 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Conditional Generative Data-Free Knowledge Distillation based on Attention Transfer
Dec 31, 2021
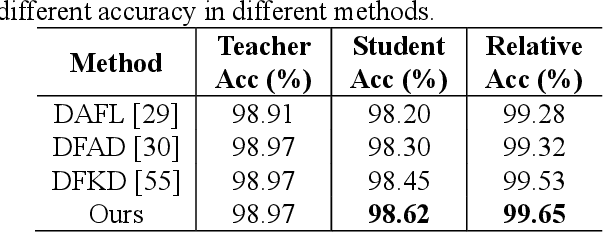

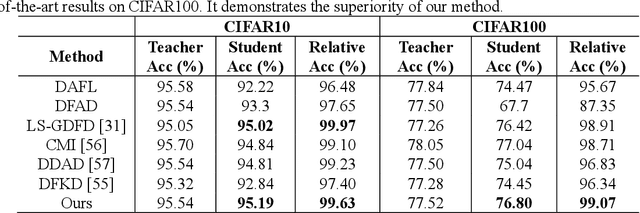
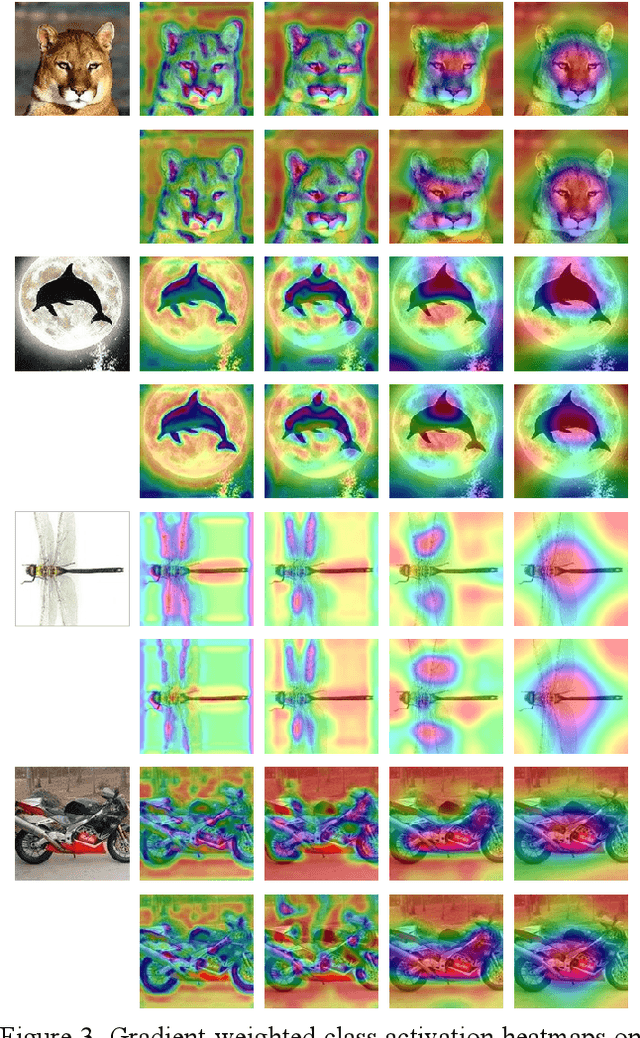
Knowledge distillation has made remarkable achievements in model compression. However, most existing methods demand original training data, while real data in practice are often unavailable due to privacy, security and transmission limitation. To address this problem, we propose a conditional generative data-free knowledge distillation (CGDD) framework to train efficient portable network without any real data. In this framework, except using the knowledge extracted from teacher model, we introduce preset labels as additional auxiliary information to train the generator. Then, the trained generator can produce meaningful training samples of specified category as required. In order to promote distillation process, except using conventional distillation loss, we treat preset label as ground truth label so that student network is directly supervised by the category of synthetic training sample. Moreover, we force student network to mimic the attention maps of teacher model and further improve its performance. To verify the superiority of our method, we design a new evaluation metric is called as relative accuracy to directly compare the effectiveness of different distillation methods. Trained portable network learned with proposed data-free distillation method obtains 99.63%, 99.07% and 99.84% relative accuracy on CIFAR10, CIFAR100 and Caltech101, respectively. The experimental results demonstrate the superiority of proposed method.
