 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Updating Street Maps using Changes Detected in Satellite Imagery
Oct 13, 2021

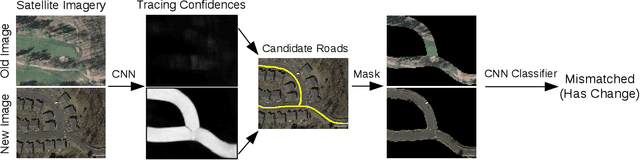


Accurately maintaining digital street maps is labor-intensive. To address this challenge, much work has studied automatically processing geospatial data sources such as GPS trajectories and satellite images to reduce the cost of maintaining digital maps. An end-to-end map update system would first process geospatial data sources to extract insights, and second leverage those insights to update and improve the map. However, prior work largely focuses on the first step of this pipeline: these map extraction methods infer road networks from scratch given geospatial data sources (in effect creating entirely new maps), but do not address the second step of leveraging this extracted information to update the existing digital map data. In this paper, we first explain why current map extraction techniques yield low accuracy when extended to update existing maps. We then propose a novel method that leverages the progression of satellite imagery over time to substantially improve accuracy. Our approach first compares satellite images captured at different times to identify portions of the physical road network that have visibly changed, and then updates the existing map accordingly. We show that our change-based approach reduces map update error rates four-fold.
Harnessing the Conditioning Sensorium for Improved Image Translation
Oct 13, 2021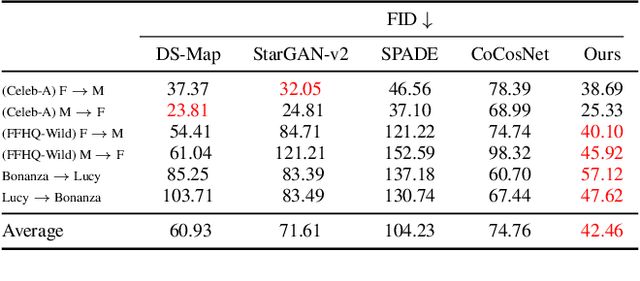
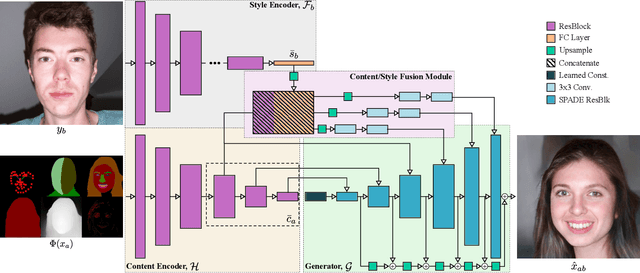


Multi-modal domain translation typically refers to synthesizing a novel image that inherits certain localized attributes from a 'content' image (e.g. layout, semantics, or geometry), and inherits everything else (e.g. texture, lighting, sometimes even semantics) from a 'style' image. The dominant approach to this task is attempting to learn disentangled 'content' and 'style' representations from scratch. However, this is not only challenging, but ill-posed, as what users wish to preserve during translation varies depending on their goals. Motivated by this inherent ambiguity, we define 'content' based on conditioning information extracted by off-the-shelf pre-trained models. We then train our style extractor and image decoder with an easy to optimize set of reconstruction objectives. The wide variety of high-quality pre-trained models available and simple training procedure makes our approach straightforward to apply across numerous domains and definitions of 'content'. Additionally it offers intuitive control over which aspects of 'content' are preserved across domains. We evaluate our method on traditional, well-aligned, datasets such as CelebA-HQ, and propose two novel datasets for evaluation on more complex scenes: ClassicTV and FFHQ-Wild. Our approach, Sensorium, enables higher quality domain translation for more complex scenes.
