 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Diffuse Map Guiding Unsupervised Generative Adversarial Network for SVBRDF Estimation
May 24, 2022
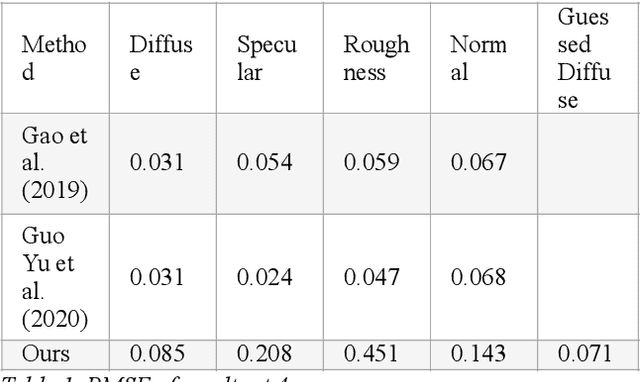
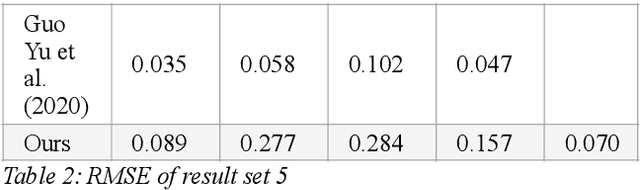
Reconstructing materials in the real world has always been a difficult problem in computer graphics. Accurately reconstructing the material in the real world is critical in the field of realistic rendering. Traditionally, materials in computer graphics are mapped by an artist, then mapped onto a geometric model by coordinate transformation, and finally rendered with a rendering engine to get realistic materials. For opaque objects, the industry commonly uses physical-based bidirectional reflectance distribution function (BRDF) rendering models for material modeling. The commonly used physical-based rendering models are Cook-Torrance BRDF, Disney BRDF. In this paper, we use the Cook-Torrance model to reconstruct the materials. The SVBRDF material parameters include Normal, Diffuse, Specular and Roughness. This paper presents a Diffuse map guiding material estimation method based on the Generative Adversarial Network(GAN). This method can predict plausible SVBRDF maps with global features using only a few pictures taken by the mobile phone. The main contributions of this paper are: 1) We preprocess a small number of input pictures to produce a large number of non-repeating pictures for training to reduce over-fitting. 2) We use a novel method to directly obtain the guessed diffuse map with global characteristics, which provides more prior information for the training process. 3) We improve the network architecture of the generator so that it can generate fine details of normal maps and reduce the possibility to generate over-flat normal maps. The method used in this paper can obtain prior knowledge without using dataset training, which greatly reduces the difficulty of material reconstruction and saves a lot of time to generate and calibrate datasets.
Building an Effective Automated Assessment System for C/C++ Introductory Programming Courses in ODL Environment
May 24, 2022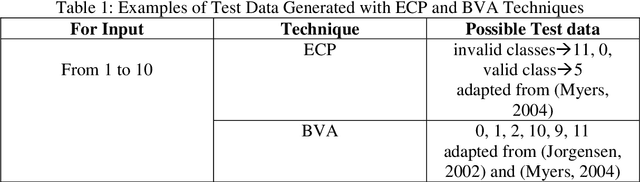
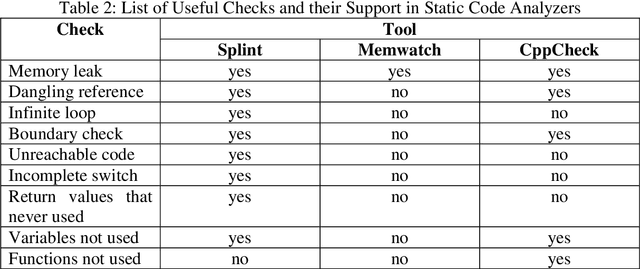
Assessments help in evaluating the knowledge gained by a learner at any specific point as well as in continuous improvement of the curriculum design and the whole learning process. However, with the increase in students' enrollment at University level in either conventional or distance education environment, traditional ways of assessing students' work are becoming insufficient in terms of both time and effort. In distance education environment, such assessments become additionally more challenging in terms of hefty remuneration for hiring large number of tutors. The availability of automated tools to assist the evaluation of students' work and providing students with appropriate and timely feedback can really help in overcoming these problems. We believe that building such tools for assessing students' work for all kinds of courses in not yet possible. However, courses that involve some formal language of expression can be automated, such as, programming courses in Computer Science (CS) discipline. Instructors provide various practical exercises to students as assignments to build these skills. Usually, instructors manually grade and provide feedbacks on these assignments. Although in literature, various tools have been reported to automate this process, but most of these tools have been developed by the host institutions themselves for their own use. We at COMSATS Institute of Information Technology, Lahore are conducting a pioneer effort in Pakistan to automate the marking of assignments of introductory programming courses that involve C or C++ languages with the capability of associating appropriate feedbacks for students. In this paper, we basically identify different components that we believe are necessary in building an effective automated assessment system in the context of introductory programming courses that involve C/C++ programming.
