 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Coherent FDA Radar Systems: Joint Design of Transmitting and Receiving Array Weighters
Apr 14, 2022

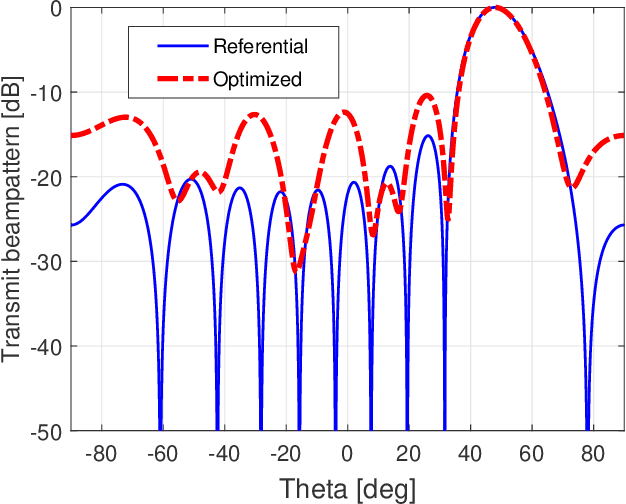
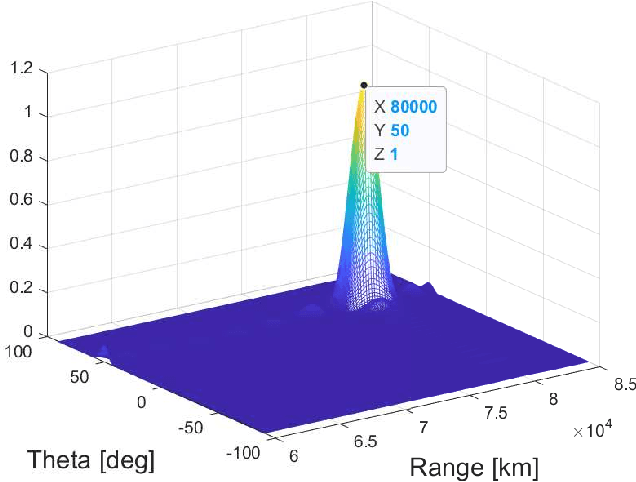
Due to the frequency offset across its array elements, frequency diverse array (FDA) will generate angle-range-dependent and time-variant transmit beampattern. Since existing investigations usually focus on FDA transmitter and only instantaneous beampattern is considered, which cannot fully exploit the time-range characteristics of FDA radar for enhanced performance, in this paper we formulate a multi-carrier mixing receiver for coherent pulsed-Doppler FDA radar to effectively retain the range information of FDA radar returned signals in subsequent receiver processing. Accordingly, the joint transmitter and receiver is systematically modeled with time-range relationship consideration. More importantly, we optimally design the joint transmitting and receiving weighters by maximizing the radiated energy within the desired range-angle sections for given total energy. All proposed methods are verified by simulation results.
Improved Object Pose Estimation via Deep Pre-touch Sensing
Apr 09, 2022

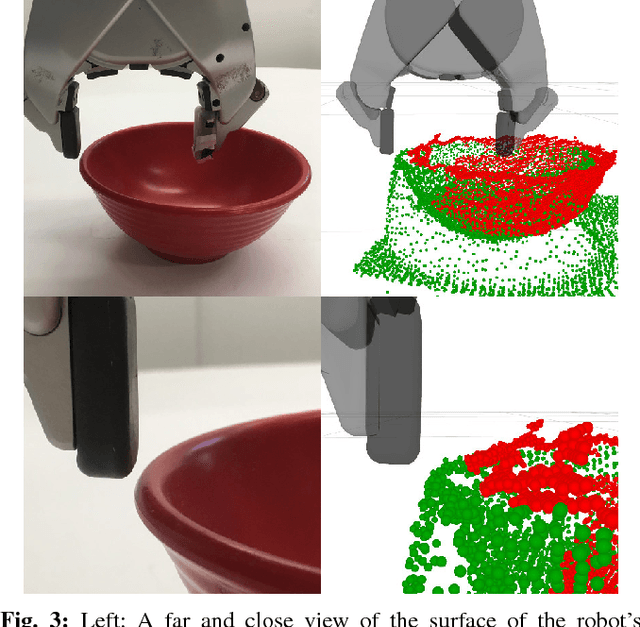

For certain manipulation tasks, object pose estimation from head-mounted cameras may not be sufficiently accurate. This is at least in part due to our inability to perfectly calibrate the coordinate frames of today's high degree of freedom robot arms that link the head to the end-effectors. We present a novel framework combining pre-touch sensing and deep learning to more accurately estimate pose in an efficient manner. The use of pre-touch sensing allows our method to localize the object directly with respect to the robot's end effector, thereby avoiding error caused by miscalibration of the arms. Instead of requiring the robot to scan the entire object with its pre-touch sensor, we use a deep neural network to detect object regions that contain distinctive geometric features. By focusing pre-touch sensing on these regions, the robot can more efficiently gather the information necessary to adjust its original pose estimate. Our region detection network was trained using a new dataset containing objects of widely varying geometries