 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Dogfight: Detecting Drones from Drones Videos
Mar 31, 2021

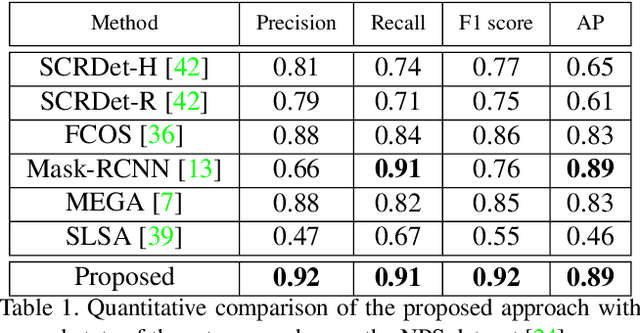
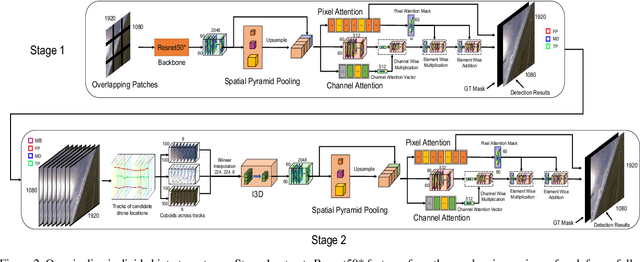
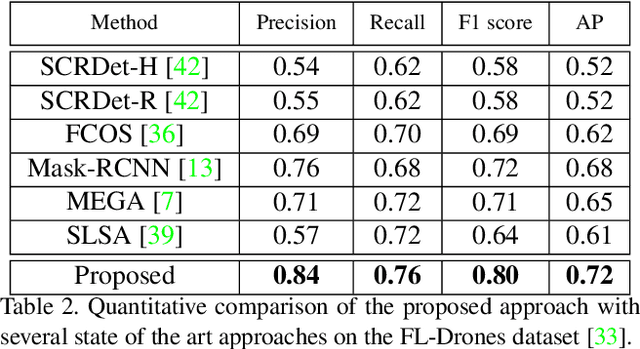
As airborne vehicles are becoming more autonomous and ubiquitous, it has become vital to develop the capability to detect the objects in their surroundings. This paper attempts to address the problem of drones detection from other flying drones. The erratic movement of the source and target drones, small size, arbitrary shape, large intensity variations, and occlusion make this problem quite challenging. In this scenario, region-proposal based methods are not able to capture sufficient discriminative foreground-background information. Also, due to the extremely small size and complex motion of the source and target drones, feature aggregation based methods are unable to perform well. To handle this, instead of using region-proposal based methods, we propose to use a two-stage segmentation-based approach employing spatio-temporal attention cues. During the first stage, given the overlapping frame regions, detailed contextual information is captured over convolution feature maps using pyramid pooling. After that pixel and channel-wise attention is enforced on the feature maps to ensure accurate drone localization. In the second stage, first stage detections are verified and new probable drone locations are explored. To discover new drone locations, motion boundaries are used. This is followed by tracking candidate drone detections for a few frames, cuboid formation, extraction of the 3D convolution feature map, and drones detection within each cuboid. The proposed approach is evaluated on two publicly available drone detection datasets and outperforms several competitive baselines.
