 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Behavioral Economics Approach to Interpretable Deep Image Classification. Rationally Inattentive Utility Maximization Explains Deep Image Classification
Feb 16, 2021
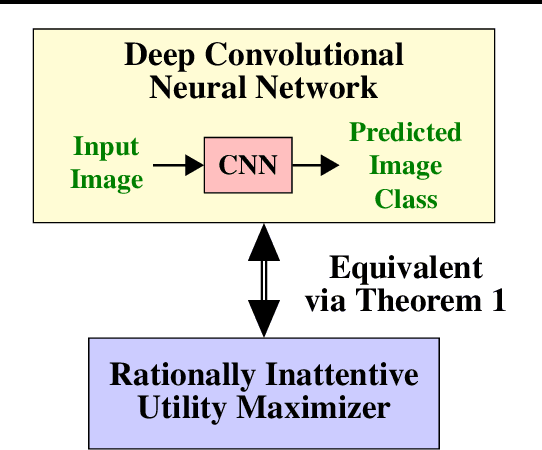

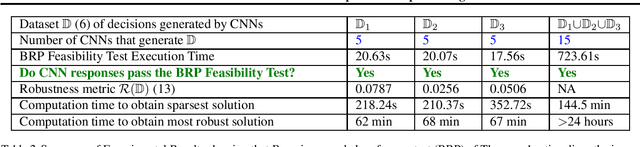
Are deep convolutional neural networks (CNNs) for image classification consistent with utility maximization behavior with information acquisition costs? This paper demonstrates the remarkable result that a deep CNN behaves equivalently (in terms of necessary and sufficient conditions) to a rationally inattentive utility maximizer, a model extensively used in behavioral economics to explain human decision making. This implies that a deep CNN has a parsimonious representation in terms of simple intuitive human-like decision parameters, namely, a utility function and an information acquisition cost. Also the reconstructed utility function that rationalizes the decisions of the deep CNNs, yields a useful preference order amongst the image classes (hypotheses).
An AutoML-based Approach to Multimodal Image Sentiment Analysis
Feb 16, 2021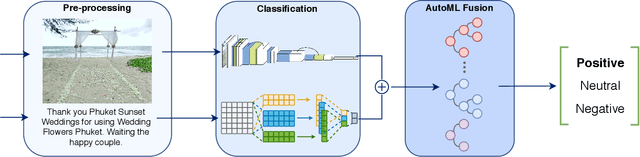

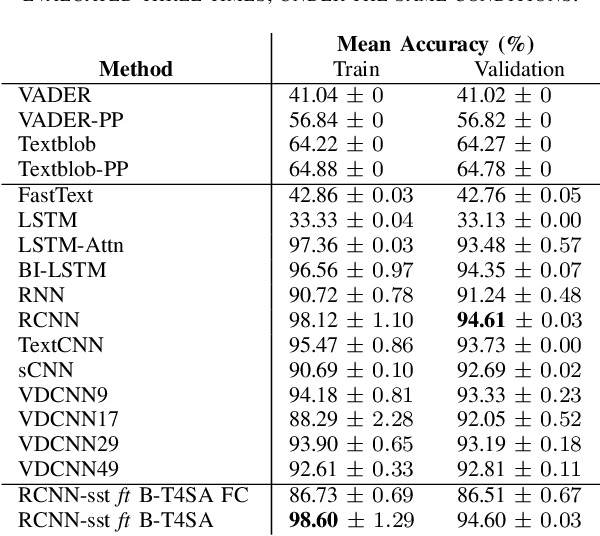
Sentiment analysis is a research topic focused on analysing data to extract information related to the sentiment that it causes. Applications of sentiment analysis are wide, ranging from recommendation systems, and marketing to customer satisfaction. Recent approaches evaluate textual content using Machine Learning techniques that are trained over large corpora. However, as social media grown, other data types emerged in large quantities, such as images. Sentiment analysis in images has shown to be a valuable complement to textual data since it enables the inference of the underlying message polarity by creating context and connections. Multimodal sentiment analysis approaches intend to leverage information of both textual and image content to perform an evaluation. Despite recent advances, current solutions still flounder in combining both image and textual information to classify social media data, mainly due to subjectivity, inter-class homogeneity and fusion data differences. In this paper, we propose a method that combines both textual and image individual sentiment analysis into a final fused classification based on AutoML, that performs a random search to find the best model. Our method achieved state-of-the-art performance in the B-T4SA dataset, with 95.19% accuracy.
