 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Bayesian Framework for Gradient Leakage
Nov 08, 2021
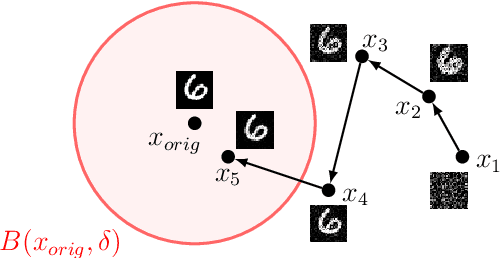

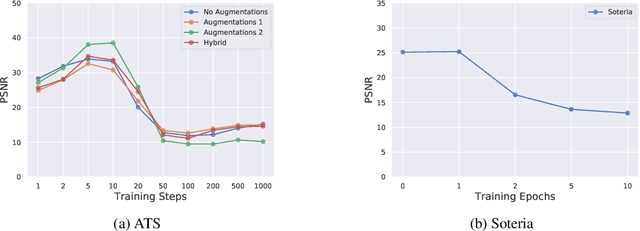
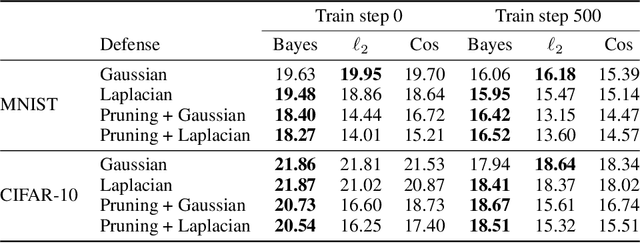
Federated learning is an established method for training machine learning models without sharing training data. However, recent work has shown that it cannot guarantee data privacy as shared gradients can still leak sensitive information. To formalize the problem of gradient leakage, we propose a theoretical framework that enables, for the first time, analysis of the Bayes optimal adversary phrased as an optimization problem. We demonstrate that existing leakage attacks can be seen as approximations of this optimal adversary with different assumptions on the probability distributions of the input data and gradients. Our experiments confirm the effectiveness of the Bayes optimal adversary when it has knowledge of the underlying distribution. Further, our experimental evaluation shows that several existing heuristic defenses are not effective against stronger attacks, especially early in the training process. Thus, our findings indicate that the construction of more effective defenses and their evaluation remains an open problem.
Selecting the suitable resampling strategy for imbalanced data classification regarding dataset properties
Dec 15, 2021
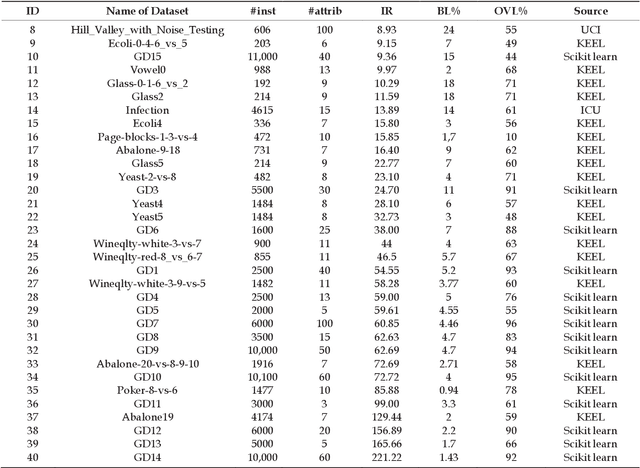
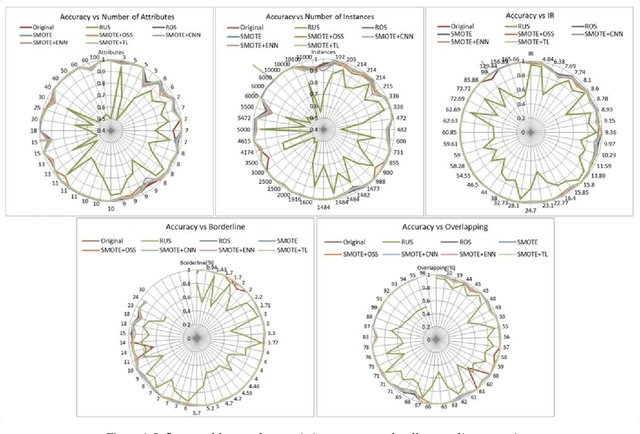
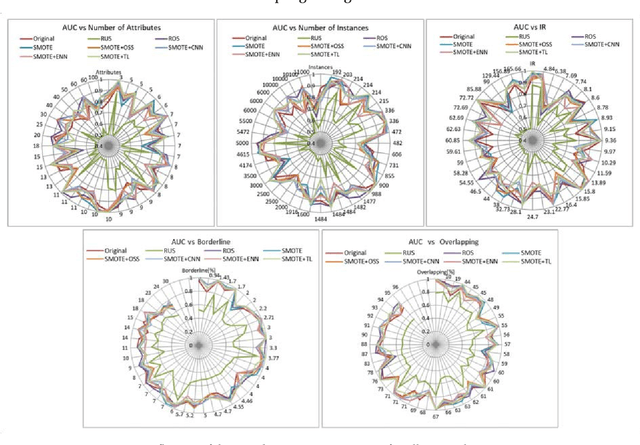
In many application domains such as medicine, information retrieval, cybersecurity, social media, etc., datasets used for inducing classification models often have an unequal distribution of the instances of each class. This situation, known as imbalanced data classification, causes