 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Knowledge-Rich BERT Embeddings for Readability Assessment
Jun 15, 2021
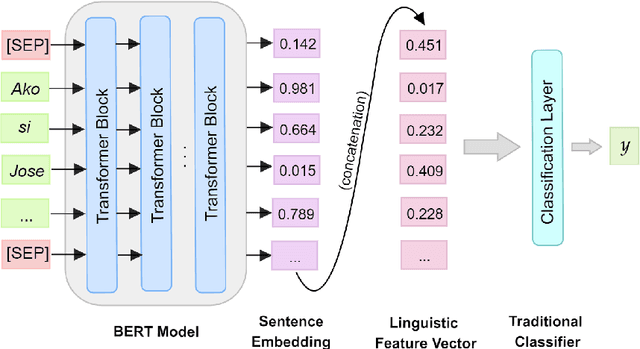
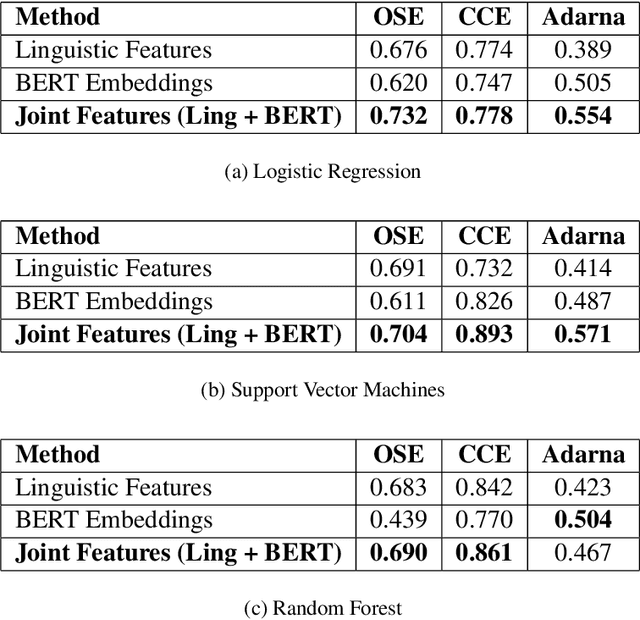

Automatic readability assessment (ARA) is the task of evaluating the level of ease or difficulty of text documents for a target audience. For researchers, one of the many open problems in the field is to make such models trained for the task show efficacy even for low-resource languages. In this study, we propose an alternative way of utilizing the information-rich embeddings of BERT models through a joint-learning method combined with handcrafted linguistic features for readability assessment. Results show that the proposed method outperforms classical approaches in readability assessment using English and Filipino datasets, and obtaining as high as 12.4% increase in F1 performance. We also show that the knowledge encoded in BERT embeddings can be used as a substitute feature set for low-resource languages like Filipino with limited semantic and syntactic NLP tools to explicitly extract feature values for the task.
Correlation Filter of 2D Laser Scans For Indoor Environment
May 27, 2021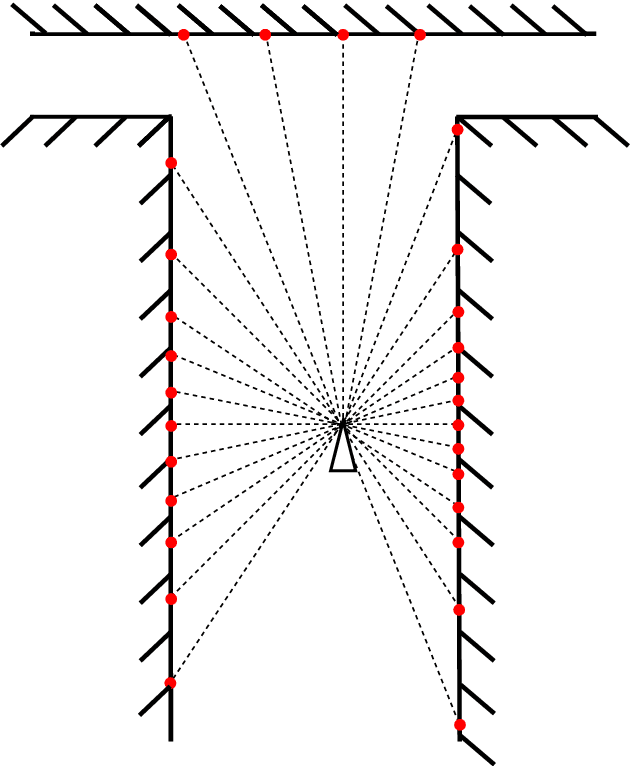
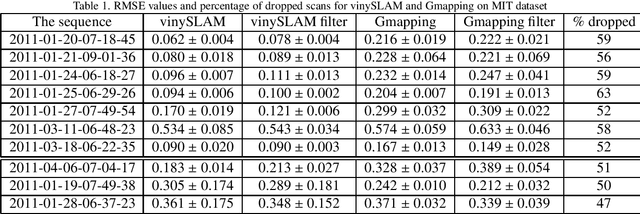