Content addressable memory without catastrophic forgetting by heteroassociation with a fixed scaffold
Feb 16, 2022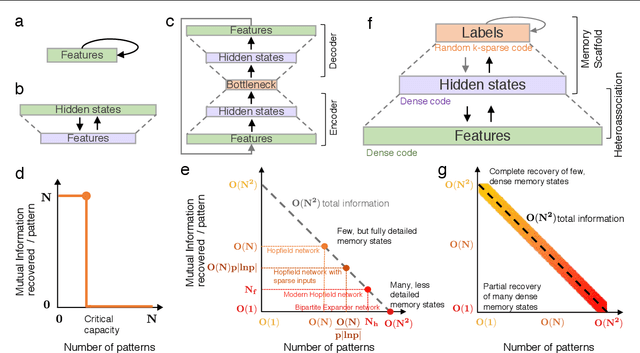
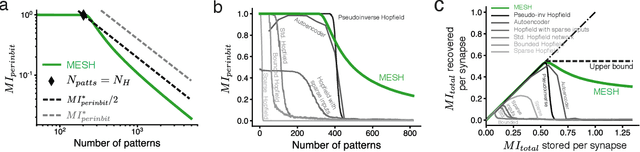
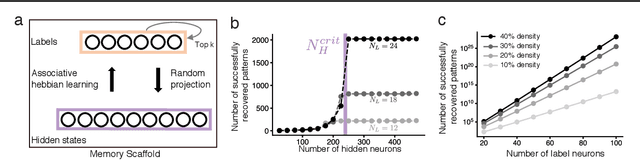
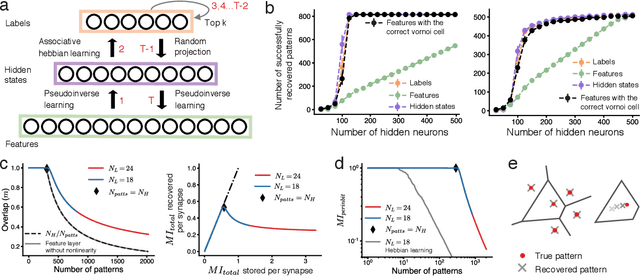
Content-addressable memory (CAM) networks, so-called because stored items can be recalled by partial or corrupted versions of the items, exhibit near-perfect recall of a small number of information-dense patterns below capacity and a `memory cliff' beyond, such that inserting a single additional pattern results in catastrophic forgetting of all stored patterns. We propose a novel ANN architecture, Memory Scaffold with Heteroassociation (MESH), that gracefully trades-off pattern richness with pattern number to generate a CAM continuum without a memory cliff: Small numbers of patterns are stored with complete information recovery matching standard CAMs, while inserting more patterns still results in partial recall of every pattern, with an information per pattern that scales inversely with the number of patterns. Motivated by the architecture of the Entorhinal-Hippocampal memory circuit in the brain, MESH is a tripartite architecture with pairwise interactions that uses a predetermined set of internally stabilized states together with heteroassociation between the internal states and arbitrary external patterns. We show analytically and experimentally that MESH nearly saturates the total information bound (given by the number of synapses) for CAM networks, invariant of the number of stored patterns, outperforming all existing CAM models.
