 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep Learning for Channel Coding via Neural Mutual Information Estimation
Mar 07, 2019
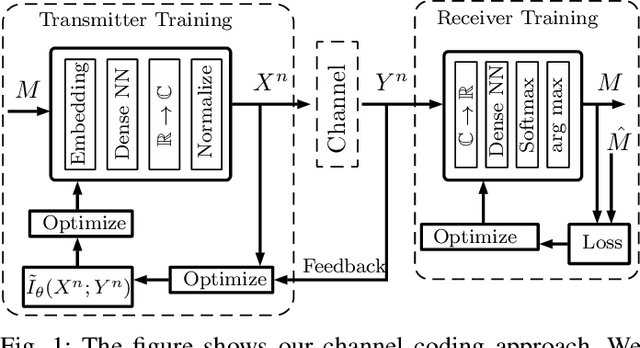
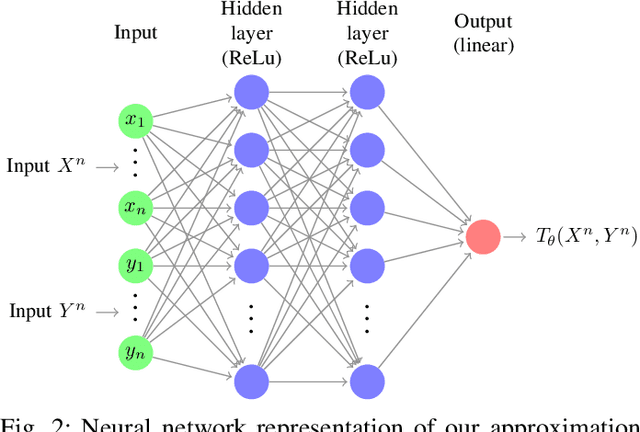
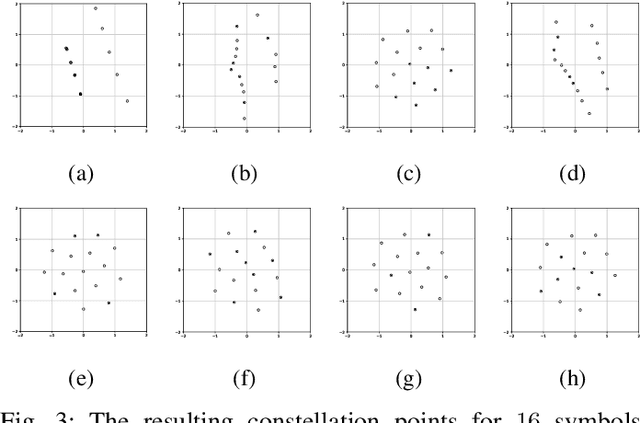
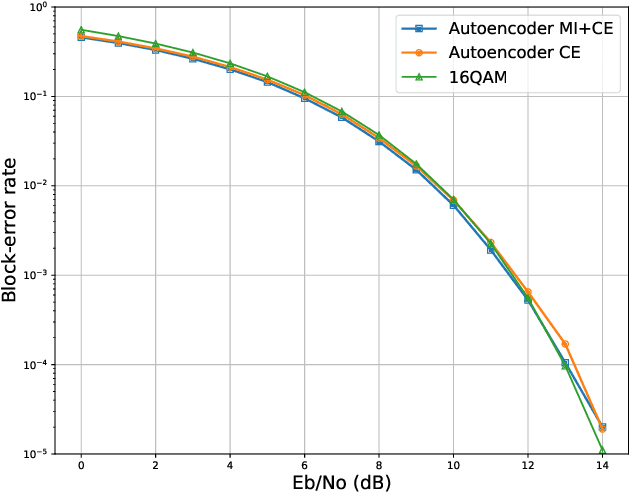
End-to-end deep learning for communication systems, i.e., systems whose encoder and decoder are learned, has attracted significant interest recently, due to its performance which comes close to well-developed classical encoder-decoder designs. However, one of the drawbacks of current learning approaches is that a differentiable channel model is needed for the training of the underlying neural networks. In real-world scenarios, such a channel model is hardly available and often the channel density is not even known at all. Some works, therefore, focus on a generative approach, i.e., generating the channel from samples, or rely on reinforcement learning to circumvent this problem. We present a novel approach which utilizes a recently proposed neural estimator of mutual information. We use this estimator to optimize the encoder for a maximized mutual information, only relying on channel samples. Moreover, we show that our approach achieves the same performance as state-of-the-art end-to-end learning with perfect channel model knowledge.
