Localization Using Radio Maps: A Deep Learning Approach
Jun 23, 2021
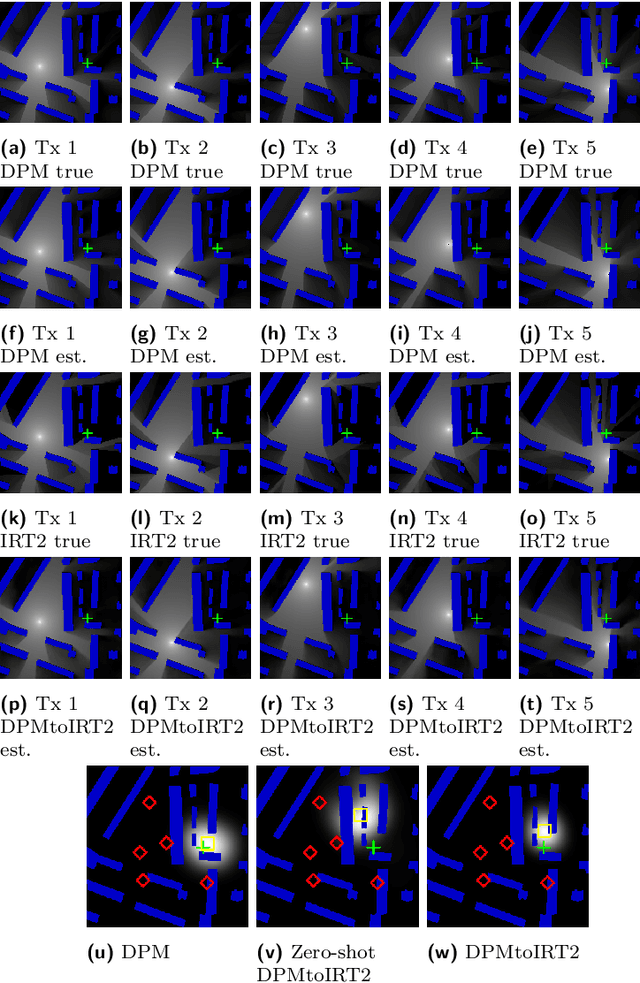
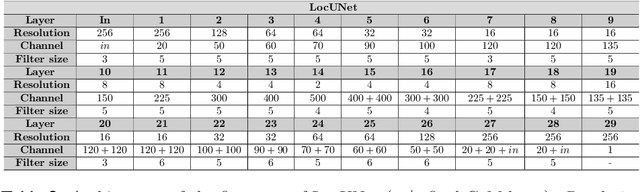
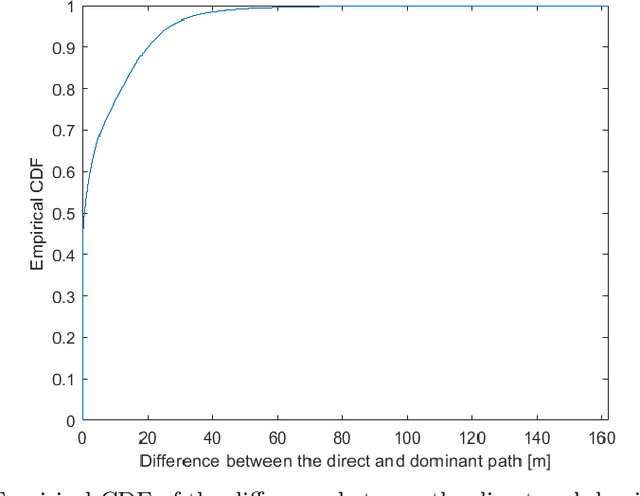
This paper deals with the problem of localization in a cellular network in a dense urban scenario. Global Navigation Satellite Systems typically perform poorly in urban environments, where the likelihood of line-of-sight conditions between the devices and the satellites is low, and thus alternative localization methods are required for good accuracy. We present a deep learning method for localization, based merely on pathloss, which does not require any increase in computation complexity at the user devices with respect to the device standard operations, unlike methods that rely on time of arrival or angle of arrival information. In a wireless network, user devices scan the base station beacon slots and identify the few strongest base station signals for handover and user-base station association purposes. In the proposed method, the user to be localized simply reports such received signal strengths to a central processing unit, which may be located in the cloud. For each base station we have good approximation of the pathloss at every location in a dense grid in the map. This approximation is provided by RadioUNet, a deep learning-based simulator of pathloss functions in urban environment, that we have previously proposed and published. Using the estimated pathloss radio maps of all base stations and the corresponding reported signal strengths, the proposed deep learning algorithm can extract a very accurate localization of the user. The proposed method, called LocUNet, enjoys high robustness to inaccuracies in the estimated radio maps. We demonstrate this by numerical experiments, which obtain state-of-the-art results.