Efficient Algorithms for Searching the Minimum Information Partition in Integrated Information Theory
Feb 13, 2018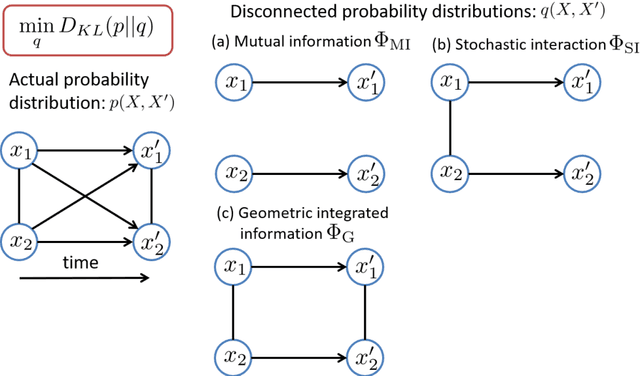
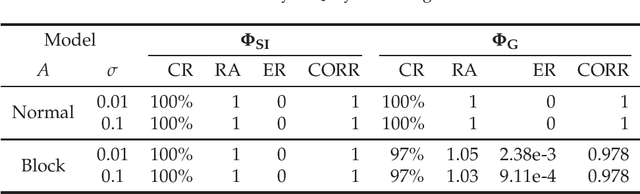
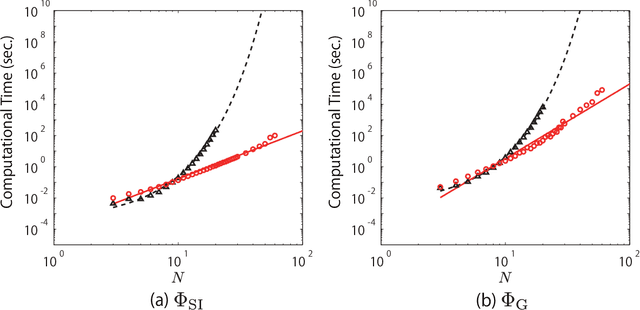
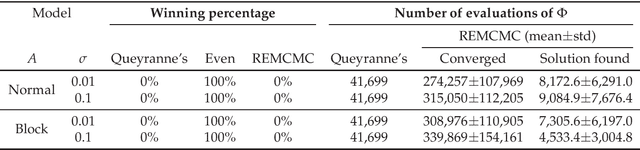
The ability to integrate information in the brain is considered to be an essential property for cognition and consciousness. Integrated Information Theory (IIT) hypothesizes that the amount of integrated information ($\Phi$) in the brain is related to the level of consciousness. IIT proposes that to quantify information integration in a system as a whole, integrated information should be measured across the partition of the system at which information loss caused by partitioning is minimized, called the Minimum Information Partition (MIP). The computational cost for exhaustively searching for the MIP grows exponentially with system size, making it difficult to apply IIT to real neural data. It has been previously shown that if a measure of $\Phi$ satisfies a mathematical property, submodularity, the MIP can be found in a polynomial order by an optimization algorithm. However, although the first version of $\Phi$ is submodular, the later versions are not. In this study, we empirically explore to what extent the algorithm can be applied to the non-submodular measures of $\Phi$ by evaluating the accuracy of the algorithm in simulated data and real neural data. We find that the algorithm identifies the MIP in a nearly perfect manner even for the non-submodular measures. Our results show that the algorithm allows us to measure $\Phi$ in large systems within a practical amount of time.