Dendritic Self-Organizing Maps for Continual Learning
Oct 18, 2021

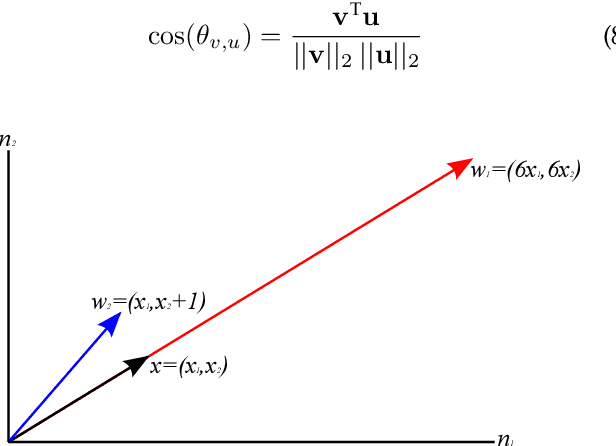
Current deep learning architectures show remarkable performance when trained in large-scale, controlled datasets. However, the predictive ability of these architectures significantly decreases when learning new classes incrementally. This is due to their inclination to forget the knowledge acquired from previously seen data, a phenomenon termed catastrophic-forgetting. On the other hand, Self-Organizing Maps (SOMs) can model the input space utilizing constrained k-means and thus maintain past knowledge. Here, we propose a novel algorithm inspired by biological neurons, termed Dendritic-Self-Organizing Map (DendSOM). DendSOM consists of a single layer of SOMs, which extract patterns from specific regions of the input space accompanied by a set of hit matrices, one per SOM, which estimate the association between units and labels. The best-matching unit of an input pattern is selected using the maximum cosine similarity rule, while the point-wise mutual information is employed for class inference. DendSOM performs unsupervised feature extraction as it does not use labels for targeted updating of the weights. It outperforms classical SOMs and several state-of-the-art continual learning algorithms on benchmark datasets, such as the Split-MNIST and Split-CIFAR-10. We propose that the incorporation of neuronal properties in SOMs may help remedy catastrophic forgetting.
To Beta or Not To Beta: Information Bottleneck for DigitaL Image Forensics
Aug 11, 2019

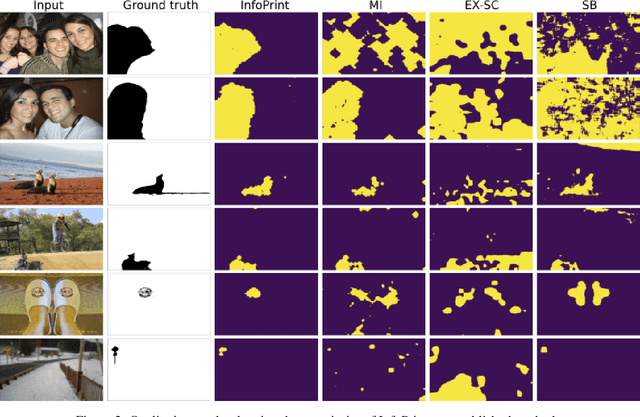
We consider an information theoretic approach to address the problem of identifying fake digital images. We propose an innovative method to formulate the issue of localizing manipulated regions in an image as a deep representation learning problem using the Information Bottleneck (IB), which has recently gained popularity as a framework for interpreting deep neural networks. Tampered images pose a serious predicament since digitized media is a ubiquitous part of our lives. These are facilitated by the easy availability of image editing software and aggravated by recent advances in deep generative models such as GANs. We propose InfoPrint, a computationally efficient solution to the IB formulation using approximate variational inference and compare it to a numerical solution that is computationally expensive. Testing on a number of standard datasets, we demonstrate that InfoPrint outperforms the state-of-the-art and the numerical solution. Additionally, it also has the ability to detect alterations made by inpainting GANs.