User Label Leakage from Gradients in Federated Learning
May 22, 2021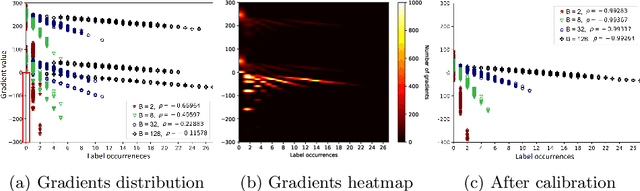

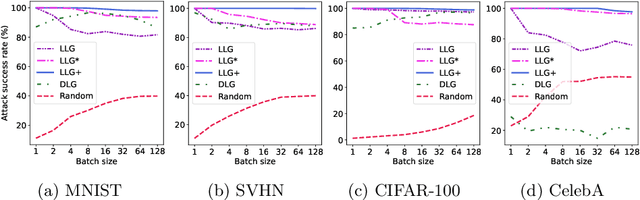

Federated learning enables multiple users to build a joint model by sharing their model updates (gradients), while their raw data remains local on their devices. In contrast to the common belief that this provides privacy benefits, we here add to the very recent results on privacy risks when sharing gradients. Specifically, we propose Label Leakage from Gradients (LLG), a novel attack to extract the labels of the users' training data from their shared gradients. The attack exploits the direction and magnitude of gradients to determine the presence or absence of any label. LLG is simple yet effective, capable of leaking potential sensitive information represented by labels, and scales well to arbitrary batch sizes and multiple classes. We empirically and mathematically demonstrate the validity of our attack under different settings. Moreover, empirical results show that LLG successfully extracts labels with high accuracy at the early stages of model training. We also discuss different defense mechanisms against such leakage. Our findings suggest that gradient compression is a practical technique to prevent our attack.
Finding simplicity: unsupervised discovery of features, patterns, and order parameters via shift-invariant variational autoencoders
Jun 23, 2021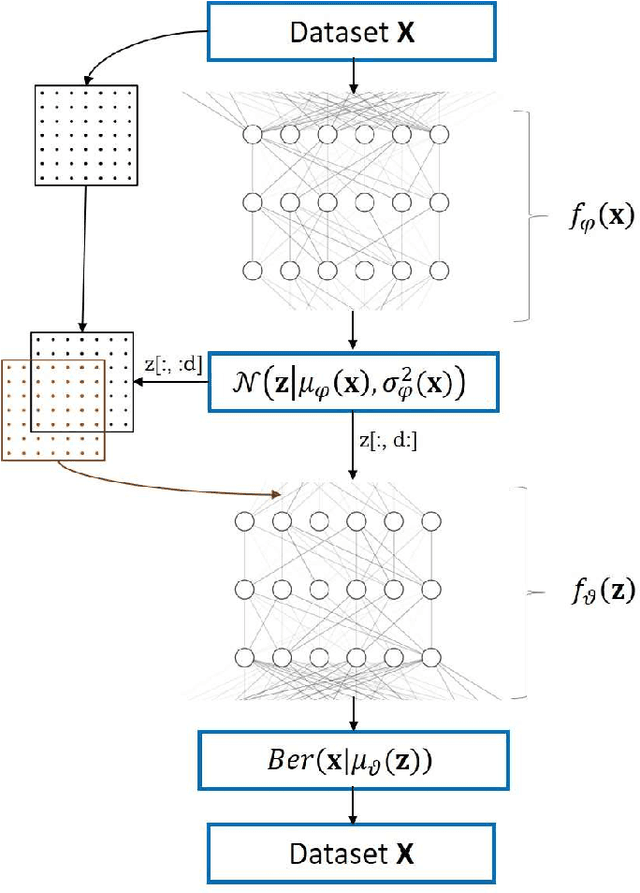
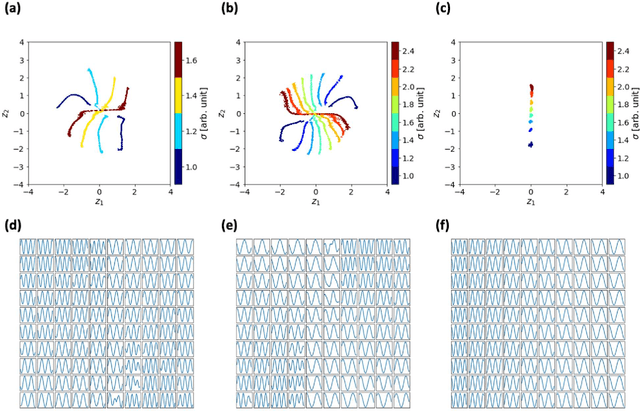
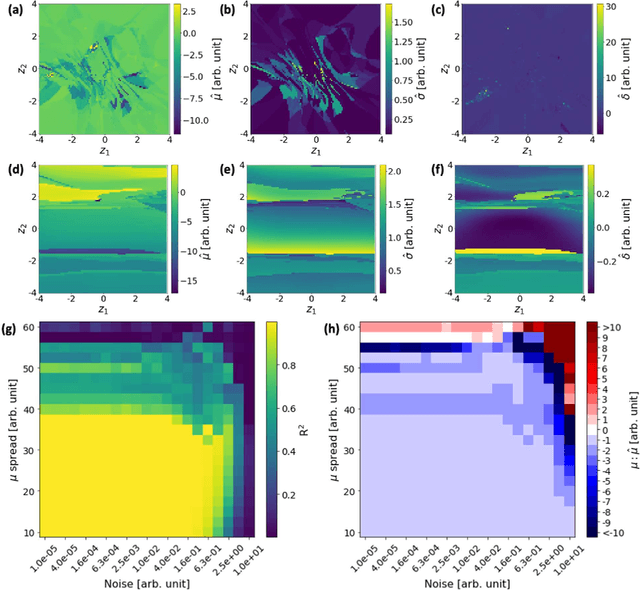
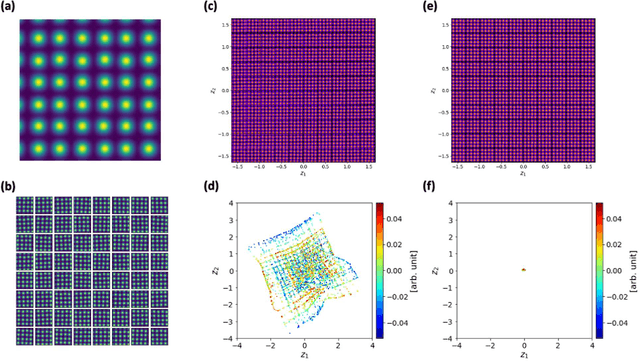
Recent advances in scanning tunneling and transmission electron microscopies (STM and STEM) have allowed routine generation of large volumes of imaging data containing information on the structure and functionality of materials. The experimental data sets contain signatures of long-range phenomena such as physical order parameter fields, polarization and strain gradients in STEM, or standing electronic waves and carrier-mediated exchange interactions in STM, all superimposed onto scanning system distortions and gradual changes of contrast due to drift and/or mis-tilt effects. Correspondingly, while the human eye can readily identify certain patterns in the images such as lattice periodicities, repeating