Directed Acyclic Graph Network for Conversational Emotion Recognition
May 27, 2021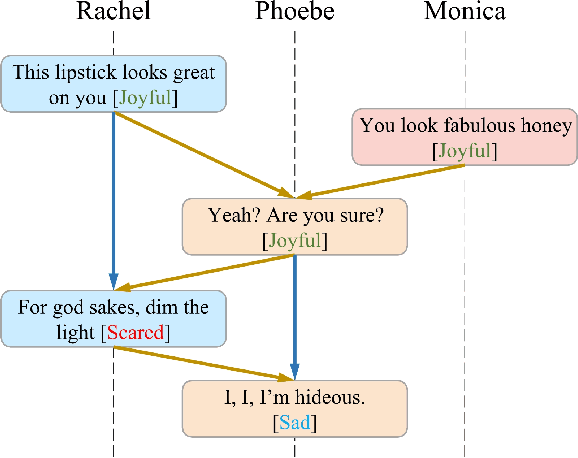
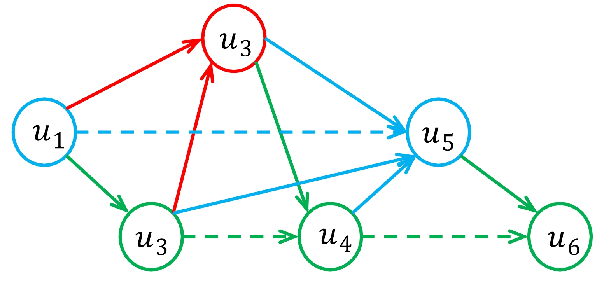
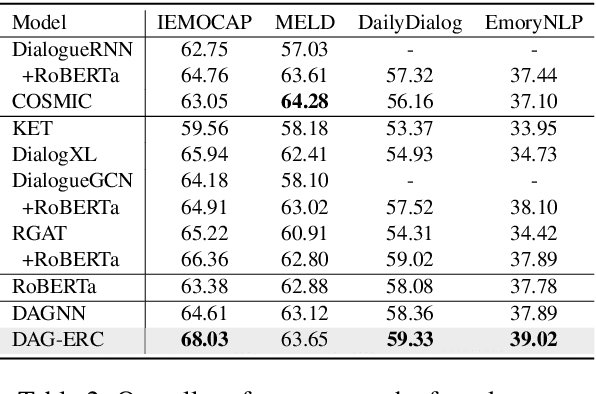
The modeling of conversational context plays a vital role in emotion recognition from conversation (ERC). In this paper, we put forward a novel idea of encoding the utterances with a directed acyclic graph (DAG) to better model the intrinsic structure within a conversation, and design a directed acyclic neural network,~namely DAG-ERC, to implement this idea.~In an attempt to combine the strengths of conventional graph-based neural models and recurrence-based neural models,~DAG-ERC provides a more intuitive way to model the information flow between long-distance conversation background and nearby context.~Extensive experiments are conducted on four ERC benchmarks with state-of-the-art models employed as baselines for comparison.~The empirical results demonstrate the superiority of this new model and confirm the motivation of the directed acyclic graph architecture for ERC.