and has been labeled in a scalable fashion that is free from human bias. This dataset is applicable to any task that involves a pre-touch sensor gathering geometric information, and has been made publicly available. We evaluate our framework by having the robot re-estimate the pose of a number of objects of varying geometries. Compared to two simpler region proposal methods, we find that our deep neural network performs significantly better. In addition, we find that after a sequence of scans, objects can typically be localized to within 0.5 cm of their true position. We also observe that the original pose estimate can often be significantly improved after collecting a single quick scan.
Examining the causal structures of deep neural networks using information theory
Oct 26, 2020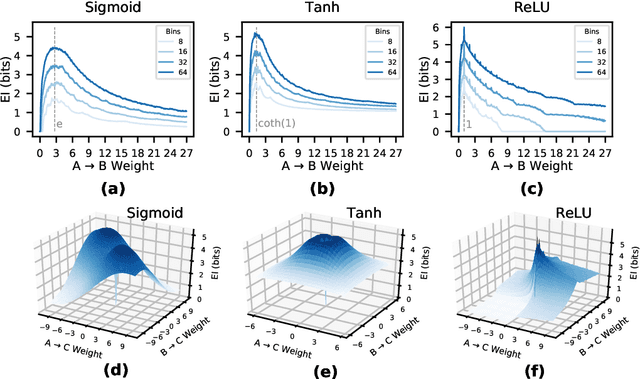
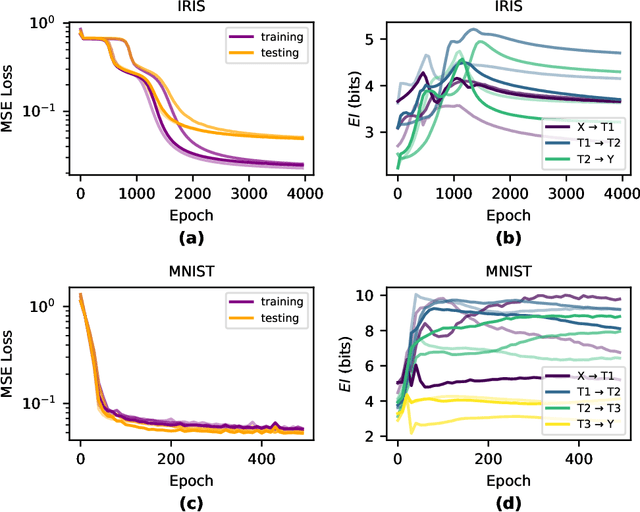
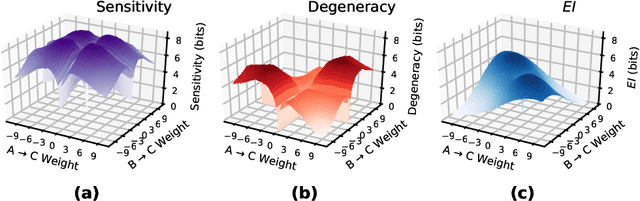
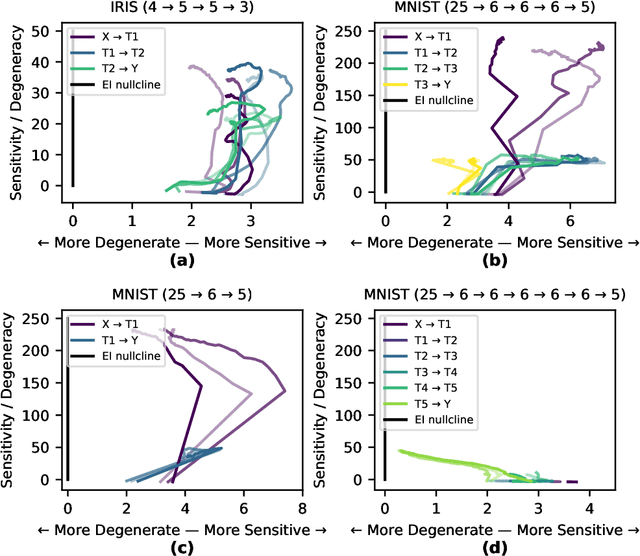
Deep Neural Networks (DNNs) are often examined at the level of their response to input, such as analyzing the mutual information between nodes and data sets. Yet DNNs can also be examined at the level of causation, exploring "what does what" within the layers of the network itself. Historically, analyzing the causal structure of DNNs has received less attention than understanding their responses to input. Yet definitionally, generalizability must be a function of a DNN's causal structure since it reflects how the DNN responds to unseen or even not-yet-defined future inputs. Here, we introduce a suite of metrics based on information theory to quantify and track changes in the causal structure of DNNs during training. Specifically, we introduce the effective information (EI) of a feedforward DNN, which is the mutual information between layer input and output following a maximum-entropy perturbation. The EI can be used to assess the degree of causal influence nodes and edges have over their downstream targets in each layer. We show that the EI can be further decomposed in order to examine the sensitivity of a layer (measured by how well edges transmit perturbations) and the degeneracy of a layer (measured by how edge overlap interferes with transmission), along with estimates of the amount of integrated information of a layer. Together, these properties