V2V Spatiotemporal Interactive Pattern Recognition and Risk Analysis in Lane Changes
May 22, 2021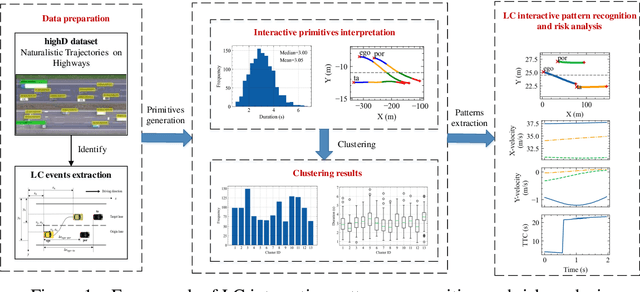
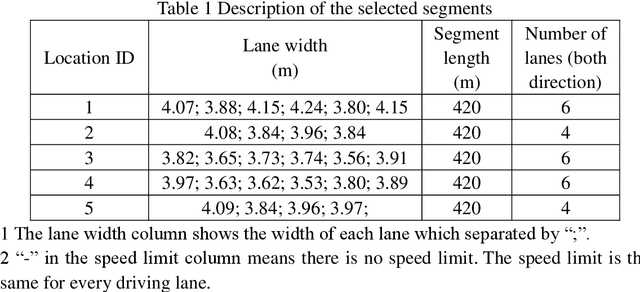
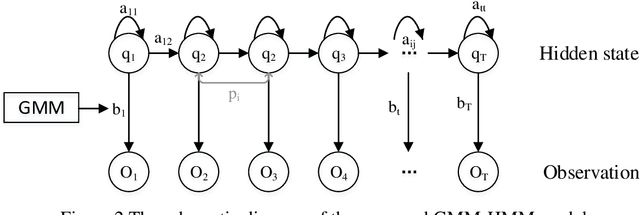
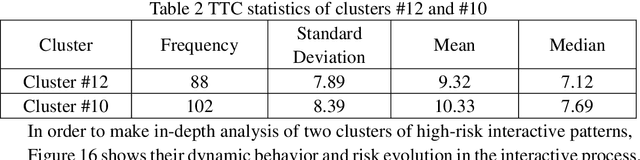
In complex lane change (LC) scenarios, semantic interpretation and safety analysis of dynamic interactive pattern are necessary for autonomous vehicles to make appropriate decisions. This study proposes an unsupervised learning framework that combines primitive-based interactive pattern recognition methods and risk analysis methods. The Hidden Markov Model with the Gaussian mixture model (GMM-HMM) approach is developed to decompose the LC scenarios into primitives. Then the Dynamic Time Warping (DTW) distance based K-means clustering is applied to gather the primitives to 13 types of interactive patterns. Finally, this study considers two types of time-to-collision (TTC) involved in the LC process as indicators to analyze the risk of the interactive patterns and extract high-risk LC interactive patterns. The results obtained from The Highway Drone Dataset (highD) demonstrate that the identified LC interactive patterns contain interpretable semantic information. This study explores the spatiotemporal evolution law and risk formation mechanism of the LC interactive patterns and the findings are useful for comprehensively understanding the latent interactive patterns, improving the rationality and safety of autonomous vehicle's decision-making.
On the Effectiveness of Dataset Embeddings in Mono-lingual,Multi-lingual and Zero-shot Conditions
Mar 01, 2021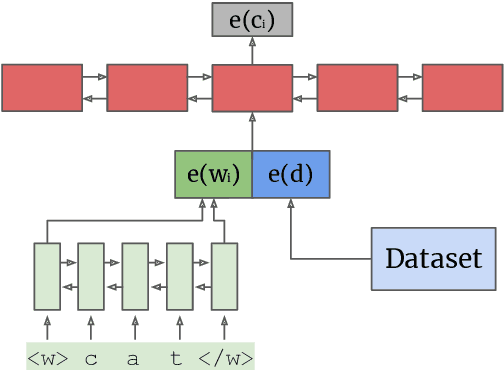

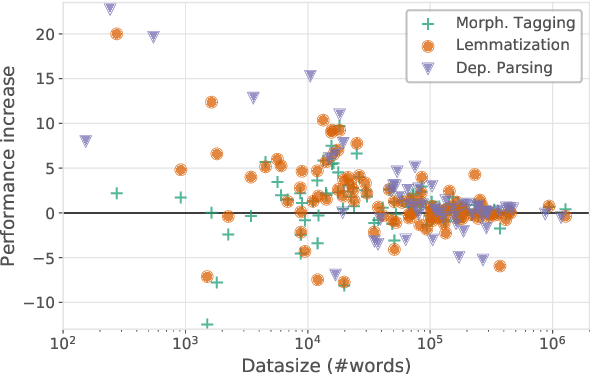
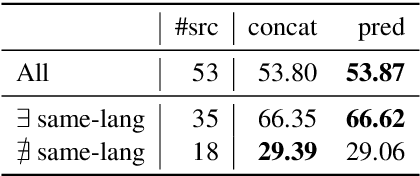
Recent complementary strands of research have shown that leveraging information on the data source through encoding their properties into embeddings can lead to performance increase when training a single model on heterogeneous data sources. However, it remains unclear in which situations these dataset embeddings are most effective, because they are used in a large variety of settings, languages and tasks. Furthermore, it is usually assumed that gold information on the data source is available, and that the test data is from a distribution seen during training. In this work, we compare the effect of dataset