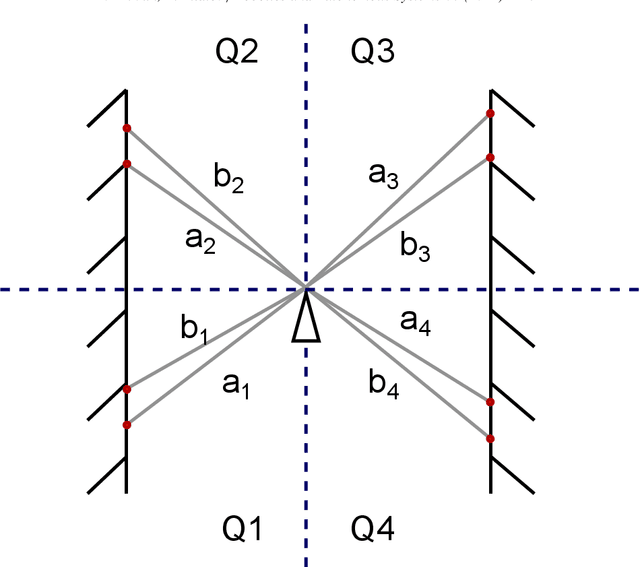
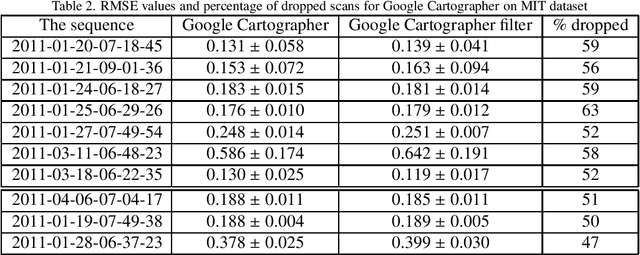
Modern laser SLAM (simultaneous localization and mapping) and structure from motion algorithms face the problem of processing redundant data. Even if a sensor does not move, it still continues to capture scans that should be processed. This paper presents the novel filter that allows dropping 2D scans that bring no new information to the system. Experiments on MIT and TUM datasets show that it is possible to drop more than half of the scans. Moreover thepaper describes the formulas that enable filter adaptation to a particular robot with known speed and characteristics of lidar. In addition, the indoor corridor detector is introduced that also can be applied to any specific shape of a corridor and sensor.
Exploiting Class Similarity for Machine Learning with Confidence Labels and Projective Loss Functions
Mar 25, 2021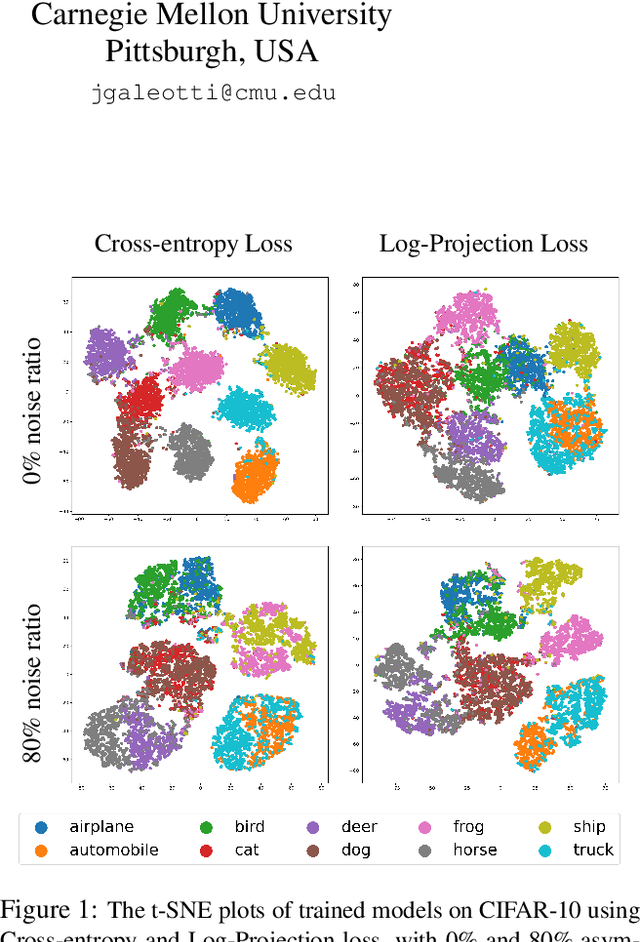
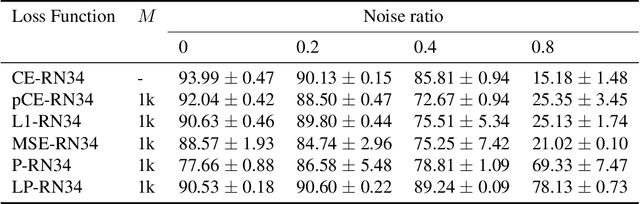
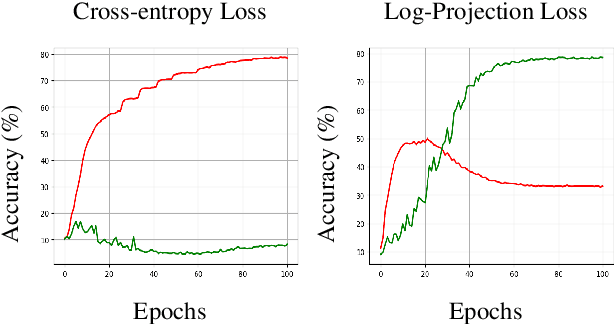
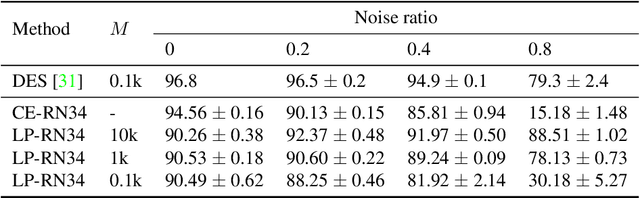
Class labels used for machine learning are relatable to each other, with certain class labels being more similar to each other than others (e.g. images of cats and dogs are more similar to each other than those of cats and cars). Such similarity among classes is often the cause of poor model performance due to the models confusing between them. Current labeling techniques fail to explicitly capture such similarity information. In this paper, we instead exploit the similarity between classes by capturing the similarity information with our novel confidence labels. Confidence labels are probabilistic labels denoting the likelihood of similarity, or confusability, between the classes. Often even after models are trained to differentiate between classes in the feature space, the similar classes' latent space still remains clustered. We view this type of clustering as valuable information and exploit it with our novel projective loss functions. Our projective loss functions are designed to work with confidence labels with an ability to relax the loss penalty for errors that confuse similar classes. We use our approach to train neural networks with noisy labels, as we believe noisy labels are partly a result of confusability arising from class similarity. We show improved performance compared to the use of standard loss functions. We conduct a detailed analysis using the CIFAR-10 dataset and show our proposed methods' applicability to larger datasets, such as ImageNet and Food-101N.