3DVSR: 3D EPI Volume-based Approach for Angular and Spatial Light field Image Super-resolution
Jan 04, 2022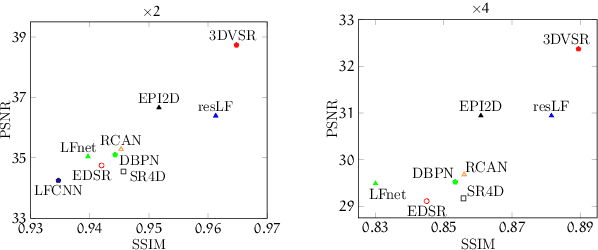
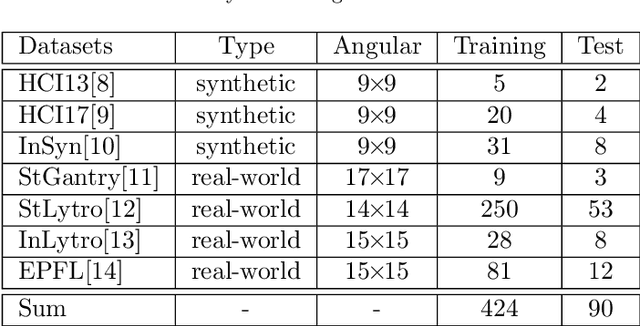

Light field (LF) imaging, which captures both spatial and angular information of a scene, is undoubtedly beneficial to numerous applications. Although various techniques have been proposed for LF acquisition, achieving both angularly and spatially high-resolution LF remains a technology challenge. In this paper, a learning-based approach applied to 3D epipolar image (EPI) is proposed to reconstruct high-resolution LF. Through a 2-stage super-resolution framework, the proposed approach effectively addresses various LF super-resolution (SR) problems, i.e., spatial SR, angular SR, and angular-spatial SR. While the first stage provides flexible options to up-sample EPI volume to the desired resolution, the second stage, which consists of a novel EPI volume-based refinement network (EVRN), substantially enhances the quality of the high-resolution EPI volume. An extensive evaluation on 90 challenging synthetic and real-world light field scenes from 7 published datasets shows that the proposed approach outperforms state-of-the-art methods to a large extend for both spatial and angular super-resolution problem, i.e., an average peak signal to noise ratio improvement of more than 2.0 dB, 1.4 dB, and 3.14 dB in spatial SR $\times 2$, spatial SR $\times 4$, and angular SR respectively. The reconstructed 4D light field demonstrates a balanced performance distribution across all perspective images and presents superior visual quality compared to the previous works.
Global-Local Transformer for Brain Age Estimation
Sep 03, 2021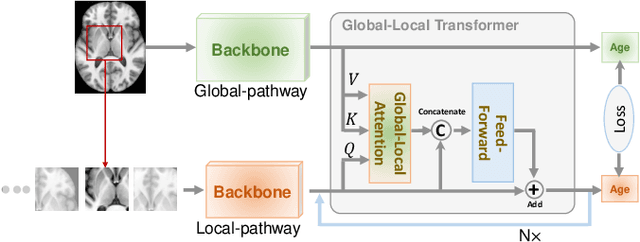
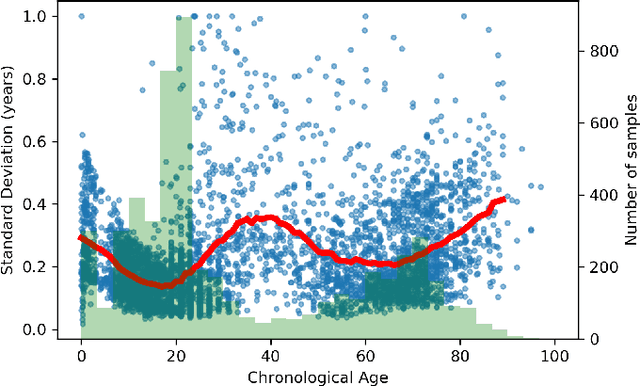
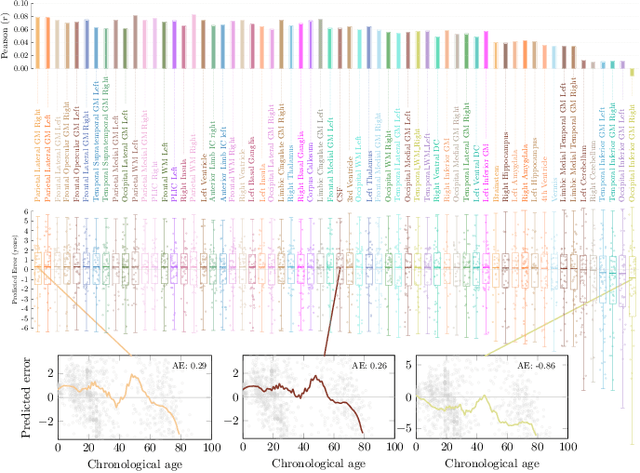
Deep learning can provide rapid brain age estimation based on brain magnetic resonance imaging (MRI). However, most studies use one neural network to extract the global information from the whole input image, ignoring the local fine-grained details. In this paper, we propose a global-local transformer, which consists of a global-pathway to extract