 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Collaborative Sensing in Perceptive Mobile Networks: Opportunities and Challenges
May 31, 2022
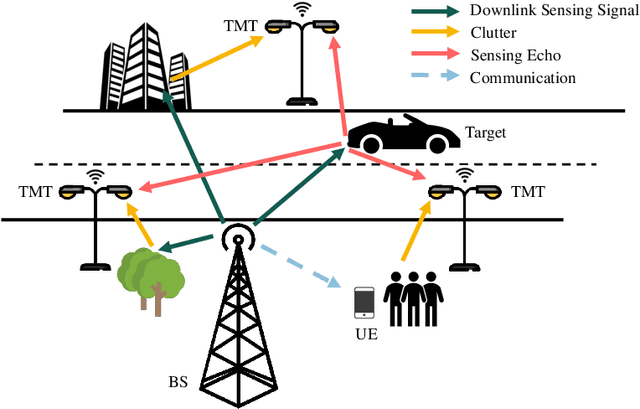
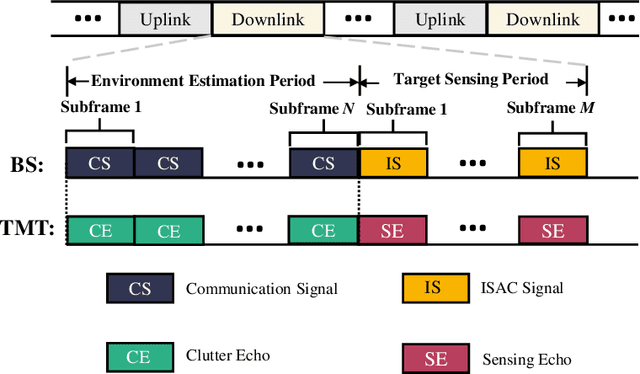
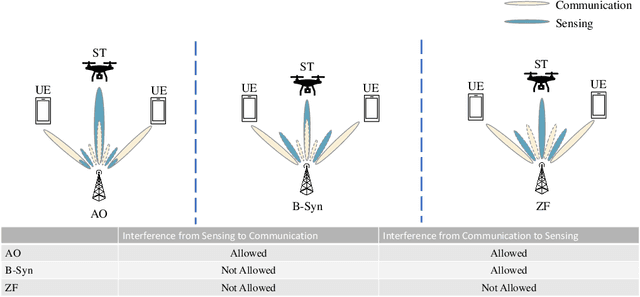
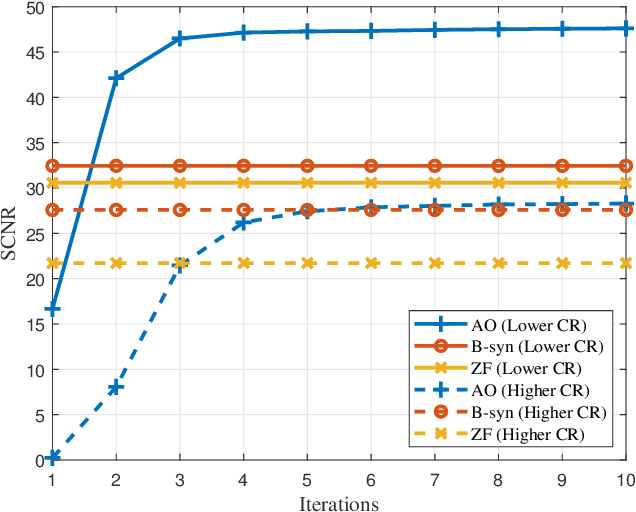
With the development of innovative applications that demand accurate environment information, e.g., autonomous driving, sensing becomes an important requirement for future wireless networks. To this end, integrated sensing and communication (ISAC) provides a promising platform to exploit the synergy between sensing and communication, where perceptive mobile networks (PMNs) were proposed to add accurate sensing capability to existing wireless networks. The well-developed cellular networks offer exciting opportunities for sensing, including large coverage, strong computation and communication power, and most importantly networked sensing, where the perspectives from multiple sensing nodes can be collaboratively utilized for sensing the same target. However, PMNs also face big challenges such as the inherent interference between sensing and communication, the complex sensing environment, and the tracking of high-speed targets by cellular networks. This paper provides a comprehensive review on the design of PMNs, covering the popular network architectures, sensing protocols, standing research problems, and available solutions. Several future research directions that are critical for the development of PMNs are also discussed.