Generating Artificial Core Users for Interpretable Condensed Data
Feb 06, 2021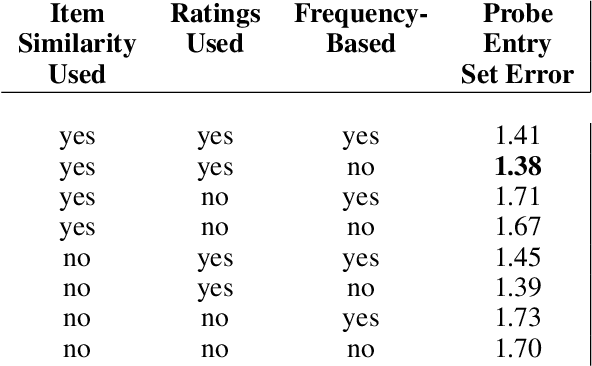
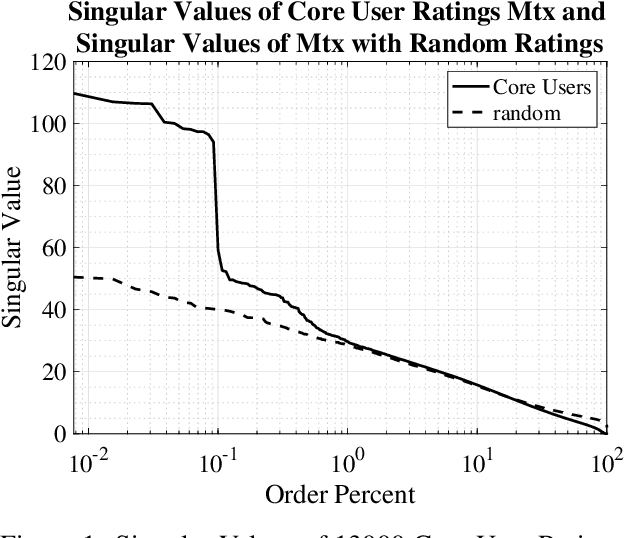
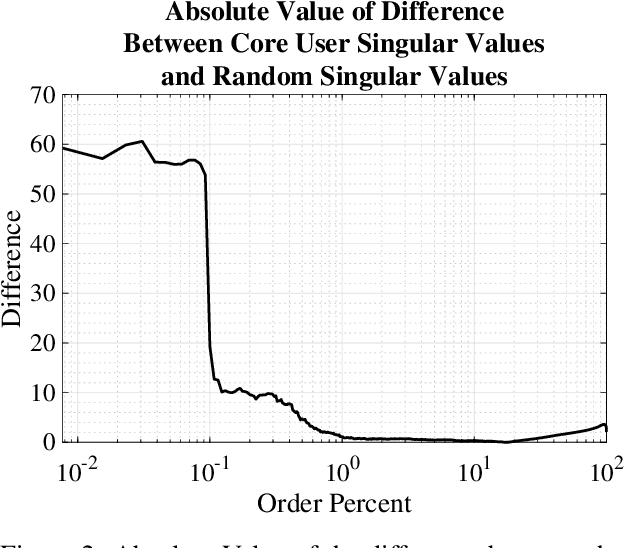
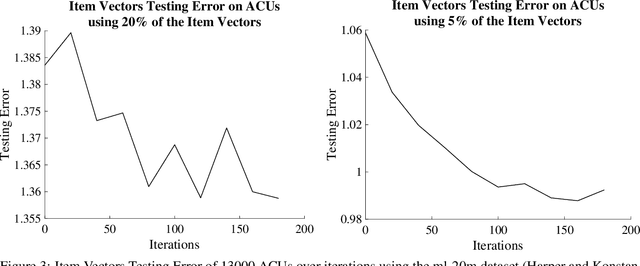
Recent work has shown that in a dataset of user ratings on items there exists a group of Core Users who hold most of the information necessary for recommendation. This set of Core Users can be as small as 20 percent of the users. Core Users can be used to make predictions for out-of-sample users without much additional work. Since Core Users substantially shrink a ratings dataset without much loss of information, they can be used to improve recommendation efficiency. We propose a method, combining latent factor models, ensemble boosting and K-means clustering, to generate a small set of Artificial Core Users (ACUs) from real Core User data. Our ACUs have dense rating information, and improve the recommendation performance of real Core Users while remaining interpretable.
Knowledge Graph Completion with Text-aided Regularization
Jan 22, 2021

Knowledge Graph Completion is a task of expanding the knowledge graph/base through estimating possible entities, or proper nouns, that can be connected using a set of predefined relations, or verb/predicates describing interconnections of two things. Generally, we describe this problem as adding new edges to a current network of vertices and edges. Traditional approaches mainly focus on using the existing graphical information that is intrinsic of the graph and train the corresponding embeddings to describe the information; however, we think that the corpus that are related to the entities should also contain information that can positively influence the embeddings to better make predictions. In our project, we try numerous ways of using extracted or raw textual information to help existing KG embedding frameworks reach better prediction results, in the means of adding a similarity function to the regularization part in the loss function. Results have shown that we have made decent improvements over baseline KG embedding methods.