the global-context information from the whole input image and a local-pathway to extract the local fine-grained details from local patches. The fine-grained information from the local patches are fused with the global-context information by the attention mechanism, inspired by the transformer, to estimate the brain age. We evaluate the proposed method on 8 public datasets with 8,379 healthy brain MRIs with the age range of 0-97 years. 6 datasets are used for cross-validation and 2 datasets are used for evaluating the generality. Comparing with other state-of-the-art methods, the proposed global-local transformer reduces the mean absolute error of the estimated ages to 2.70 years and increases the correlation coefficient of the estimated age and the chronological age to 0.9853. In addition, our proposed method provides regional information of which local patches are most informative for brain age estimation. Our source code is available on: \url{https://github.com/shengfly/global-local-transformer}.
Cognition-aware Cognate Detection
Dec 15, 2021
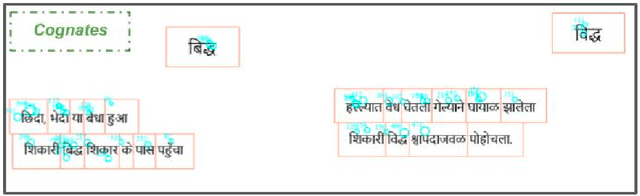

Automatic detection of cognates helps downstream NLP tasks of Machine Translation, Cross-lingual Information Retrieval, Computational Phylogenetics and Cross-lingual Named Entity Recognition. Previous approaches for the task of cognate detection use orthographic, phonetic and semantic similarity based features sets. In this paper, we propose a novel method for enriching the feature sets, with cognitive features extracted from human readers' gaze behaviour. We collect gaze behaviour data for a small sample of cognates and show that extracted cognitive features help the task of cognate detection. However, gaze data collection and annotation is a costly task. We use the collected gaze behaviour data to predict cognitive features for a larger sample and show that predicted cognitive features, also, significantly improve the task performance. We report improvements of 10% with the collected gaze features, and 12% using the predicted gaze features, over the previously proposed approaches. Furthermore, we release the collected gaze behaviour data along with our code and cross-lingual models.
