 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-Slice Dense-Sparse Learning for Efficient Liver and Tumor Segmentation
Aug 15, 2021
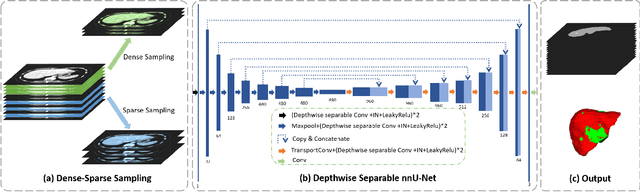
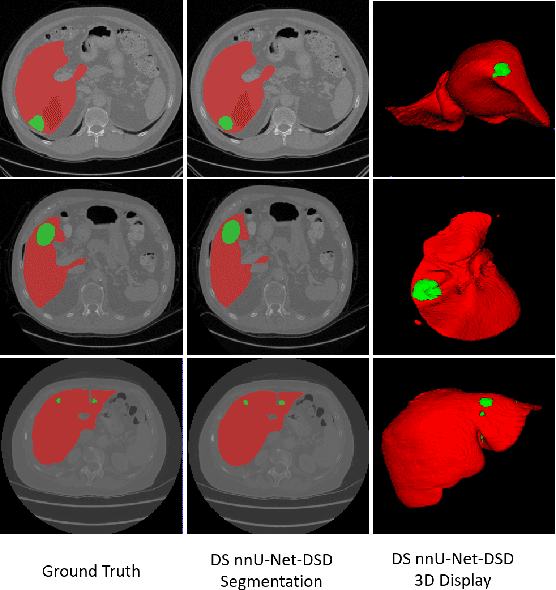
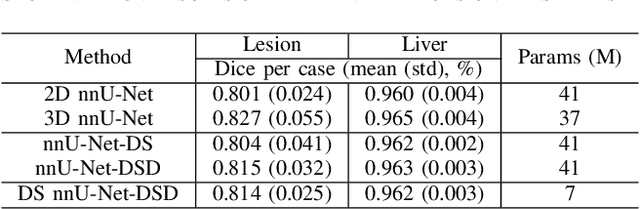
Accurate automatic liver and tumor segmentation plays a vital role in treatment planning and disease monitoring. Recently, deep convolutional neural network (DCNNs) has obtained tremendous success in 2D and 3D medical image segmentation. However, 2D DCNNs cannot fully leverage the inter-slice information, while 3D DCNNs are computationally expensive and memory intensive. To address these issues, we first propose a novel dense-sparse training flow from a data perspective, in which, densely adjacent slices and sparsely adjacent slices are extracted as inputs for regularizing DCNNs, thereby improving the model performance. Moreover, we design a 2.5D light-weight nnU-Net from a network perspective, in which, depthwise separable convolutions are adopted to improve the efficiency. Extensive experiments on the LiTS dataset have demonstrated the superiority of the proposed method.
Fine-grained Semantics-aware Representation Enhancement for Self-supervised Monocular Depth Estimation
Aug 19, 2021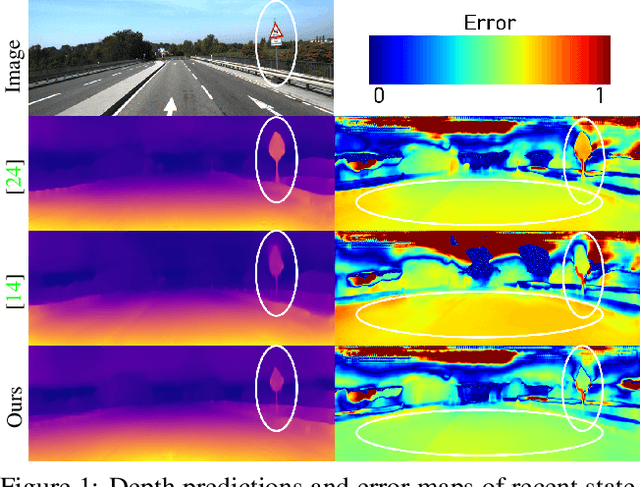
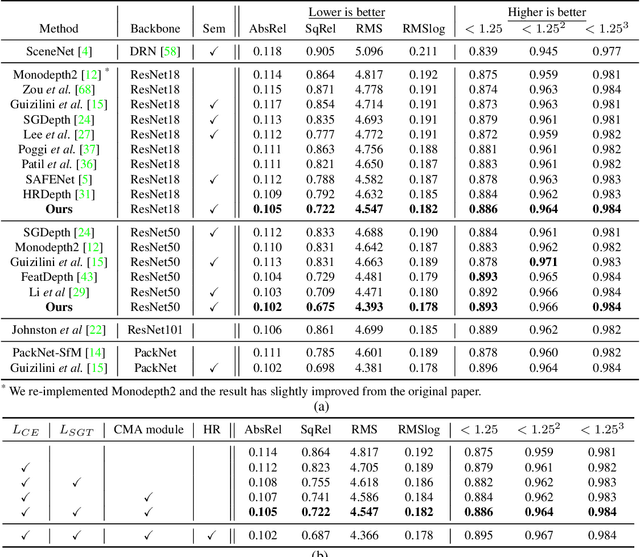
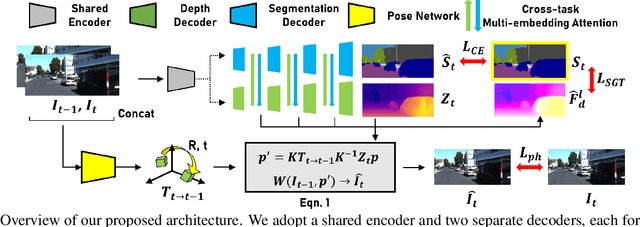
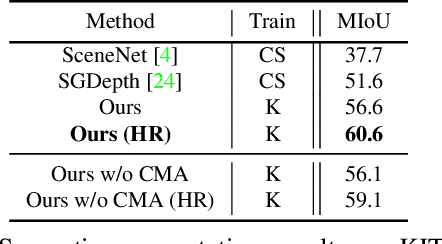
Self-supervised monocular depth estimation has been widely studied, owing to its practical importance and recent promising improvements. However, most works suffer from limited supervision of photometric consistency, especially in weak texture regions and at object boundaries. To overcome this weakness, we propose novel ideas to improve self-supervised monocular depth estimation by leveraging cross-domain information, especially scene semantics. We focus on incorporating implicit semantic knowledge