Entities of Interest
Feb 22, 2021
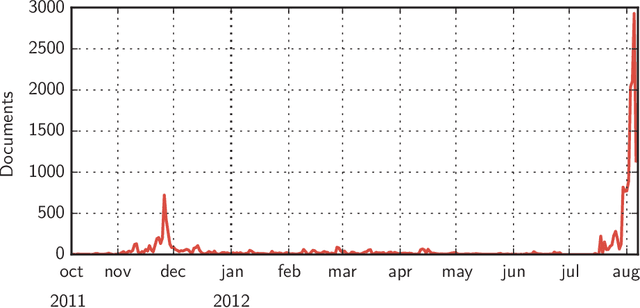
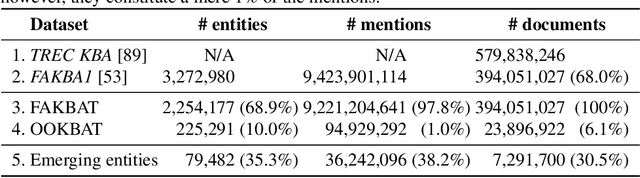
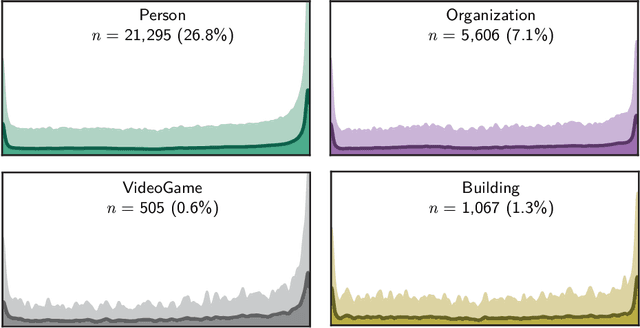
In the era of big data, we continuously - and at times unknowingly - leave behind digital traces, by browsing, sharing, posting, liking, searching, watching, and listening to online content. When aggregated, these digital traces can provide powerful insights into the behavior, preferences, activities, and traits of people. While many have raised privacy concerns around the use of aggregated digital traces, it has undisputedly brought us many advances, from the search engines that learn from their users and enable our access to unforeseen amounts of data, knowledge, and information, to, e.g., the discovery of previously unknown adverse drug reactions from search engine logs. Whether in online services, journalism, digital forensics, law, or research, we increasingly set out to exploring large amounts of digital traces to discover new information. Consider for instance, the Enron scandal, Hillary Clinton's email controversy, or the Panama papers: cases that revolve around analyzing, searching, investigating, exploring, and turning upside down large amounts of digital traces to gain new insights, knowledge, and information. This discovery task is at its core about "finding evidence of activity in the real world." This dissertation revolves around discovery in digital traces, and sits at the intersection of Information Retrieval, Natural Language Processing, and applied Machine Learning. We propose computational methods that aim to support the exploration and sense-making process of large collections of digital traces. We focus on textual traces, e.g., emails and social media streams, and address two aspects that are central to discovery in digital traces.
Transforming India's Agricultural Sector using Ontology-based Tantra Framework