A surprisal--duration trade-off across and within the world's languages
Sep 30, 2021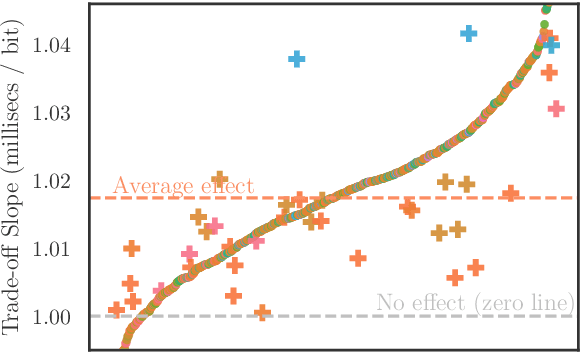
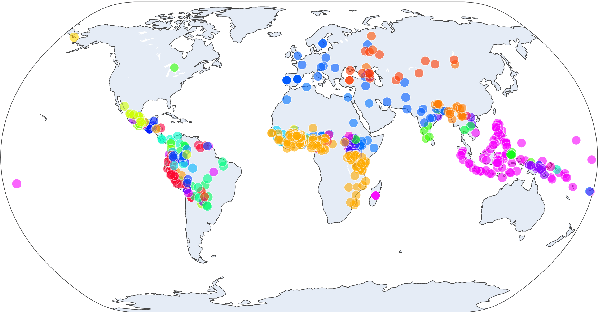
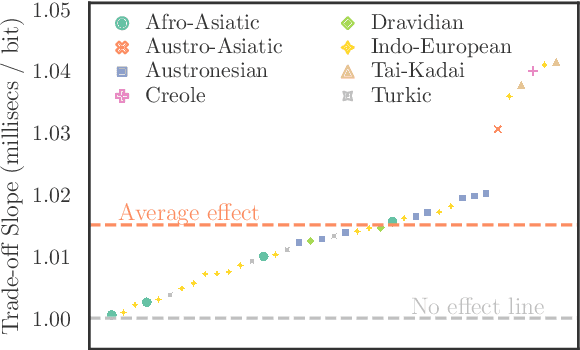
While there exist scores of natural languages, each with its unique features and idiosyncrasies, they all share a unifying theme: enabling human communication. We may thus reasonably predict that human cognition shapes how these languages evolve and are used. Assuming that the capacity to process information is roughly constant across human populations, we expect a surprisal--duration trade-off to arise both across and within languages. We analyse this trade-off using a corpus of 600 languages and, after controlling for several potential confounds, we find strong supporting evidence in both settings. Specifically, we find that, on average, phones are produced faster in languages where they are less surprising, and vice versa. Further, we confirm that more surprising phones are longer, on average, in 319 languages out of the 600. We thus conclude that there is strong evidence of a surprisal--duration trade-off in operation, both across and within the world's languages.
Learning Meta-class Memory for Few-Shot Semantic Segmentation
Aug 16, 2021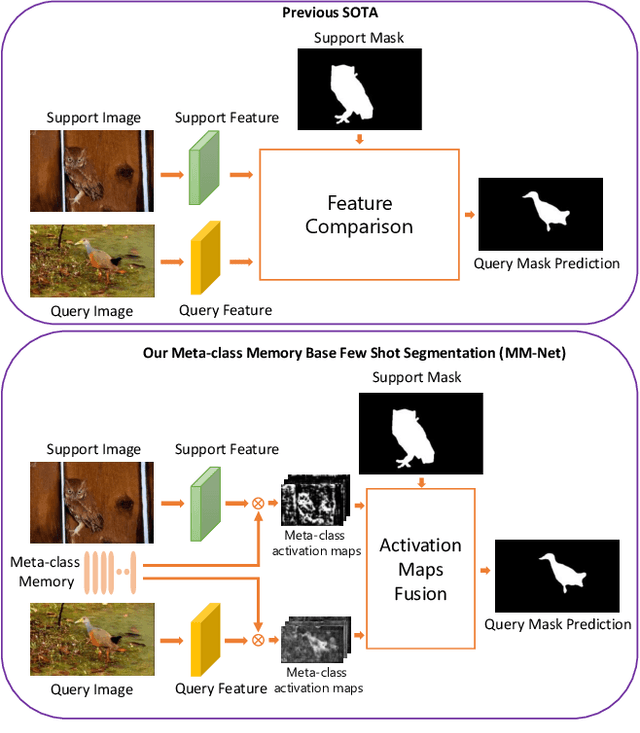
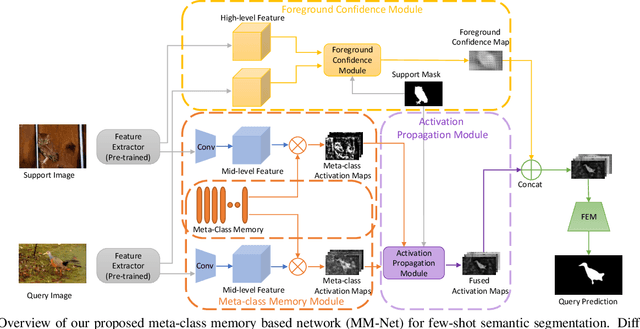
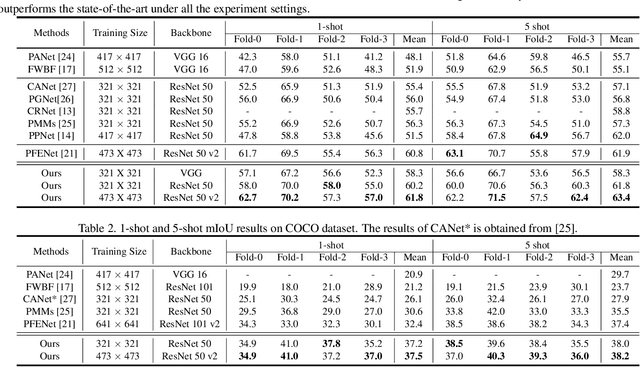
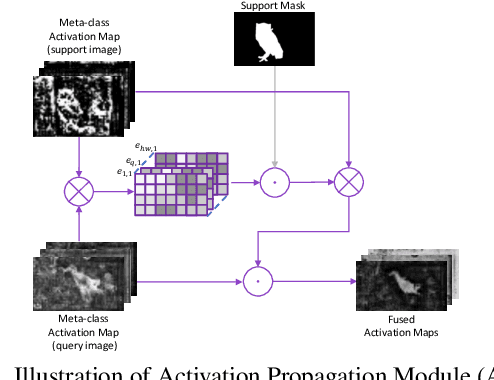
Currently, the state-of-the-art methods treat few-shot semantic segmentation task as a conditional foreground-background segmentation problem, assuming each class is independent. In this paper, we introduce the concept of meta-class, which is the meta information (e.g. certain middle-level features) shareable among all classes. To