Artificial Intelligence-Driven Customized Manufacturing Factory: Key Technologies, Applications, and Challenges
Aug 07, 2021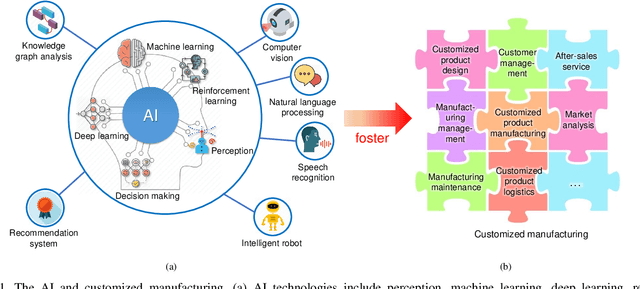
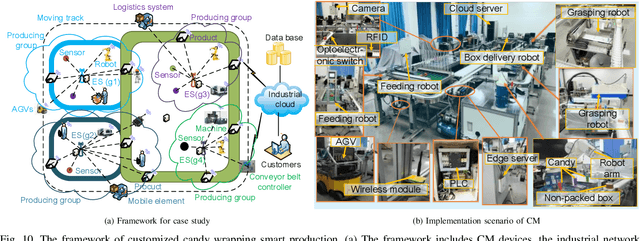
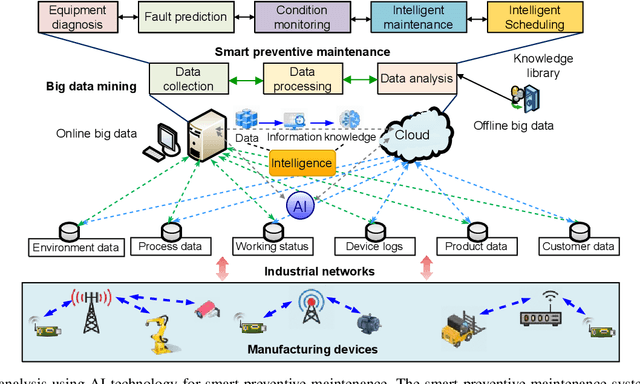
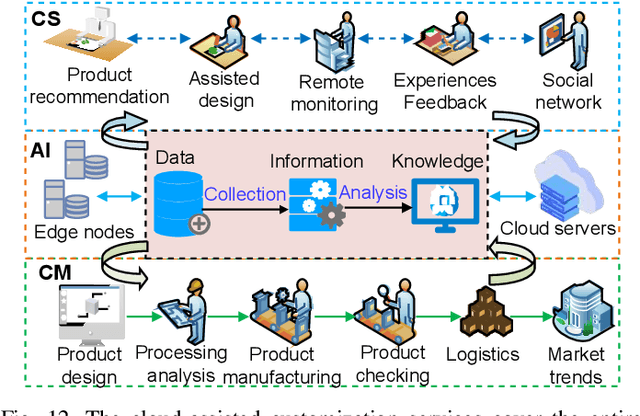
The traditional production paradigm of large batch production does not offer flexibility towards satisfying the requirements of individual customers. A new generation of smart factories is expected to support new multi-variety and small-batch customized production modes. For that, Artificial Intelligence (AI) is enabling higher value-added manufacturing by accelerating the integration of manufacturing and information communication technologies, including computing, communication, and control. The characteristics of a customized smart factory are to include self-perception, operations optimization, dynamic reconfiguration, and intelligent decision-making. The AI technologies will allow manufacturing systems to perceive the environment, adapt to the external needs, and extract the process knowledge, including business models, such as intelligent production, networked collaboration, and extended service models. This paper focuses on the implementation of AI in customized manufacturing (CM). The architecture of an AI-driven customized smart factory is presented. Details of intelligent manufacturing devices, intelligent information interaction, and construction of a flexible manufacturing line are showcased. The state-of-the-art AI technologies of potential use in CM, i.e., machine learning, multi-agent systems, Internet of Things, big data, and cloud-edge computing are surveyed. The AI-enabled technologies in a customized smart factory are validated with a case study of customized packaging. The experimental results have demonstrated that the AI-assisted CM offers the possibility of higher production flexibility and efficiency. Challenges and solutions related to AI in CM are also discussed.
