 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Generic Correlation to Input-Specific Credit in On-Policy Self Distillation
May 12, 2026On-policy self-distillation has emerged as a promising paradigm for post-training language models, in which the model conditions on environment feedback to serve as its own teacher, providing dense token-level rewards without external teacher models or step-level annotations. Despite its empirical success, what this reward actually measures and what kind of credit it assigns remain unclear. Under a posterior-compatibility interpretation of feedback conditioning, standard in the implicit-reward literature, we show that the self-distillation token reward is a Bayesian filtering increment whose trajectory sum is exactly the pointwise mutual information between the response and the feedback given the input. This pMI can be raised by input-specific reasoning or by input-generic shortcuts, so we further decompose the teacher log-probability along the input axis. Based on this analysis, we propose CREDIT (Contrastive REward from DIsTillation), which isolates the input-specific component with a batch-contrastive baseline. At the sequence level, CREDIT is a teacher-side surrogate for a contrastive pMI objective that also penalizes responses remaining likely under unrelated inputs. Across coding, scientific reasoning, and tool-use benchmarks on two model families, CREDIT delivers the strongest aggregate performance at negligible additional compute.
Anti-Self-Distillation for Reasoning RL via Pointwise Mutual Information
May 12, 2026On-policy self-distillation, where a student is pulled toward a copy of itself conditioned on privileged context (e.g., a verified solution or feedback), offers a promising direction for advancing reasoning capability without a stronger external teacher. Yet in math reasoning the gains are inconsistent, even when the same approach succeeds elsewhere. A pointwise mutual information analysis traces the failure to the privileged context itself: it inflates the teacher's confidence on tokens already implied by the solution (structural connectives, verifiable claims) and deflates it on deliberation tokens ("Wait", "Let", "Maybe") that drive multi-step search. We propose Anti-Self-Distillation (AntiSD), which ascends a divergence between student and teacher rather than descending it: this reverses the per-token sign and yields a naturally bounded advantage in one step. An entropy-triggered gate disables the term once the teacher entropy collapses, completing a drop-in replacement for default self-distillation. Across five models from 4B to 30B parameters on math reasoning benchmarks, AntiSD reaches the GRPO baseline's accuracy in 2 to 10x fewer training steps and improves final accuracy by up to 11.5 points. AntiSD opens a path to scalable self-improvement, where a language model bootstraps its own reasoning through its training signal.
Bootstrapping Exploration with Group-Level Natural Language Feedback in Reinforcement Learning
Mar 04, 2026Large language models (LLMs) typically receive diverse natural language (NL) feedback through interaction with the environment. However, current reinforcement learning (RL) algorithms rely solely on scalar rewards, leaving the rich information in NL feedback underutilized and leading to inefficient exploration. In this work, we propose GOLF, an RL framework that explicitly exploits group-level language feedback to guide targeted exploration through actionable refinements. GOLF aggregates two complementary feedback sources: (i) external critiques that pinpoint errors or propose targeted fixes, and (ii) intra-group attempts that supply alternative partial ideas and diverse failure patterns. These group-level feedbacks are aggregated to produce high-quality refinements, which are adaptively injected into training as off-policy scaffolds to provide targeted guidance in sparse-reward regions. Meanwhile, GOLF jointly optimizes generation and refinement within a unified RL loop, creating a virtuous cycle that continuously improves both capabilities. Experiments on both verifiable and non-verifiable benchmarks show that GOLF achieves superior performance and exploration efficiency, achieving 2.2$\times$ improvements in sample efficiency compared to RL methods trained solely on scalar rewards. Code is available at https://github.com/LuckyyySTA/GOLF.
REDSearcher: A Scalable and Cost-Efficient Framework for Long-Horizon Search Agents
Feb 15, 2026Large language models are transitioning from generalpurpose knowledge engines to realworld problem solvers, yet optimizing them for deep search tasks remains challenging. The central bottleneck lies in the extreme sparsity of highquality search trajectories and reward signals, arising from the difficulty of scalable longhorizon task construction and the high cost of interactionheavy rollouts involving external tool calls. To address these challenges, we propose REDSearcher, a unified framework that codesigns complex task synthesis, midtraining, and posttraining for scalable searchagent optimization. Specifically, REDSearcher introduces the following improvements: (1) We frame task synthesis as a dualconstrained optimization, where task difficulty is precisely governed by graph topology and evidence dispersion, allowing scalable generation of complex, highquality tasks. (2) We introduce toolaugmented queries to encourage proactive tool use rather than passive recall.(3) During midtraining, we strengthen core atomic capabilities knowledge, planning, and function calling substantially reducing the cost of collecting highquality trajectories for downstream training. (4) We build a local simulated environment that enables rapid, lowcost algorithmic iteration for reinforcement learning experiments. Across both textonly and multimodal searchagent benchmarks, our approach achieves stateoftheart performance. To facilitate future research on longhorizon search agents, we will release 10K highquality complex text search trajectories, 5K multimodal trajectories and 1K text RL query set, and together with code and model checkpoints.