Learning-by-Narrating: Narrative Pre-Training for Zero-Shot Dialogue Comprehension
Mar 19, 2022

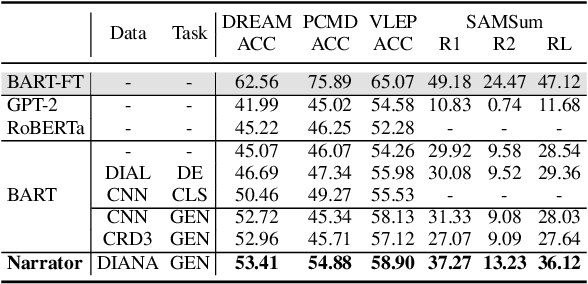
Comprehending a dialogue requires a model to capture diverse kinds of key information in the utterances, which are either scattered around or implicitly implied in different turns of conversations. Therefore, dialogue comprehension requires diverse capabilities such as paraphrasing, summarizing, and commonsense reasoning. Towards the objective of pre-training a zero-shot dialogue comprehension model, we develop a novel narrative-guided pre-training strategy that learns by narrating the key information from a dialogue input. However, the dialogue-narrative parallel corpus for such a pre-training strategy is currently unavailable. For this reason, we first construct a dialogue-narrative parallel corpus by automatically aligning movie subtitles and their synopses. We then pre-train a BART model on the data and evaluate its performance on four dialogue-based tasks that require comprehension. Experimental results show that our model not only achieves superior zero-shot performance but also exhibits stronger fine-grained dialogue comprehension capabilities. The data and code are available at https://github.com/zhaochaocs/Diana
Minimising Biasing Word Errors for Contextual ASR with the Tree-Constrained Pointer Generator
May 18, 2022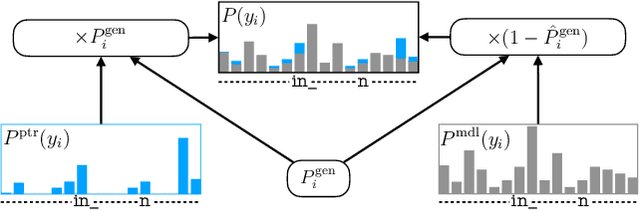
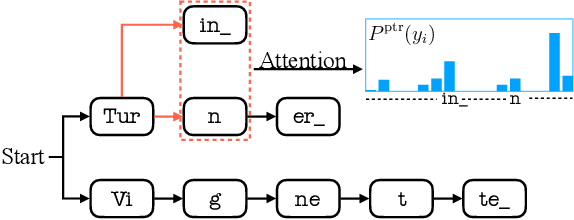
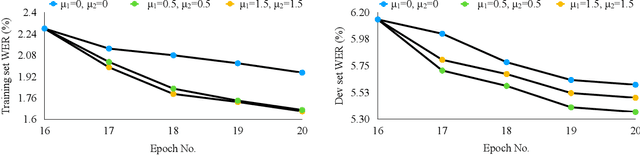
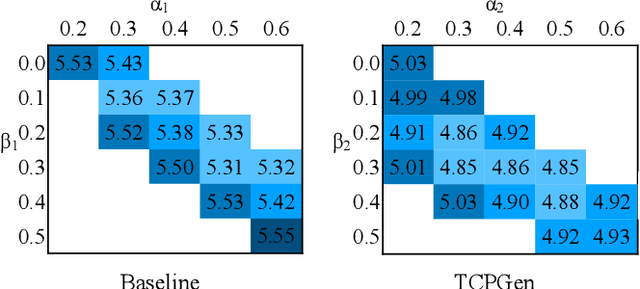
Contextual knowledge is essential for reducing speech recognition errors on high-valued long-tail words. This paper proposes a novel tree-constrained pointer generator (TCPGen) component that enables end-to-end ASR models to bias towards a list of long-tail words obtained using external contextual information. With only a small overhead in memory use and computation cost, TCPGen can structure thousands of biasing words efficiently into a symbolic prefix-tree and creates a neural shortcut between the tree and the final ASR output to facilitate the recognition of the biasing words. To enhance TCPGen, we further propose a novel minimum biasing word error (MBWE) loss that directly optimises biasing word errors during training, along with a biasing-word-driven language model discounting (BLMD) method during the test. All contextual ASR systems were evaluated on the public Librispeech audiobook corpus and the data from the dialogue state tracking challenges (DSTC) with the biasing lists extracted from the dialogue-system ontology. Consistent word error rate (WER) reductions were achieved with TCPGen, which were particularly significant on the biasing words with around 40\% relative reductions in the recognition error rates. MBWE and BLMD further improved the effectiveness of TCPGen and achieved more significant WER reductions on the biasing words. TCPGen also achieved zero-shot learning of words not in the audio training set with large WER reductions on the out-of-vocabulary words in the biasing list.