define where each layer lies in the "causal plane" which can be used to visualize how layer connectivity becomes more sensitive or degenerate over time, and how integration changes during training, revealing how the layer-by-layer causal structure differentiates. These results may help in understanding the generalization capabilities of DNNs and provide foundational tools for making DNNs both more generalizable and more explainable.
A Tale of Two Flows: Cooperative Learning of Langevin Flow and Normalizing Flow Toward Energy-Based Model
May 13, 2022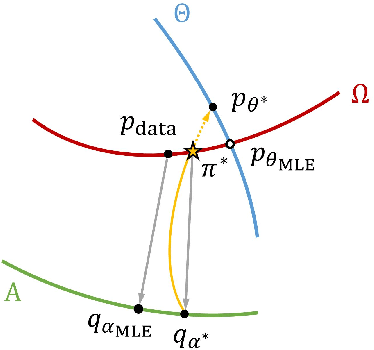
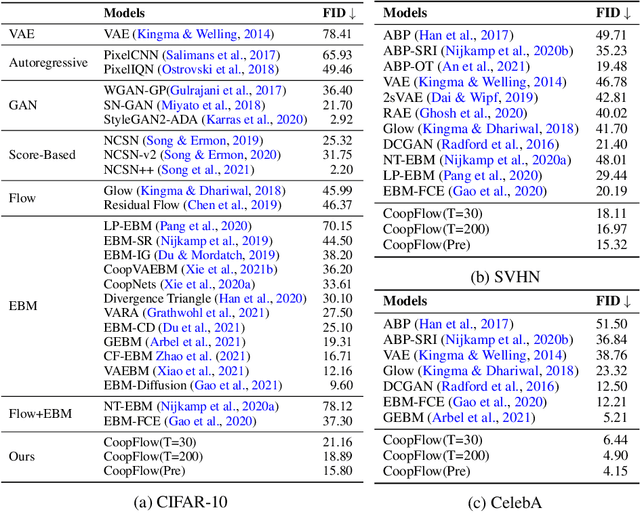
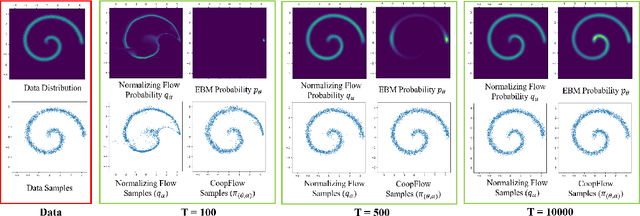

This paper studies the cooperative learning of two generative flow models, in which the two models are iteratively updated based on the jointly synthesized examples. The first flow model is a normalizing flow that transforms an initial simple density to a target density by applying a sequence of invertible transformations. The second flow model is a Langevin flow that runs finite steps of gradient-based MCMC toward an energy-based model. We start from proposing a generative framework that trains an energy-based model with a normalizing flow as an amortized sampler to initialize the MCMC chains of the energy-based model. In each learning iteration, we generate synthesized examples by using a normalizing flow initialization followed by a short-run Langevin flow revision toward the current energy-based model. Then we treat the synthesized examples as fair samples from the energy-based model and update the model parameters with the maximum likelihood learning gradient, while the normalizing flow directly learns from the synthesized examples by maximizing the tractable likelihood. Under the short-run non-mixing MCMC scenario, the estimation of the energy-based model is shown to follow the perturbation of maximum likelihood, and the short-run Langevin flow and the normalizing flow form a two-flow generator that we call CoopFlow. We provide an understating of the CoopFlow algorithm by information geometry and show that it is a valid generator as it converges to a moment matching estimator. We demonstrate that the trained CoopFlow is capable of synthesizing realistic images, reconstructing images, and interpolating between images.