* 21 pages, 12 figures
Moving Object Detection for Event-based vision using Graph Spectral Clustering
Sep 30, 2021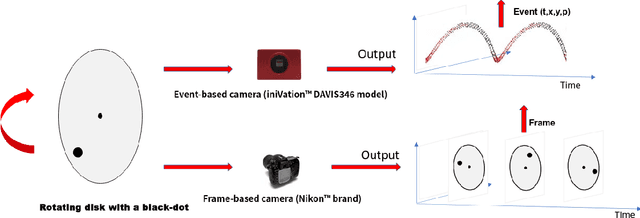
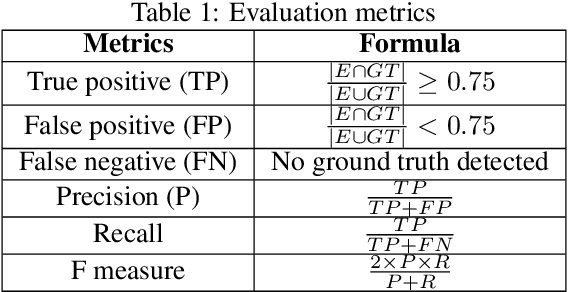
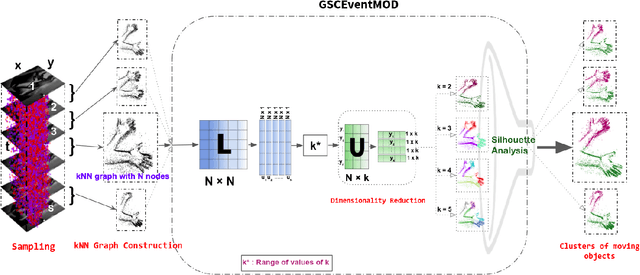

Moving object detection has been a central topic of discussion in computer vision for its wide range of applications like in self-driving cars, video surveillance, security, and enforcement. Neuromorphic Vision Sensors (NVS) are bio-inspired sensors that mimic the working of the human eye. Unlike conventional frame-based cameras, these sensors capture a stream of asynchronous 'events' that pose multiple advantages over the former, like high dynamic range, low latency, low power consumption, and reduced motion blur. However, these advantages come at a high cost, as the event camera data typically contains more noise and has low resolution. Moreover, as event-based cameras can only capture the relative changes in brightness of a scene, event data do not contain usual visual information (like texture and color) as available in video data from normal cameras. So, moving object detection in event-based cameras becomes an extremely challenging task. In this paper, we present an unsupervised Graph Spectral Clustering technique for Moving Object Detection in Event-based data (GSCEventMOD). We additionally show how the optimum number of moving objects can be automatically determined. Experimental comparisons on publicly available datasets show that the proposed GSCEventMOD algorithm outperforms a number of state-of-the-art techniques by a maximum margin of 30%.
The Animation Transformer: Visual Correspondence via Segment Matching
Sep 08, 2021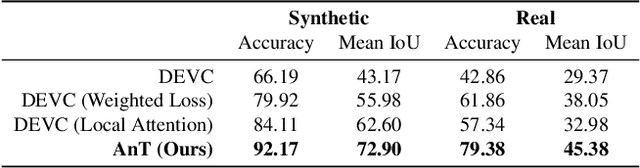
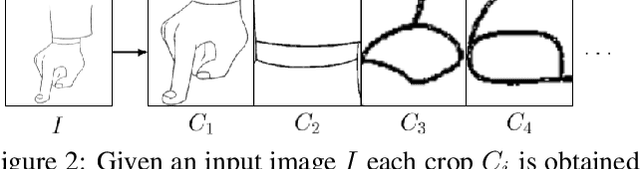
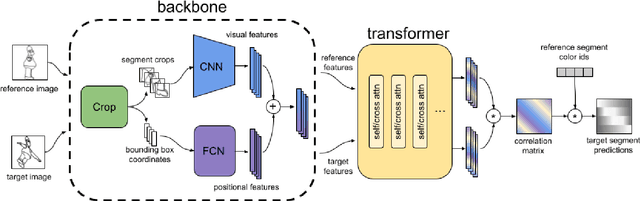
Visual correspondence is a fundamental building block on the way to building assistive tools for hand-drawn animation. However, while a large body of work has focused on learning visual correspondences at the pixel-level, few approaches have emerged to learn correspondence at the level of line enclosures (segments) that naturally occur in hand-drawn animation. Exploiting this structure in animation has numerous benefits: it avoids the intractable memory complexity of attending to individual pixels in high resolution images and enables the use of real-world animation datasets that contain correspondence information at the level of per-segment colors. To that end, we propose the Animation Transformer (AnT) which uses a transformer-based architecture to learn the spatial and visual relationships between segments across a sequence of images. AnT enables practical ML-assisted colorization for professional animation workflows and is publicly accessible as a creative tool in Cadmium.