Coarse-to-Fine Video Denoising with Dual-Stage Spatial-Channel Transformer
Apr 30, 2022
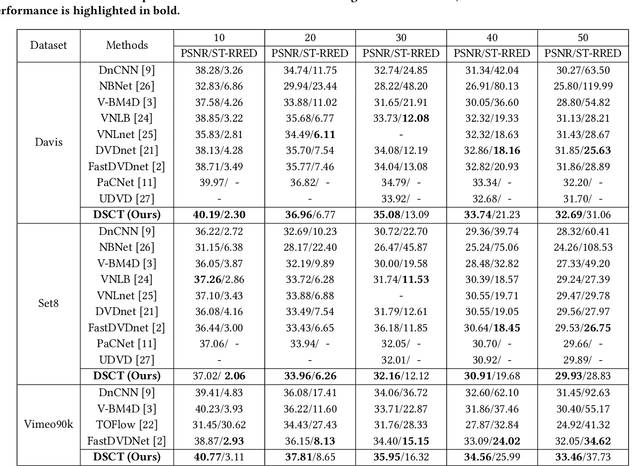
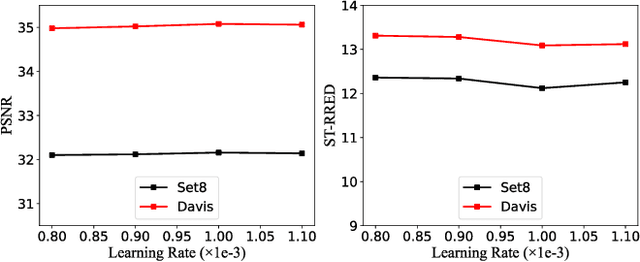
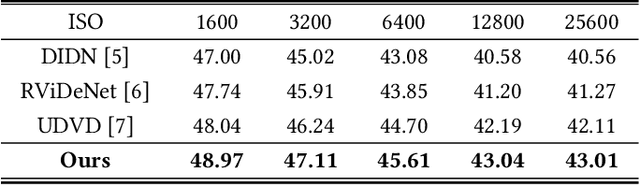
Video denoising aims to recover high-quality frames from the noisy video. While most existing approaches adopt convolutional neural networks(CNNs) to separate the noise from the original visual content, however, CNNs focus on local information and ignore the interactions between long-range regions. Furthermore, most related works directly take the output after spatio-temporal denoising as the final result, neglecting the fine-grained denoising process. In this paper, we propose a Dual-stage Spatial-Channel Transformer (DSCT) for coarse-to-fine video denoising, which inherits the advantages of both Transformer and CNNs. Specifically, DSCT is proposed based on a progressive dual-stage architecture, namely a coarse-level and a fine-level to extract dynamic feature and static feature, respectively. At both stages, a Spatial-Channel Encoding Module(SCEM) is designed to model the long-range contextual dependencies at spatial and channel levels. Meanwhile, we design a Multi-scale Residual Structure to preserve multiple aspects of information at different stages, which contains a Temporal Features Aggregation Module(TFAM) to summarize the dynamic representation. Extensive experiments on four publicly available datasets demonstrate our proposed DSCT achieves significant improvements compared to the state-of-the-art methods.