Bayesian Optimization of Function Networks
Dec 31, 2021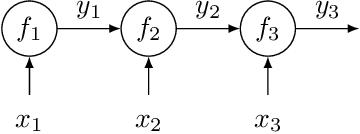
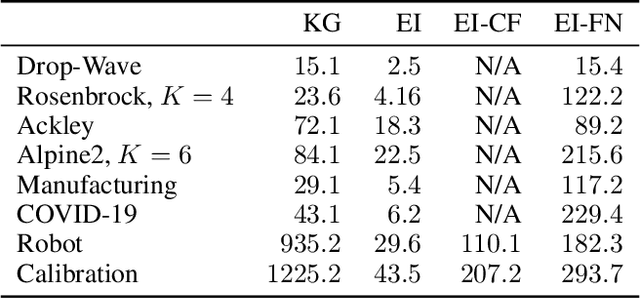
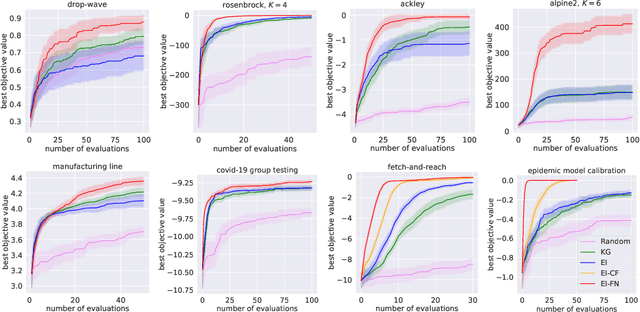
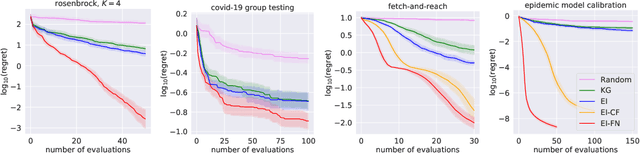
We consider Bayesian optimization of the output of a network of functions, where each function takes as input the output of its parent nodes, and where the network takes significant time to evaluate. Such problems arise, for example, in reinforcement learning, engineering design, and manufacturing. While the standard Bayesian optimization approach observes only the final output, our approach delivers greater query efficiency by leveraging information that the former ignores: intermediate output within the network. This is achieved by modeling the nodes of the network using Gaussian processes and choosing the points to evaluate using, as our acquisition function, the expected improvement computed with respect to the implied posterior on the objective. Although the non-Gaussian nature of this posterior prevents computing our acquisition function in closed form, we show that it can be efficiently maximized via sample average approximation. In addition, we prove that our method is asymptotically consistent, meaning that it finds a globally optimal solution as the number of evaluations grows to infinity, thus generalizing previously known convergence results for the expected improvement. Notably, this holds even though our method might not evaluate the domain densely, instead leveraging problem structure to leave regions unexplored. Finally, we show that our approach dramatically outperforms standard Bayesian optimization methods in several synthetic and real-world problems.
TME-BNA: Temporal Motif-Preserving Network Embedding with Bicomponent Neighbor Aggregation
Oct 26, 2021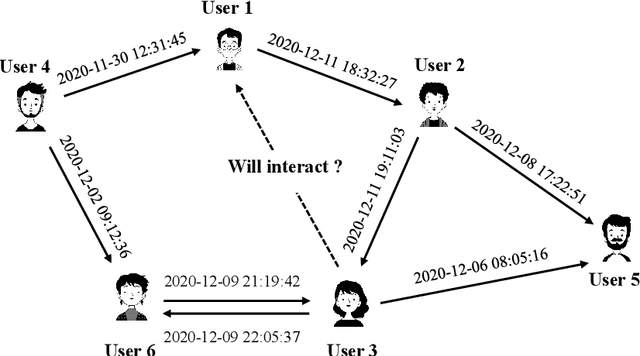
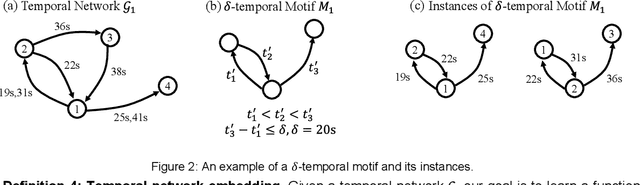
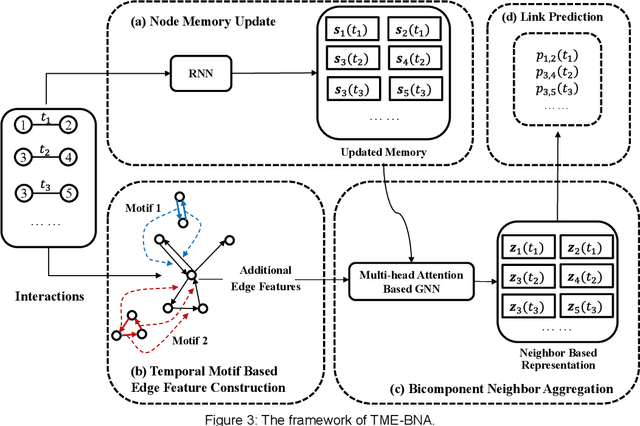