* 23 pages
Privacy-Preserving Federated Learning via System Immersion and Random Matrix Encryption
Apr 05, 2022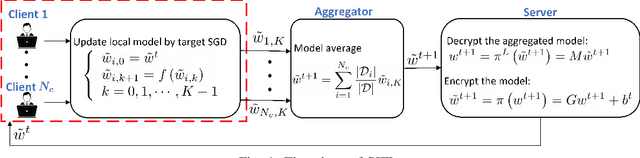
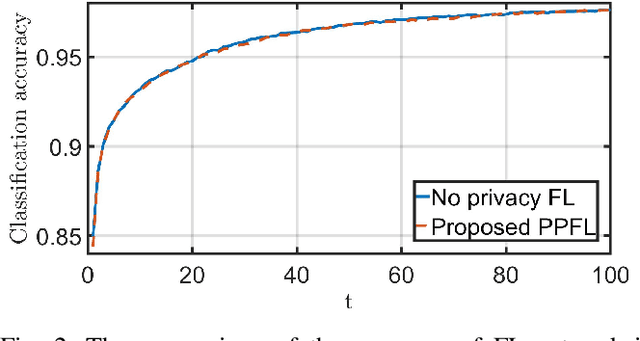
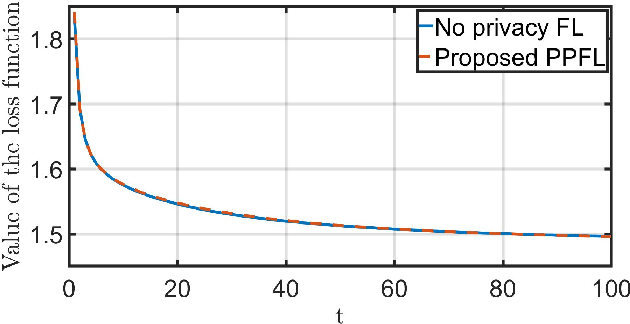
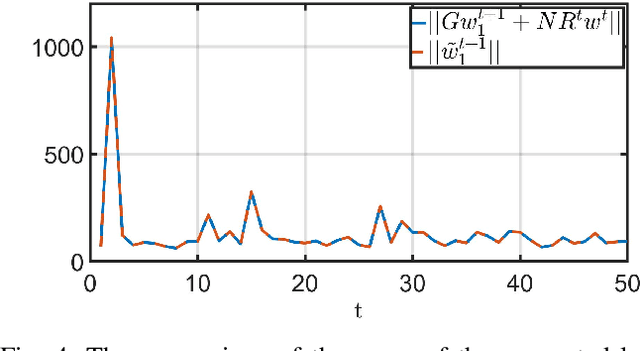
Federated learning (FL) has emerged as a privacy solution for collaborative distributed learning where clients train AI models directly on their devices instead of sharing their data with a centralized (potentially adversarial) server. Although FL preserves local data privacy to some extent, it has been shown that information about clients' data can still be inferred from model updates. In recent years, various privacy-preserving schemes have been developed to address this privacy leakage. However, they often provide privacy at the expense of model performance or system efficiency and balancing these tradeoffs is a crucial challenge when implementing FL schemes. In this manuscript, we propose a Privacy-Preserving Federated Learning (PPFL) framework built on the synergy of matrix encryption and system immersion tools from control theory. The idea is to immerse the learning algorithm, a Stochastic Gradient Decent (SGD), into a higher-dimensional system (the so-called target system) and design the dynamics of the target system so that: the trajectories of the original SGD are immersed/embedded in its trajectories, and it learns on encrypted data (here we use random matrix encryption). Matrix encryption is reformulated at the server as a random change of coordinates that maps original parameters to a higher-dimensional parameter space and enforces that the target SGD converges to an encrypted version of the original SGD optimal solution. The server decrypts the aggregated model using the left inverse of the immersion map. We show that our algorithm provides the same level of accuracy and convergence rate as the standard FL with a negligible computation cost while revealing no information about the clients' data.