low predictive performance for the minority class examples. Thus, the prediction model is unreliable although the overall model accuracy can be acceptable. Oversampling and undersampling techniques are well-known strategies to deal with this problem by balancing the number of examples of each class. However, their effectiveness depends on several factors mainly related to data intrinsic characteristics, such as imbalance ratio, dataset size and dimensionality, overlapping between classes or borderline examples. In this work, the impact of these factors is analyzed through a comprehensive comparative study involving 40 datasets from different application areas. The objective is to obtain models for automatic selection of the best resampling strategy for any dataset based on its characteristics. These models allow us to check several factors simultaneously considering a wide range of values since they are induced from very varied datasets that cover a broad spectrum of conditions. This differs from most studies that focus on the individual analysis of the characteristics or cover a small range of values. In addition, the study encompasses both basic and advanced resampling strategies that are evaluated by means of eight different performance metrics, including new measures specifically designed for imbalanced data classification. The general nature of the proposal allows the choice of the most appropriate method regardless of the domain, avoiding the search for special purpose techniques that could be valid for the target data.
* Kraiem, M.S., S\'anchez-Hern\'andez, F., Moreno-Garc\'ia, M.N. Selecting the Suitable Resampling Strategy for Imbalanced Data Classification Regarding Dataset Properties. An Approach Based on Association Models. Appl. Sci. 2021, 11(18), 8546, 2021