An Efficient Cervical Whole Slide Image Analysis Framework Based on Multi-scale Semantic and Spatial Deep Features
Jul 03, 2021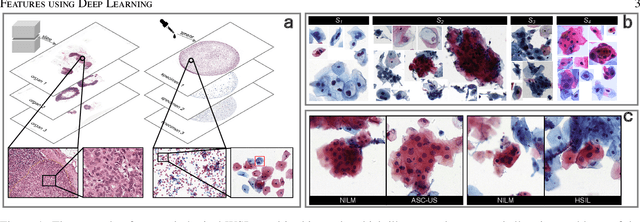
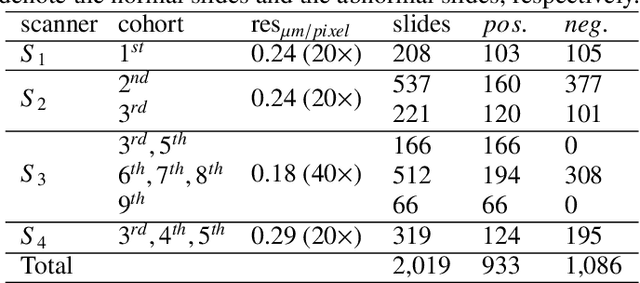
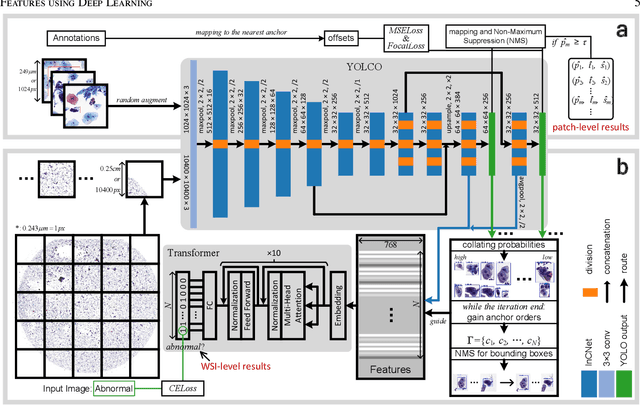
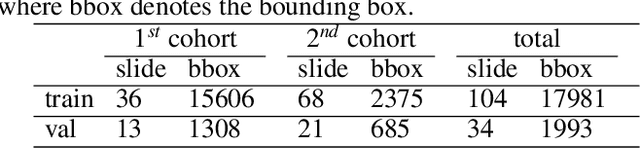
Digital gigapixel whole slide image (WSI) is widely used in clinical diagnosis, and automated WSI analysis is key for computer-aided diagnosis. Currently, analyzing the integrated descriptor of probabilities or feature maps from massive local patches encoded by ResNet classifier is the main manner for WSI-level prediction. Feature representations of the sparse and tiny lesion cells in cervical slides, however, are still challengeable for the under-promoted upstream encoders, while the unused spatial representations of cervical cells are the available features to supply the semantics analysis. As well as patches sampling with overlap and repetitive processing incur the inefficiency and the unpredictable side effect. This study designs a novel inline connection network (InCNet) by enriching the multi-scale connectivity to build the lightweight model named You Only Look Cytopathology Once (YOLCO) with the additional supervision of spatial information. The proposed model allows the input size enlarged to megapixel that can stitch the WSI without any overlap by the average repeats decreased from $10^3\sim10^4$ to $10^1\sim10^2$ for collecting features and predictions at two scales. Based on Transformer for classifying the integrated multi-scale multi-task features, the experimental results appear $0.872$ AUC score better and $2.51\times$ faster than the best conventional method in WSI classification on multicohort datasets of 2,019 slides from four scanning devices.