Local Hypergraph-based Nested Named Entity Recognition as Query-based Sequence Labeling
May 04, 2022

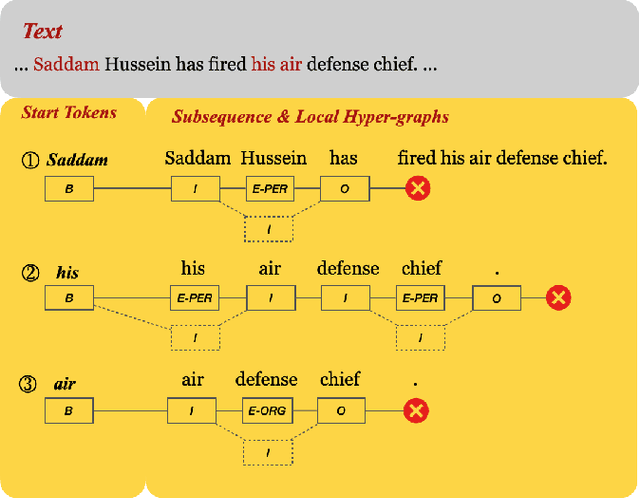
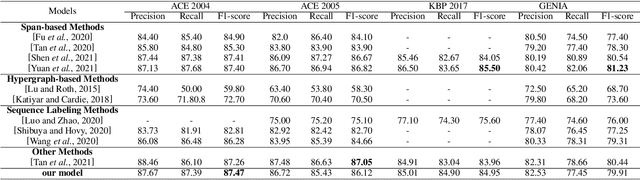
There has been a growing academic interest in the recognition of nested named entities in many domains. We tackle the task with a novel local hypergraph-based method: We first propose start token candidates and generate corresponding queries with their surrounding context, then use a query-based sequence labeling module to form a local hypergraph for each candidate. An end token estimator is used to correct the hypergraphs and get the final predictions. Compared to span-based approaches, our method is free of the high computation cost of span sampling and the risk of losing long entities. Sequential prediction makes it easier to leverage information in word order inside nested structures, and richer representations are built with a local hypergraph. Experiments show that our proposed method outperforms all the previous hypergraph-based and sequence labeling approaches with large margins on all four nested datasets. It achieves a new state-of-the-art F1 score on the ACE 2004 dataset and competitive F1 scores with previous state-of-the-art methods on three other nested NER datasets: ACE 2005, GENIA, and KBP 2017.