VESPO: Variational Sequence-Level Soft Policy Optimization for Stable Off-Policy LLM Training
Feb 11, 2026Training stability remains a central challenge in reinforcement learning (RL) for large language models (LLMs). Policy staleness, asynchronous training, and mismatches between training and inference engines all cause the behavior policy to diverge from the current policy, risking training collapse. Importance sampling provides a principled correction for this distribution shift but suffers from high variance; existing remedies such as token-level clipping and sequence-level normalization lack a unified theoretical foundation. We propose Variational sEquence-level Soft Policy Optimization (VESPO). By incorporating variance reduction into a variational formulation over proposal distributions, VESPO derives a closed-form reshaping kernel that operates directly on sequence-level importance weights without length normalization. Experiments on mathematical reasoning benchmarks show that VESPO maintains stable training under staleness ratios up to 64x and fully asynchronous execution, and delivers consistent gains across both dense and Mixture-of-Experts models. Code is available at https://github.com/FloyedShen/VESPO
DeepEyesV2: Toward Agentic Multimodal Model
Nov 10, 2025Agentic multimodal models should not only comprehend text and images, but also actively invoke external tools, such as code execution environments and web search, and integrate these operations into reasoning. In this work, we introduce DeepEyesV2 and explore how to build an agentic multimodal model from the perspectives of data construction, training methods, and model evaluation. We observe that direct reinforcement learning alone fails to induce robust tool-use behavior. This phenomenon motivates a two-stage training pipeline: a cold-start stage to establish tool-use patterns, and reinforcement learning stage to further refine tool invocation. We curate a diverse, moderately challenging training dataset, specifically including examples where tool use is beneficial. We further introduce RealX-Bench, a comprehensive benchmark designed to evaluate real-world multimodal reasoning, which inherently requires the integration of multiple capabilities, including perception, search, and reasoning. We evaluate DeepEyesV2 on RealX-Bench and other representative benchmarks, demonstrating its effectiveness across real-world understanding, mathematical reasoning, and search-intensive tasks. Moreover, DeepEyesV2 exhibits task-adaptive tool invocation, tending to use image operations for perception tasks and numerical computations for reasoning tasks. Reinforcement learning further enables complex tool combinations and allows model to selectively invoke tools based on context. We hope our study can provide guidance for community in developing agentic multimodal models.
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning
May 20, 2025Large Vision-Language Models (VLMs) have shown strong capabilities in multimodal understanding and reasoning, yet they are primarily constrained by text-based reasoning processes. However, achieving seamless integration of visual and textual reasoning which mirrors human cognitive processes remains a significant challenge. In particular, effectively incorporating advanced visual input processing into reasoning mechanisms is still an open question. Thus, in this paper, we explore the interleaved multimodal reasoning paradigm and introduce DeepEyes, a model with "thinking with images" capabilities incentivized through end-to-end reinforcement learning without the need for cold-start SFT. Notably, this ability emerges natively within the model itself, leveraging its inherent grounding ability as a tool instead of depending on separate specialized models. Specifically, we propose a tool-use-oriented data selection mechanism and a reward strategy to encourage successful tool-assisted reasoning trajectories. DeepEyes achieves significant performance gains on fine-grained perception and reasoning benchmarks and also demonstrates improvement in grounding, hallucination, and mathematical reasoning tasks. Interestingly, we observe the distinct evolution of tool-calling behavior from initial exploration to efficient and accurate exploitation, and diverse thinking patterns that closely mirror human visual reasoning processes. Code is available at https://github.com/Visual-Agent/DeepEyes.
The Adversarial Attack and Detection under the Fisher Information Metric
Oct 09, 2018


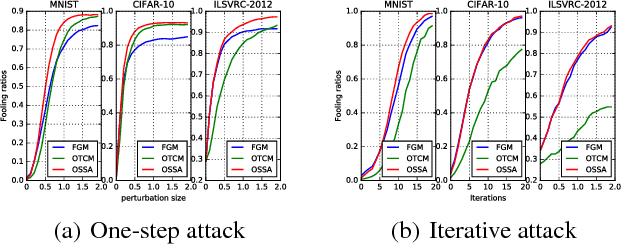
Many deep learning models are vulnerable to the adversarial attack, i.e., imperceptible but intentionally-designed perturbations to the input can cause incorrect output of the networks. In this paper, using information geometry, we provide a reasonable explanation for the vulnerability of deep learning models. By considering the data space as a non-linear space with the Fisher information metric induced from a neural network, we first propose an adversarial attack algorithm termed one-step spectral attack (OSSA). The method is described by a constrained quadratic form of the Fisher information matrix, where the optimal adversarial perturbation is given by the first eigenvector, and the model vulnerability is reflected by the eigenvalues. The larger an eigenvalue is, the more vulnerable the model is to be attacked by the corresponding eigenvector. Taking advantage of the property, we also propose an adversarial detection method with the eigenvalues serving as characteristics. Both our attack and detection algorithms are numerically optimized to work efficiently on large datasets. Our evaluations show superior performance compared with other methods, implying that the Fisher information is a promising approach to investigate the adversarial attacks and defenses.