RuleBert: Teaching Soft Rules to Pre-trained Language Models
Sep 24, 2021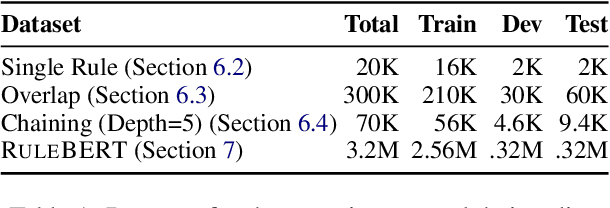
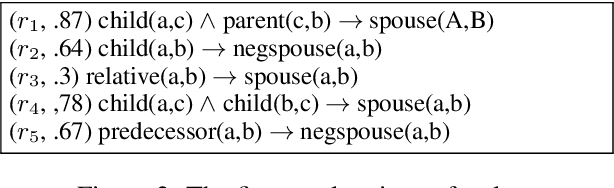
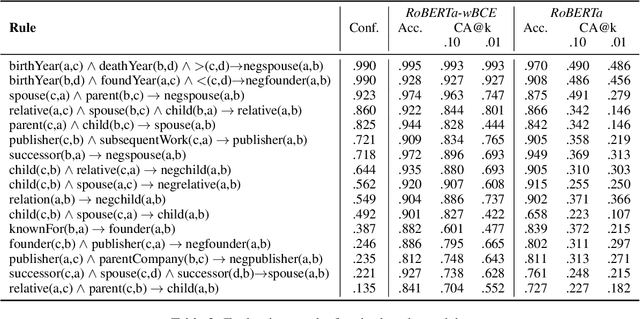
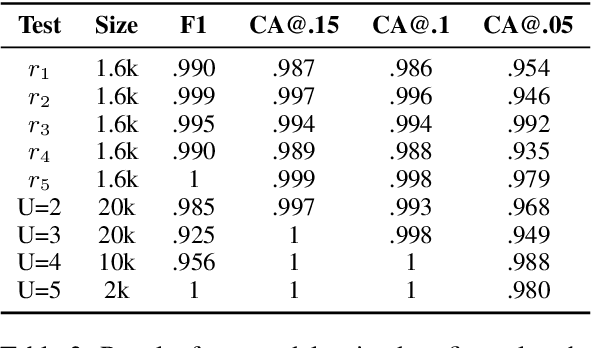
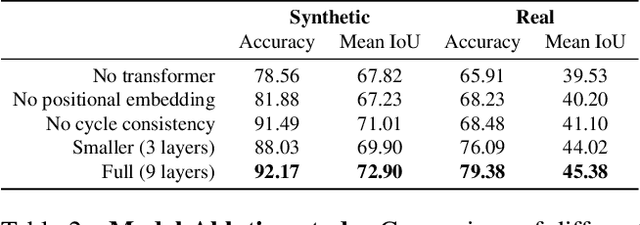
While pre-trained language models (PLMs) are the go-to solution to tackle many natural language processing problems, they are still very limited in their ability to capture and to use common-sense knowledge. In fact, even if information is available in the form of approximate (soft) logical rules, it is not clear how to transfer it to a PLM in order to improve its performance for deductive reasoning tasks. Here, we aim to bridge this gap by teaching PLMs how to reason with soft Horn rules. We introduce a classification task where, given facts and soft rules, the PLM should return a prediction with a probability for a given hypothesis. We release the first dataset for this task, and we propose a revised loss function that enables the PLM to learn how to predict precise probabilities for the task. Our evaluation results show that the resulting fine-tuned models achieve very high performance, even on logical rules that were unseen at training. Moreover, we demonstrate that logical notions expressed by the rules are transferred to the fine-tuned model, yielding state-of-the-art results on external datasets.