Reinforcement Learning for Minimizing Age of Information in Real-time Internet of Things Systems with Realistic Physical Dynamics
Apr 04, 2021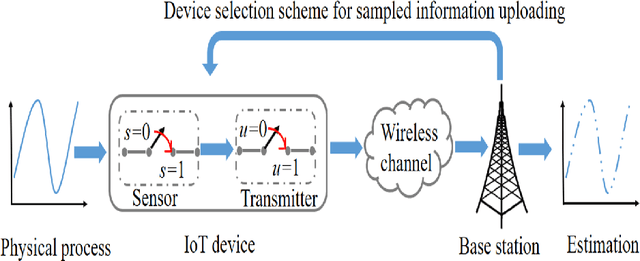
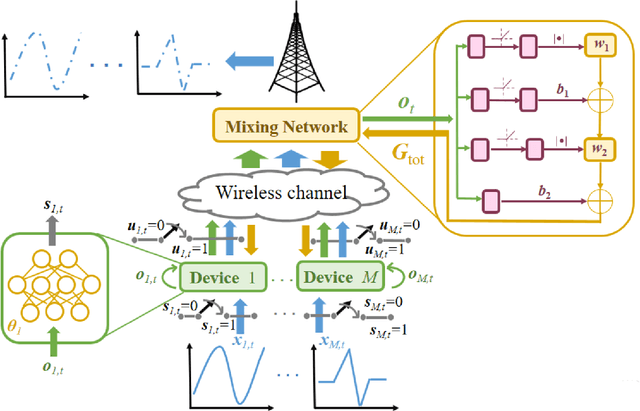
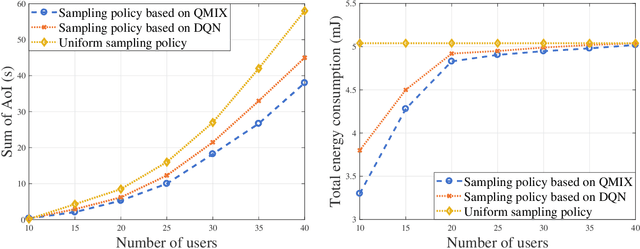
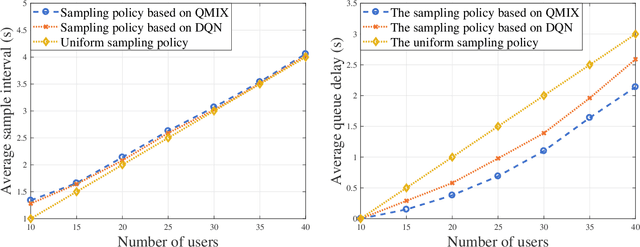
In this paper, the problem of minimizing the weighted sum of age of information (AoI) and total energy consumption of Internet of Things (IoT) devices is studied. In the considered model, each IoT device monitors a physical process that follows nonlinear dynamics. As the dynamics of the physical process vary over time, each device must find an optimal sampling frequency to sample the real-time dynamics of the physical system and send sampled information to a base station (BS). Due to limited wireless resources, the BS can only select a subset of devices to transmit their sampled information. Meanwhile, changing the sampling frequency will also impact the energy used by each device for sampling and information transmission. Thus, it is necessary to jointly optimize the sampling policy of each device and the device selection scheme of the BS so as to accurately monitor the dynamics of the physical process using minimum energy. This problem is formulated as an optimization problem whose goal is to minimize the weighted sum of AoI cost and energy consumption. To solve this problem, a distributed reinforcement learning approach is proposed to optimize the sampling policy. The proposed learning method enables the IoT devices to find the optimal sampling policy using their local observations. Given the sampling policy, the device selection scheme can be optimized so as to minimize the weighted sum of AoI and energy consumption of all devices. Simulations with real data of PM 2.5 pollution show that the proposed algorithm can reduce the sum of AoI by up to 17.8% and 33.9% and the total energy consumption by up to 13.2% and 35.1%, compared to a conventional deep Q network method and a uniform sampling policy.