into geometric representation enhancement and suggest two ideas: a metric learning approach that exploits the semantics-guided local geometry to optimize intermediate depth representations and a novel feature fusion module that judiciously utilizes cross-modality between two heterogeneous feature representations. We comprehensively evaluate our methods on the KITTI dataset and demonstrate that our method outperforms state-of-the-art methods. The source code is available at https://github.com/hyBlue/FSRE-Depth.
Video Classification with FineCoarse Networks
Mar 29, 2021

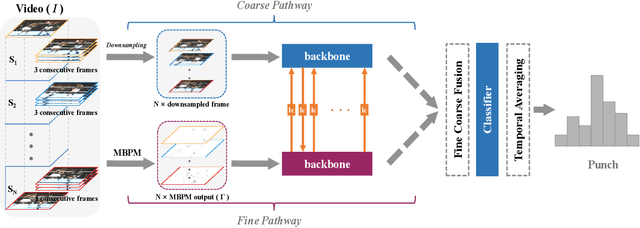
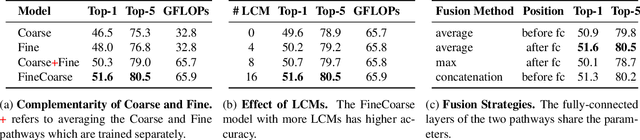
A rich representation of the information in video data can be realized by means of frequency analysis. Fine motion details from the boundaries of moving regions are characterized by high frequencies in the spatio-temporal domain. Meanwhile, lower frequencies are encoded with coarse information containing substantial redundancy, which causes low efficiency for those video models that take as input raw RGB frames. In this work, we propose a Motion Band-pass Module (MBPM) for separating the fine-grained information from coarse information in raw video data. By representing the coarse information with low resolution, we can increase the efficiency of video data processing. By embedding the MBPM into a two-pathway CNN architecture, we define a FineCoarse network. The efficiency of the FineCoarse network is determined by avoiding the redundancy in the feature space processed by the two pathways: one operates on downsampled features of low-resolution data, while the other operates on the fine-grained motion information captured by the MBPM. The proposed FineCoarse network outperforms many recent video processing models on Kinetics400, UCF101 and HMDB51. Furthermore, our approach achieves the state-of-the-art with 57.0% top-1 accuracy on Something-Something V1.