Phylogeny-Inspired Adaptation of Multilingual Models to New Languages
May 19, 2022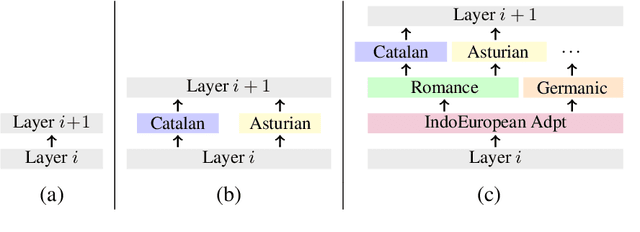
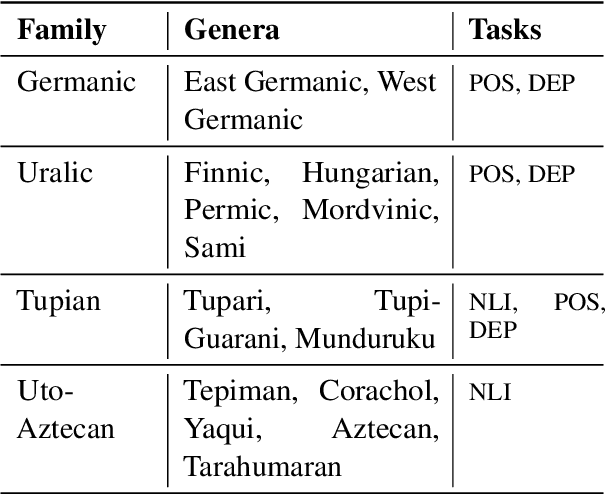
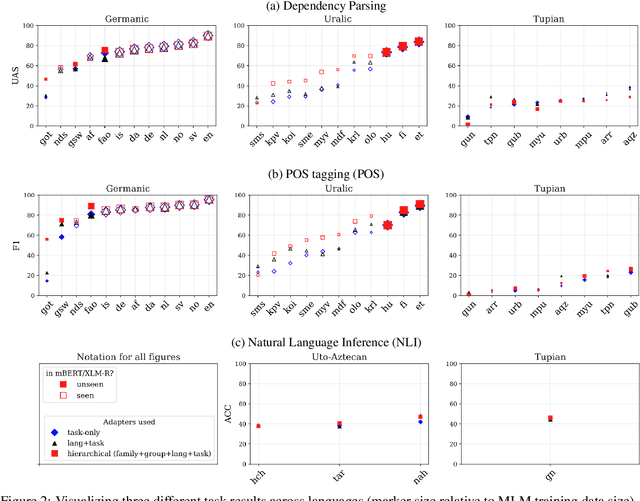
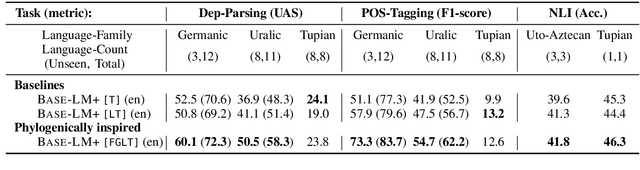
Large pretrained multilingual models, trained on dozens of languages, have delivered promising results due to cross-lingual learning capabilities on variety of language tasks. Further adapting these models to specific languages, especially ones unseen during pre-training, is an important goal towards expanding the coverage of language technologies. In this study, we show how we can use language phylogenetic information to improve cross-lingual transfer leveraging closely related languages in a structured, linguistically-informed manner. We perform adapter-based training on languages from diverse language families (Germanic, Uralic, Tupian, Uto-Aztecan) and evaluate on both syntactic and semantic tasks, obtaining more than 20% relative performance improvements over strong commonly used baselines, especially on languages unseen during pre-training.