explicitly learn meta-class representations in few-shot segmentation task, we propose a novel Meta-class Memory based few-shot segmentation method (MM-Net), where we introduce a set of learnable memory embeddings to memorize the meta-class information during the base class training and transfer to novel classes during the inference stage. Moreover, for the $k$-shot scenario, we propose a novel image quality measurement module to select images from the set of support images. A high-quality class prototype could be obtained with the weighted sum of support image features based on the quality measure. Experiments on both PASCAL-$5^i$ and COCO dataset shows that our proposed method is able to achieve state-of-the-art results in both 1-shot and 5-shot settings. Particularly, our proposed MM-Net achieves 37.5\% mIoU on the COCO dataset in 1-shot setting, which is 5.1\% higher than the previous state-of-the-art.
Syntactic Persistence in Language Models: Priming as a Window into Abstract Language Representations
Sep 30, 2021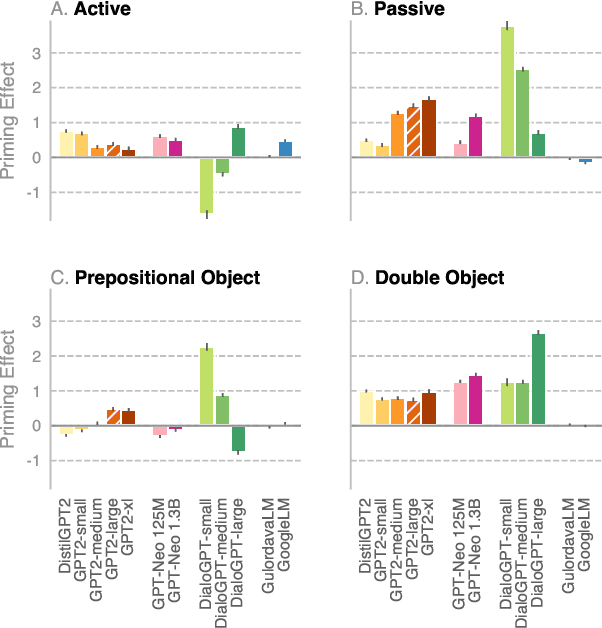
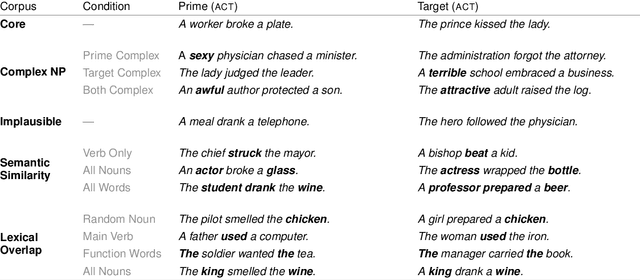
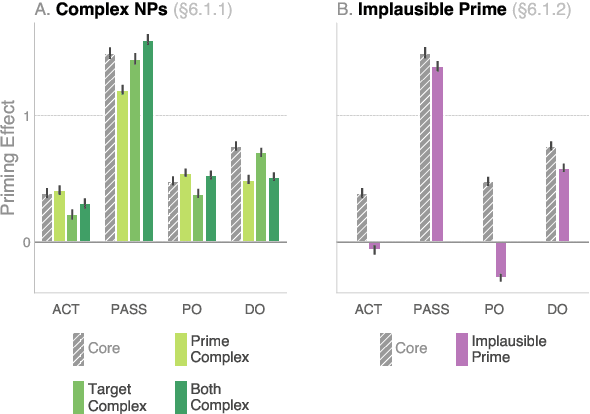

We investigate the extent to which modern, neural language models are susceptible to syntactic priming, the phenomenon where the syntactic structure of a sentence makes the same structure more probable in a follow-up sentence. We explore how priming can be used to study the nature of the syntactic knowledge acquired by these models. We introduce a novel metric and release Prime-LM, a large corpus where we control for various linguistic factors which interact with priming strength. We find that recent large Transformer models indeed show evidence of syntactic priming, but also that the syntactic