structural elements, or microstructures, their automatic extraction and classification are highly non-trivial and universal pathways to accomplish such analyses are absent. We pose that the most distinctive elements of the patterns observed in STM and (S)TEM images are similarity and (almost-) periodicity, behaviors stemming directly from the parsimony of elementary atomic structures, superimposed on the gradual changes reflective of order parameter distributions. However, the discovery of these elements via global Fourier methods is non-trivial due to variability and lack of ideal discrete translation symmetry. To address this problem, we develop shift-invariant variational autoencoders (shift-VAE) that allow disentangling characteristic repeating features in the images, their variations, and shifts inevitable for random sampling of image space. Shift-VAEs balance the uncertainty in the position of the object of interest with the uncertainty in shape reconstruction. This approach is illustrated for model 1D data, and further extended to synthetic and experimental STM and STEM 2D data.
BinarizedAttack: Structural Poisoning Attacks to Graph-based Anomaly Detection
Jun 23, 2021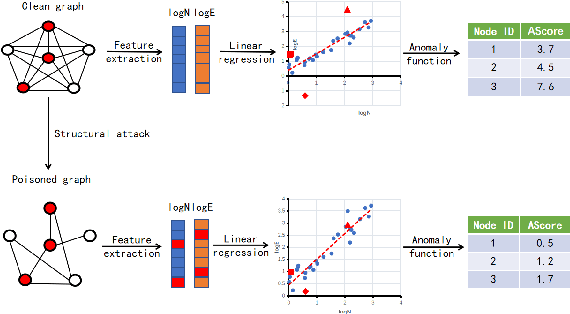
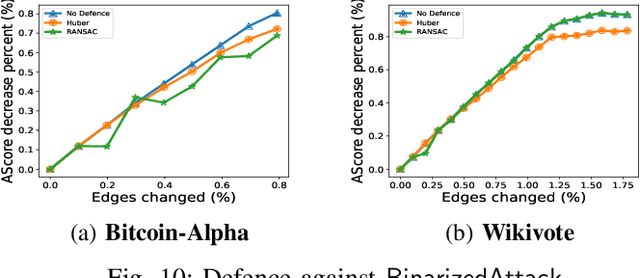
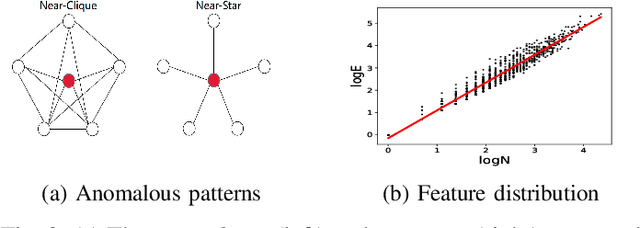
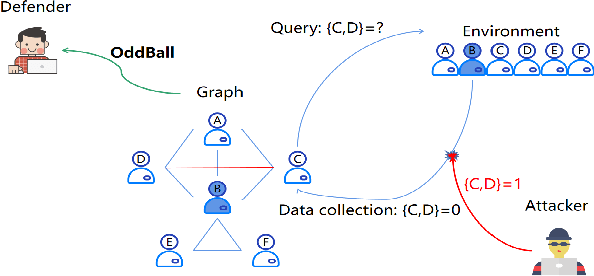
Graph-based Anomaly Detection (GAD) is becoming prevalent due to the powerful representation abilities of graphs as well as recent advances in graph mining techniques. These GAD tools, however, expose a new attacking surface, ironically due to their unique advantage of being able to exploit the relations among data. That is, attackers now can manipulate those relations (i.e., the structure of the graph) to allow some target nodes to evade detection. In this paper, we exploit this vulnerability by designing a new type of targeted structural poisoning attacks to a representative regression-based GAD system termed OddBall. Specially, we formulate the attack against OddBall as a bi-level optimization problem, where the key technical challenge is to efficiently solve the problem in a discrete domain. We propose a novel attack method termed BinarizedAttack based on gradient descent. Comparing to prior arts, BinarizedAttack can better