Active multi-fidelity Bayesian online changepoint detection
Mar 26, 2021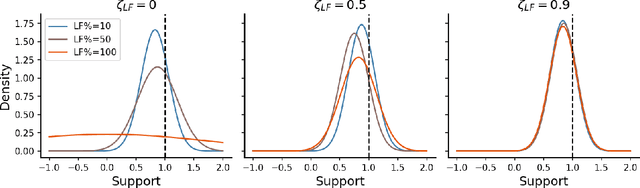
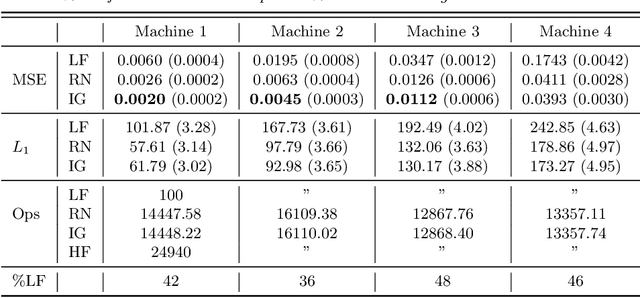
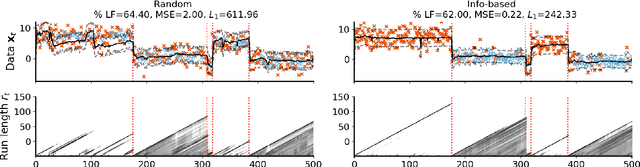
Online algorithms for detecting changepoints, or abrupt shifts in the behavior of a time series, are often deployed with limited resources, e.g., to edge computing settings such as mobile phones or industrial sensors. In these scenarios it may be beneficial to trade the cost of collecting an environmental measurement against the quality or "fidelity" of this measurement and how the measurement affects changepoint estimation. For instance, one might decide between inertial measurements or GPS to determine changepoints for motion. A Bayesian approach to changepoint detection is particularly appealing because we can represent our posterior uncertainty about changepoints and make active, cost-sensitive decisions about data fidelity to reduce this posterior uncertainty. Moreover, the total cost could be dramatically lowered through active fidelity switching, while remaining robust to changes in data distribution. We propose a multi-fidelity approach that makes cost-sensitive decisions about which data fidelity to collect based on maximizing information gain with respect to changepoints. We evaluate this framework on synthetic, video, and audio data and show that this information-based approach results in accurate predictions while reducing total cost.
Deep Contextual Bandits for Fast Neighbor-Aided Initial Access in mmWave Cell-Free Networks
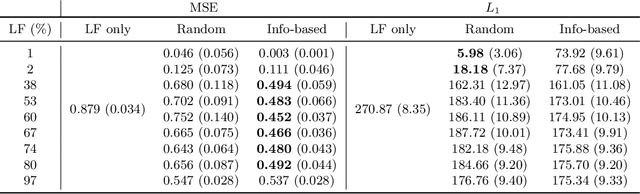
Mar 17, 2021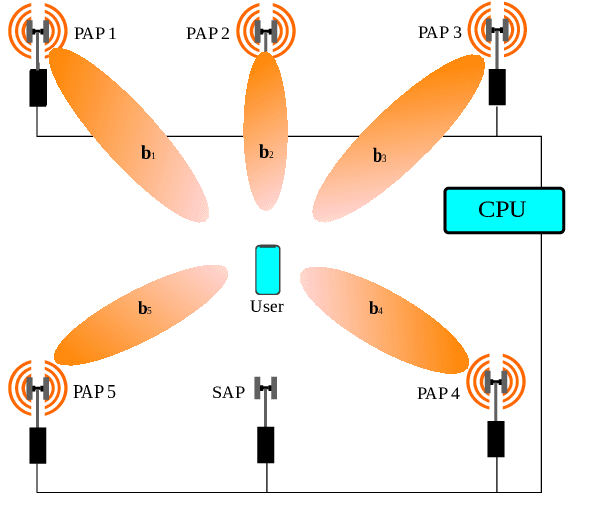
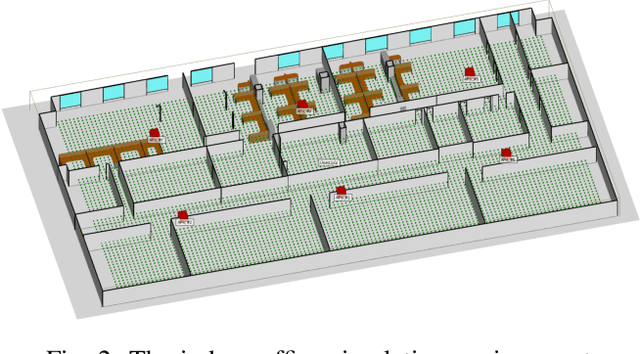
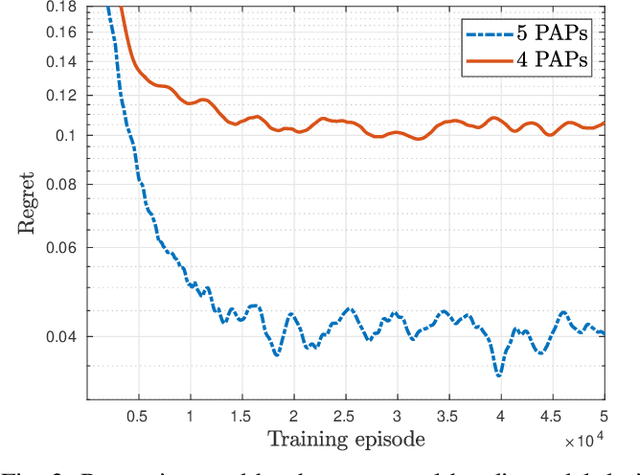
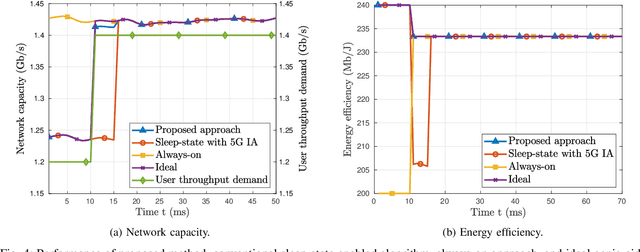