embeddings in mono-lingual settings, multi-lingual settings, and with predicted data source label in a zero-shot setting. We evaluate on three morphosyntactic tasks: morphological tagging, lemmatization, and dependency parsing, and use 104 datasets, 66 languages, and two different dataset grouping strategies. Performance increases are highest when the datasets are of the same language, and we know from which distribution the test-instance is drawn. In contrast, for setups where the data is from an unseen distribution, performance increase vanishes.
Ergodic imitation: Learning from what to do and what not to do
Mar 31, 2021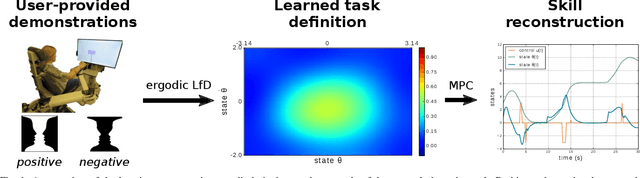
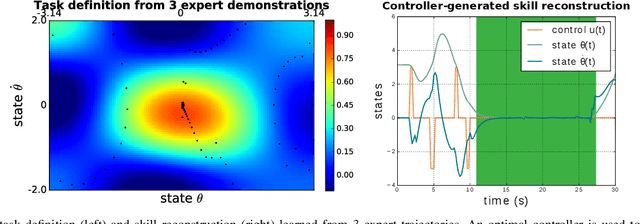
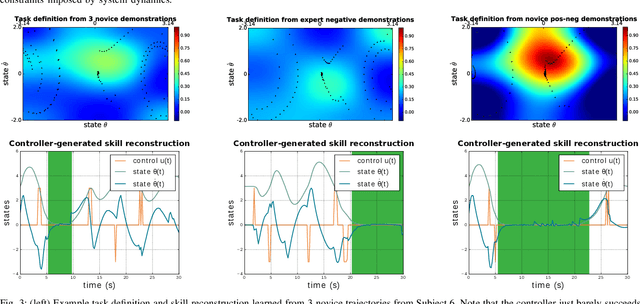
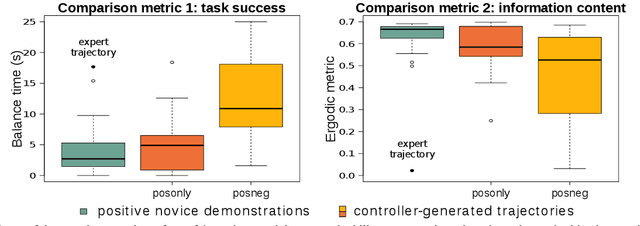
With growing access to versatile robotics, it is beneficial for end users to be able to teach robots tasks without needing to code a control policy. One possibility is to teach the robot through successful task executions. However, near-optimal demonstrations of a task can be difficult to provide and even successful demonstrations can fail to capture task aspects key to robust skill replication. Here, we propose a learning from demonstration (LfD) approach that enables learning of robust task definitions without the need for near-optimal demonstrations. We present a novel algorithmic framework for learning tasks based on the ergodic metric -- a measure of information content in motion. Moreover, we make use of negative demonstrations -- demonstrations of what not to do -- and show that they can help compensate for imperfect demonstrations, reduce the number of demonstrations needed, and highlight crucial task elements improving robot performance. In a proof-of-concept example of cart-pole inversion, we show that negative demonstrations alone can be sufficient to successfully learn and recreate a skill. Through a human subject study with 24 participants, we show that consistently more information about a task can be captured from combined positive and negative (posneg) demonstrations than from the same amount of just positive demonstrations. Finally, we demonstrate our learning approach on simulated tasks of target reaching and table cleaning with a 7-DoF Franka arm. Our results point towards a future with robust, data-efficient LfD for novice users.