A Review of Web Infodemic Analysis and Detection Trends across Multi-modalities using Deep Neural Networks
Nov 23, 2021
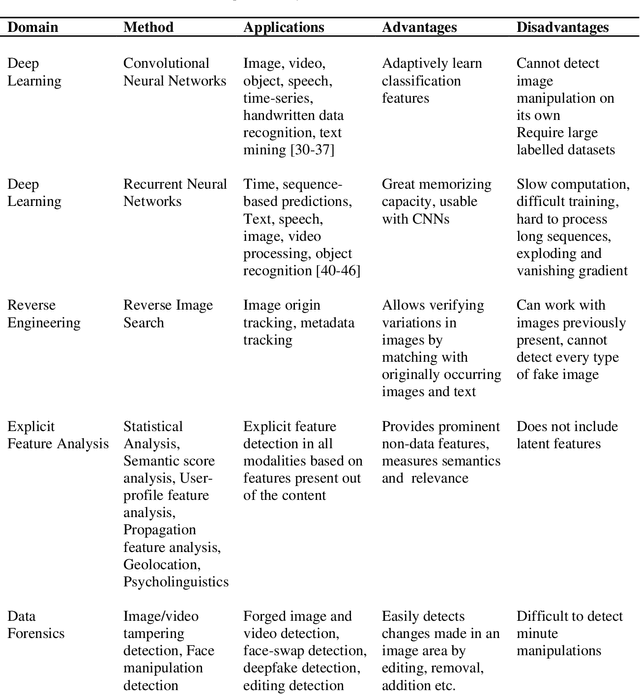

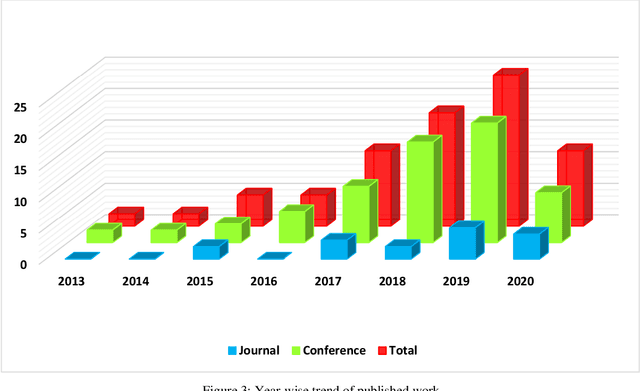
Fake news and misinformation are a matter of concern for people around the globe. Users of the internet and social media sites encounter content with false information much frequently. Fake news detection is one of the most analyzed and prominent areas of research. These detection techniques apply popular machine learning and deep learning algorithms. Previous work in this domain covers fake news detection vastly among text circulating online. Platforms that have extensively been observed and analyzed include news websites and Twitter. Facebook, Reddit, WhatsApp, YouTube, and other social applications are gradually gaining attention in this emerging field. Researchers are analyzing online data based on multiple modalities composed of text, image, video, speech, and other contributing factors. The combination of various modalities has resulted in efficient fake news detection. At present, there is an abundance of surveys consolidating textual fake news detection algorithms. This review primarily deals with multi-modal fake news detection techniques that include images, videos, and their combinations with text. We provide a comprehensive literature survey of eighty articles presenting state-of-the-art detection techniques, thereby identifying research gaps and building a pathway for researchers to further advance this domain.
One System to Rule them All: a Universal Intent Recognition System for Customer Service Chatbots
Dec 15, 2021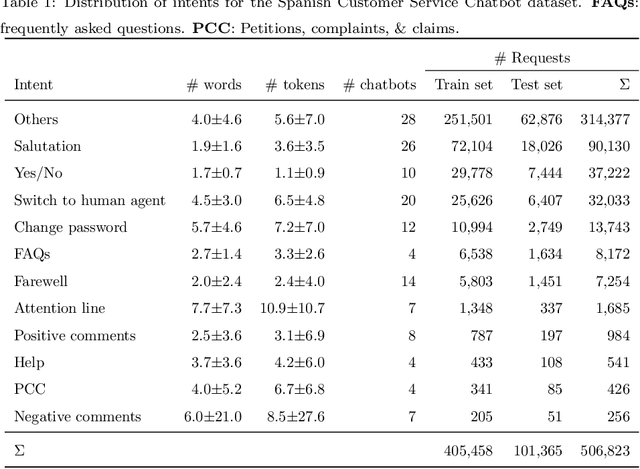
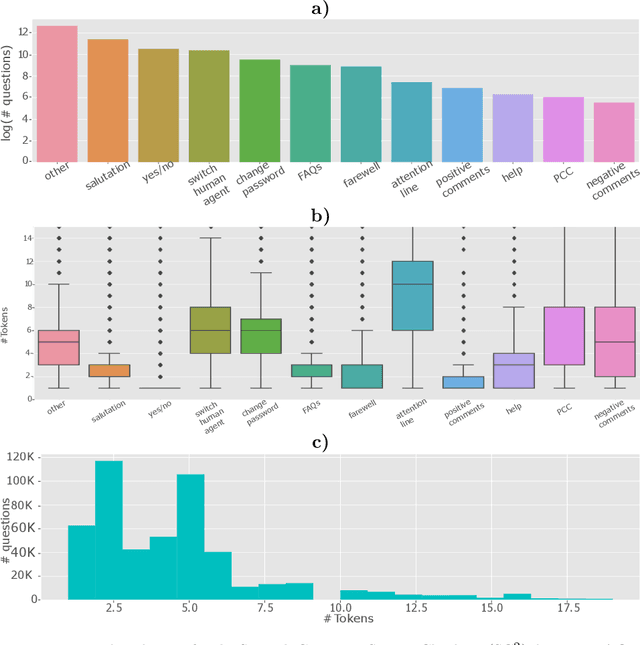
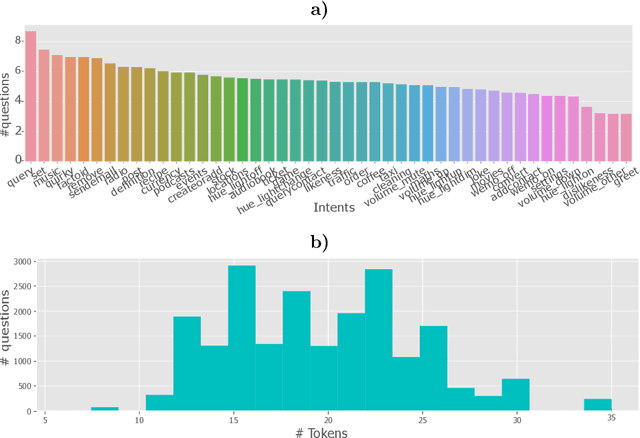