Jan 26, 2021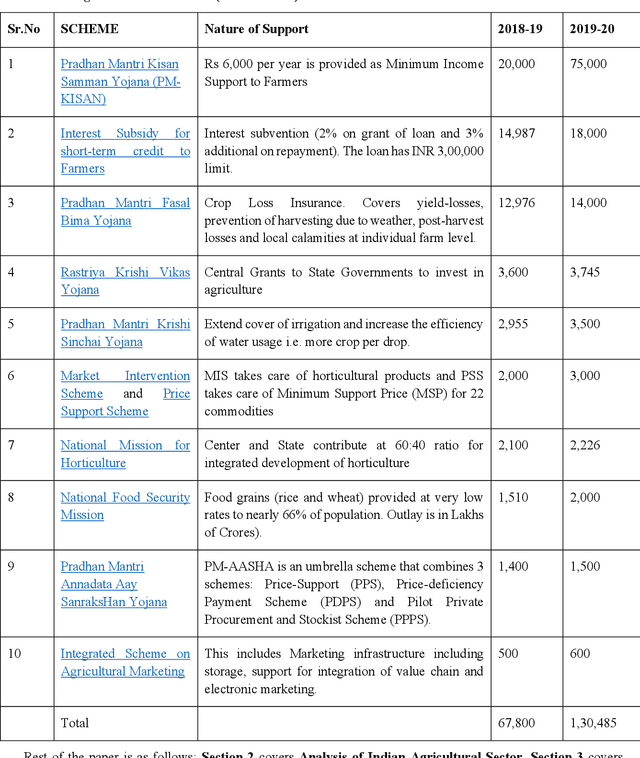
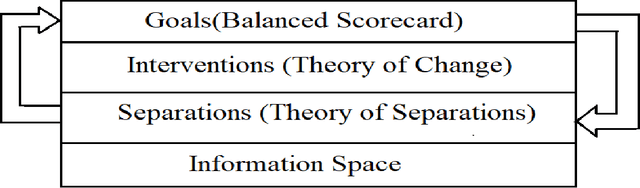
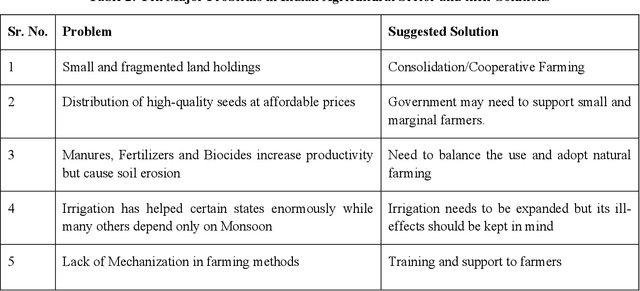
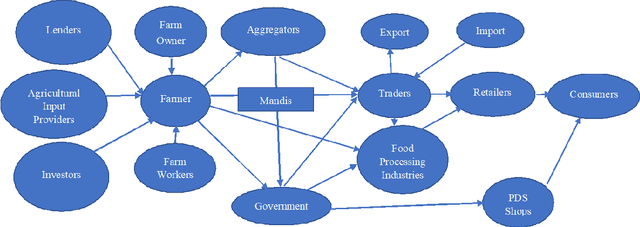
Food production is a critical activity in which every nation would like to be self-sufficient. India is one of the largest producers of food grains in the world. In India, nearly 70 percent of rural households still depend on agriculture for their livelihood. Keeping farmers happy is particularly important in India as farmers form a large vote bank which politicians dare not disappoint. At the same time, Governments need to balance the interest of farmers with consumers, intermediaries and society at large. The whole agriculture sector is highly information-intensive. Even with enormous collection of data and statistics from different arms of Government, there continue to be information gaps. In this paper we look at how Tantra Social Information Management Framework can help analyze the agricultural sector and transform the same using a holistic approach. Advantage of Tantra Framework approach is that it looks at societal information as a whole without limiting it to only the sector at hand. Tantra Framework makes use of concepts from Zachman Framework to manage aspects of social information through different perspectives and concepts from Unified Foundational Ontology (UFO) to represent interrelationships between aspects. Further, Tantra Framework interoperates with models such as Balanced Scorecard, Theory of Change and Theory of Separations. Finally, we model Indian Agricultural Sector as a business ecosystem and look at approaches to steer transformation from within.
Deep Dialog Act Recognition using Multiple Token, Segment, and Context Information Representations
Jul 23, 2018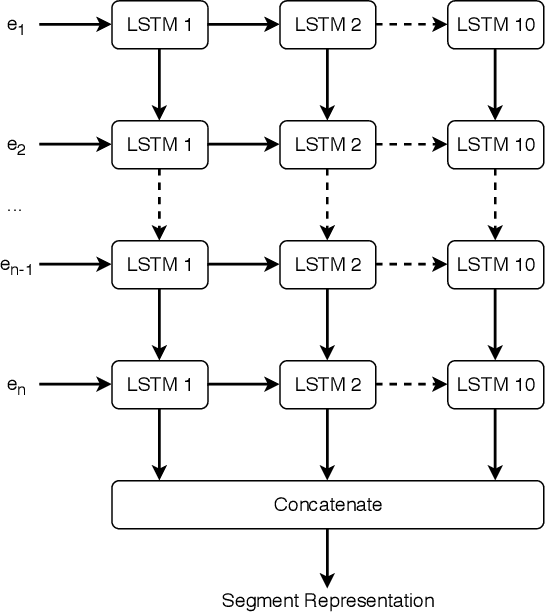
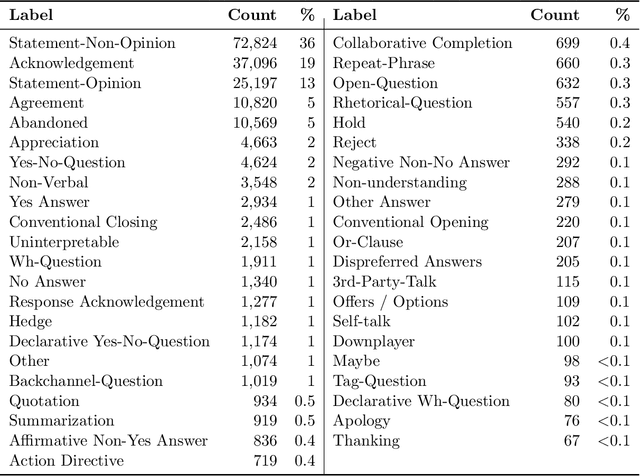
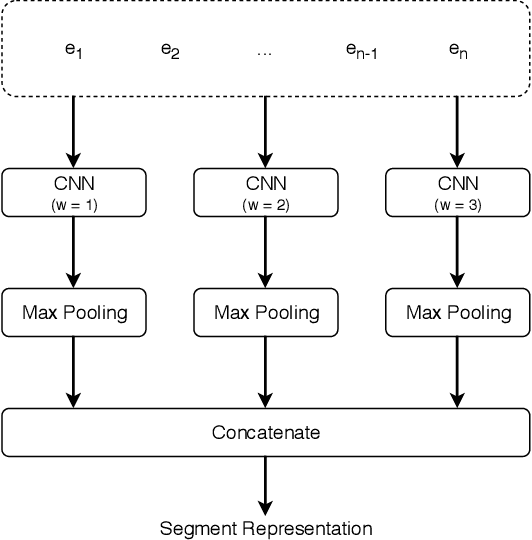
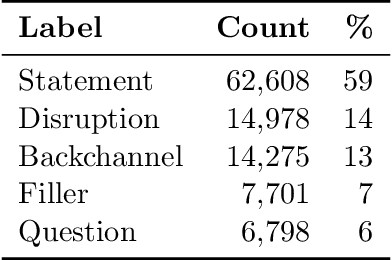