SE-GAN: Skeleton Enhanced GAN-based Model for Brush Handwriting Font Generation
Apr 22, 2022
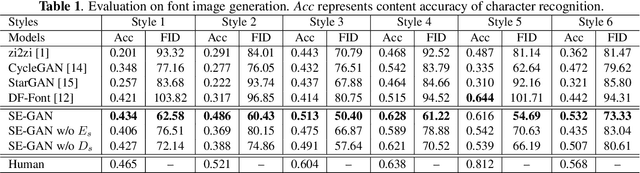
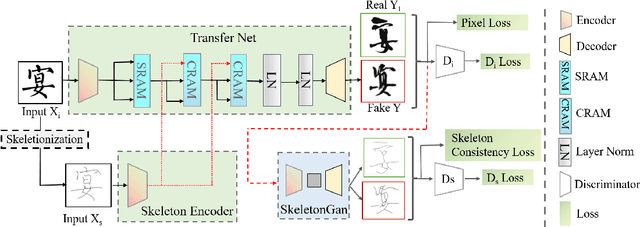
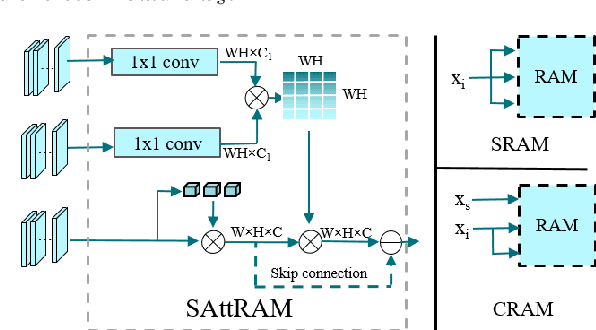
Previous works on font generation mainly focus on the standard print fonts where character's shape is stable and strokes are clearly separated. There is rare research on brush handwriting font generation, which involves holistic structure changes and complex strokes transfer. To address this issue, we propose a novel GAN-based image translation model by integrating the skeleton information. We first extract the skeleton from training images, then design an image encoder and a skeleton encoder to extract corresponding features. A self-attentive refined attention module is devised to guide the model to learn distinctive features between different domains. A skeleton discriminator is involved to first synthesize the skeleton image from the generated image with a pre-trained generator, then to judge its realness to the target one. We also contribute a large-scale brush handwriting font image dataset with six styles and 15,000 high-resolution images. Both quantitative and qualitative experimental results demonstrate the competitiveness of our proposed model.