* Kalinowska and Prabhakar contributed equally to this work
Zero-shot Task Adaptation using Natural Language
Jun 05, 2021
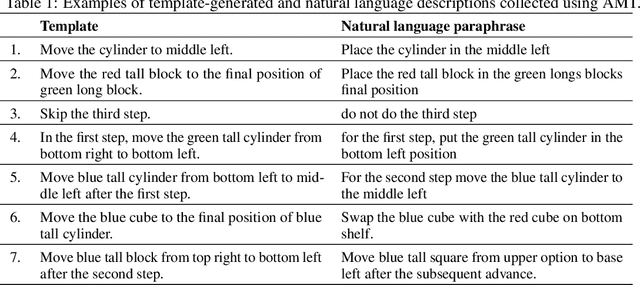
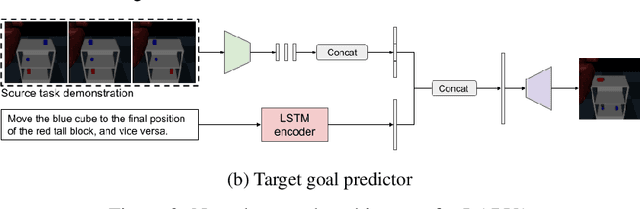
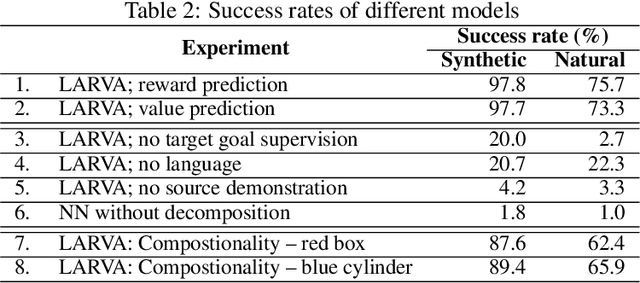
Imitation learning and instruction-following are two common approaches to communicate a user's intent to a learning agent. However, as the complexity of tasks grows, it could be beneficial to use both demonstrations and language to communicate with an agent. In this work, we propose a novel setting where an agent is given both a demonstration and a description, and must combine information from both the modalities. Specifically, given a demonstration for a task (the source task), and a natural language description of the differences between the demonstrated task and a related but different task (the target task), our goal is to train an agent to complete the target task in a zero-shot setting, that is, without any demonstrations for the target task. To this end, we introduce Language-Aided Reward and Value Adaptation (LARVA) which, given a source demonstration and a linguistic description of how the target task differs, learns to output a reward / value function that accurately describes the target task. Our experiments show that on a diverse set of adaptations, our approach is able to complete more than 95% of target tasks when using template-based descriptions, and more than 70% when using free-form natural language.