Evolving temporal networks serve as the abstractions of many real-life dynamic systems, e.g., social network and e-commerce. The purpose of temporal network embedding is to map each node to a time-evolving low-dimension vector for downstream tasks, e.g., link prediction and node classification. The difficulty of temporal network embedding lies in how to utilize the topology and time information jointly to capture the evolution of a temporal network. In response to this challenge, we propose a temporal motif-preserving network embedding method with bicomponent neighbor aggregation, named TME-BNA. Considering that temporal motifs are essential to the understanding of topology laws and functional properties of a temporal network, TME-BNA constructs additional edge features based on temporal motifs to explicitly utilize complex topology with time information. In order to capture the topology dynamics of nodes, TME-BNA utilizes Graph Neural Networks (GNNs) to aggregate the historical and current neighbors respectively according to the timestamps of connected edges. Experiments are conducted on three public temporal network datasets, and the results show the effectiveness of TME-BNA.
Autoencoder-based background reconstruction and foreground segmentation with background noise estimation
Dec 15, 2021

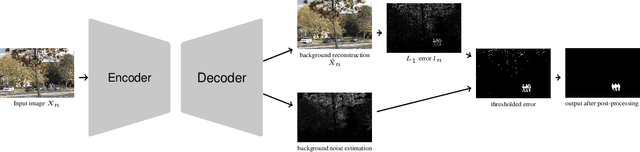
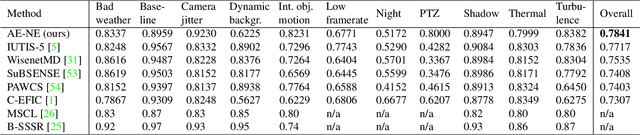
Even after decades of research, dynamic scene background reconstruction and foreground object segmentation are still considered as open problems due various challenges such as illumination changes, camera movements, or background noise caused by air turbulence or moving trees. We propose in this paper to model the background of a video sequence as a low dimensional manifold using an autoencoder and to compare the reconstructed background provided by this autoencoder with the original image to compute the foreground/background