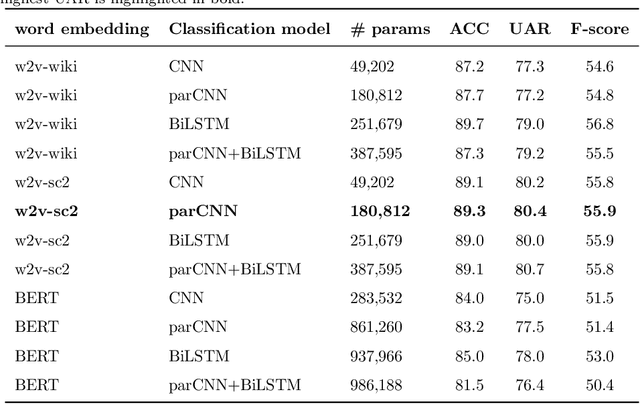
Customer service chatbots are conversational systems designed to provide information to customers about products/services offered by different companies. Particularly, intent recognition is one of the core components in the natural language understating capabilities of a chatbot system. Among the different intents that a chatbot is trained to recognize, there is a set of them that is universal to any customer service chatbot. Universal intents may include salutation, switch the conversation to a human agent, farewells, among others. A system to recognize those universal intents will be very helpful to optimize the training process of specific customer service chatbots. We propose the development of a universal intent recognition system, which is trained to recognize a selected group of 11 intents that are common in 28 different chatbots. The proposed system is trained considering state-of-the-art word-embedding models such as word2vec and BERT, and deep classifiers based on convolutional and recurrent neural networks. The proposed model is able to discriminate between those universal intents with a balanced accuracy up to 80.4\%. In addition, the proposed system is equally accurate to recognize intents expressed both in short and long text requests. At the same time, misclassification errors often occurs between intents with very similar semantic fields such as farewells and positive comments. The proposed system will be very helpful to optimize the training process of a customer service chatbot because some of the intents will be already available and detected by our system. At the same time, the proposed approach will be a suitable base model to train more specific chatbots by applying transfer learning strategies.