Graph Neural Networks with Local Graph Parameters
Jun 12, 2021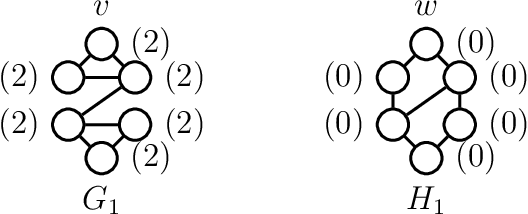
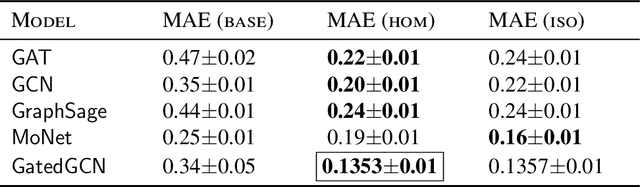
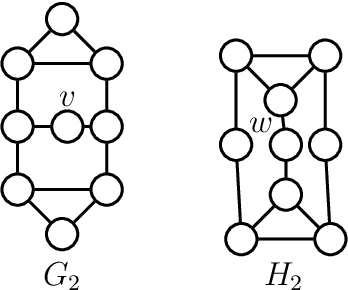

Various recent proposals increase the distinguishing power of Graph Neural Networks GNNs by propagating features between $k$-tuples of vertices. The distinguishing power of these "higher-order'' GNNs is known to be bounded by the $k$-dimensional Weisfeiler-Leman (WL) test, yet their $\mathcal O(n^k)$ memory requirements limit their applicability. Other proposals infuse GNNs with local higher-order graph structural information from the start, hereby inheriting the desirable $\mathcal O(n)$ memory requirement from GNNs at the cost of a one-time, possibly non-linear, preprocessing step. We propose local graph parameter enabled GNNs as a framework for studying the latter kind of approaches and precisely characterize their distinguishing power, in terms of a variant of the WL test, and in terms of the graph structural properties that they can take into account. Local graph parameters can be added to any GNN architecture, and are cheap to compute. In terms of expressive power, our proposal lies in the middle of GNNs and their higher-order counterparts. Further, we propose several techniques to aide in choosing the right local graph parameters. Our results connect GNNs with deep results in finite model theory and finite variable logics. Our experimental evaluation shows that adding local graph parameters often has a positive effect for a variety of GNNs, datasets and graph learning tasks.
Deep Fake Detection: Survey of Facial Manipulation Detection Solutions
Jun 23, 2021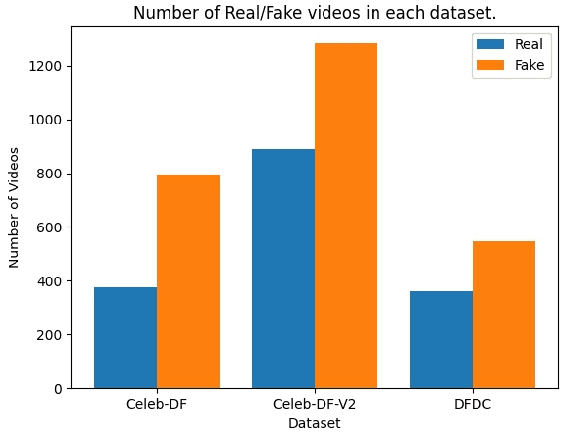
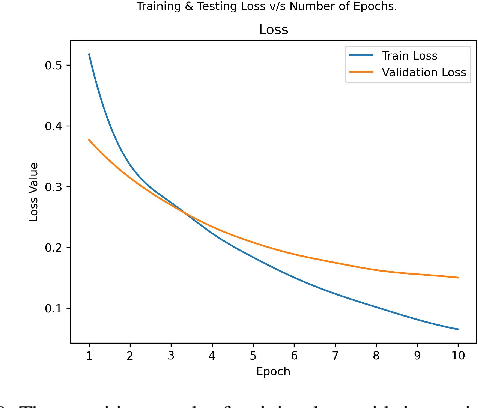
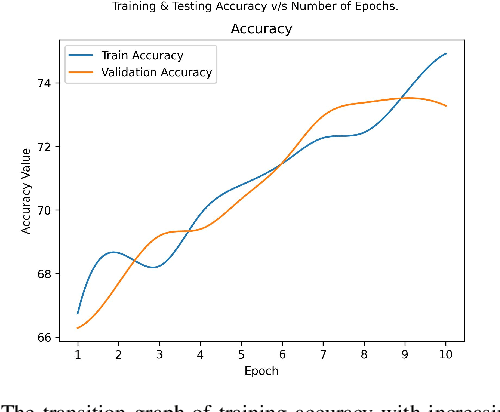
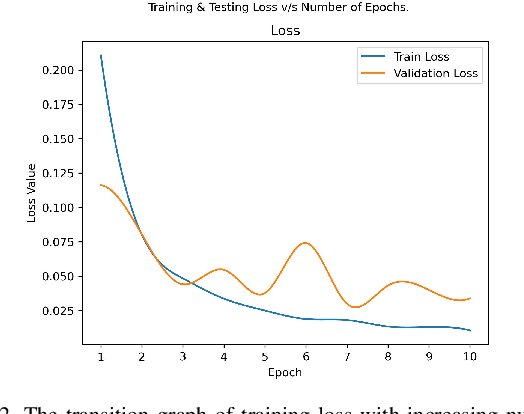
