 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep learning for surrogate modelling of 2D mantle convection
Aug 23, 2021
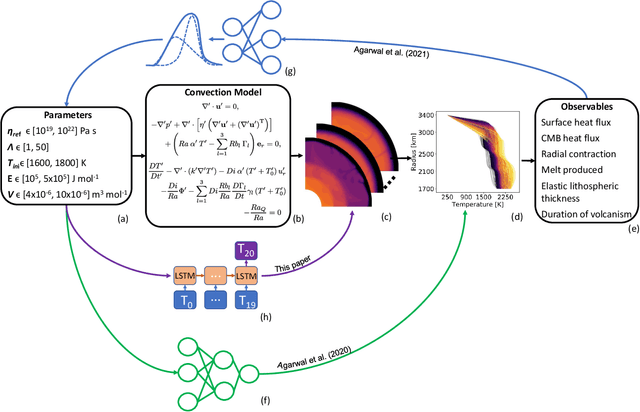
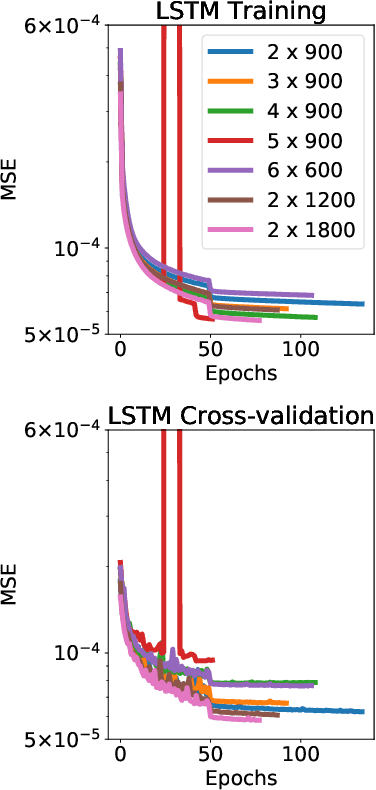
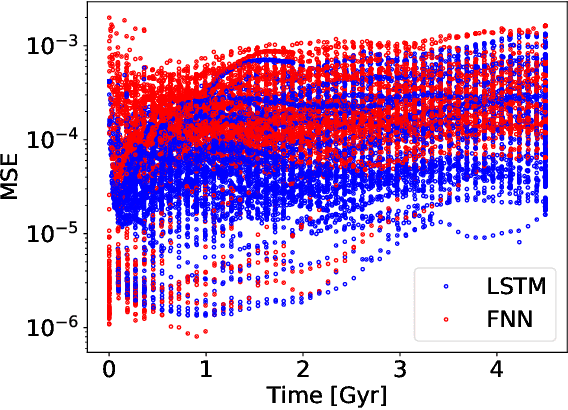
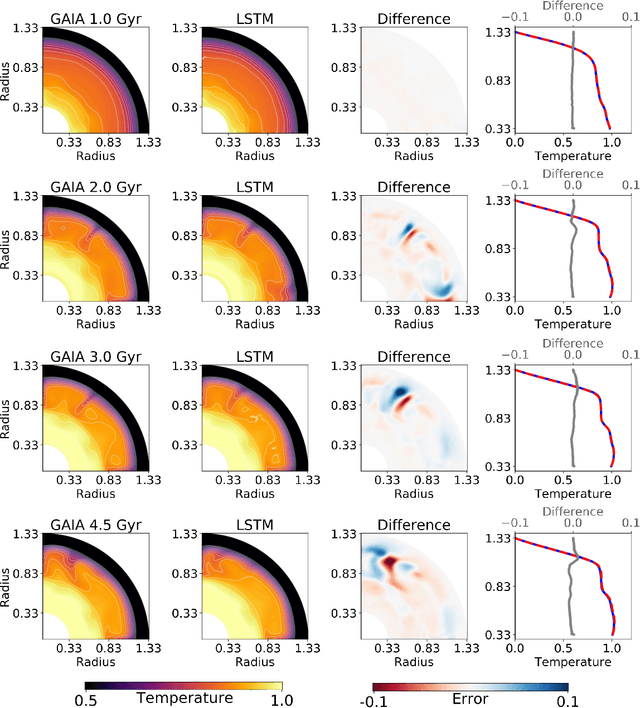
Traditionally, 1D models based on scaling laws have been used to parameterized convective heat transfer rocks in the interior of terrestrial planets like Earth, Mars, Mercury and Venus to tackle the computational bottleneck of high-fidelity forward runs in 2D or 3D. However, these are limited in the amount of physics they can model (e.g. depth dependent material properties) and predict only mean quantities such as the mean mantle temperature. We recently showed that feedforward neural networks (FNN) trained using a large number of 2D simulations can overcome this limitation and reliably predict the evolution of entire 1D laterally-averaged temperature profile in time for complex models [Agarwal et al. 2020]. We now extend that approach to predict the full 2D temperature field, which contains more information in the form of convection structures such as hot plumes and cold downwellings. Using a dataset of 10,525 two-dimensional simulations of the thermal evolution of the mantle of a Mars-like planet, we show that deep learning techniques can produce reliable parameterized surrogates (i.e. surrogates that predict state variables such as temperature based only on parameters) of the underlying partial differential equations. We first use convolutional autoencoders to compress the temperature fields by a factor of 142 and then use FNN and long-short term memory networks (LSTM) to predict the compressed fields. On average, the FNN predictions are 