use the gradient information, making it particularly suitable for solving combinatorial optimization problems. Furthermore, we investigate the attack transferability of BinarizedAttack by employing it to attack other representation-learning-based GAD systems. Our comprehensive experiments demonstrate that BinarizedAttack is very effective in enabling target nodes to evade graph-based anomaly detection tools with limited attackers' budget, and in the black-box transfer attack setting, BinarizedAttack is also tested effective and in particular, can significantly change the node embeddings learned by the GAD systems. Our research thus opens the door to studying a new type of attack against security analytic tools that rely on graph data.
MARL with General Utilities via Decentralized Shadow Reward Actor-Critic
May 29, 2021
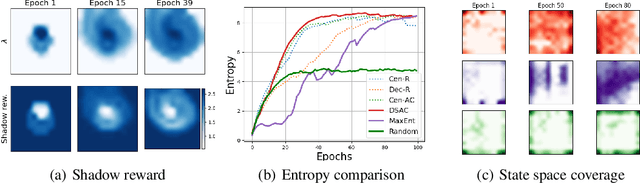
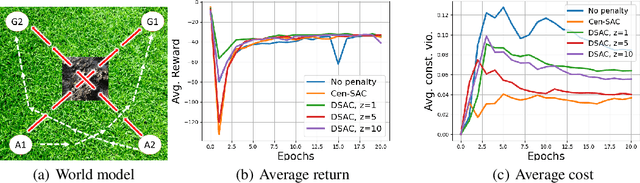
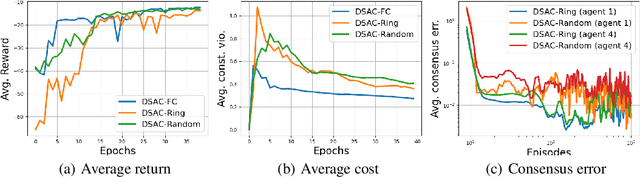
We posit a new mechanism for cooperation in multi-agent reinforcement learning (MARL) based upon any nonlinear function of the team's long-term state-action occupancy measure, i.e., a \emph{general utility}. This subsumes the cumulative return but also allows one to incorporate risk-sensitivity, exploration, and priors. % We derive the {\bf D}ecentralized {\bf S}hadow Reward {\bf A}ctor-{\bf C}ritic (DSAC) in which agents alternate between policy evaluation (critic), weighted averaging with neighbors (information mixing), and local gradient updates for their policy parameters (actor). DSAC augments the classic critic step by requiring agents to (i) estimate their local occupancy measure in order to (ii) estimate the derivative of the local utility with respect to their occupancy measure, i.e., the "shadow reward". DSAC converges to $\epsilon$-stationarity in $\mathcal{O}(1/\epsilon^{2.5})$ (Theorem \ref{theorem:final}) or faster $\mathcal{O}(1/\epsilon^{2})$ (Corollary \ref{corollary:communication}) steps with high probability, depending on the amount of communications. We further establish the non-existence of spurious stationary points for this problem, that is, DSAC finds the globally optimal policy (Corollary \ref{corollary:global}). Experiments demonstrate the merits of goals beyond the cumulative return in cooperative MARL.