Deep Learning as a field has been successfully used to solve a plethora of complex problems, the likes of which we could not have imagined a few decades back. But as many benefits as it brings, there are still ways in which it can be used to bring harm to our society. Deep fakes have been proven to be one such problem, and now more than ever, when any individual can create a fake image or video simply using an application on the smartphone, there need to be some countermeasures, with which we can detect if the image or video is a fake or real and dispose of the problem threatening the trustworthiness of online information. Although the Deep fakes created by neural networks, may seem to be as real as a real image or video, it still leaves behind spatial and temporal traces or signatures after moderation, these signatures while being invisible to a human eye can be detected with the help of a neural network trained to specialize in Deep fake detection. In this paper, we analyze several such states of the art neural networks (MesoNet, ResNet-50, VGG-19, and Xception Net) and compare them against each other, to find an optimal solution for various scenarios like real-time deep fake detection to be deployed in online social media platforms where the classification should be made as fast as possible or for a small news agency where the classification need not be in real-time but requires utmost accuracy.
* 7 Pages, 14 figures, and 1 table
A surgical dataset from the da Vinci Research Kit for task automation and recognition
Feb 06, 2021
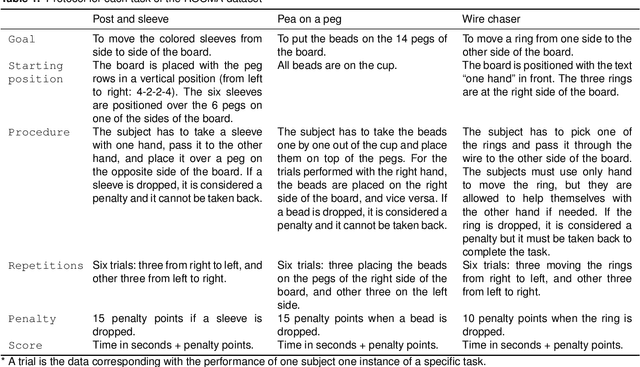
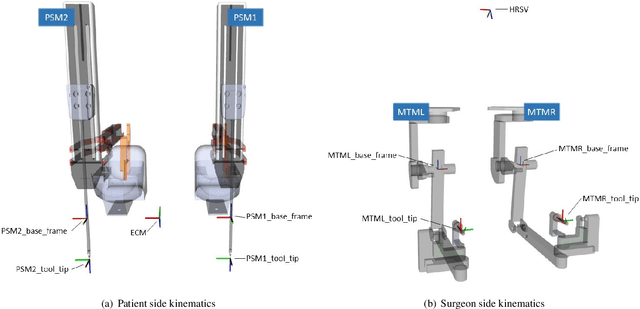

The use of datasets is getting more relevance in surgical robotics since they can be used to recognise and automate tasks. Also, this allows to use common datasets to compare different algorithms and methods. The objective of this work is to provide a complete dataset of three common training surgical tasks that surgeons perform to improve their skills. For this purpose, 12 subjects teleoperated the da Vinci Research Kit to perform these tasks. The obtained dataset includes all the kinematics and dynamics information provided by the da Vinci robot (both master and slave side) together with the associated video from the camera. All the information has been carefully timestamped and provided in a readable csv format. A MATLAB interface integrated with ROS for using and replicating the data is also provided.