99.30% and the LSTM predictions are 99.22% accurate with respect to unseen simulations. Proper orthogonal decomposition (POD) of the LSTM and FNN predictions shows that despite a lower mean absolute relative accuracy, LSTMs capture the flow dynamics better than FNNs. When summed, the POD coefficients from FNN predictions and from LSTM predictions amount to 96.51% and 97.66% relative to the coefficients of the original simulations, respectively.
Innovations Autoencoder and its Application in One-class Anomalous Sequence Detection
Jul 15, 2021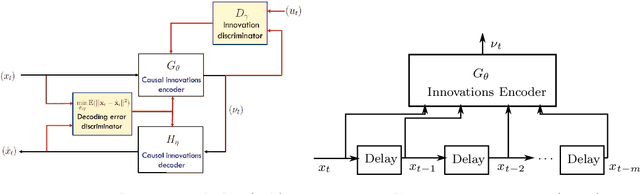


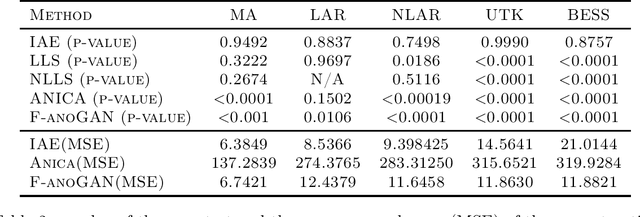
An innovations sequence of a time series is a sequence of independent and identically distributed random variables with which the original time series has a causal representation. The innovation at a time is statistically independent of the history of the time series. As such, it represents the new information contained at present but not in the past. Because of its simple probability structure, an innovations sequence is the most efficient signature of the original. Unlike the principle or independent component analysis representations, an innovations sequence preserves not only the complete statistical properties but also the temporal order of the original time series. An long-standing open problem is to find a computationally tractable way to extract an innovations sequence of non-Gaussian processes. This paper presents a deep learning approach, referred to as Innovations Autoencoder (IAE), that extracts innovations sequences using a causal convolutional neural network. An application of IAE to the one-class anomalous sequence detection problem with unknown anomaly and anomaly-free models is also presented.