Explaining a black-box using Deep Variational Information Bottleneck Approach
Feb 19, 2019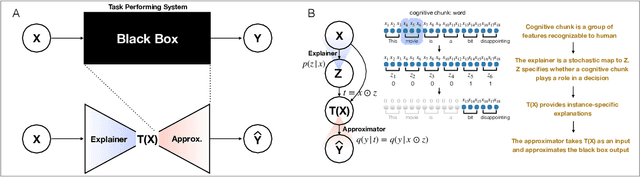
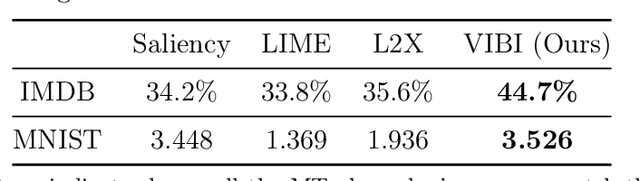

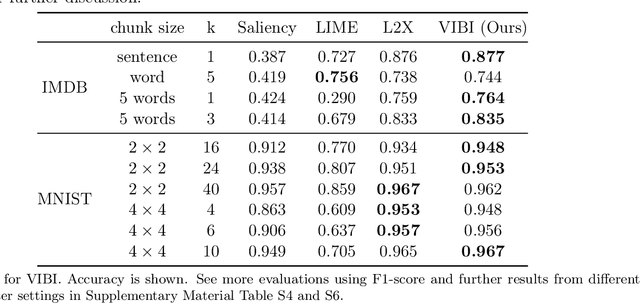
Briefness and comprehensiveness are necessary in order to give a lot of information concisely in explaining a black-box decision system. However, existing interpretable machine learning methods fail to consider briefness and comprehensiveness simultaneously, which may lead to redundant explanations. We propose a system-agnostic interpretable method that provides a brief but comprehensive explanation by adopting the inspiring information theoretic principle, information bottleneck principle. Using an information theoretic objective, VIBI selects instance-wise key features that are maximally compressed about an input (briefness), and informative about a decision made by a black-box on that input (comprehensive). The selected key features act as an information bottleneck that serves as a concise explanation for each black-box decision. We show that VIBI outperforms other interpretable machine learning methods in terms of both interpretability and fidelity evaluated by human and quantitative metrics.
Local Permutation Equivariance For Graph Neural Networks
Nov 23, 2021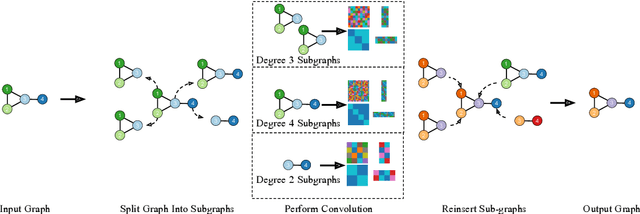
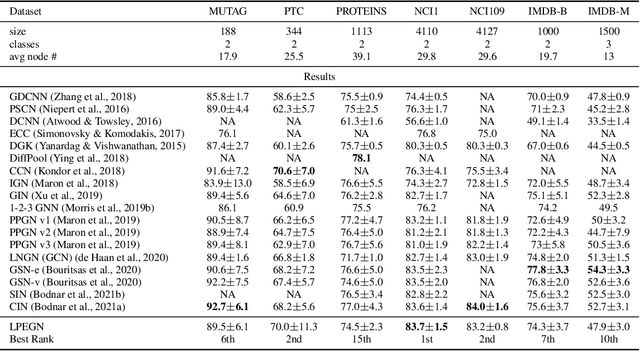

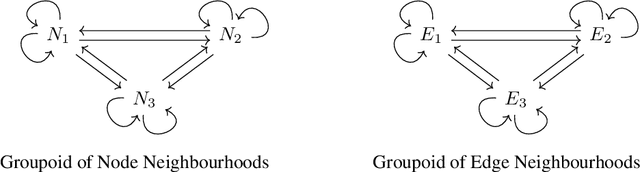
In this work we develop a new method, named locally permutation-equivariant graph neural networks, which provides a framework for building graph neural networks that operate on local node neighbourhoods, through sub-graphs, while using permutation equivariant update functions. Message passing neural networks have been shown to be limited in their expressive power and recent approaches to over come this either lack scalability or require structural information to be encoded into the feature space. The general framework presented here overcomes the scalability issues associated with global permutation equivariance by operating on sub-graphs through restricted representations. In addition, we prove that there is no loss of expressivity by using restricted representations. Furthermore, the proposed framework only requires a choice of $k$-hops for creating sub-graphs and a choice of representation space to be used for each layer, which makes the method easily applicable across a range of graph based domains. We experimentally validate the method on a range of graph benchmark classification tasks, demonstrating either state-of-the-art results or very competitive results on all benchmarks. Further, we demonstrate that the use of local update functions offers a significant improvement in GPU memory over global methods.