Monitoring nonstationary processes based on recursive cointegration analysis and elastic weight consolidation
Jan 21, 2021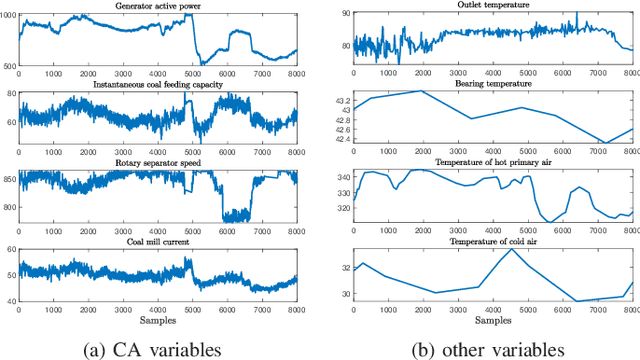
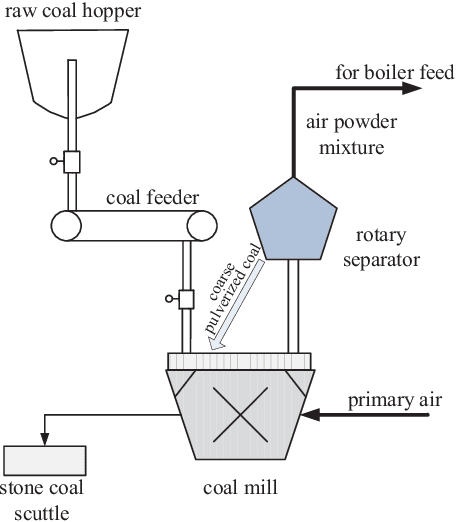
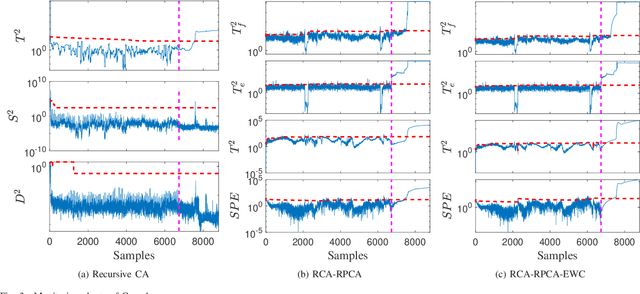
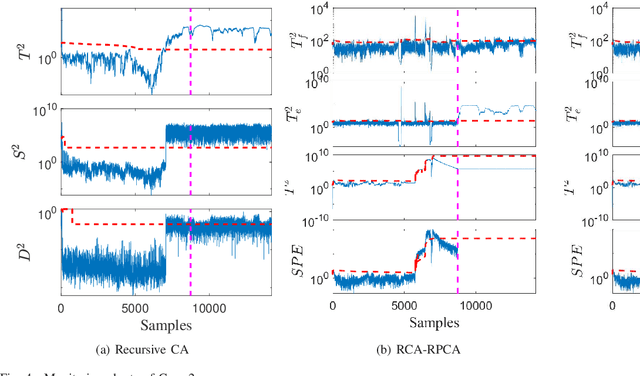
This paper considers the problem of nonstationary process monitoring under frequently varying operating conditions. Traditional approaches generally misidentify the normal dynamic deviations as faults and thus lead to high false alarms. Besides, they generally consider single relatively steady operating condition and suffer from the catastrophic forgetting issue when learning successive operating conditions. In this paper, recursive cointegration analysis (RCA) is first proposed to distinguish the real faults from normal systems changes, where the model is updated once a new normal sample arrives and can adapt to slow change of cointegration relationship. Based on the long-term equilibrium information extracted by RCA, the remaining short-term dynamic information is monitored by recursive principal component analysis (RPCA). Thus a comprehensive monitoring framework is built. When the system enters a new operating condition, the RCA-RPCA model is rebuilt to deal with the new condition. Meanwhile, elastic weight consolidation (EWC) is employed to settle the `catastrophic forgetting' issue inherent in RPCA, where significant information of influential parameters is enhanced to avoid the abrupt performance degradation for similar modes. The effectiveness of the proposed method is illustrated by a practical industrial system.