Deriving the Traveler Behavior Information from Social Media: A Case Study in Manhattan with Twitter
Jan 27, 2021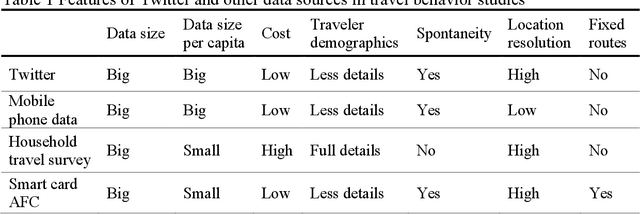
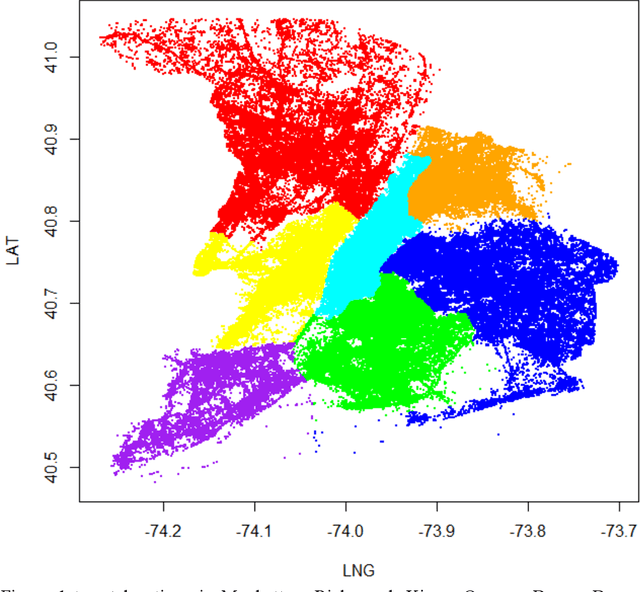

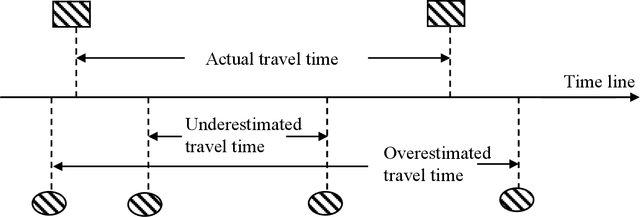
Social media platforms, such as Twitter, provide a totally new perspective in dealing with the traffic problems and is anticipated to complement the traditional methods. The geo-tagged tweets can provide the Twitter users' location information and is being applied in traveler behavior analysis. This paper explores the full potentials of Twitter in deriving travel behavior information and conducts a case study in Manhattan Area. A systematic method is proposed to extract displacement information from Twitter locations. Our study shows that Twitter has a unique demographics which combine not only local residents but also the tourists or passengers. For individual user, Twitter can uncover his/her travel behavior features including the time-of-day and location distributions on both weekdays and weekends. For all Twitter users, the aggregated travel behavior results also show that the time-of-day travel patterns in Manhattan Island resemble that of the traffic flow; the identification of OD pattern is also promising by comparing with the results of travel survey.
Few-Shot Image Classification Benchmarks are Too Far From Reality: Build Back Better with Semantic Task Sampling
May 10, 2022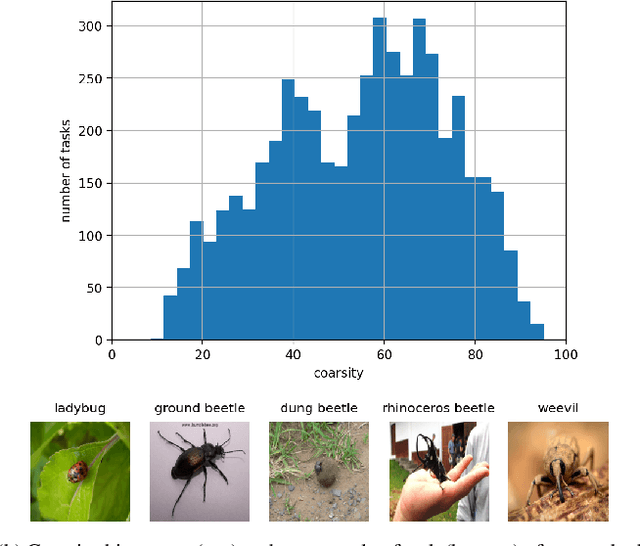
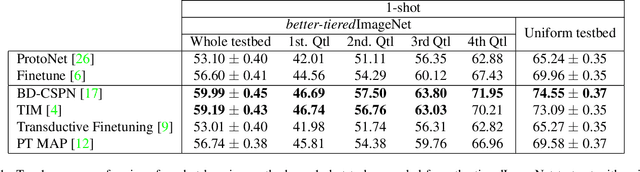
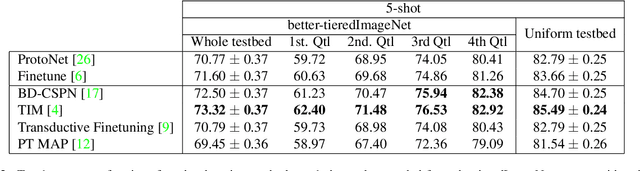
Every day, a new method is published to tackle Few-Shot Image Classification, showing better and better performances on academic benchmarks. Nevertheless, we observe that these current benchmarks do not accurately represent the real industrial use cases that we encountered. In this work, through both qualitative and quantitative studies, we expose that the widely used benchmark tieredImageNet is strongly biased towards tasks composed of very semantically dissimilar classes e.g. bathtub, cabbage, pizza, schipperke, and cardoon. This makes tieredImageNet (and similar benchmarks) irrelevant to evaluate the ability of a model to solve real-life use cases usually involving more fine-grained classification. We mitigate this bias using semantic information about the classes of tieredImageNet and generate an improved, balanced benchmark. Going further, we also introduce a new benchmark for Few-Shot Image Classification using the Danish Fungi 2020 dataset. This benchmark proposes a wide variety of evaluation tasks with various fine-graininess. Moreover, this benchmark includes many-way tasks (e.g. composed of 100 classes), which is a challenging setting yet very common in industrial applications. Our experiments bring out the correlation between the difficulty of a task and the semantic similarity between its classes, as well as a heavy performance drop of state-of-the-art methods on many-way few-shot classification, raising questions about the scaling abilities of these methods. We hope that our work will encourage the community to further question the quality of standard evaluation processes and their relevance to real-life applications.