MD-CSDNetwork: Multi-Domain Cross Stitched Network for Deepfake Detection
Sep 15, 2021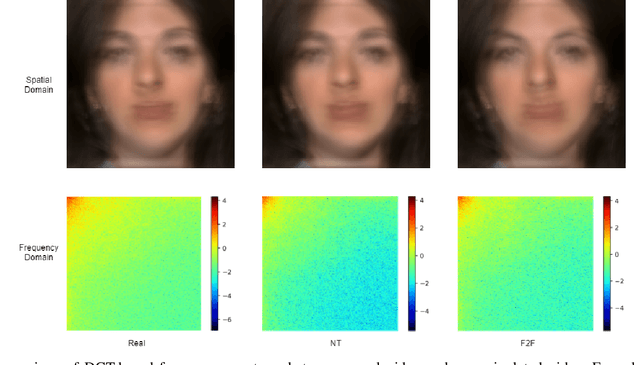
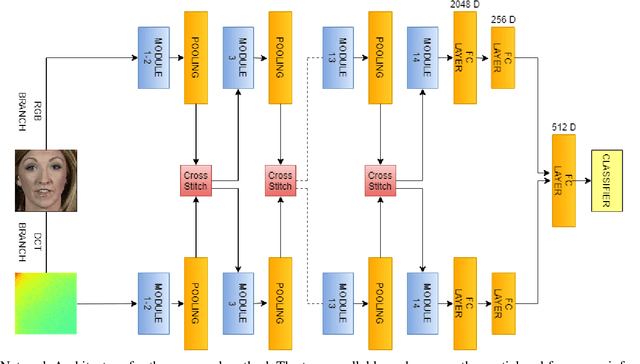
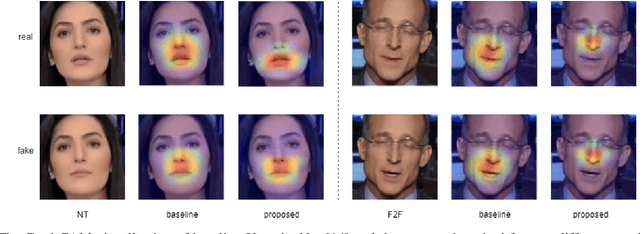
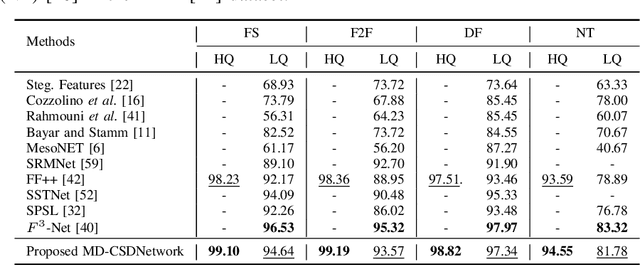
The rapid progress in the ease of creating and spreading ultra-realistic media over social platforms calls for an urgent need to develop a generalizable deepfake detection technique. It has been observed that current deepfake generation methods leave discriminative artifacts in the frequency spectrum of fake images and videos. Inspired by this observation, in this paper, we present a novel approach, termed as MD-CSDNetwork, for combining the features in the spatial and frequency domains to mine a shared discriminative representation for classifying \textit{deepfakes}. MD-CSDNetwork is a novel cross-stitched network with two parallel branches carrying the spatial and frequency information, respectively. We hypothesize that these multi-domain input data streams can be considered as related supervisory signals. The supervision from both branches ensures better performance and generalization. Further, the concept of cross-stitch connections is utilized where they are inserted between the two branches to learn an optimal combination of domain-specific and shared representations from other domains automatically. Extensive experiments are conducted on the popular benchmark dataset namely FaceForeniscs++ for forgery classification. We report improvements over all the manipulation types in FaceForensics++ dataset and comparable results with state-of-the-art methods for cross-database evaluation on the Celeb-DF dataset and the Deepfake Detection Dataset.