Counterfactual Fairness with Disentangled Causal Effect Variational Autoencoder
Nov 24, 2020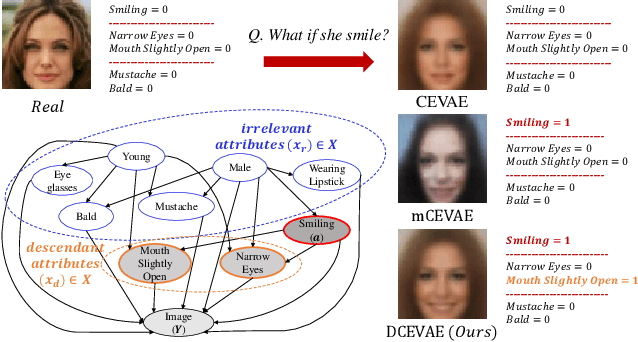
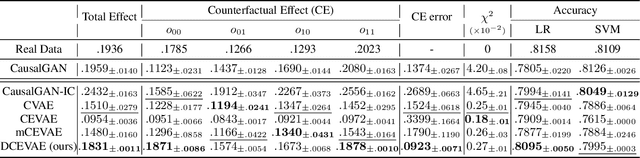
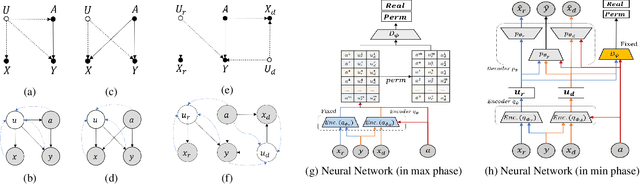
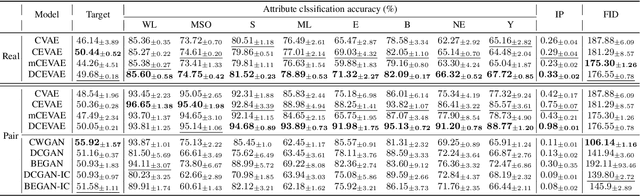
The problem of fair classification can be mollified if we develop a method to remove the embedded sensitive information from the classification features. This line of separating the sensitive information is developed through the causal inference, and the causal inference enables the counterfactual generations to contrast the what-if case of the opposite sensitive attribute. Along with this separation with the causality, a frequent assumption in the deep latent causal model defines a single latent variable to absorb the entire exogenous uncertainty of the causal graph. However, we claim that such structure cannot distinguish the 1) information caused by the intervention (i.e., sensitive variable) and 2) information correlated with the intervention from the data. Therefore, this paper proposes Disentangled Causal Effect Variational Autoencoder (DCEVAE) to resolve this limitation by disentangling the exogenous uncertainty into two latent variables: either 1) independent to interventions or 2) correlated to interventions without causality. Particularly, our disentangling approach preserves the latent variable correlated to interventions in generating counterfactual examples. We show that our method estimates the total effect and the counterfactual effect without a complete causal graph. By adding a fairness regularization, DCEVAE generates a counterfactual fair dataset while losing less original information. Also, DCEVAE generates natural counterfactual images by only flipping sensitive information. Additionally, we theoretically show the differences in the covariance structures of DCEVAE and prior works from the perspective of the latent disentanglement.