HRel: Filter Pruning based on High Relevance between Activation Maps and Class Labels
Feb 22, 2022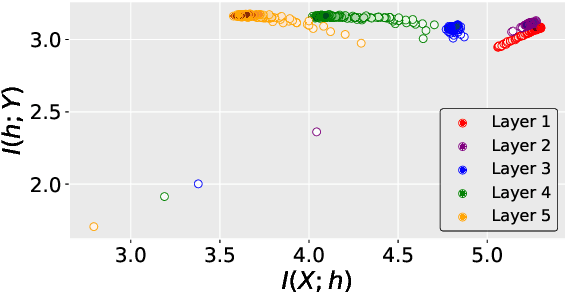
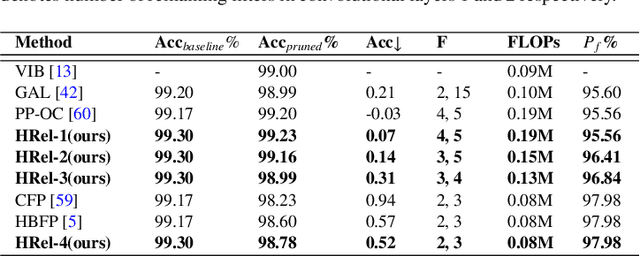
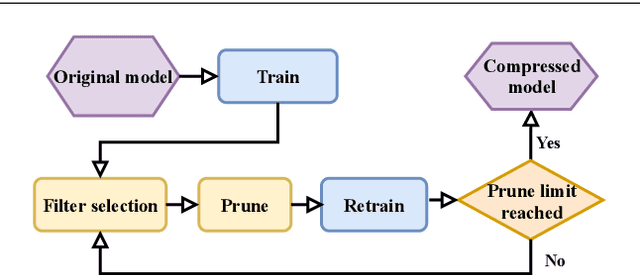
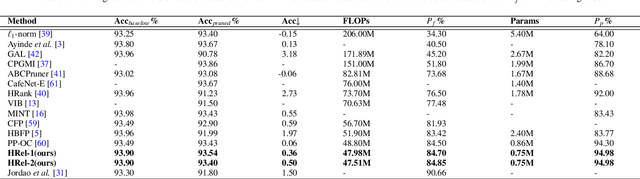
This paper proposes an Information Bottleneck theory based filter pruning method that uses a statistical measure called Mutual Information (MI). The MI between filters and class labels, also called \textit{Relevance}, is computed using the filter's activation maps and the annotations. The filters having High Relevance (HRel) are considered to be more important. Consequently, the least important filters, which have lower Mutual Information with the class labels, are pruned. Unlike the existing MI based pruning methods, the proposed method determines the significance of the filters purely based on their corresponding activation map's relationship with the class labels. Architectures such as LeNet-5, VGG-16, ResNet-56\textcolor{myblue}{, ResNet-110 and ResNet-50 are utilized to demonstrate the efficacy of the proposed pruning method over MNIST, CIFAR-10 and ImageNet datasets. The proposed method shows the state-of-the-art pruning results for LeNet-5, VGG-16, ResNet-56, ResNet-110 and ResNet-50 architectures. In the experiments, we prune 97.98 \%, 84.85 \%, 76.89\%, 76.95\%, and 63.99\% of Floating Point Operation (FLOP)s from LeNet-5, VGG-16, ResNet-56, ResNet-110, and ResNet-50 respectively.} The proposed HRel pruning method outperforms recent state-of-the-art filter pruning methods. Even after pruning the filters from convolutional layers of LeNet-5 drastically (i.e. from 20, 50 to 2, 3, respectively), only a small accuracy drop of 0.52\% is observed. Notably, for VGG-16, 94.98\% parameters are reduced, only with a drop of 0.36\% in top-1 accuracy. \textcolor{myblue}{ResNet-50 has shown a 1.17\% drop in the top-5 accuracy after pruning 66.42\% of the FLOPs.} In addition to pruning, the Information Plane dynamics of Information Bottleneck theory is analyzed for various Convolutional Neural Network architectures with the effect of pruning.