* Logical reasoning, soft Horn rules, Transformers, pre-trained language models, combining symbolic and probabilistic methods, BERT
Resolving gas bubbles ascending in liquid metal from low-SNR neutron radiography images
Sep 08, 2021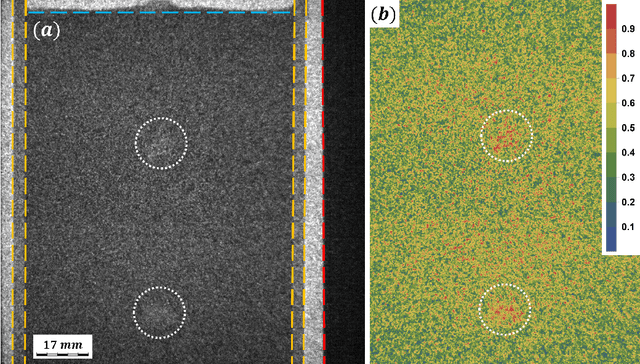
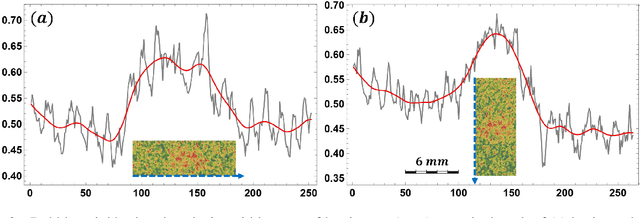

We demonstrate a new image processing methodology for resolving gas bubbles travelling through liquid metal from dynamic neutron radiography images with intrinsically low signal-to-noise ratio. Image pre-processing, denoising and bubble segmentation are described in detail, with practical recommendations. Experimental validation is presented - stationary and moving reference bodies with neutron-transparent cavities are radiographed with imaging conditions similar to the cases with bubbles in liquid metal. The new methods are applied to our experimental data from previous and recent imaging campaigns, and the performance of the methods proposed in this paper is compared against our previously developed methods. Significant improvements are observed as well as the capacity to reliably extract physically meaningful information from measurements performed under highly adverse imaging conditions. The showcased image processing solution and separate elements thereof are readily extendable beyond the present application, and have been made open-source.
BIOPAK Flasher: Epidemic disease monitoring and detection in Pakistan using text mining
Jun 12, 2021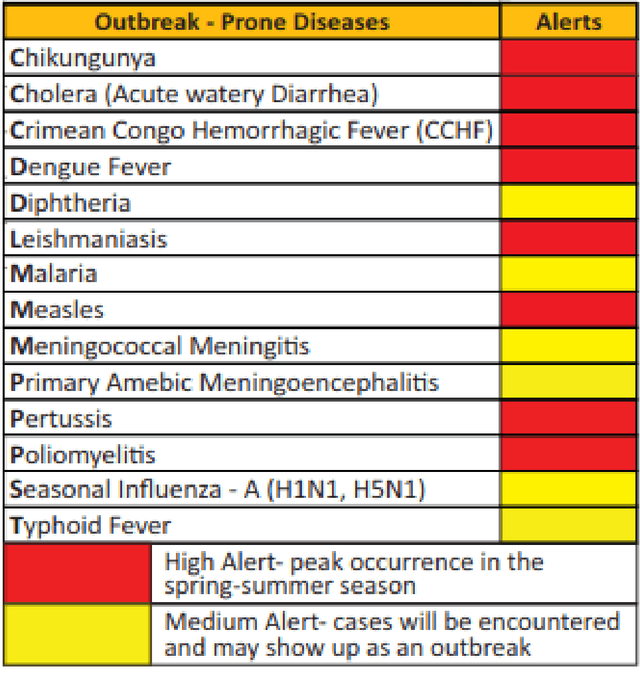
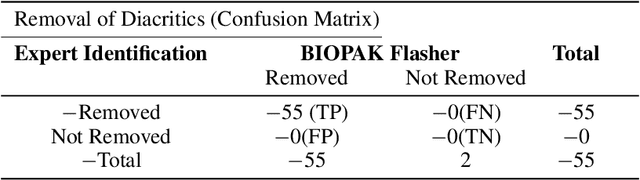
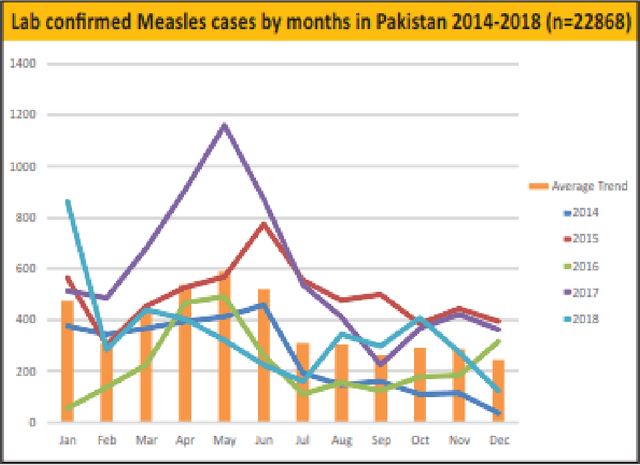
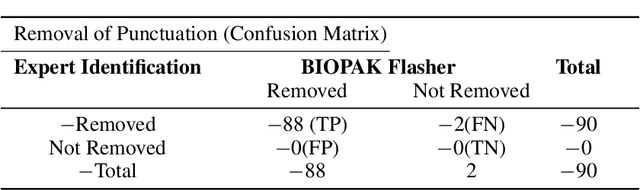
Infectious disease outbreak has a significant impact on morbidity, mortality and can cause economic instability of many countries. As global trade is growing, goods and individuals are expected to travel across the border, an infected epidemic area carrier can pose a great danger to his hostile. If a disease outbreak is recognized promptly, then commercial products and travelers (traders/visitors) will be effectively vaccinated, and therefore the disease