segmentation masks. The main novelty of the proposed model is that the autoencoder is also trained to predict the background noise, which allows to compute for each frame a pixel-dependent threshold to perform the background/foreground segmentation. Although the proposed model does not use any temporal or motion information, it exceeds the state of the art for unsupervised background subtraction on the CDnet 2014 and LASIESTA datasets, with a significant improvement on videos where the camera is moving.
Understanding Autoencoders with Information Theoretic Concepts
Aug 23, 2018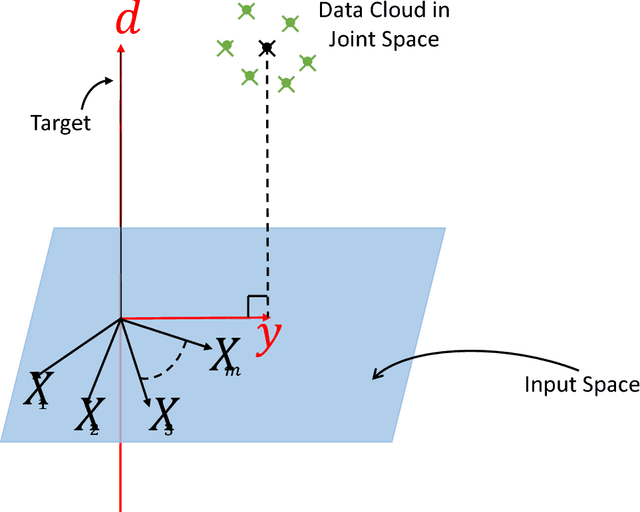
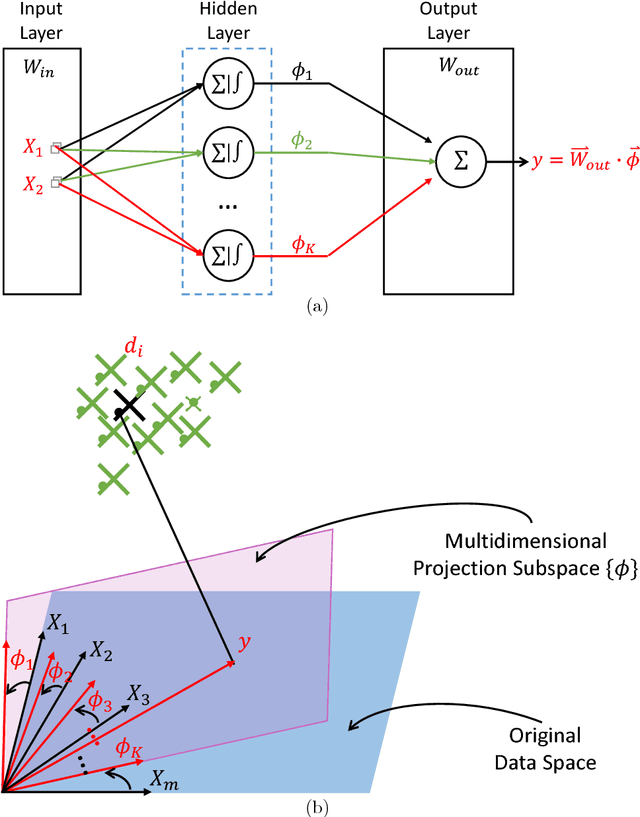
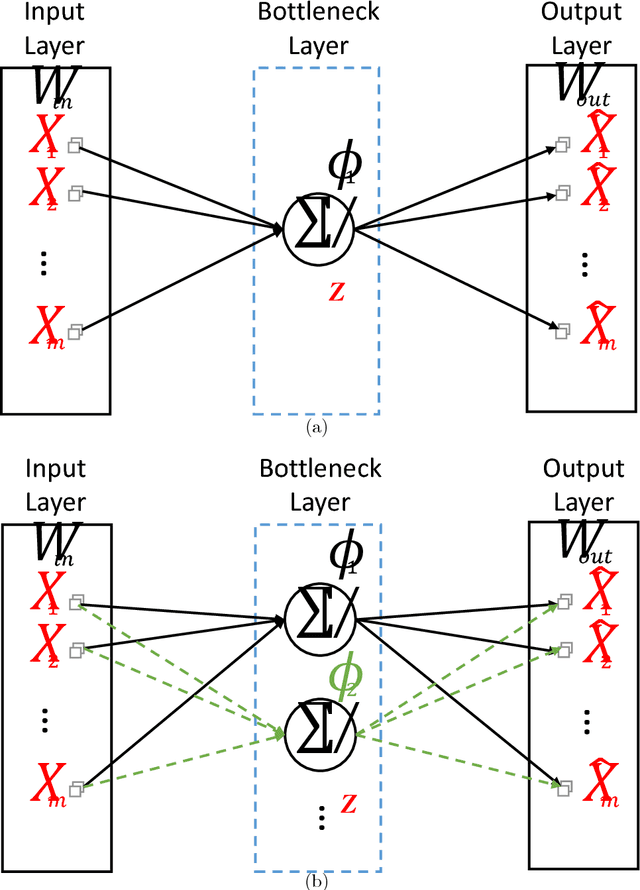
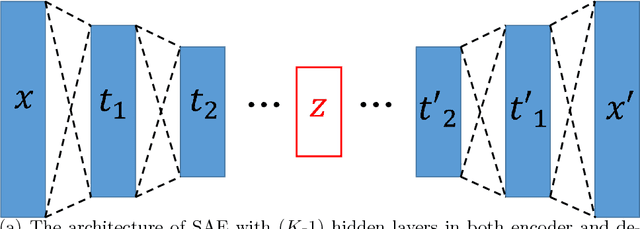
Despite their great success in practical applications, there is still a lack of theoretical and systematic methods to analyze deep neural networks. In this paper, we illustrate an advanced information theoretic methodology to understand the dynamics of learning and the design of autoencoders, a special type of deep learning architectures that resembles a communication channel. By generalizing the information plane to any cost function, and inspecting the roles and dynamics of different layers using layer-wise information quantities, we emphasize the role that mutual information plays in quantifying learning from data. We further suggest and also experimentally validate, for mean square error training, three fundamental properties regarding the layer-wise flow of information and intrinsic dimensionality of the bottleneck layer, using respectively the data processing inequality and the identification of a bifurcation point in the information plane that is controlled by the given data. Our observations have direct impact on the optimal design of autoencoders, the design of alternative feedforward training methods, and even in the problem of generalization.