InfoDCL: A Distantly Supervised Contrastive Learning Framework for Social Meaning
Mar 15, 2022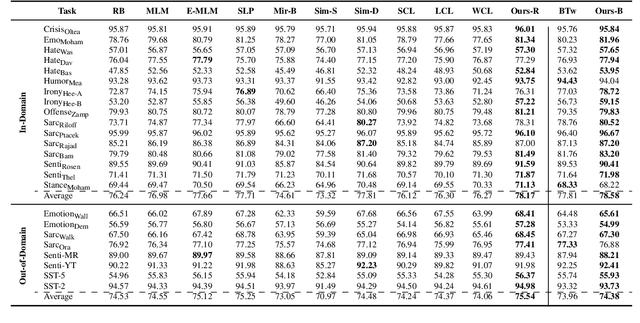
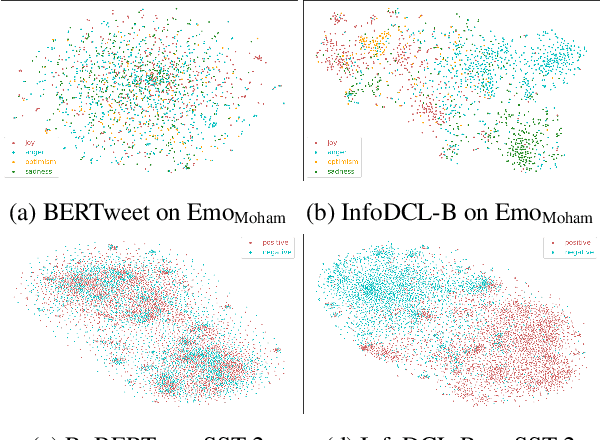
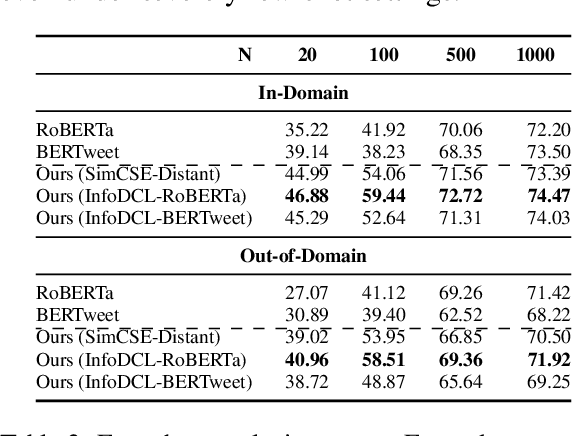
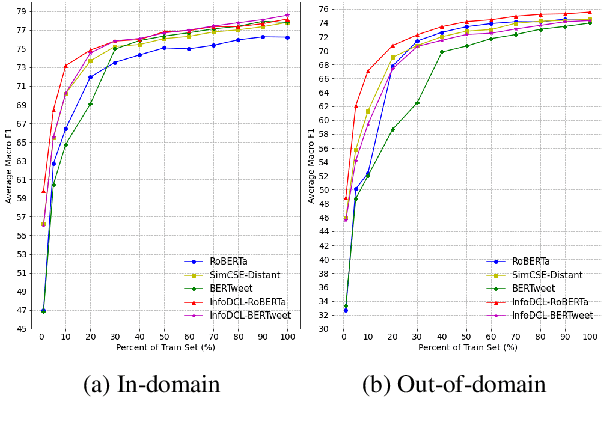
Existing supervised contrastive learning frameworks suffer from two major drawbacks: (i) they depend on labeled data, which is limited for the majority of tasks in real-world, and (ii) they incorporate inter-class relationships based on instance-level information, while ignoring corpus-level information, for weighting negative samples. To mitigate these challenges, we propose an effective distantly supervised contrastive learning framework (InfoDCL) that makes use of naturally occurring surrogate labels in the context of contrastive learning and employs pointwise mutual information to leverage corpus-level information. Our framework outperforms an extensive set of existing contrastive learning methods (self-supervised, supervised, and weakly supervised) on a wide range of social meaning tasks (in-domain and out-of-domain), in both the general and few-shot settings. Our method is also language-agnostic, as we demonstrate on three languages in addition to English.