Access points (APs) in millimeter-wave (mmWave) and sub-THz-based user-centric (UC) networks will have sleep mode functionality. As a result of this, it becomes challenging to solve the initial access (IA) problem when the sleeping APs are activated to start serving users. In this paper, a novel deep contextual bandit (DCB) learning method is proposed to provide instant IA using information from the neighboring active APs. In the proposed approach, beam selection information from the neighboring active APs is used as an input to neural networks that act as a function approximator for the bandit algorithm. Simulations are carried out with realistic channel models generated using the Wireless Insight ray-tracing tool. The results show that the system can respond to dynamic throughput demands with negligible latency compared to the standard baseline 5G IA scheme. The proposed fast beam selection scheme can enable the network to use energy-saving sleep modes without compromising the quality of service due to inefficient IA
Evaluating Foveated Video Quality Using Entropic Differencing
Jun 12, 2021
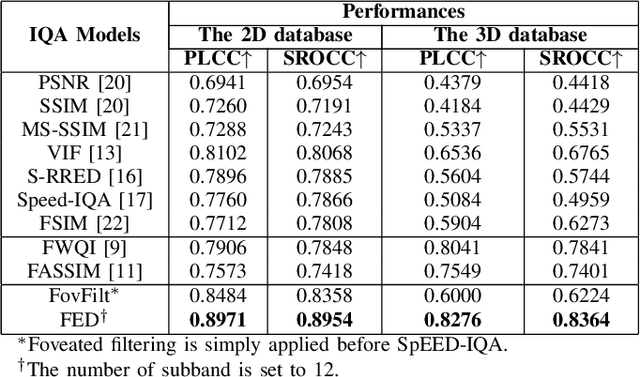
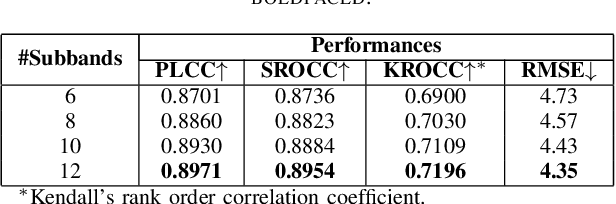
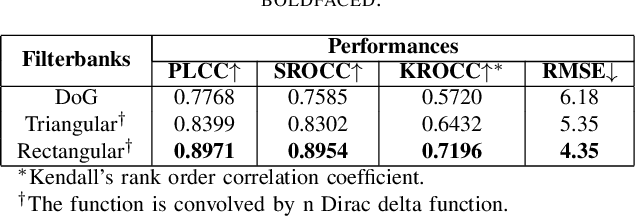
Virtual Reality is regaining attention due to recent advancements in hardware technology. Immersive images / videos are becoming widely adopted to carry omnidirectional visual information. However, due to the requirements for higher spatial and temporal resolution of real video data, immersive videos require significantly larger bandwidth consumption. To reduce stresses on bandwidth, foveated video compression is regaining popularity, whereby the space-variant spatial resolution of the retina is exploited. Towards advancing the progress of foveated video compression, we propose a full reference (FR) foveated image quality assessment algorithm, which we call foveated entropic differencing (FED), which employs the natural scene statistics of bandpass responses by applying differences of local entropies weighted by a foveation-based error sensitivity function. We evaluate the proposed