 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Fair Demand Models
Jun 05, 2026Data-driven pricing is increasingly prevalent in sectors such as airlines, lending, insurance, and retail. By learning demand models from customer features and setting prices accordingly, these systems may generate discriminatory outcomes that raise fairness concerns. This leads to fundamental questions - how and where should systems incorporate fairness considerations in the pricing pipeline, and how does it ultimately affect societal outcomes? To answer these, we study a stylized model where a seller has a two-stage decision pipeline comprising linear demand model estimation followed by price optimization. The seller considers fairness notions in training loss, price, and demand, under both parity-wise and Rawlsian perspectives. We show that equalizing training loss across consumer groups leads to multiple solutions, which in turn can result in undesirable outcomes despite being a standard approach in fair machine learning. Focusing instead on fairness applied directly to prices or demand, we compare two strategies that enforce fairness in either the demand estimation stage or the price optimization stage. For parity-wise fairness, we characterize when each strategy yields higher social welfare under small fairness levels. We show that when market sizes and prices in the dataset are similar, imposing price fairness in the estimation stage is more beneficial to consumers, whereas imposing demand fairness in the optimization stage yields better consumer outcomes. For Rawlsian fairness, the two strategies coincide exactly. Lastly, we extend our model to alternate demand functions and conduct a case study using real-world vaccine pricing data.
A study of audio mixing methods for piano transcription in violin-piano ensembles
May 23, 2023



While piano music transcription models have shown high performance for solo piano recordings, their performance degrades when applied to ensemble recordings. This study aims to analyze the impact of different data augmentation methods on piano transcription performance, specifically focusing on mixing techniques applied to violin-piano ensembles. We apply mixing methods that consider both harmonic and temporal characteristics of the audio. To create datasets for this study, we generated the PFVN-synth dataset, which contains 7 hours of violin-piano ensemble audio by rendering MIDI files and corresponding labels, and also collected unaccompanied violin recordings and mixed them with the MAESTRO dataset. We evaluated the transcription results on both synthesized and real audio recordings datasets.
Counterfactual Fairness with Disentangled Causal Effect Variational Autoencoder
Dec 09, 2020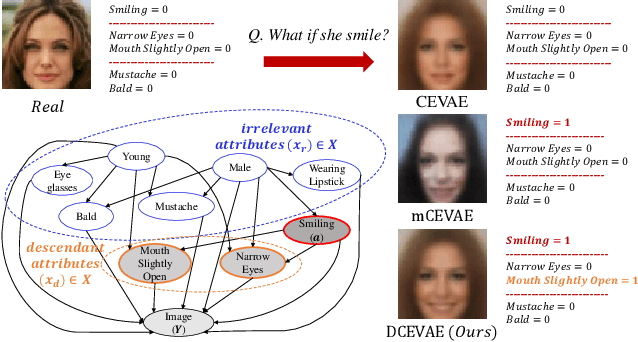
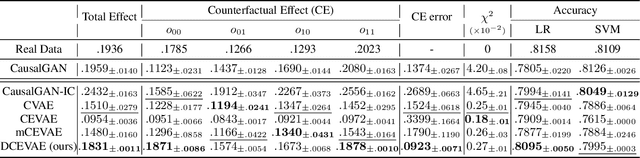
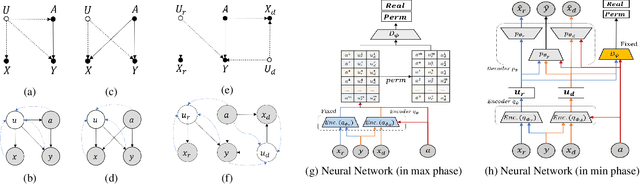
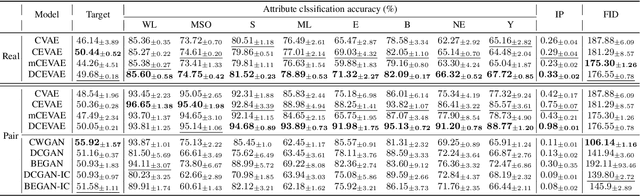
The problem of fair classification can be mollified if we develop a method to remove the embedded sensitive information from the classification features. This line of separating the sensitive information is developed through the causal inference, and the causal inference enables the counterfactual generations to contrast the what-if case of the opposite sensitive attribute. Along with this separation with the causality, a frequent assumption in the deep latent causal model defines a single latent variable to absorb the entire exogenous uncertainty of the causal graph. However, we claim that such structure cannot distinguish the 1) information caused by the intervention (i.e., sensitive variable) and 2) information correlated with the intervention from the data. Therefore, this paper proposes Disentangled Causal Effect Variational Autoencoder (DCEVAE) to resolve this limitation by disentangling the exogenous uncertainty into two latent variables: either 1) independent to interventions or 2) correlated to interventions without causality. Particularly, our disentangling approach preserves the latent variable correlated to interventions in generating counterfactual examples. We show that our method estimates the total effect and the counterfactual effect without a complete causal graph. By adding a fairness regularization, DCEVAE generates a counterfactual fair dataset while losing less original information. Also, DCEVAE generates natural counterfactual images by only flipping sensitive information. Additionally, we theoretically show the differences in the covariance structures of DCEVAE and prior works from the perspective of the latent disentanglement.