stopped. Early detection of outbreaks plays an important role here, and beware of the rapid implementation of control measures by citizens, public health organizations, and government. Many indicators have valuable information, such as online news sources (RSS) and social media sources (Twitter, Facebook) that can be used, but are unstructured and bulky, to extract information about disease outbreaks. Few early warning outbreak systems exist with some limitation of linguistic (Urdu) and covering areas (Pakistan). In Pakistan, few channels are published the outbreak news in Urdu or English. The aim is to procure information from Pakistan's English and Urdu news channels and then investigate process, integrate, and visualize the disease epidemic. Urdu ontology is not existed before to match extracted diseases, so we also build that ontology of disease.
Solution of Physics-based Bayesian Inverse Problems with Deep Generative Priors
Jul 06, 2021
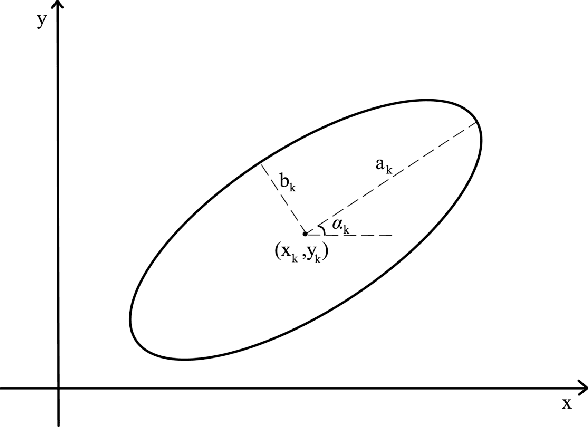
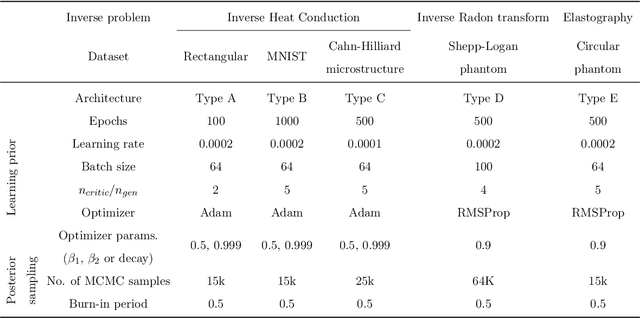
Inverse problems are notoriously difficult to solve because they can have no solutions, multiple solutions, or have solutions that vary significantly in response to small perturbations in measurements. Bayesian inference, which poses an inverse problem as a stochastic inference problem, addresses these difficulties and provides quantitative estimates of the inferred field and the associated uncertainty. However, it is difficult to employ when inferring vectors of large dimensions, and/or when prior information is available through previously acquired samples. In this paper, we describe how deep generative adversarial networks can be used to represent the prior distribution in Bayesian inference and overcome these challenges. We apply these ideas to inverse problems that are diverse in terms of the governing physical principles, sources of prior knowledge, type of measurement, and the extent of available information about measurement noise. In each case we apply the proposed approach to infer the most likely solution and quantitative estimates of uncertainty.