Selective Pseudo-label Clustering
Jul 22, 2021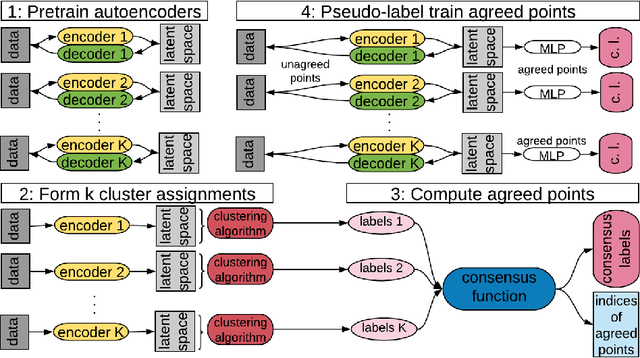
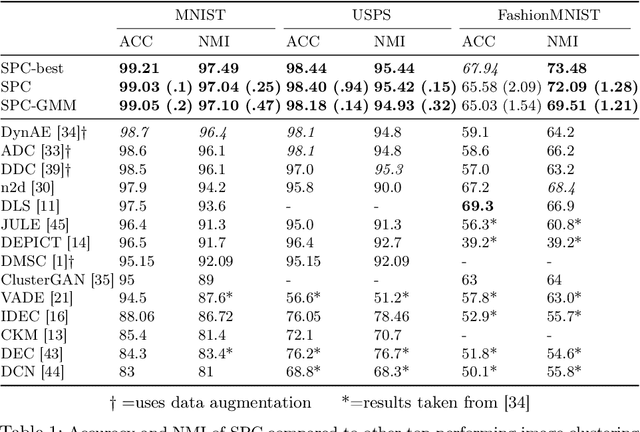
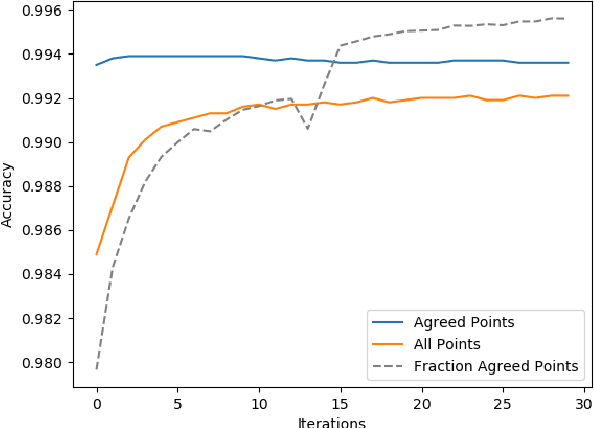
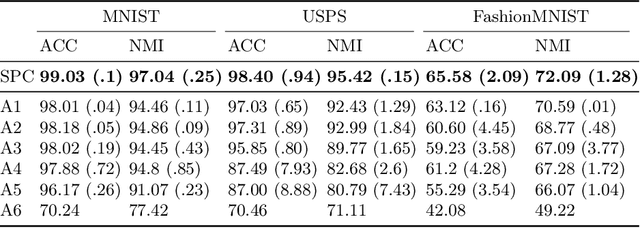
Deep neural networks (DNNs) offer a means of addressing the challenging task of clustering high-dimensional data. DNNs can extract useful features, and so produce a lower dimensional representation, which is more amenable to clustering techniques. As clustering is typically performed in a purely unsupervised setting, where no training labels are available, the question then arises as to how the DNN feature extractor can be trained. The most accurate existing approaches combine the training of the DNN with the clustering objective, so that information from the clustering process can be used to update the DNN to produce better features for clustering. One problem with this approach is that these ``pseudo-labels'' produced by the clustering algorithm are noisy, and any errors that they contain will hurt the training of the DNN. In this paper, we propose selective pseudo-label clustering, which uses only the most confident pseudo-labels for training the~DNN. We formally prove the performance gains under certain conditions. Applied to the task of image clustering, the new approach achieves a state-of-the-art performance on three popular image datasets. Code is available at https://github.com/Lou1sM/clustering.