A dialog act is a representation of an intention transmitted in the form of words. In this sense, when someone wants to transmit some intention, it is revealed both in the selected words and in how they are combined to form a structured segment. Furthermore, the intentions of a speaker depend not only on her intrinsic motivation, but also on the history of the dialog and the expectation she has of its future. In this article we explore multiple representation approaches to capture cues for intention at different levels. Recent approaches on automatic dialog act recognition use Word2Vec embeddings for word representation. However, these are not able to capture segment structure information nor morphological traits related to intention. Thus, we also explore the use of dependency-based word embeddings, as well as character-level tokenization. To generate the segment representation, the top performing approaches on the task use either RNNs that are able to capture information concerning the sequentiality of the tokens or CNNs that are able to capture token patterns that reveal function. However, both aspects are important and should be captured together. Thus, we also explore the use of an RCNN. Finally, context information concerning turn-taking, as well as that provided by the surrounding segments has been proved important in previous studies. However, the representation approaches used for the latter in those studies are not appropriate to capture sequentiality, which is one of the most important characteristics of the segments in a dialog. Thus, we explore the use of approaches able to capture that information. By combining the best approaches for each aspect, we achieve results that surpass the previous state-of-the-art in a dialog system context and similar to human-level in an annotation context on the Switchboard Dialog Act Corpus, which is the most explored corpus for the task.