Colonoscopy 3D Video Dataset with Paired Depth from 2D-3D Registration
Jun 17, 2022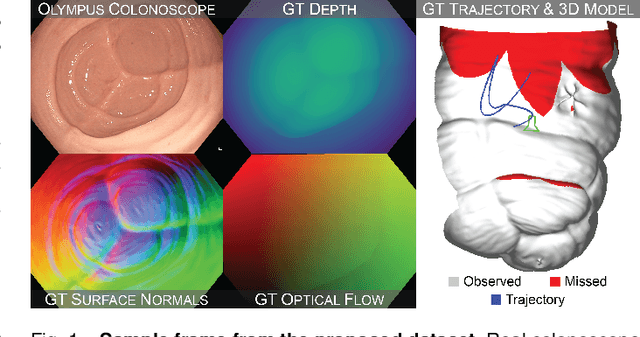
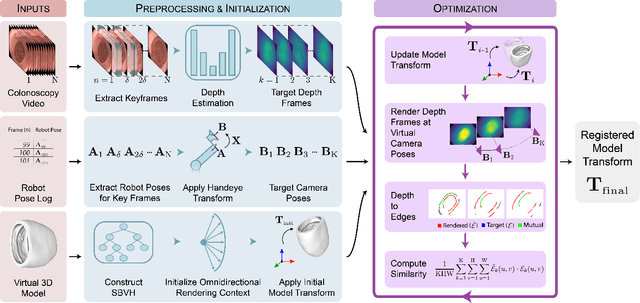
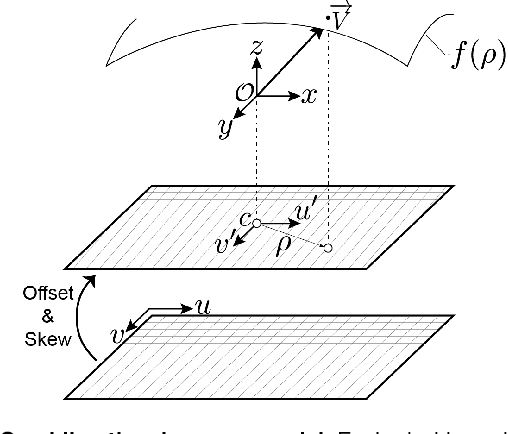
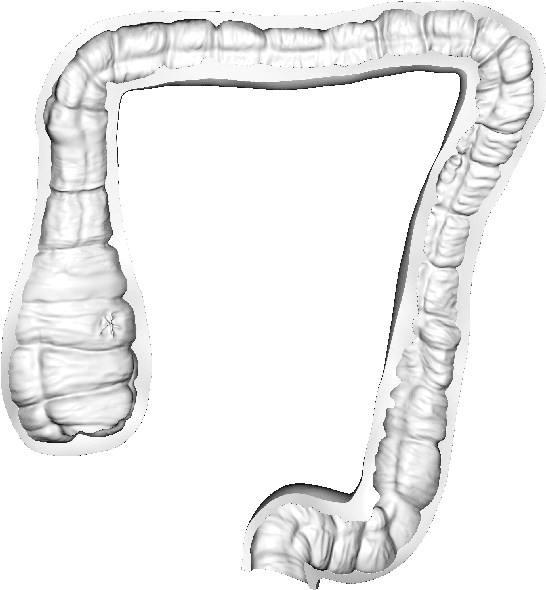
Screening colonoscopy is an important clinical application for several 3D computer vision techniques, including depth estimation, surface reconstruction, and missing region detection. However, the development, evaluation, and comparison of these techniques in real colonoscopy videos remain largely qualitative due to the difficulty of acquiring ground truth data. In this work, we present a Colonoscopy 3D Video Dataset (C3VD) acquired with a high definition clinical colonoscope and high-fidelity colon models for benchmarking computer vision methods in colonoscopy. We introduce a novel multimodal 2D-3D registration technique to register optical video sequences with ground truth rendered views of a known 3D model. The different modalities are registered by transforming optical images to depth maps with a Generative Adversarial Network and aligning edge features with an evolutionary optimizer. This registration method achieves an average translation error of 0.321 millimeters and an average rotation error of 0.159 degrees in simulation experiments where error-free ground truth is available. The method also leverages video information, improving registration accuracy by 55.6% for translation and 60.4% for rotation compared to single frame registration. 22 short video sequences were registered to generate 10,015 total frames with paired ground truth depth, surface normals, optical flow, occlusion, six degree-of-freedom pose, coverage maps, and 3D models. The dataset also includes screening videos acquired by a gastroenterologist with paired ground truth pose and 3D surface models. The dataset and registration source code are available at durr.jhu.edu/C3VD.