Extending Models Via Gradient Boosting: An Application to Mendelian Models
May 13, 2021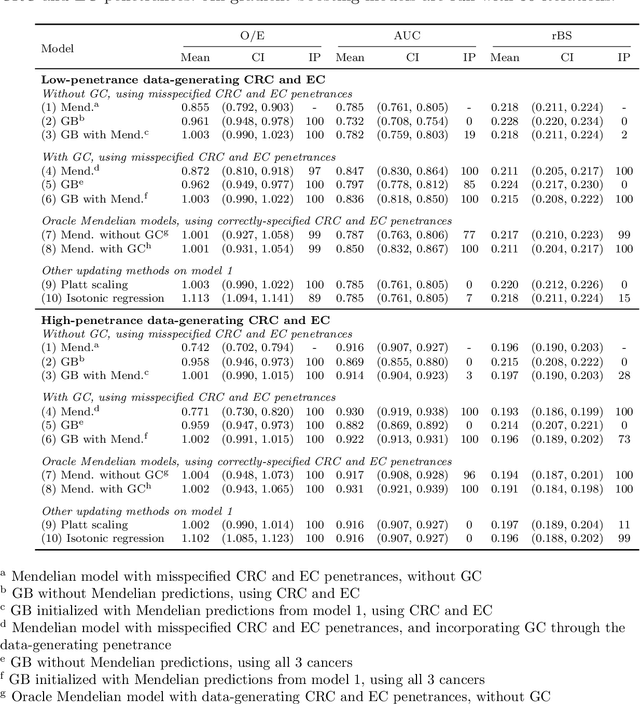
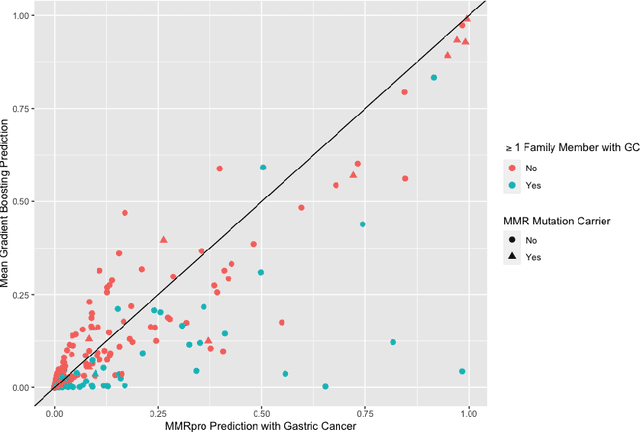
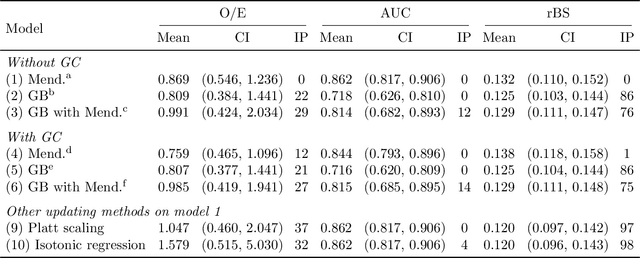
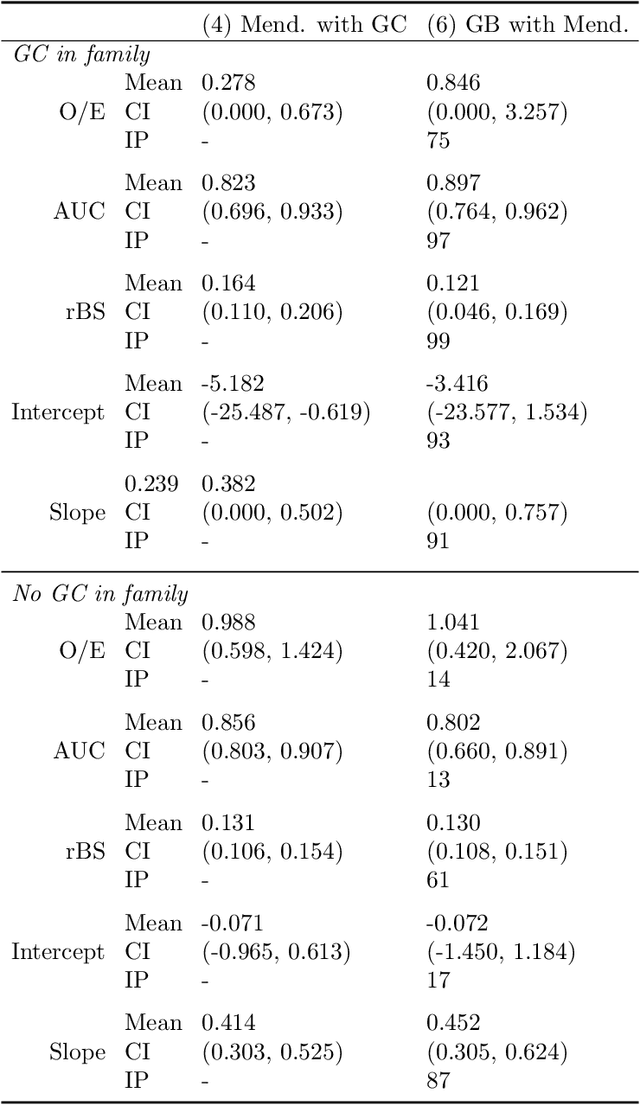
Improving existing widely-adopted prediction models is often a more efficient and robust way towards progress than training new models from scratch. Existing models may (a) incorporate complex mechanistic knowledge, (b) leverage proprietary information and, (c) have surmounted barriers to adoption. Compared to model training, model improvement and modification receive little attention. In this paper we propose a general approach to model improvement: we combine gradient boosting with any previously developed model to improve model performance while retaining important existing characteristics. To exemplify, we consider the context of Mendelian models, which estimate the probability of carrying genetic mutations that confer susceptibility to disease by using family pedigrees and health histories of family members. Via simulations we show that integration of gradient boosting with an existing Mendelian model can produce an improved model that outperforms both that model and the model built using gradient boosting alone. We illustrate the approach on genetic testing data from the USC-Stanford Cancer Genetics Hereditary Cancer Panel (HCP) study.