algorithm by measuring the correlations of the predictions that FED makes against human judgements on the newly created 2D and 3D LIVE-FBT-FCVR databases for Virtual Reality (VR). The performance of the proposed algorithm yields state-of-the-art as compared with other existing full reference algorithms. Software for FED has been made available at: http://live.ece.utexas.edu/research/Quality/FED.zip
Beyond Short Clips: End-to-End Video-Level Learning with Collaborative Memories
Apr 02, 2021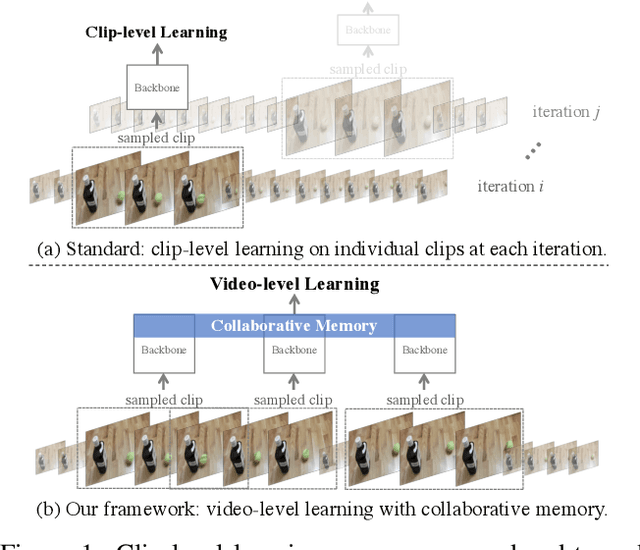
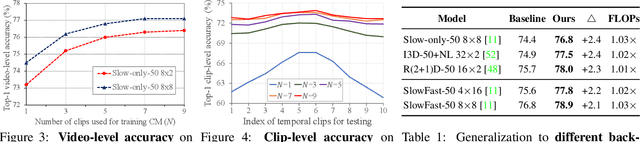
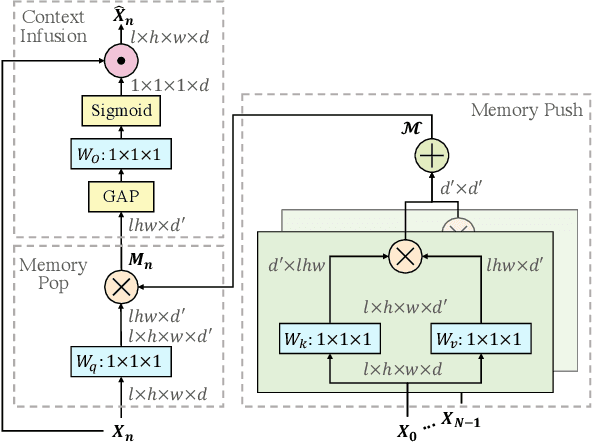
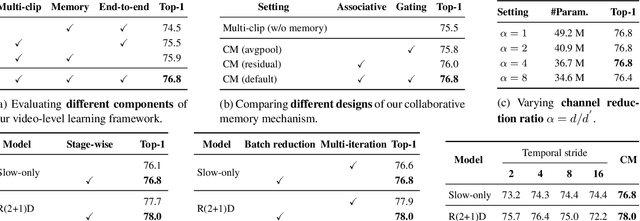
The standard way of training video models entails sampling at each iteration a single clip from a video and optimizing the clip prediction with respect to the video-level label. We argue that a single clip may not have enough temporal coverage to exhibit the label to recognize, since video datasets are often weakly labeled with categorical information but without dense temporal annotations. Furthermore, optimizing the model over brief clips impedes its ability to learn long-term temporal dependencies. To overcome these limitations, we introduce a collaborative memory mechanism that encodes information across multiple sampled clips of a video at each training iteration. This enables the learning of long-range dependencies beyond a single clip. We explore different design choices for the collaborative memory to ease the optimization difficulties. Our proposed framework is end-to-end trainable and significantly improves the accuracy of video classification at a negligible computational overhead. Through extensive experiments, we demonstrate that our framework generalizes to different video architectures and tasks, outperforming the state of the art on both action recognition (e.g., Kinetics-400 & 700, Charades, Something-Something-V1) and action detection (e.g., AVA v2.1 & v2.2).