Attentional Graph Neural Network for Parking-slot Detection
Apr 06, 2021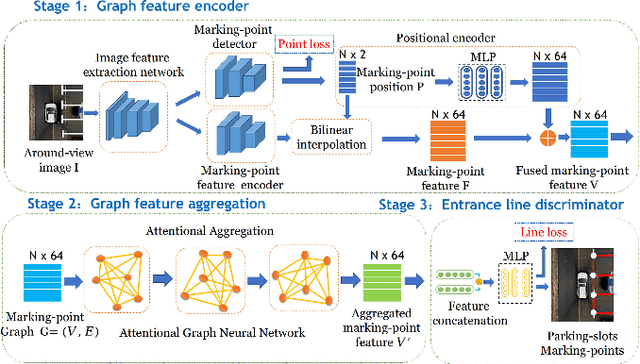
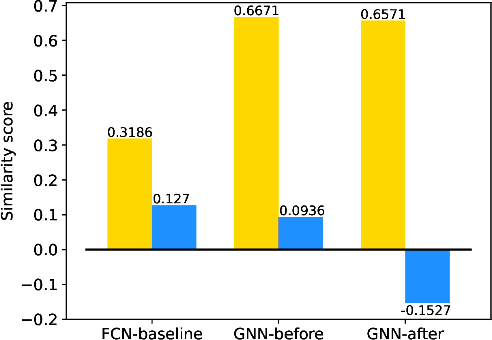

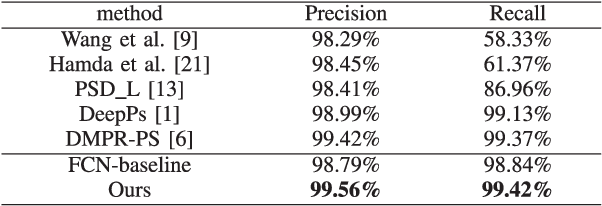
Deep learning has recently demonstrated its promising performance for vision-based parking-slot detection. However, very few existing methods explicitly take into account learning the link information of the marking-points, resulting in complex post-processing and erroneous detection. In this paper, we propose an attentional graph neural network based parking-slot detection method, which refers the marking-points in an around-view image as graph-structured data and utilize graph neural network to aggregate the neighboring information between marking-points. Without any manually designed post-processing, the proposed method is end-to-end trainable. Extensive experiments have been conducted on public benchmark dataset, where the proposed method achieves state-of-the-art accuracy. Code is publicly available at \url{https://github.com/Jiaolong/gcn-parking-slot}.
* Accepted by RAL
Majorization Minimization Methods for Distributed Pose Graph Optimization
Aug 03, 2021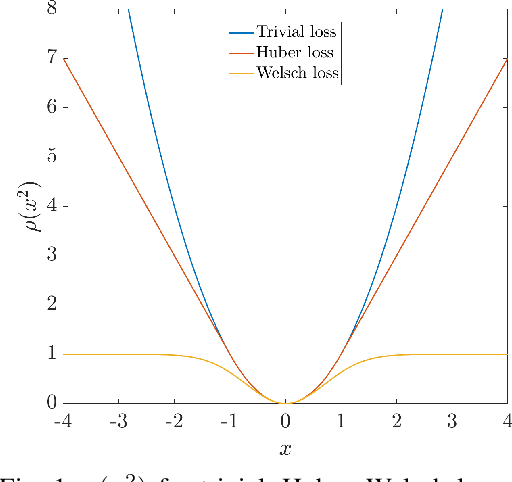
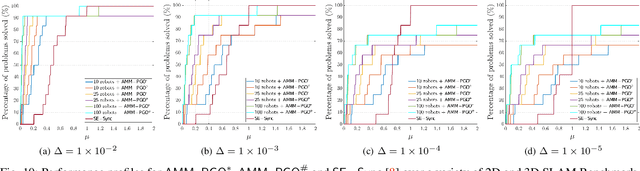
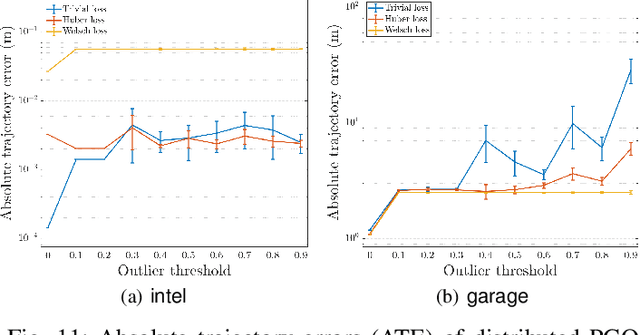

We consider the problem of distributed pose graph optimization (PGO) that has important applications in multi-robot simultaneous localization and mapping (SLAM). We propose the majorization minimization (MM) method for distributed PGO ($\mathsf{MM\!\!-\!\!PGO}$) that applies to a broad class of robust loss kernels. The $\mathsf{MM\!\!-\!\!PGO}$ method is guaranteed to converge to first-order critical points under mild conditions. Furthermore, noting that the $\mathsf{MM\!\!-\!\!PGO}$ method is reminiscent of proximal methods, we leverage Nesterov's method and adopt adaptive restarts to accelerate convergence. The resulting accelerated MM methods for distributed PGO -- both with a master node in the network ($\mathsf{AMM\!\!-\!\!PGO}^*$) and without ($\mathsf{AMM\!\!-\!\!PGO}^{\#}$) -- have faster convergence in contrast to the $\mathsf{MM\!\!-\!\!PGO}$ method without sacrificing theoretical guarantees. In particular, the $\mathsf{AMM\!\!-\!\!PGO}^{\#}$ method, which needs no master node and is fully decentralized, features a novel adaptive restart scheme and has a rate of convergence comparable to that of the $\mathsf{AMM\!\!-\!\!PGO}^*$ method using a master node to aggregate information from all the other nodes. The efficacy of this work is validated through extensive applications to 2D and 3D SLAM benchmark datasets and comprehensive comparisons against existing state-of-the-art methods, indicating that our MM methods converge faster and result in better solutions to distributed PGO.