Cross-Modal Transformer-Based Neural Correction Models for Automatic Speech Recognition
Jul 04, 2021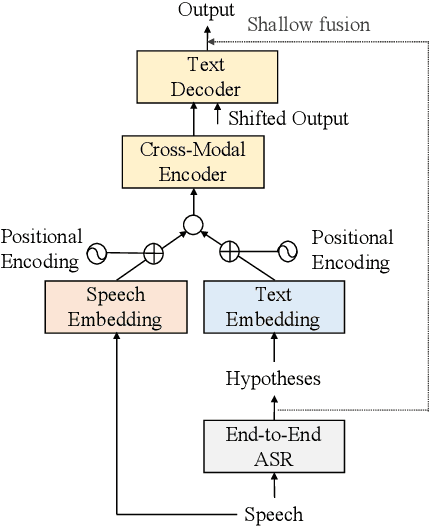
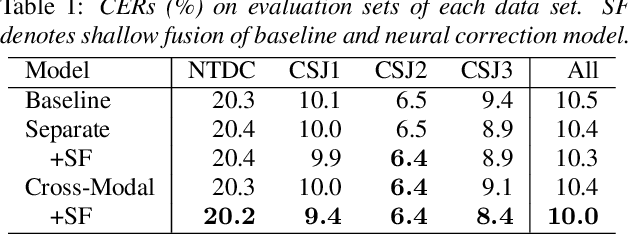
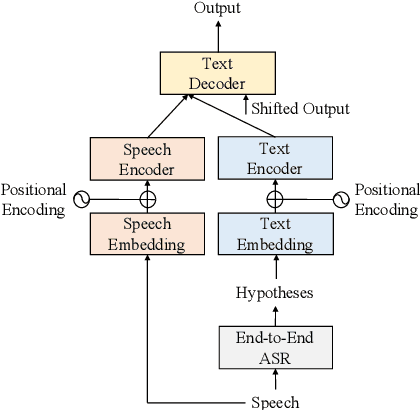
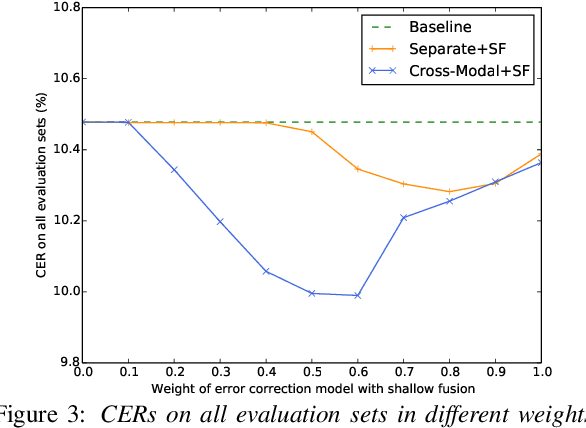
We propose a cross-modal transformer-based neural correction models that refines the output of an automatic speech recognition (ASR) system so as to exclude ASR errors. Generally, neural correction models are composed of encoder-decoder networks, which can directly model sequence-to-sequence mapping problems. The most successful method is to use both input speech and its ASR output text as the input contexts for the encoder-decoder networks. However, the conventional method cannot take into account the relationships between these two different modal inputs because the input contexts are separately encoded for each modal. To effectively leverage the correlated information between the two different modal inputs, our proposed models encode two different contexts jointly on the basis of cross-modal self-attention using a transformer. We expect that cross-modal self-attention can effectively capture the relationships between two different modals for refining ASR hypotheses. We also introduce a shallow fusion technique to efficiently integrate the first-pass ASR model and our proposed neural correction model. Experiments on Japanese natural language ASR tasks demonstrated that our proposed models achieve better ASR performance than conventional neural correction models.
SADRNet: Self-Aligned Dual Face Regression Networks for Robust 3D Dense Face Alignment and Reconstruction
Jun 06, 2021
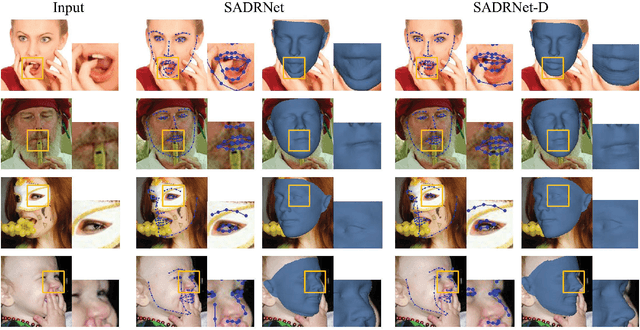

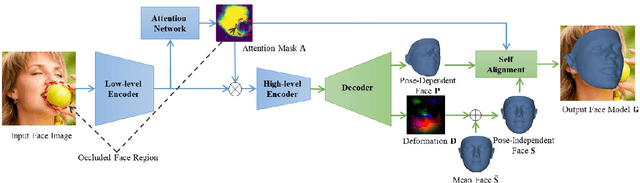
Three-dimensional face dense alignment and reconstruction in the wild is a challenging problem as partial facial information is commonly missing in occluded and large pose face images. Large head pose variations also increase the solution space and make the modeling more difficult. Our key idea is to model occlusion and pose to decompose this challenging task into several relatively more manageable subtasks. To this end, we propose an end-to-end framework, termed as Self-aligned Dual face Regression Network (SADRNet), which predicts a pose-dependent face, a pose-independent face. They are combined by an occlusion-aware self-alignment to generate the final 3D face. Extensive experiments on two popular benchmarks, AFLW2000-3D and Florence, demonstrate that the proposed method achieves significant superior performance over existing state-of-the-art methods.