Image Captioning for Effective Use of Language Models in Knowledge-Based Visual Question Answering
Sep 15, 2021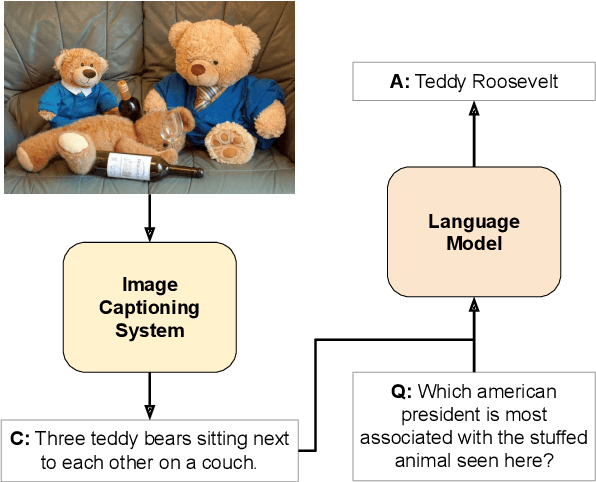



Integrating outside knowledge for reasoning in visio-linguistic tasks such as visual question answering (VQA) is an open problem. Given that pretrained language models have been shown to include world knowledge, we propose to use a unimodal (text-only) train and inference procedure based on automatic off-the-shelf captioning of images and pretrained language models. Our results on a visual question answering task which requires external knowledge (OK-VQA) show that our text-only model outperforms pretrained multimodal (image-text) models of comparable number of parameters. In contrast, our model is less effective in a standard VQA task (VQA 2.0) confirming that our text-only method is specially effective for tasks requiring external knowledge. In addition, we show that our unimodal model is complementary to multimodal models in both OK-VQA and VQA 2.0, and yield the best result to date in OK-VQA among systems not using external knowledge graphs, and comparable to systems that do use them. Our qualitative analysis on OK-VQA reveals that automatic captions often fail to capture relevant information in the images, which seems to be balanced by the better inference ability of the text-only language models. Our work opens up possibilities to further improve inference in visio-linguistic tasks.
Conditional t-SNE: Complementary t-SNE embeddings through factoring out prior information
May 24, 2019
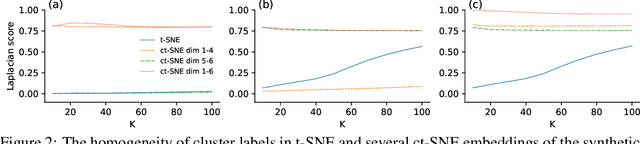
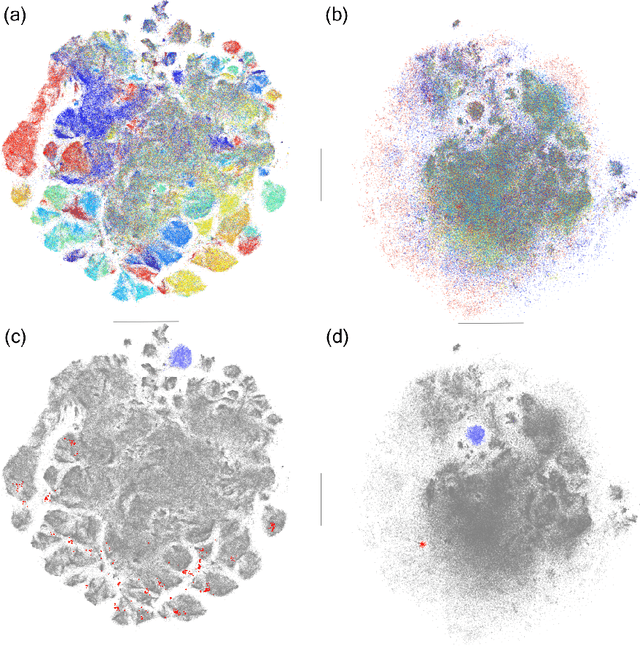

Dimensionality reduction and manifold learning methods such as t-Distributed Stochastic Neighbor Embedding (t-SNE) are routinely used to map high-dimensional data into a 2-dimensional space to visualize and explore the data. However, two dimensions are typically insufficient to capture all structure in the data, the salient structure is often already known, and it is not obvious how to extract the remaining information in a similarly effective manner. To fill this gap, we introduce \emph{conditional t-SNE} (ct-SNE), a generalization of t-SNE that discounts prior information from the embedding in the form of labels. To achieve this, we propose a conditioned version of the t-SNE objective, obtaining a single, integrated, and elegant method. ct-SNE has one extra parameter over t-SNE; we investigate its effects and show how to efficiently optimize the objective. Factoring out prior knowledge allows complementary structure to be captured in the embedding, providing new insights. Qualitative and quantitative empirical results on synthetic and (large) real data show ct-SNE is effective and achieves its goal.