Self-Contrastive Learning
Jun 29, 2021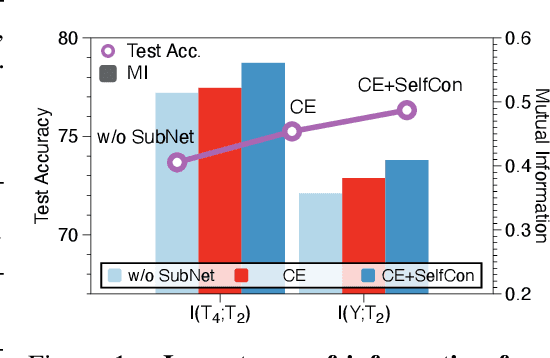
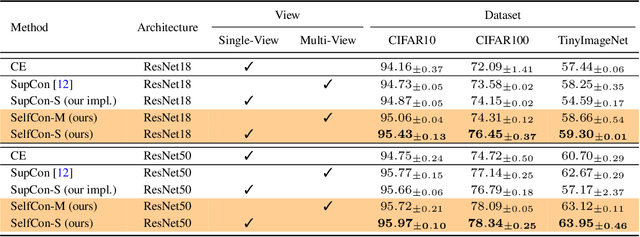
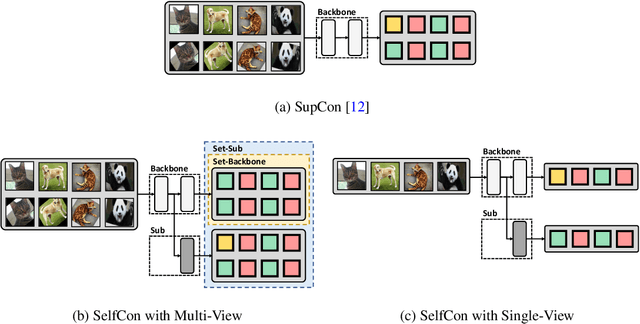
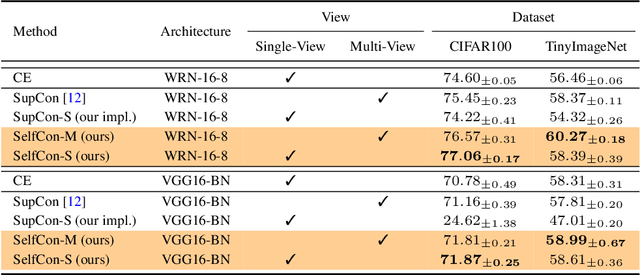
This paper proposes a novel contrastive learning framework, coined as Self-Contrastive (SelfCon) Learning, that self-contrasts within multiple outputs from the different levels of a network. We confirmed that SelfCon loss guarantees the lower bound of mutual information (MI) between the intermediate and last representations. Besides, we empirically showed, via various MI estimators, that SelfCon loss highly correlates to the increase of MI and better classification performance. In our experiments, SelfCon surpasses supervised contrastive (SupCon) learning without the need for a multi-viewed batch and with the cheaper computational cost. Especially on ResNet-18, we achieved top-1 classification accuracy of 76.45% for the CIFAR-100 dataset, which is 2.87% and 4.36% higher than SupCon and cross-entropy loss, respectively. We found that mitigating both vanishing gradient and overfitting issue makes our method outperform the counterparts.