Diagnosing BERT with Retrieval Heuristics
Jan 12, 2022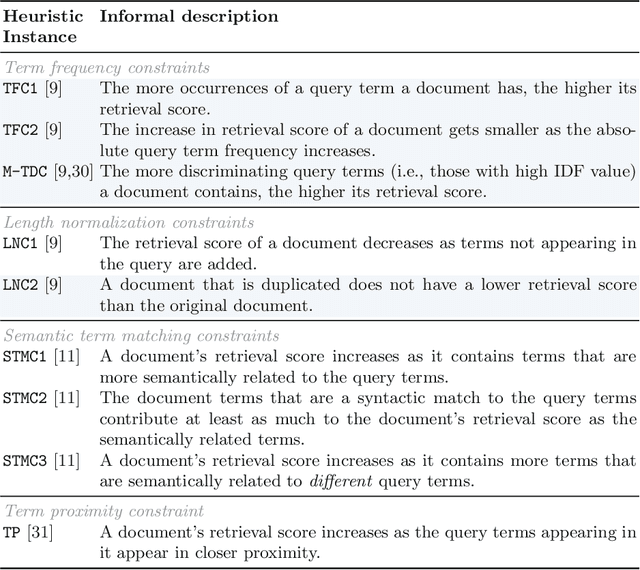
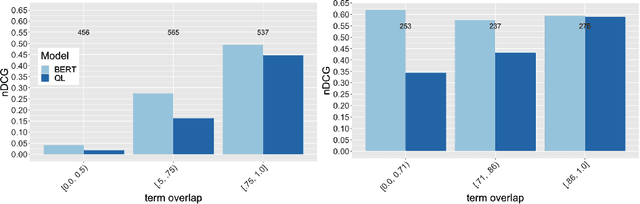


Word embeddings, made widely popular in 2013 with the release of word2vec, have become a mainstay of NLP engineering pipelines. Recently, with the release of BERT, word embeddings have moved from the term-based embedding space to the contextual embedding space -- each term is no longer represented by a single low-dimensional vector but instead each term and \emph{its context} determine the vector weights. BERT's setup and architecture have been shown to be general enough to be applicable to many natural language tasks. Importantly for Information Retrieval (IR), in contrast to prior deep learning solutions to IR problems which required significant tuning of neural net architectures and training regimes, "vanilla BERT" has been shown to outperform existing retrieval algorithms by a wide margin, including on tasks and corpora that have long resisted retrieval effectiveness gains over traditional IR baselines (such as Robust04). In this paper, we employ the recently proposed axiomatic dataset analysis technique -- that is, we create diagnostic datasets that each fulfil a retrieval heuristic (both term matching and semantic-based) -- to explore what BERT is able to learn. In contrast to our expectations, we find BERT, when applied to a recently released large-scale web corpus with ad-hoc topics, to \emph{not} adhere to any of the explored axioms. At the same time, BERT outperforms the traditional query likelihood retrieval model by 40\%. This means that the axiomatic approach to IR (and its extension of diagnostic datasets created for retrieval heuristics) may in its current form not be applicable to large-scale corpora. Additional -- different -- axioms are needed.
* Published at ECIR 2020