The Adversarial Attack and Detection under the Fisher Information Metric
Oct 09, 2018


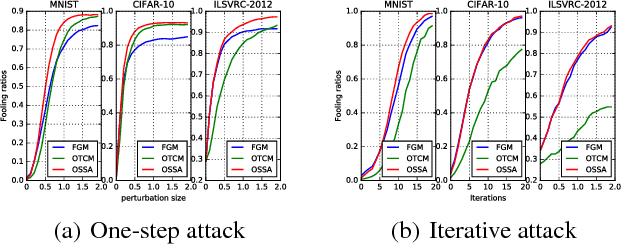
Many deep learning models are vulnerable to the adversarial attack, i.e., imperceptible but intentionally-designed perturbations to the input can cause incorrect output of the networks. In this paper, using information geometry, we provide a reasonable explanation for the vulnerability of deep learning models. By considering the data space as a non-linear space with the Fisher information metric induced from a neural network, we first propose an adversarial attack algorithm termed one-step spectral attack (OSSA). The method is described by a constrained quadratic form of the Fisher information matrix, where the optimal adversarial perturbation is given by the first eigenvector, and the model vulnerability is reflected by the eigenvalues. The larger an eigenvalue is, the more vulnerable the model is to be attacked by the corresponding eigenvector. Taking advantage of the property, we also propose an adversarial detection method with the eigenvalues serving as characteristics. Both our attack and detection algorithms are numerically optimized to work efficiently on large datasets. Our evaluations show superior performance compared with other methods, implying that the Fisher information is a promising approach to investigate the adversarial attacks and defenses.
Spatio-Temporal Context for Action Detection
Jun 29, 2021
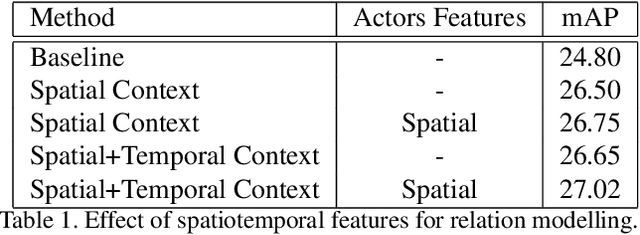
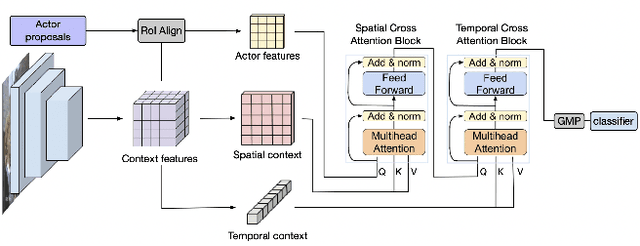
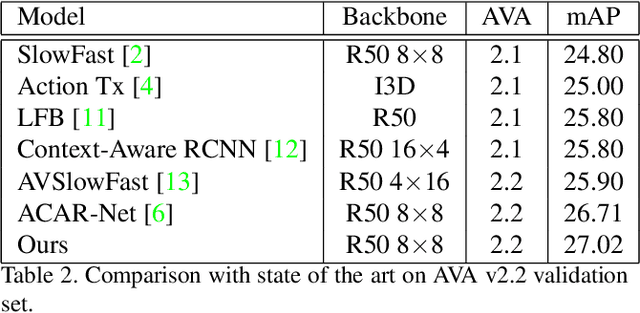
Research in action detection has grown in the recentyears, as it plays a key role in video understanding. Modelling the interactions (either spatial or temporal) between actors and their context has proven to be essential for this task. While recent works use spatial features with aggregated temporal information, this work proposes to use non-aggregated temporal information. This is done by adding an attention based method that leverages spatio-temporal interactions between elements in the scene along the clip.The main contribution of this work is the introduction of two cross attention blocks to effectively model the spatial relations and capture short range temporal interactions.Experiments on the AVA dataset show the advantages of the proposed approach that models spatio-temporal relations between relevant elements in the scene, outperforming other methods that model actor interactions with their context by +0.31 mAP.