generalisations learned by these models are to some extent modulated by semantic information. We report surprisingly strong priming effects when priming with multiple sentences, each with different words and meaning but with identical syntactic structure. We conclude that the syntactic priming paradigm is a highly useful, additional tool for gaining insights into the capacities of language models.
Leveraging MoCap Data for Human Mesh Recovery
Oct 18, 2021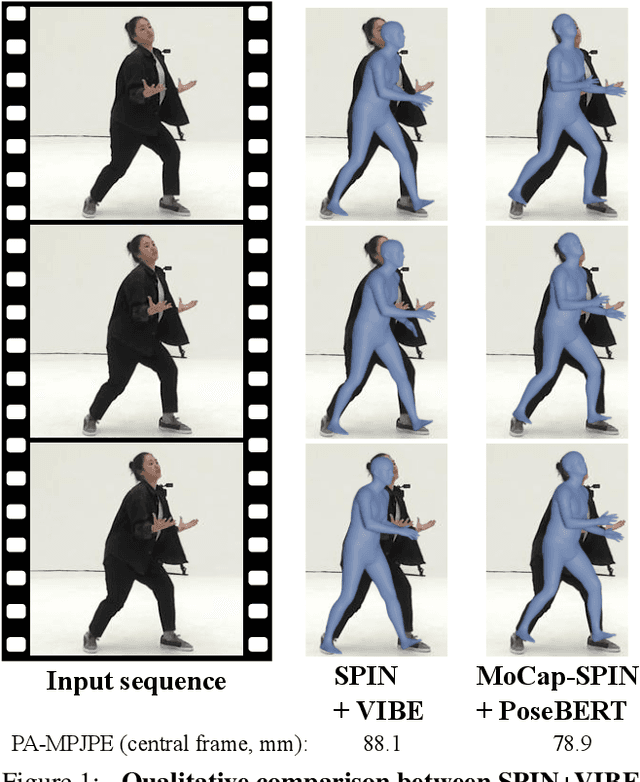
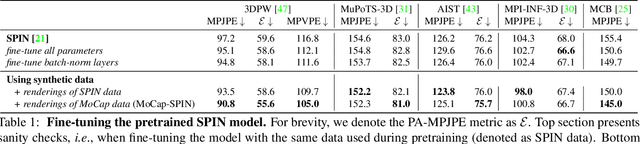


Training state-of-the-art models for human body pose and shape recovery from images or videos requires datasets with corresponding annotations that are really hard and expensive to obtain. Our goal in this paper is to study whether poses from 3D Motion Capture (MoCap) data can be used to improve image-based and video-based human mesh recovery methods. We find that fine-tune image-based models with synthetic renderings from MoCap data can increase their performance, by providing them with a wider variety of poses, textures and backgrounds. In fact, we show that simply fine-tuning the batch normalization layers of the model is enough to achieve large gains. We further study the use of MoCap data for video, and introduce PoseBERT, a transformer module that directly regresses the pose parameters and is trained via masked modeling. It is simple, generic and can be plugged on top of any state-of-the-art image-based model in order to transform it in a video-based model leveraging temporal information. Our experimental results show that the proposed approaches reach state-of-the-art performance on various datasets including 3DPW, MPI-INF-3DHP, MuPoTS-3D, MCB and AIST. Test code and models will be available soon.