Attention-based Multimodal Feature Representation Model for Micro-video Recommendation
May 18, 2022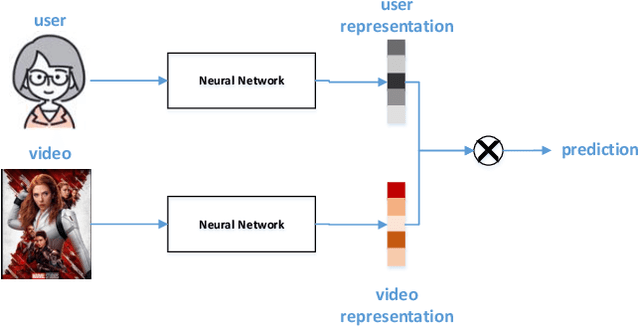
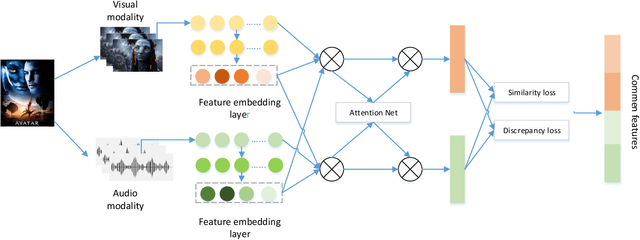
In recommender systems, models mostly use a combination of embedding layers and multilayer feedforward neural networks. The high-dimensional sparse original features are downscaled in the embedding layer and then fed into the fully connected network to obtain prediction results. However, the above methods have a rather obvious problem, that is, the features directly input are treated as independent individuals, and in fact there are internal correlations between features and features, and even different features have different importance in the recommendation. In this regard, this paper adopts a self-attentive mechanism to mine the internal correlations between features as well as their relative importance. In recent years, as a special form of attention mechanism, self-attention mechanism is favored by many researchers. The self-attentive mechanism captures the internal correlation of data or features by learning itself, thus reducing the dependence on external sources. Therefore, this paper adopts a multi-headed self-attentive mechanism to mine the internal correlations between features and thus learn the internal representation of features. At the same time, considering the rich information often hidden between features, the new feature representation obtained by crossover between the two is likely to imply the new description of the user likes the item. However, not all crossover features are meaningful, i.e., there is a problem of limited expression of feature combinations. Therefore, this paper adopts an attention-based approach to learn the external cross-representation of features.
Explaining Classifiers by Constructing Familiar Concepts
Mar 07, 2022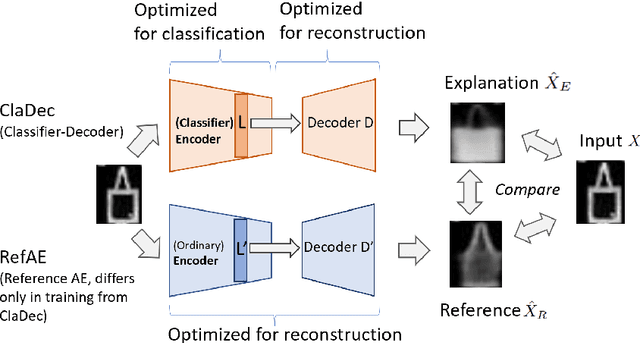
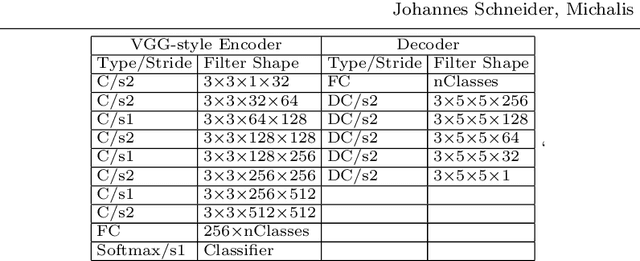
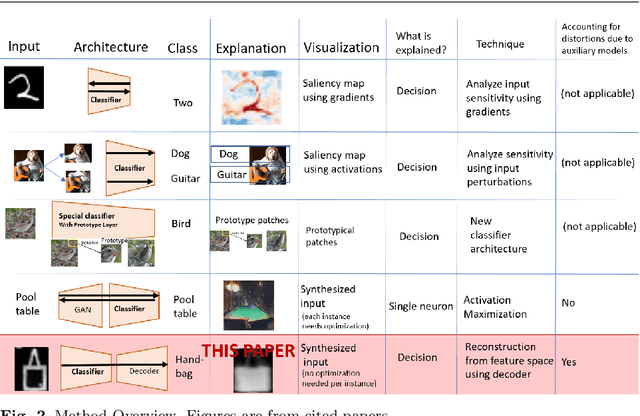
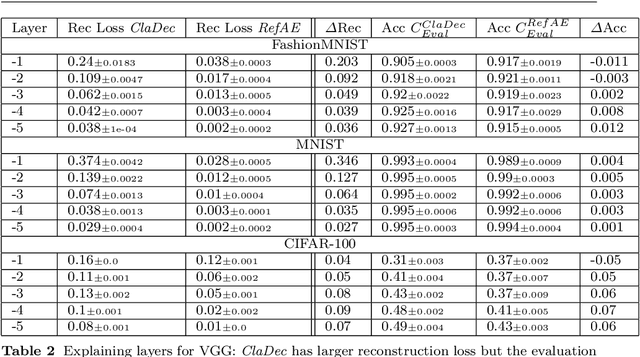