Learning First-Order Representations for Planning from Black-Box States: New Results
May 23, 2021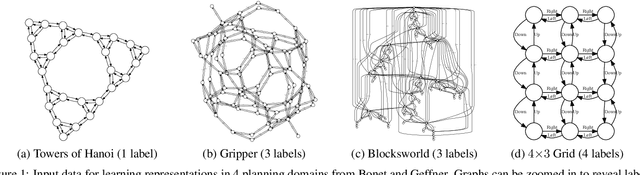
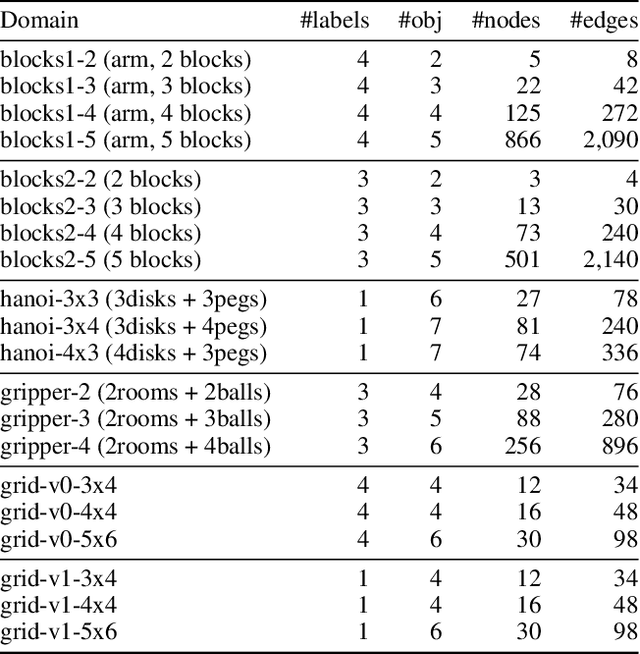

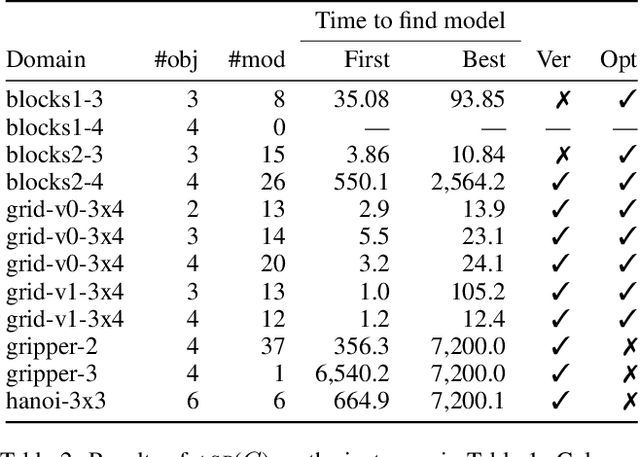
Recently Bonet and Geffner have shown that first-order representations for planning domains can be learned from the structure of the state space without any prior knowledge about the action schemas or domain predicates. For this, the learning problem is formulated as the search for a simplest first-order domain description D that along with information about instances I_i (number of objects and initial state) determine state space graphs G(P_i) that match the observed state graphs G_i where P_i = (D, I_i). The search is cast and solved approximately by means of a SAT solver that is called over a large family of propositional theories that differ just in the parameters encoding the possible number of action schemas and domain predicates, their arities, and the number of objects. In this work, we push the limits of these learners by moving to an answer set programming (ASP) encoding using the CLINGO system. The new encodings are more transparent and concise, extending the range of possible models while facilitating their exploration. We show that the domains introduced by Bonet and Geffner can be solved more efficiently in the new approach, often optimally, and furthermore, that the approach can be easily extended to handle partial information about the state graphs as well as noise that prevents some states from being distinguished.