CEM: Commonsense-aware Empathetic Response Generation
Sep 13, 2021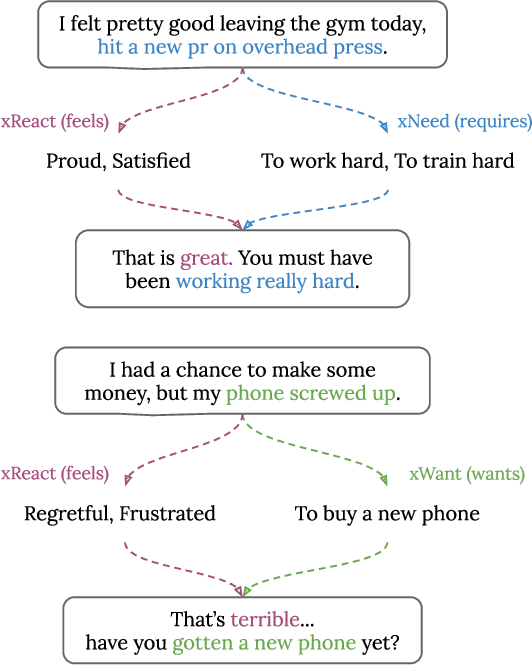

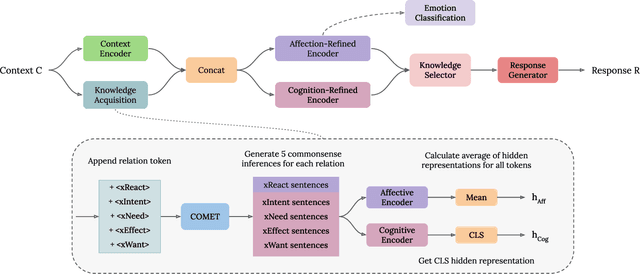
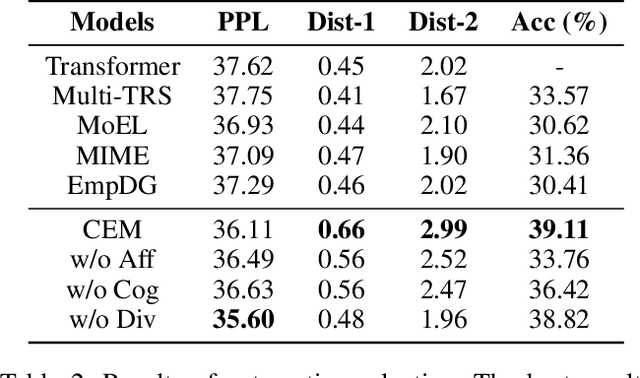
A key trait of daily conversations between individuals is the ability to express empathy towards others, and exploring ways to implement empathy is a crucial step towards human-like dialogue systems. Previous approaches on this topic mainly focus on detecting and utilizing the user's emotion for generating empathetic responses. However, since empathy includes both aspects of affection and cognition, we argue that in addition to identifying the user's emotion, cognitive understanding of the user's situation should also be considered. To this end, we propose a novel approach for empathetic response generation, which leverages commonsense to draw more information about the user's situation and uses this additional information to further enhance the empathy expression in generated responses. We evaluate our approach on EmpatheticDialogues, which is a widely-used benchmark dataset for empathetic response generation. Empirical results demonstrate that our approach outperforms the baseline models in both automatic and human evaluations and can generate more informative and empathetic responses.