Stochastic functional analysis with applications to robust machine learning
Oct 04, 2021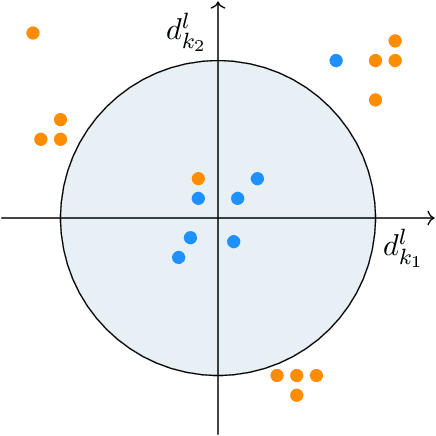
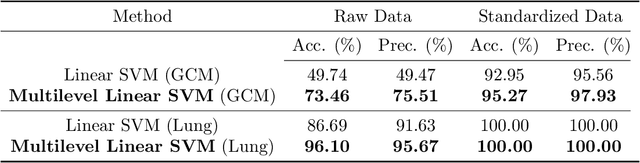
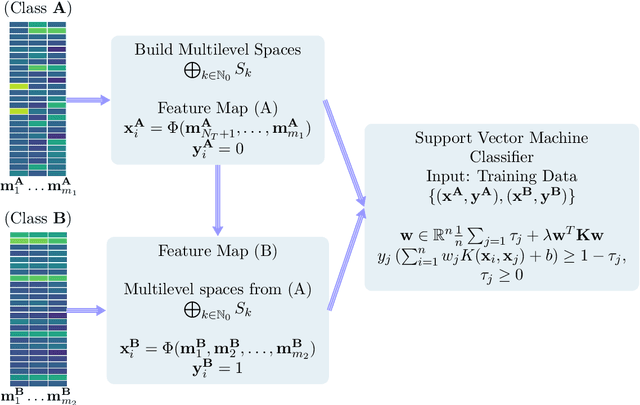
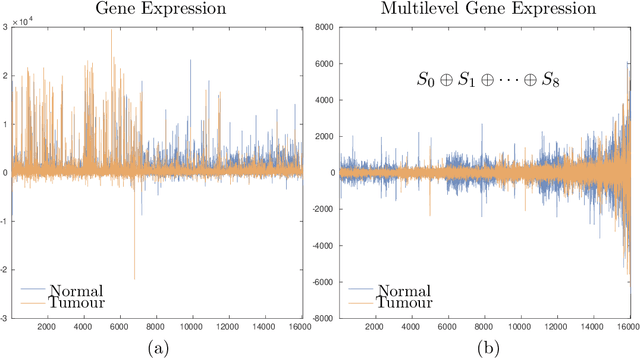
It is well-known that machine learning protocols typically under-utilize information on the probability distributions of feature vectors and related data, and instead directly compute regression or classification functions of feature vectors. In this paper we introduce a set of novel features for identifying underlying stochastic behavior of input data using the Karhunen-Lo\'{e}ve (KL) expansion, where classification is treated as detection of anomalies from a (nominal) signal class. These features are constructed from the recent Functional Data Analysis (FDA) theory for anomaly detection. The related signal decomposition is an exact hierarchical tensor product expansion with known optimality properties for approximating stochastic processes (random fields) with finite dimensional function spaces. In principle these primary low dimensional spaces can capture most of the stochastic behavior of `underlying signals' in a given nominal class, and can reject signals in alternative classes as stochastic anomalies. Using a hierarchical finite dimensional KL expansion of the nominal class, a series of orthogonal nested subspaces is constructed for detecting anomalous signal components. Projection coefficients of input data in these subspaces are then used to train an ML classifier. However, due to the split of the signal into nominal and anomalous projection components, clearer separation surfaces of the classes arise. In fact we show that with a sufficiently accurate estimation of the covariance structure of the nominal class, a sharp classification can be obtained. We carefully formulate this concept and demonstrate it on a number of high-dimensional datasets in cancer diagnostics. This method leads to a significant increase in precision and accuracy over the current top benchmarks for the Global Cancer Map (GCM) gene expression network dataset.