Analysing Affective Behavior in the second ABAW2 Competition
Jul 03, 2021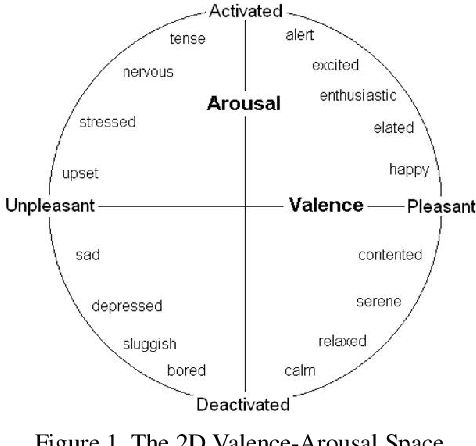
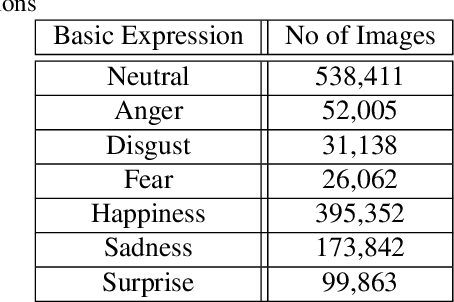
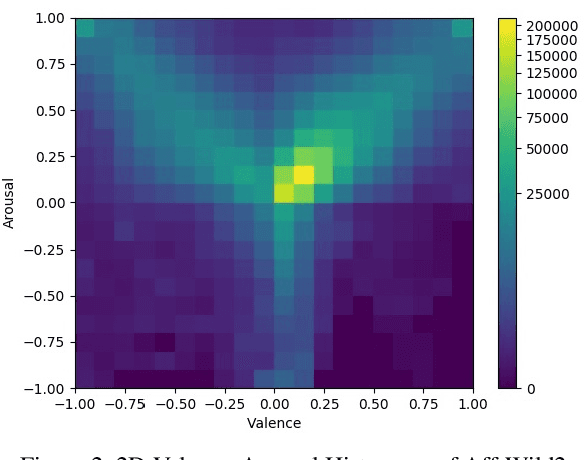
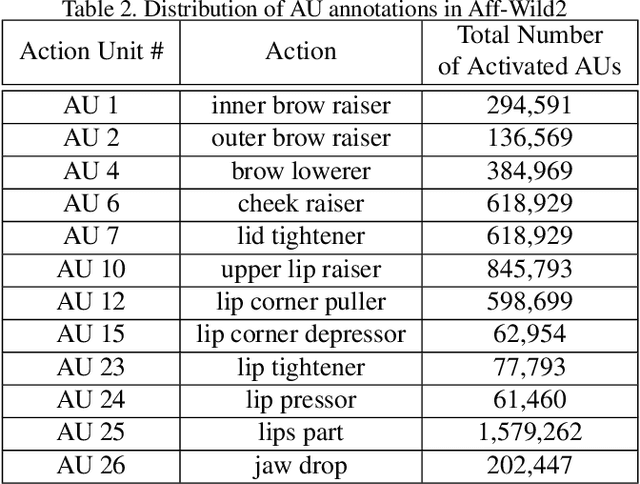
The Affective Behavior Analysis in-the-wild (ABAW2) 2021 Competition is the second -- following the first very successful ABAW Competition held in conjunction with IEEE FG 2020- Competition that aims at automatically analyzing affect. ABAW2 is split into three Challenges, each one addressing one of the three main behavior tasks of valence-arousal estimation, basic expression classification and action unit detection. All three Challenges are based on a common benchmark database, Aff-Wild2, which is a large scale in-the-wild database and the first one to be annotated for all these three tasks. In this paper, we describe this Competition, to be held in conjunction with ICCV 2021. We present the three Challenges, with the utilized Competition corpora. We outline the evaluation metrics and present the baseline system with its results. More information regarding the Competition is provided in the Competition site: https://ibug.doc.ic.ac.uk/resources/iccv-2021-2nd-abaw.