TagRec: Automated Tagging of Questions with Hierarchical Learning Taxonomy
Jul 03, 2021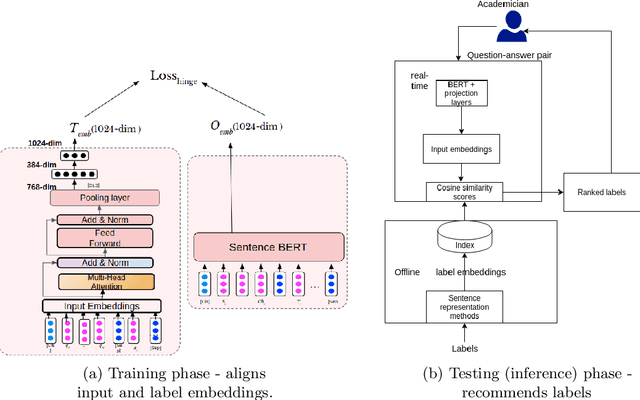

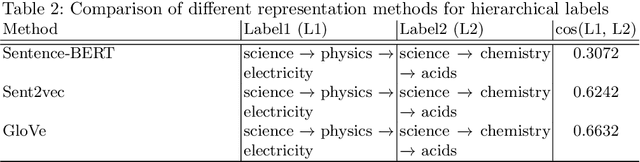
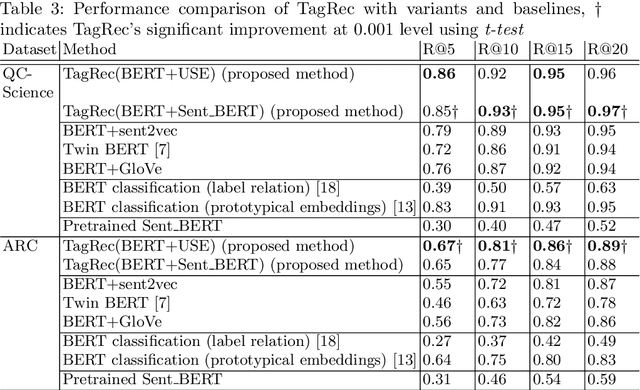
Online educational platforms organize academic questions based on a hierarchical learning taxonomy (subject-chapter-topic). Automatically tagging new questions with existing taxonomy will help organize these questions into different classes of hierarchical taxonomy so that they can be searched based on the facets like chapter. This task can be formulated as a flat multi-class classification problem. Usually, flat classification based methods ignore the semantic relatedness between the terms in the hierarchical taxonomy and the questions. Some traditional methods also suffer from the class imbalance issues as they consider only the leaf nodes ignoring the hierarchy. Hence, we formulate the problem as a similarity-based retrieval task where we optimize the semantic relatedness between the taxonomy and the questions. We demonstrate that our method helps to handle the unseen labels and hence can be used for taxonomy tagging in the wild. In this method, we augment the question with its corresponding answer to capture more semantic information and then align the question-answer pair's contextualized embedding with the corresponding label (taxonomy) vector representations. The representations are aligned by fine-tuning a transformer based model with a loss function that is a combination of the cosine similarity and hinge rank loss. The loss function maximizes the similarity between the question-answer pair and the correct label representations and minimizes the similarity to unrelated labels. Finally, we perform experiments on two real-world datasets. We show that the proposed learning method outperforms representations learned using the multi-class classification method and other state of the art methods by 6% as measured by Recall@k. We also demonstrate the performance of the proposed method on unseen but related learning content like the learning objectives without re-training the network.