Early Myocardial Infarction Detection over Multi-view Echocardiography
Nov 09, 2021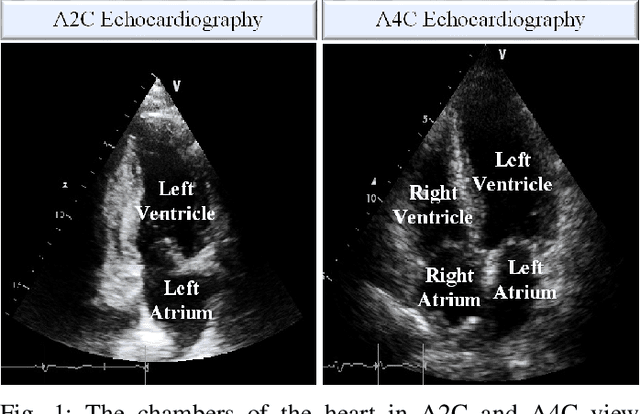
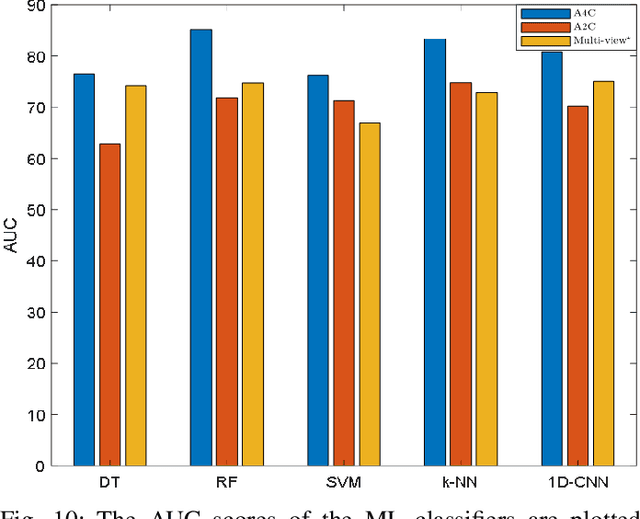
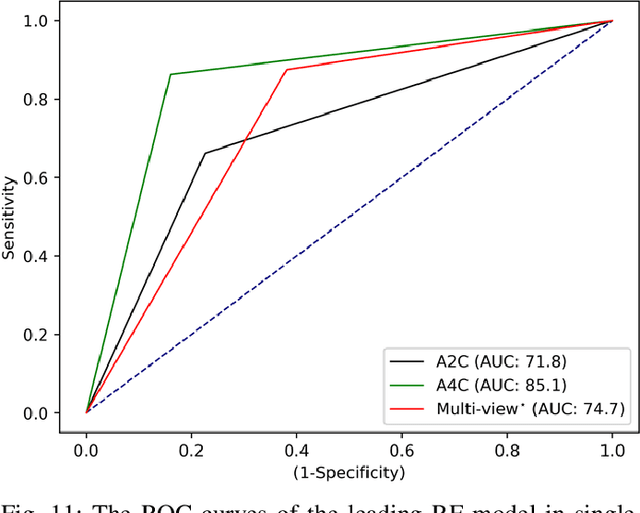
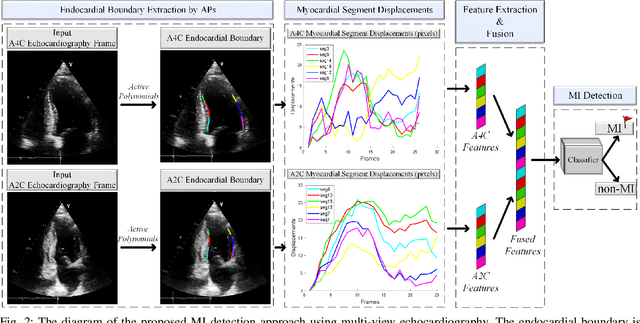
Myocardial infarction (MI) is the leading cause of mortality in the world that occurs due to a blockage of the coronary arteries feeding the myocardium. An early diagnosis of MI and its localization can mitigate the extent of myocardial damage by facilitating early therapeutic interventions. Following the blockage of a coronary artery, the regional wall motion abnormality (RWMA) of the ischemic myocardial segments is the earliest change to set in. Echocardiography is the fundamental tool to assess any RWMA. Assessing the motion of the left ventricle (LV) wall only from a single echocardiography view may lead to missing the diagnosis of MI as the RWMA may not be visible on that specific view. Therefore, in this study, we propose to fuse apical 4-chamber (A4C) and apical 2-chamber (A2C) views in which a total of 11 myocardial segments can be analyzed for MI detection. The proposed method first estimates the motion of the LV wall by Active Polynomials (APs), which extract and track the endocardial boundary to compute myocardial segment displacements. The features are extracted from the A4C and A2C view displacements, which are fused and fed into the classifiers to detect MI. The main contributions of this study are 1) creation of a new benchmark dataset by including both A4C and A2C views in a total of 260 echocardiography recordings, which is