Neutralizing Gender Bias in Word Embedding with Latent Disentanglement and Counterfactual Generation
Apr 07, 2020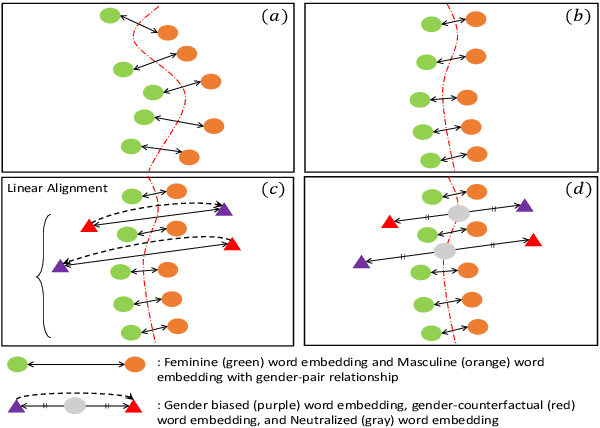
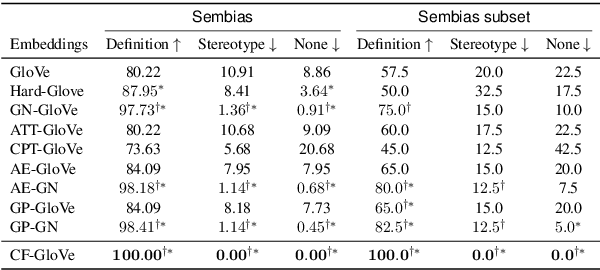
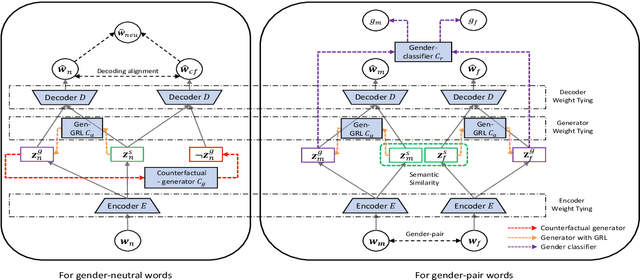
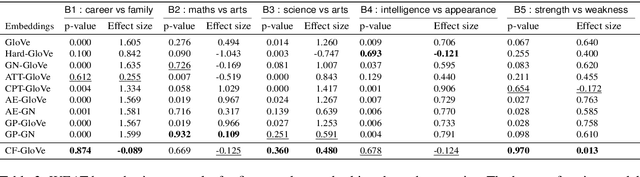
Recent researches demonstrate that word embeddings, trained on the human-generated corpus, have strong gender biases in embedding spaces, and these biases can result in the prejudiced results from the downstream tasks, i.e. sentiment analysis. Whereas the previous debiasing models project word embeddings into a linear subspace, we introduce a Latent Disentangling model with a siamese auto-encoder structure and a gradient reversal layer. Our siamese auto-encoder utilizes gender word pairs to disentangle semantics and gender information of given word, and the associated gradient reversal layer provides the negative gradient to distinguish the semantics from the gender. Afterwards, we introduce a Counterfactual Generation model to modify the gender information of words, so the original and the modified embeddings can produce a gender-neutralized word embedding after geometric alignment without loss of semantic information. Experimental results quantitatively and qualitatively indicate that the introduced method is better in debiasing word embeddings, and in minimizing the semantic information losses for NLP downstream tasks.