Gaussian Process Regression for Active Sensing Probabilistic Structural Health Monitoring: Experimental Assessment Across Multiple Damage and Loading Scenarios
Jun 28, 2021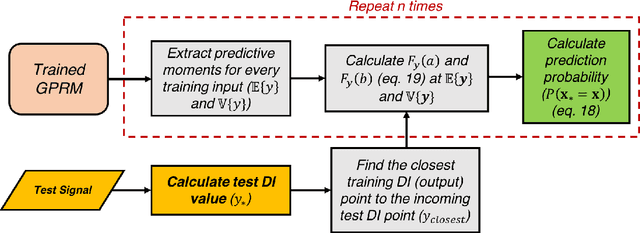
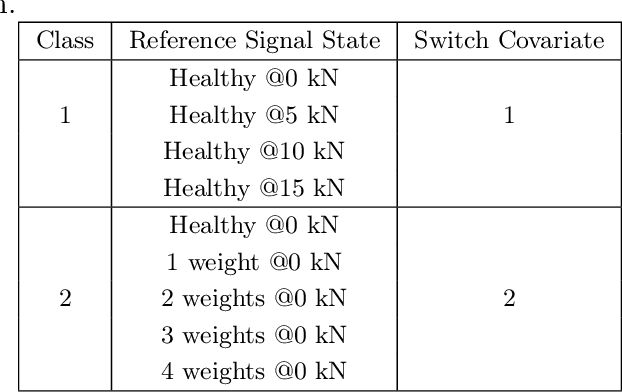
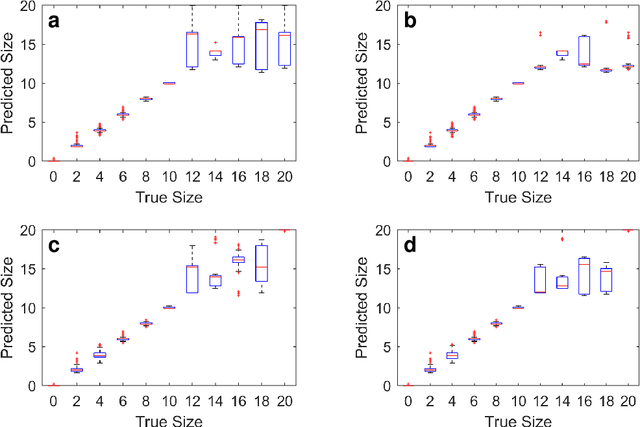
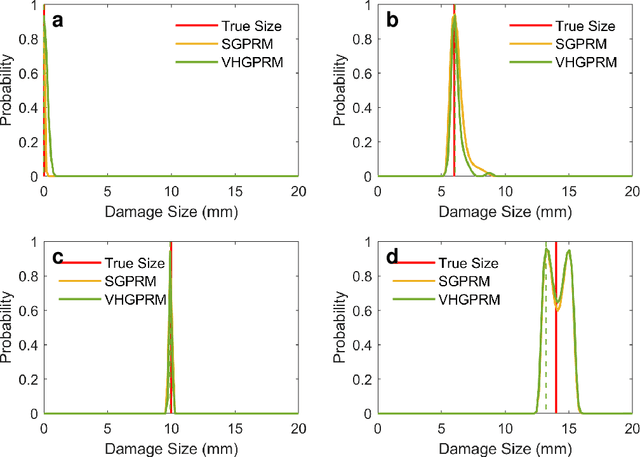
In the near future, Structural Health Monitoring (SHM) technologies will be capable of overcoming the drawbacks in the current maintenance and life-cycle management paradigms, namely: cost, increased downtime, less-than-optimal safety management paradigm and the limited applicability of fully-autonomous operations. In the context of SHM, one of the most challenging tasks is damage quantification. Current methods face accuracy and/or robustness issues when it comes to varying operating and environmental conditions. In addition, the damage/no-damage paradigm of current frameworks does not offer much information to maintainers on the ground for proper decision-making. In this study, a novel structural damage quantification framework is proposed based on widely-used Damage Indices (DIs) and Gaussian Process Regression Models (GPRMs). The novelty lies in calculating the probability of an incoming test DI point originating from a specific state, which allows for probability-educated decision-making. This framework is applied to three test cases: a Carbon Fiber-Reinforced Plastic (CFRP) coupon with attached weights as simulated damage, an aluminum coupon with a notch, and an aluminum coupon with attached weights as simulated damage under varying loading states. The state prediction method presented herein is applied to single-state quantification in the first two test cases, as well as the third one assuming the loading state is known. Finally, the proposed method is applied to the third test case assuming neither the damage size nor the load is known in order to predict both simultaneously from incoming DI test points. In applying this framework, two forms of GPRMs (standard and variational heteroscedastic) are used in order to critically assess their performances with respect to the three test cases.