Deep Variational Information Bottleneck
Jul 17, 2017
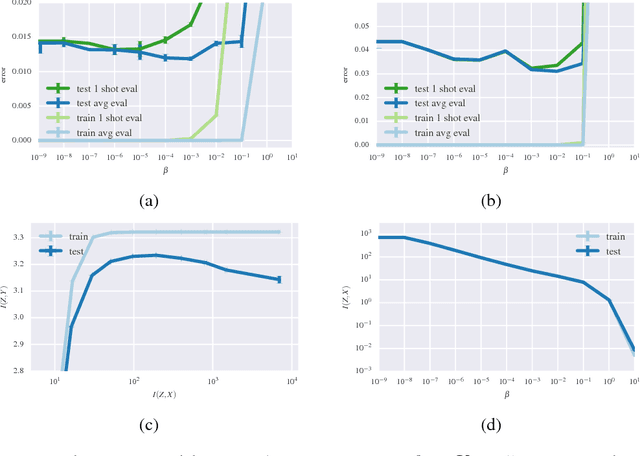
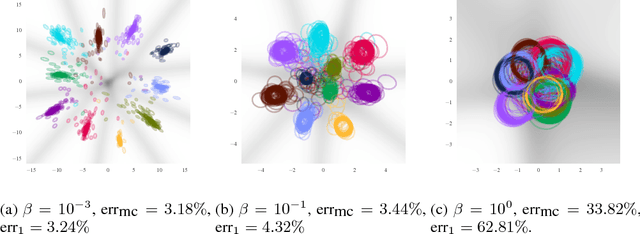
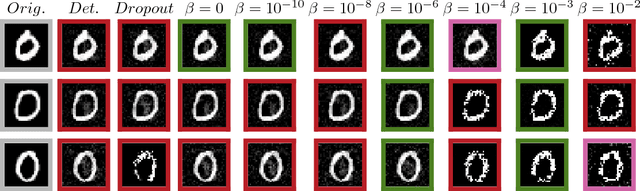
We present a variational approximation to the information bottleneck of Tishby et al. (1999). This variational approach allows us to parameterize the information bottleneck model using a neural network and leverage the reparameterization trick for efficient training. We call this method "Deep Variational Information Bottleneck", or Deep VIB. We show that models trained with the VIB objective outperform those that are trained with other forms of regularization, in terms of generalization performance and robustness to adversarial attack.
Improving Domain Adaptation Translation with Domain Invariant and Specific Information
Apr 08, 2019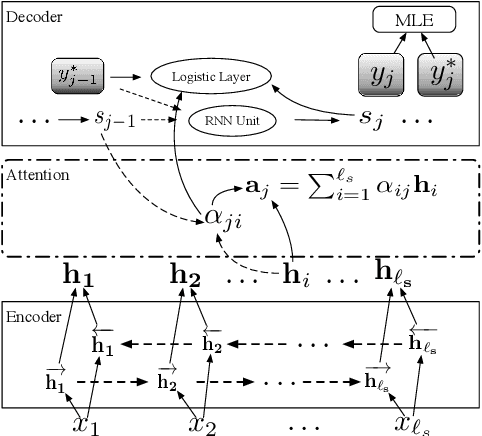
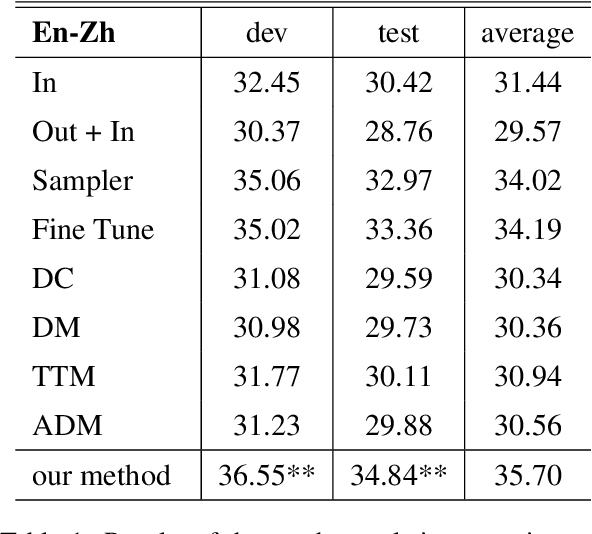
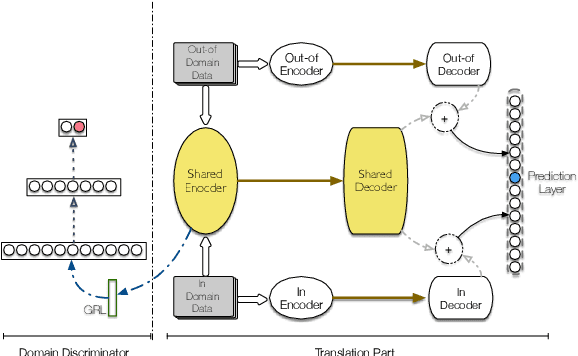
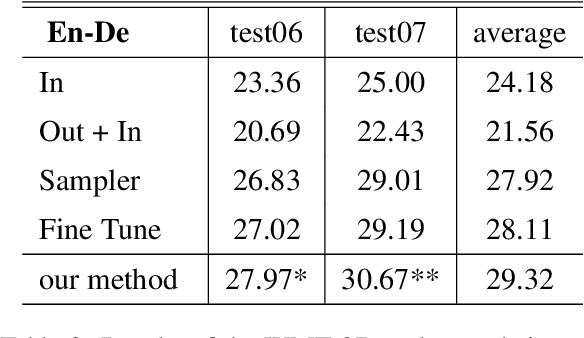
In domain adaptation for neural machine translation, translation performance can benefit from separating features into domain-specific features and common features. In this paper, we propose a method to explicitly model the two kinds of information in the encoder-decoder framework so as to exploit out-of-domain data in in-domain training. In our method, we maintain a private encoder and a private decoder for each domain which are used to model domain-specific information. In the meantime, we introduce a common encoder and a common