publicly shared with the research community, 2) improving the performance of the prior work of threshold-based APs by a Machine Learning based approach, and 3) a pioneer MI detection approach via multi-view echocardiography by fusing the information of A4C and A2C views. Experimental results show that the proposed method achieves 90.91% sensitivity and 86.36% precision for MI detection over multi-view echocardiography.
On the Prunability of Attention Heads in Multilingual BERT
Sep 26, 2021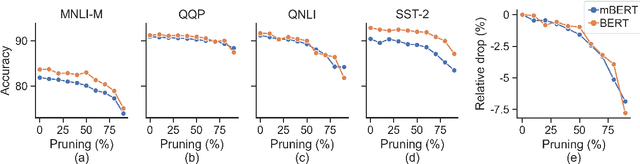
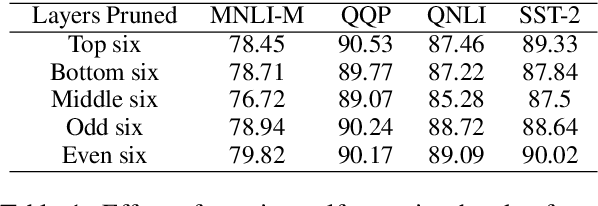
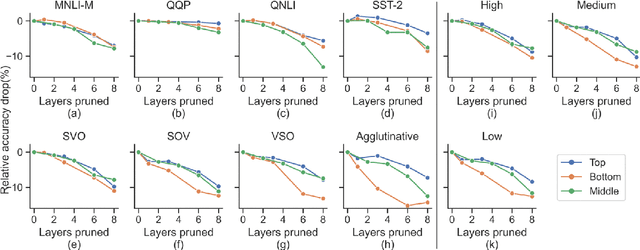
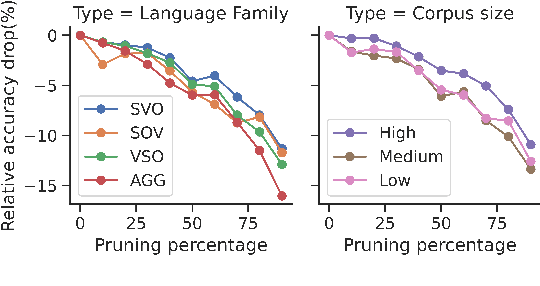
Large multilingual models, such as mBERT, have shown promise in crosslingual transfer. In this work, we employ pruning to quantify the robustness and interpret layer-wise importance of mBERT. On four GLUE tasks, the relative drops in accuracy due to pruning have almost identical results on mBERT and BERT suggesting that the reduced attention capacity of the multilingual models does not affect robustness to pruning. For the crosslingual task XNLI, we report higher drops in accuracy with pruning indicating lower robustness in crosslingual transfer. Also, the importance of the encoder layers sensitively depends on the language family and the pre-training corpus size. The top layers, which are relatively more influenced by fine-tuning, encode important information for languages similar to English (SVO) while the bottom layers, which are relatively less influenced by fine-tuning, are particularly important for agglutinative and low-resource languages.