Musical Prosody-Driven Emotion Classification: Interpreting Vocalists Portrayal of Emotions Through Machine Learning
Jun 04, 2021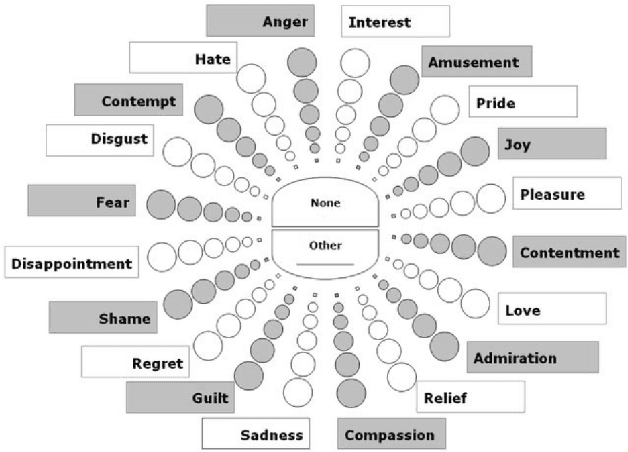
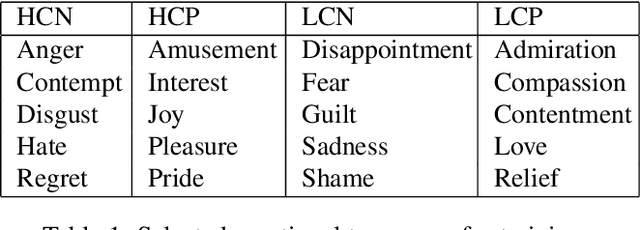
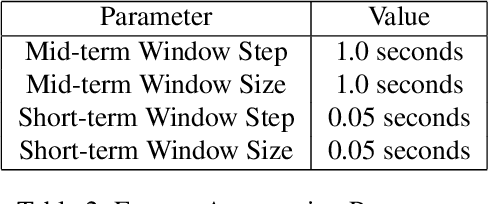
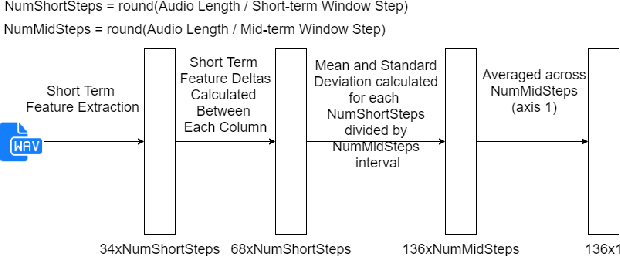
The task of classifying emotions within a musical track has received widespread attention within the Music Information Retrieval (MIR) community. Music emotion recognition has traditionally relied on the use of acoustic features, verbal features, and metadata-based filtering. The role of musical prosody remains under-explored despite several studies demonstrating a strong connection between prosody and emotion. In this study, we restrict the input of traditional machine learning algorithms to the features of musical prosody. Furthermore, our proposed approach builds upon the prior by classifying emotions under an expanded emotional taxonomy, using the Geneva Wheel of Emotion. We utilize a methodology for individual data collection from vocalists, and personal ground truth labeling by the artist themselves. We found that traditional machine learning algorithms when limited to the features of musical prosody (1) achieve high accuracies for a single singer, (2) maintain high accuracy when the dataset is expanded to multiple singers, and (3) achieve high accuracies when trained on a reduced subset of the total features.