Interpreting a large number of neurons in deep learning is difficult. Our proposed `CLAssifier-DECoder' architecture (ClaDec) facilitates the understanding of the output of an arbitrary layer of neurons or subsets thereof. It uses a decoder that transforms the incomprehensible representation of the given neurons to a representation that is more similar to the domain a human is familiar with. In an image recognition problem, one can recognize what information (or concepts) a layer maintains by contrasting reconstructed images of ClaDec with those of a conventional auto-encoder(AE) serving as reference. An extension of ClaDec allows trading comprehensibility and fidelity. We evaluate our approach for image classification using convolutional neural networks. We show that reconstructed visualizations using encodings from a classifier capture more relevant classification information than conventional AEs. This holds although AEs contain more information on the original input. Our user study highlights that even non-experts can identify a diverse set of concepts contained in images that are relevant (or irrelevant) for the classifier. We also compare against saliency based methods that focus on pixel relevance rather than concepts. We show that ClaDec tends to highlight more relevant input areas to classification though outcomes depend on classifier architecture. Code is at \url{https://github.com/JohnTailor/ClaDec}
Gaze-enhanced Crossmodal Embeddings for Emotion Recognition
Apr 30, 2022
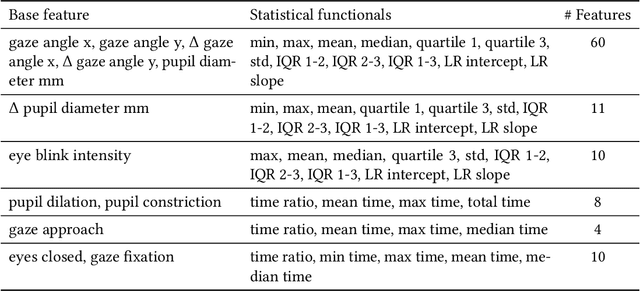

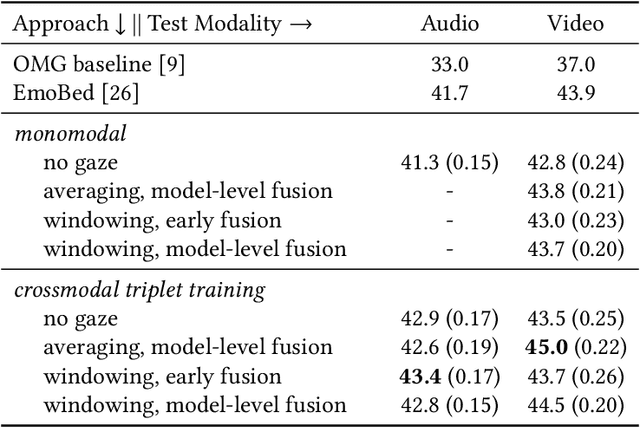
Emotional expressions are inherently multimodal -- integrating facial behavior, speech, and gaze -- but their automatic recognition is often limited to a single modality, e.g. speech during a phone call. While previous work proposed crossmodal emotion embeddings to improve monomodal recognition performance, despite its importance, an explicit representation of gaze was not included. We propose a new approach to emotion recognition that incorporates an explicit representation of gaze in a crossmodal emotion embedding framework. We show that our method outperforms the previous state of the art for both audio-only and video-only emotion classification on the popular One-Minute Gradual Emotion Recognition dataset. Furthermore, we report extensive ablation experiments and provide detailed insights into the performance of different state-of-the-art gaze representations and integration strategies. Our results not only underline the importance of gaze for emotion recognition but also demonstrate a practical and highly effective approach to leveraging gaze information for this task.