decoder shared by all the domains which can only have domain-independent information flow through. Besides, we add a discriminator to the shared encoder and employ adversarial training for the whole model to reinforce the performance of information separation and machine translation simultaneously. Experiment results show that our method can outperform competitive baselines greatly on multiple data sets.
Human Age Estimation from Gene Expression Data using Artificial Neural Networks
Nov 05, 2021
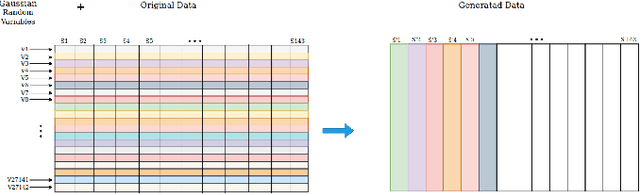
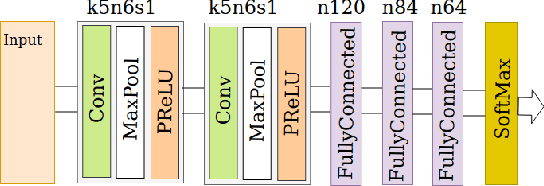
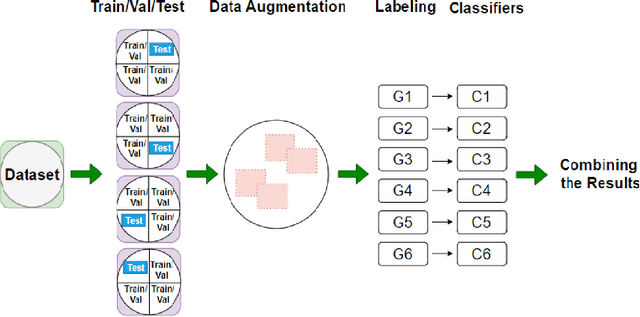
The study of signatures of aging in terms of genomic biomarkers can be uniquely helpful in understanding the mechanisms of aging and developing models to accurately predict the age. Prior studies have employed gene expression and DNA methylation data aiming at accurate prediction of age. In this line, we propose a new framework for human age estimation using information from human dermal fibroblast gene expression data. First, we propose a new spatial representation as well as a data augmentation approach for gene expression data. Next in order to predict the age, we design an architecture of neural network and apply it to this new representation of the original and augmented data, as an ensemble classification approach. Our experimental results suggest the superiority of the proposed framework over state-of-the-art age estimation methods using DNA methylation and gene expression data.