Dynamic detection of mobile malware using smartphone data and machine learning
Jul 23, 2021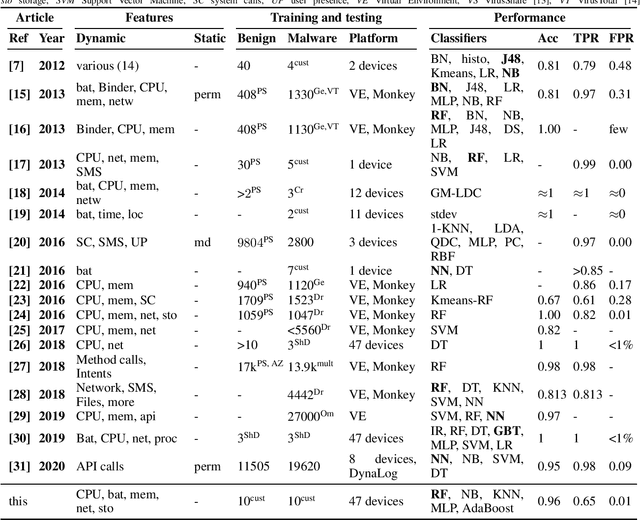
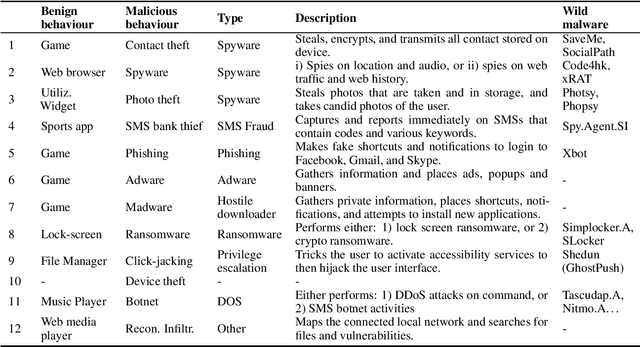
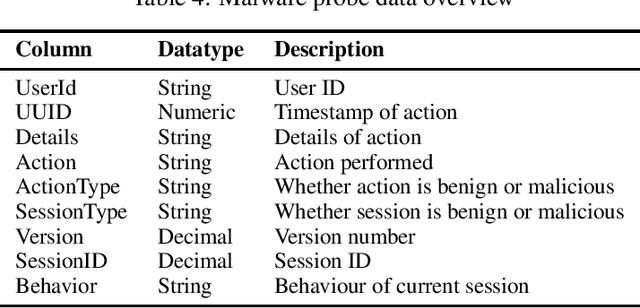
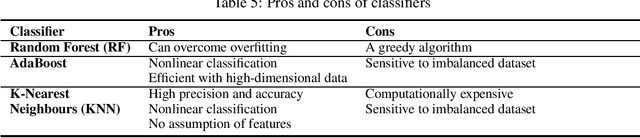
Mobile malware are malicious programs that target mobile devices. They are an increasing problem, as seen in the rise of detected mobile malware samples per year. The number of active smartphone users is expected to grow, stressing the importance of research on the detection of mobile malware. Detection methods for mobile malware exist but are still limited. In this paper, we provide an overview of the performance of machine learning (ML) techniques to detect malware on Android, without using privileged access. The ML-classifiers use device information such as the CPU usage, battery usage, and memory usage for the detection of 10 subtypes of Mobile Trojans on the Android Operating System (OS). We use a real-life dataset containing device and malware data from 47 users for a year (2016). We examine which features, i.e. aspects, of a device, are most important to monitor to detect (subtypes of) Mobile Trojans. The focus of this paper is on dynamic hardware features. Using these dynamic features we apply state-of-the-art machine learning classifiers: Random Forest, K-Nearest Neighbour, and AdaBoost. We show classification results on different feature sets, making a distinction between global device features, and specific app features. None of the measured feature sets require privileged access. Our results show that the Random Forest classifier performs best as a general malware classifier: across 10 subtypes of Mobile Trojans, it achieves an F1 score of 0.73 with a False Positive Rate (FPR) of 0.009 and a False Negative Rate (FNR) of 0.380. The Random Forest, K-Nearest Neighbours, and AdaBoost classifiers achieve F1 scores above 0.72, an FPR below 0.02 and, an FNR below 0.33, when trained separately to detect each subtype of Mobile Trojans.