Improving Multi-Document Summarization through Referenced Flexible Extraction with Credit-Awareness
May 04, 2022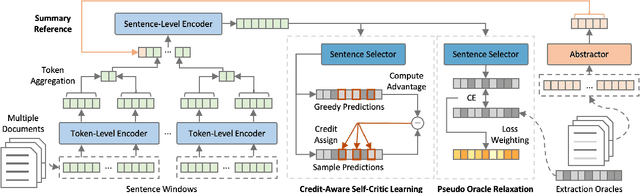
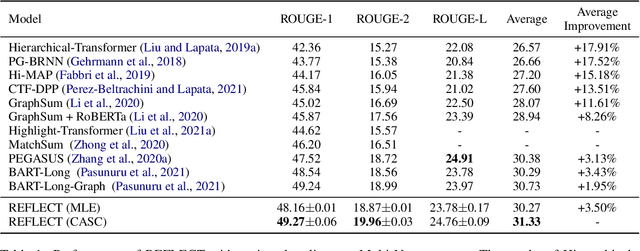
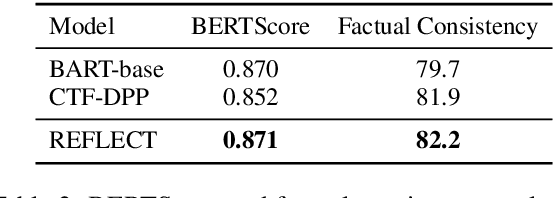
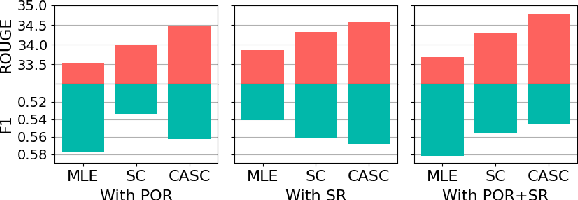
A notable challenge in Multi-Document Summarization (MDS) is the extremely-long length of the input. In this paper, we present an extract-then-abstract Transformer framework to overcome the problem. Specifically, we leverage pre-trained language models to construct a hierarchical extractor for salient sentence selection across documents and an abstractor for rewriting the selected contents as summaries. However, learning such a framework is challenging since the optimal contents for the abstractor are generally unknown. Previous works typically create pseudo extraction oracle to enable the supervised learning for both the extractor and the abstractor. Nevertheless, we argue that the performance of such methods could be restricted due to the insufficient information for prediction and inconsistent objectives between training and testing. To this end, we propose a loss weighting mechanism that makes the model aware of the unequal importance for the sentences not in the pseudo extraction oracle, and leverage the fine-tuned abstractor to generate summary references as auxiliary signals for learning the extractor. Moreover, we propose a reinforcement learning method that can efficiently apply to the extractor for harmonizing the optimization between training and testing. Experiment results show that our framework substantially outperforms strong baselines with comparable model sizes and achieves the best results on the Multi-News, Multi-XScience, and WikiCatSum corpora.