Accessing accurate documents by mining auxiliary document information
Apr 15, 2016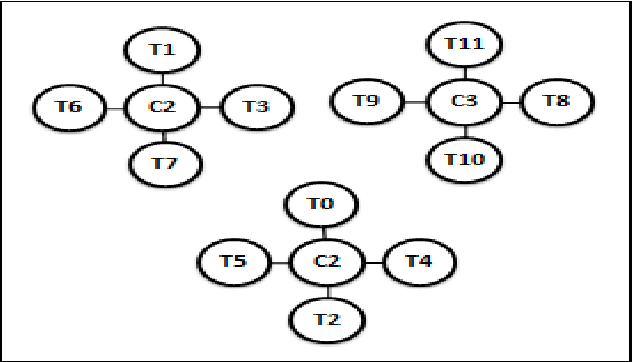
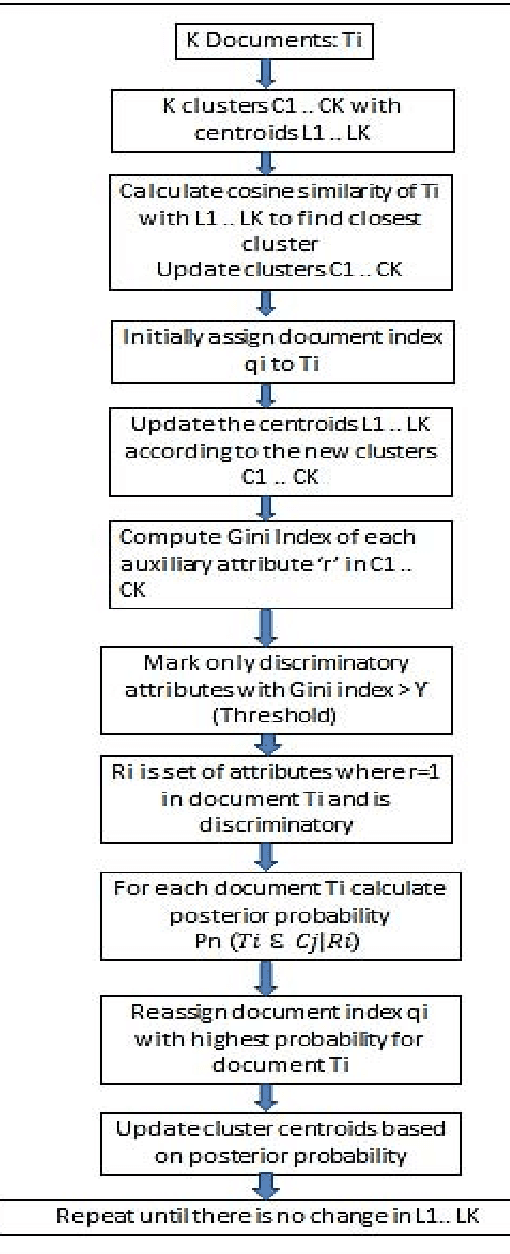
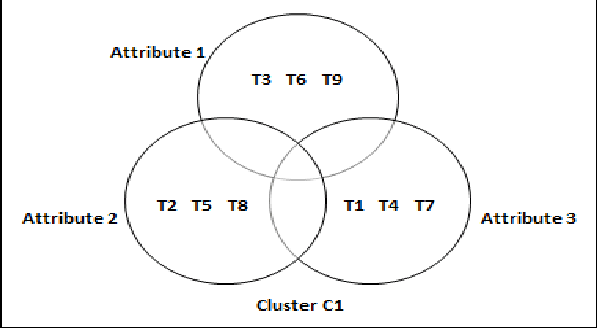
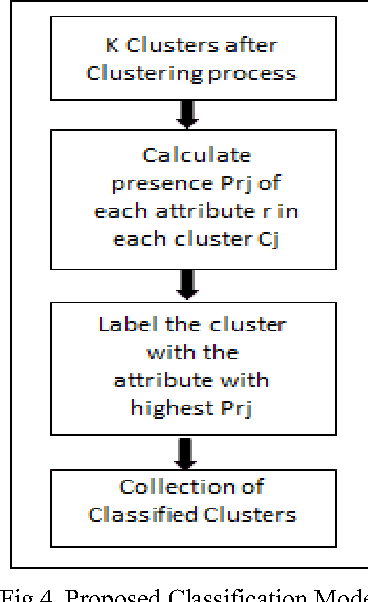
Earlier techniques of text mining included algorithms like k-means, Naive Bayes, SVM which classify and cluster the text document for mining relevant information about the documents. The need for improving the mining techniques has us searching for techniques using the available algorithms. This paper proposes one technique which uses the auxiliary information that is present inside the text documents to improve the mining. This auxiliary information can be a description to the content. This information can be either useful or completely useless for mining. The user should assess the worth of the auxiliary information before considering this technique for text mining. In this paper, a combination of classical clustering algorithms is used to mine the datasets. The algorithm runs in two stages which carry out mining at different levels of abstraction. The clustered documents would then be classified based on the necessary groups. The proposed technique is aimed at improved results of document clustering.