Subnet Replacement: Deployment-stage backdoor attack against deep neural networks in gray-box setting
Jul 15, 2021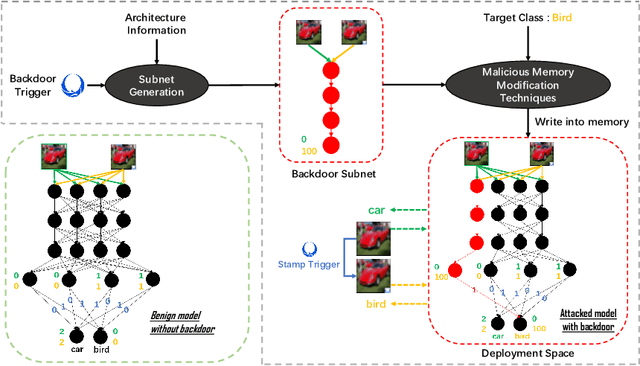
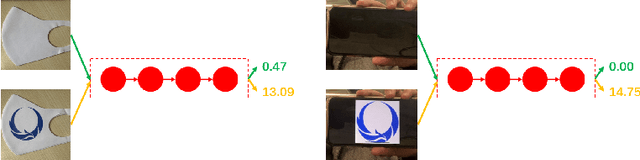
We study the realistic potential of conducting backdoor attack against deep neural networks (DNNs) during deployment stage. Specifically, our goal is to design a deployment-stage backdoor attack algorithm that is both threatening and realistically implementable. To this end, we propose Subnet Replacement Attack (SRA), which is capable of embedding backdoor into DNNs by directly modifying a limited number of model parameters. Considering the realistic practicability, we abandon the strong white-box assumption widely adopted in existing studies, instead, our algorithm works in a gray-box setting, where architecture information of the victim model is available but the adversaries do not have any knowledge of parameter values. The key philosophy underlying our approach is -- given any neural network instance (regardless of its specific parameter values) of a certain architecture, we can always embed a backdoor into that model instance, by replacing a very narrow subnet of a benign model (without backdoor) with a malicious backdoor subnet, which is designed to be sensitive (fire large activation value) to a particular backdoor trigger pattern.
Decentralized Bayesian Learning with Metropolis-Adjusted Hamiltonian Monte Carlo
Jul 15, 2021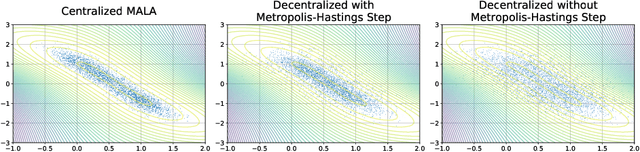
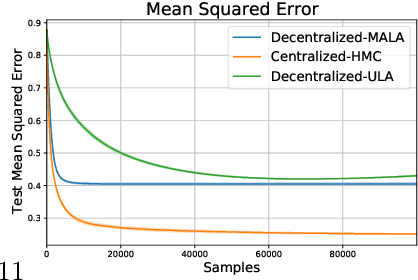
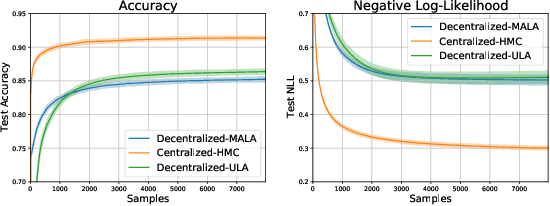
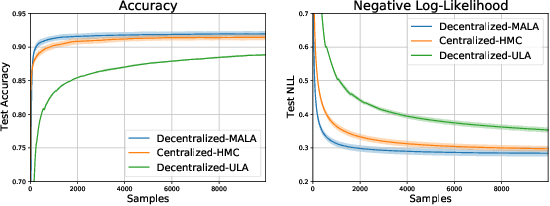
Federated learning performed by a decentralized networks of agents is becoming increasingly important with the prevalence of embedded software on autonomous devices. Bayesian approaches to learning benefit from offering more information as to the uncertainty of a random quantity, and Langevin and Hamiltonian methods are effective at realizing sampling from an uncertain distribution with large parameter dimensions. Such methods have only recently appeared in the decentralized setting, and either exclusively use stochastic gradient Langevin and Hamiltonian Monte Carlo approaches that require a diminishing stepsize to asymptotically sample from the posterior and are known in practice to characterize uncertainty less faithfully than constant step-size methods with a Metropolis adjustment, or assume strong convexity properties of the potential function. We present the first approach to incorporating constant stepsize Metropolis-adjusted HMC in the decentralized sampling framework, show theoretical guarantees for consensus and probability distance to the posterior stationary distribution, and demonstrate their effectiveness numerically on standard real world problems, including decentralized learning of neural networks which is known to be highly non-convex.