Common Information Components Analysis
Feb 28, 2020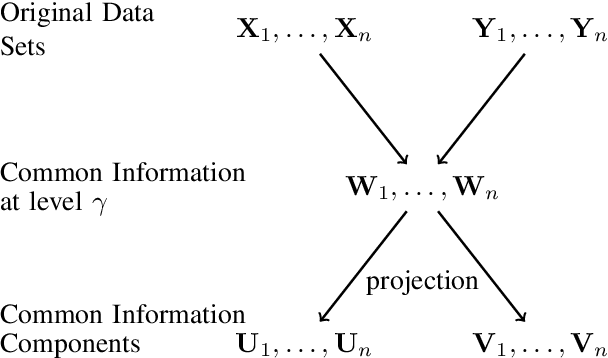
We give an information-theoretic interpretation of Canonical Correlation Analysis (CCA) via (relaxed) Wyner's common information. CCA permits to extract from two high-dimensional data sets low-dimensional descriptions (features) that capture the commonalities between the data sets, using a framework of correlations and linear transforms. Our interpretation first extracts the common information up to a pre-selected resolution level, and then projects this back onto each of the data sets. In the case of Gaussian statistics, this procedure precisely reduces to CCA, where the resolution level specifies the number of CCA components that are extracted. This also suggests a novel algorithm, Common Information Components Analysis (CICA), with several desirable features, including a natural extension to beyond just two data sets.
Approach to Predicting News -- A Precise Multi-LSTM Network With BERT
Apr 26, 2022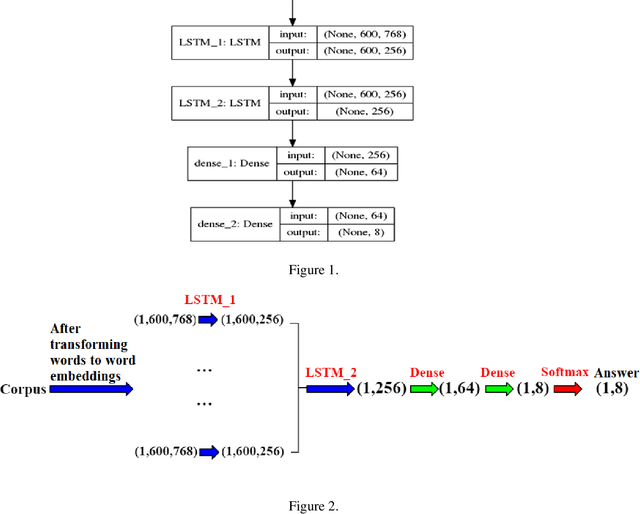
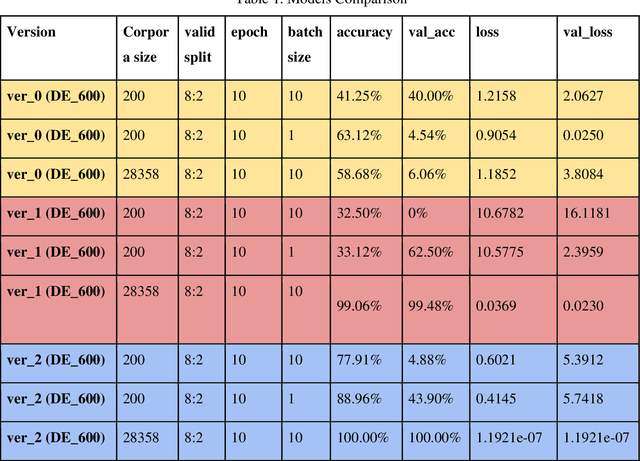
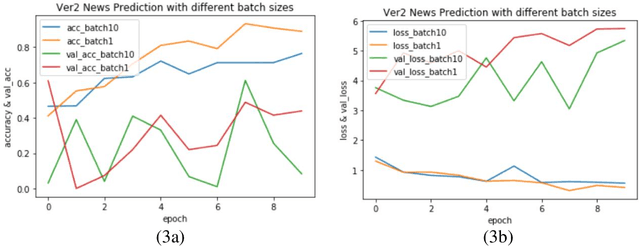
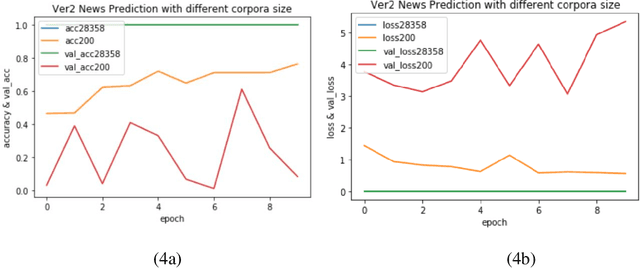
Varieties of Democracy (V-Dem) is a new approach to conceptualizing and measuring democracy and politics. It has information for 200 countries and is one of the biggest databases for political science. According to the V-Dem annual democracy report 2019, Taiwan is one of the two countries that got disseminated false information from foreign governments the most. It also shows that the "made-up news" has caused a great deal of confusion in Taiwanese society and has serious impacts on global stability. Although there are several applications helping distinguish the false information, we found out that the pre-processing of categorizing the news is still done by human labor. However, human labor may cause mistakes and cannot work for a long time. The growing demands for automatic machines in the near decades show that while the machine can do as good as humans or even better, using machines can reduce humans' burden and cut down costs. Therefore, in this work, we build a predictive model to classify the category of news. The corpora we used contains 28358 news and 200 news