 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid diffusion models: combining supervised and generative pretraining for label-efficient fine-tuning of segmentation models
Aug 06, 2024We are considering in this paper the task of label-efficient fine-tuning of segmentation models: We assume that a large labeled dataset is available and allows to train an accurate segmentation model in one domain, and that we have to adapt this model on a related domain where only a few samples are available. We observe that this adaptation can be done using two distinct methods: The first method, supervised pretraining, is simply to take the model trained on the first domain using classical supervised learning, and fine-tune it on the second domain with the available labeled samples. The second method is to perform self-supervised pretraining on the first domain using a generic pretext task in order to get high-quality representations which can then be used to train a model on the second domain in a label-efficient way. We propose in this paper to fuse these two approaches by introducing a new pretext task, which is to perform simultaneously image denoising and mask prediction on the first domain. We motivate this choice by showing that in the same way that an image denoiser conditioned on the noise level can be considered as a generative model for the unlabeled image distribution using the theory of diffusion models, a model trained using this new pretext task can be considered as a generative model for the joint distribution of images and segmentation masks under the assumption that the mapping from images to segmentation masks is deterministic. We then empirically show on several datasets that fine-tuning a model pretrained using this approach leads to better results than fine-tuning a similar model trained using either supervised or unsupervised pretraining only.
Unsupervised Multi-object Segmentation Using Attention and Soft-argmax
May 26, 2022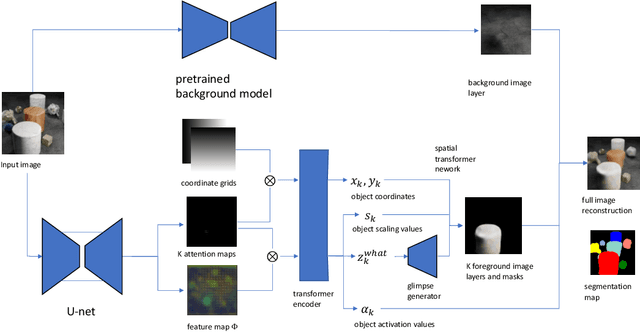
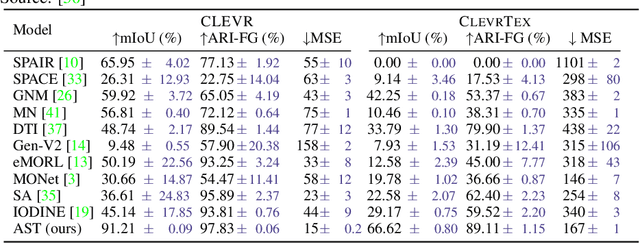


We introduce a new architecture for unsupervised object-centric representation learning and multi-object detection and segmentation, which uses an attention mechanism to associate a feature vector to each object present in the scene and to predict the coordinates of these objects using soft-argmax. A transformer encoder handles occlusions and redundant detections, and a separate pre-trained background model is in charge of background reconstruction. We show that this architecture significantly outperforms the state of the art on complex synthetic benchmarks and provide examples of applications to real-world traffic videos.
Autoencoder-based background reconstruction and foreground segmentation with background noise estimation
Dec 15, 2021

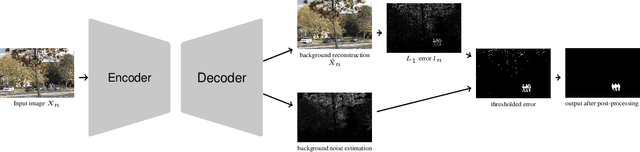
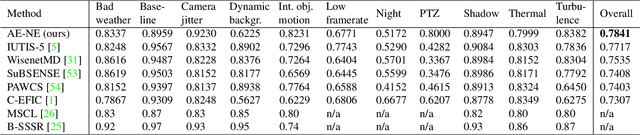
Even after decades of research, dynamic scene background reconstruction and foreground object segmentation are still considered as open problems due various challenges such as illumination changes, camera movements, or background noise caused by air turbulence or moving trees. We propose in this paper to model the background of a video sequence as a low dimensional manifold using an autoencoder and to compare the reconstructed background provided by this autoencoder with the original image to compute the foreground/background segmentation masks. The main novelty of the proposed model is that the autoencoder is also trained to predict the background noise, which allows to compute for each frame a pixel-dependent threshold to perform the background/foreground segmentation. Although the proposed model does not use any temporal or motion information, it exceeds the state of the art for unsupervised background subtraction on the CDnet 2014 and LASIESTA datasets, with a significant improvement on videos where the camera is moving.