How much pretraining data do language models need to learn syntax?
Sep 09, 2021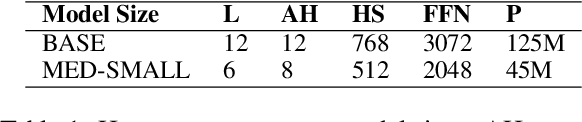
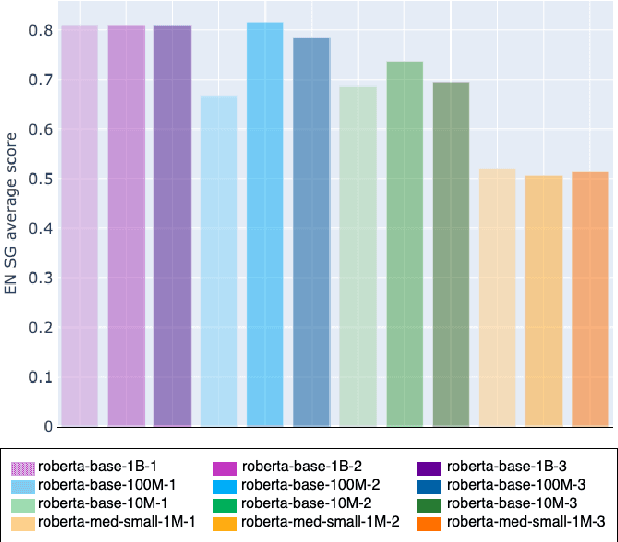
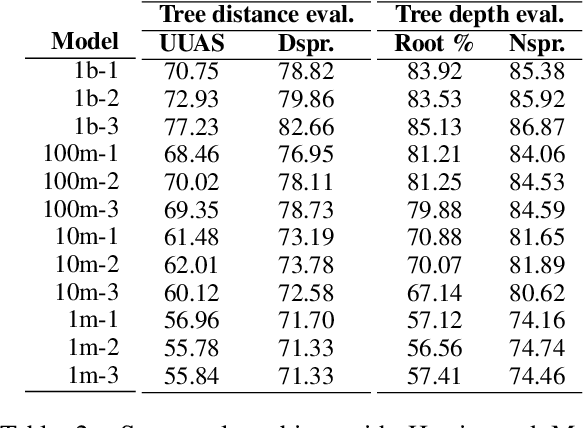
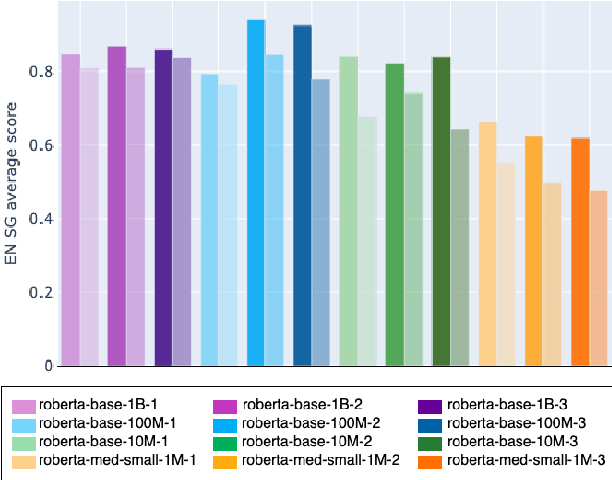
Transformers-based pretrained language models achieve outstanding results in many well-known NLU benchmarks. However, while pretraining methods are very convenient, they are expensive in terms of time and resources. This calls for a study of the impact of pretraining data size on the knowledge of the models. We explore this impact on the syntactic capabilities of RoBERTa, using models trained on incremental sizes of raw text data. First, we use syntactic structural probes to determine whether models pretrained on more data encode a higher amount of syntactic information. Second, we perform a targeted syntactic evaluation to analyze the impact of pretraining data size on the syntactic generalization performance of the models. Third, we compare the performance of the different models on three downstream applications: part-of-speech tagging, dependency parsing and paraphrase identification. We complement our study with an analysis of the cost-benefit trade-off of training such models. Our experiments show that while models pretrained on more data encode more syntactic knowledge and perform better on downstream applications, they do not always offer a better performance across the different syntactic phenomena and come at a higher financial and environmental cost.
Understanding the Basis of Graph Convolutional Neural Networks via an Intuitive Matched Filtering Approach
Aug 23, 2021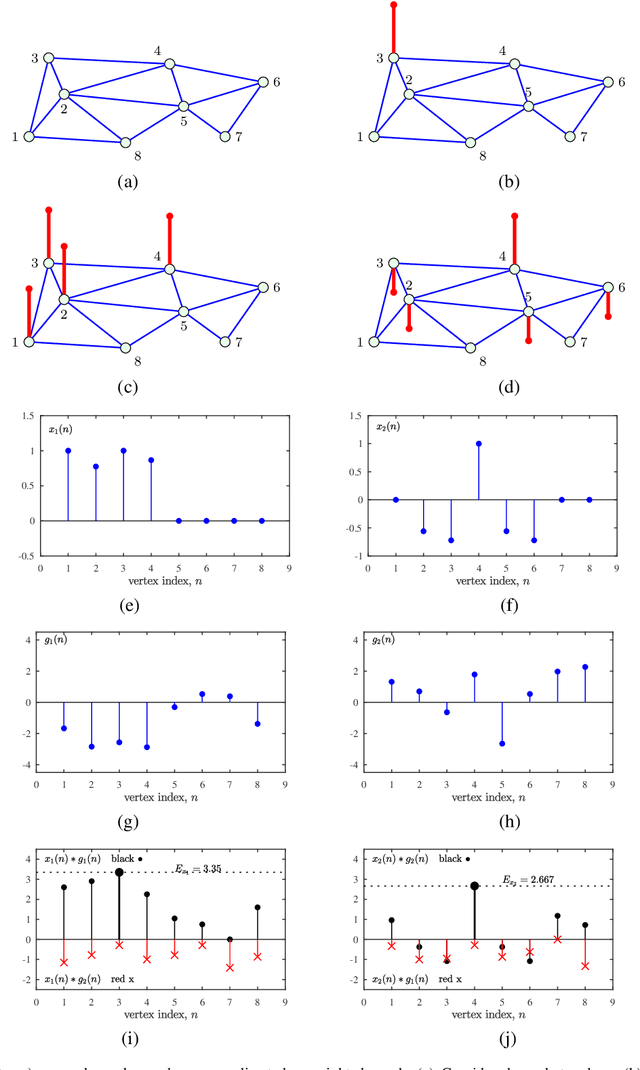
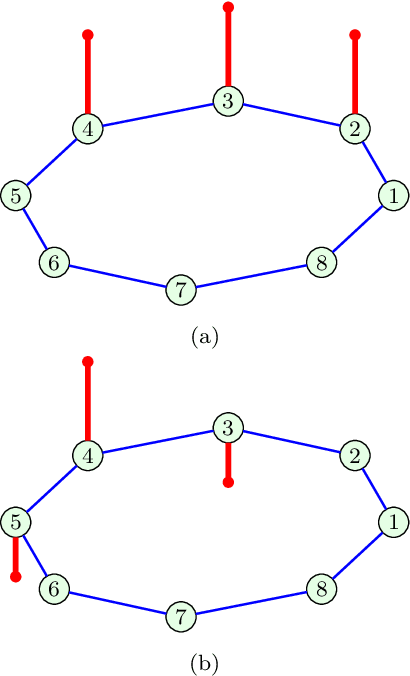
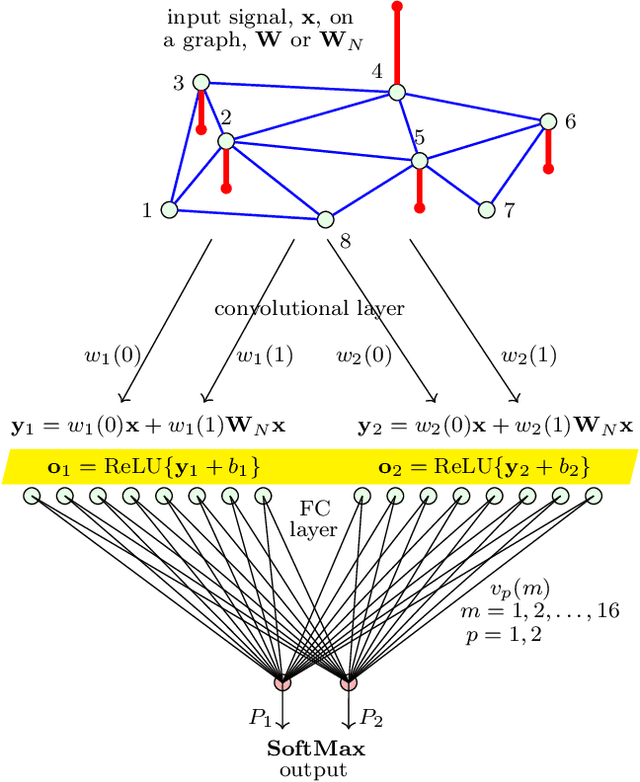
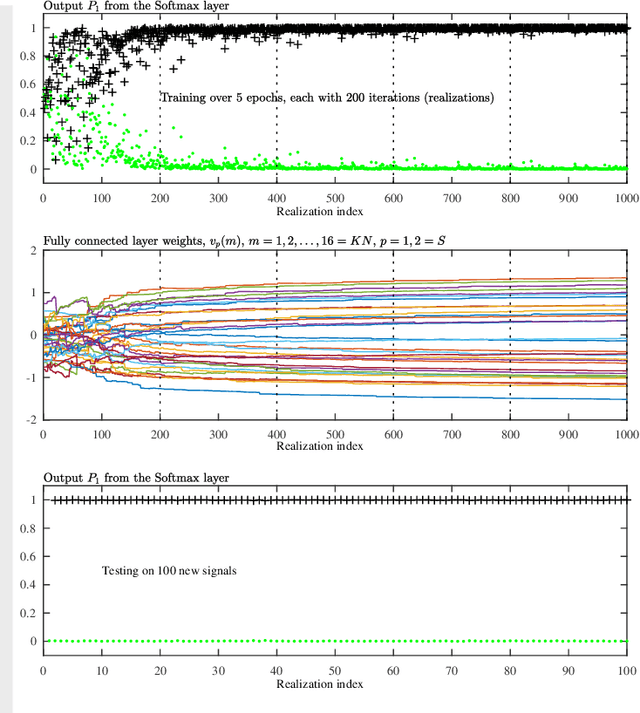
Graph Convolutional Neural Networks (GCNN) are becoming a preferred model for data processing on irregular domains, yet their analysis and principles of operation are rarely examined due to the black box nature of NNs. To this end, we revisit the operation of GCNNs and show that their convolution layers effectively perform matched filtering of input data with the chosen patterns (features). This allows us to provide a unifying account of GCNNs through a matched filter perspective, whereby the nonlinear ReLU and max-pooling layers are also discussed within the matched filtering framework. This is followed by a step-by-step guide on information propagation and learning in GCNNs. It is also shown that standard CNNs and fully connected NNs can be obtained as a special case of GCNNs. A carefully chosen numerical example guides the reader through the various steps of GCNN operation and learning both visually and numerically.
PolyDNN: Polynomial Representation of NN for Communication-less SMPC Inference
Apr 28, 2021
The structure and weights of Deep Neural Networks (DNN) typically encode and contain very valuable information about the dataset that was used to train the network. One way to protect this information when DNN is published is to perform an interference of the network using secure multi-party computations (MPC). In this paper, we suggest a translation of deep neural networks to polynomials, which are easier to calculate efficiently with MPC techniques. We show a way to translate complete networks into a single polynomial and how to calculate the polynomial with an efficient and information-secure MPC algorithm. The calculation is done without intermediate communication between the participating parties, which is beneficial in several cases, as explained in the paper.