scraped from the online newspaper Liberty Times Net (LTN) website and includes 8 categories: Technology, Entertainment, Fashion, Politics, Sports, International, Finance, and Health. At first, we use Bidirectional Encoder Representations from Transformers (BERT) for word embeddings which transform each Chinese character into a (1,768) vector. Then, we use a Long Short-Term Memory (LSTM) layer to transform word embeddings into sentence embeddings and add another LSTM layer to transform them into document embeddings. Each document embedding is an input for the final predicting model, which contains two Dense layers and one Activation layer. And each document embedding is transformed into 1 vector with 8 real numbers, then the highest one will correspond to the 8 news categories with up to 99% accuracy.
* Accepted by The 25th International Conference on Information Management & Practice (IMP) 2019
Rare event failure test case generation in Learning-Enabled-Controllers
Jun 11, 2022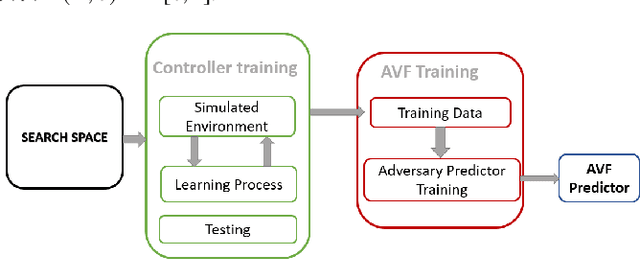
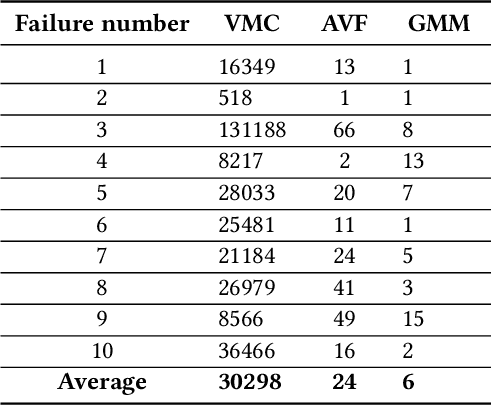
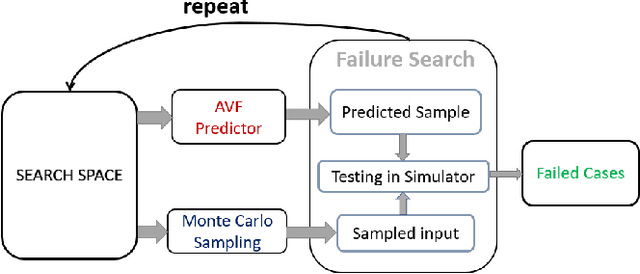

Machine learning models have prevalent applications in many real-world problems, which increases the importance of correctness in the behaviour of these trained models. Finding a good test case that can reveal the potential failure in these trained systems can help to retrain these models to increase their correctness. For a well-trained model, the occurrence of a failure is rare. Consequently, searching these rare scenarios by evaluating each sample in input search space or randomized search would be costly and sometimes intractable due to large search space, limited computational resources, and available time. In this paper, we tried to address this challenge of finding these failure scenarios faster than traditional randomized search. The central idea of our approach is to separate the input data space in region of high failure probability and region of low/minimal failure probability based on the observation made by training data, data drawn from real-world statistics, and knowledge from a domain expert. Using these information, we can design a generative model from which we can generate scenarios that have a high likelihood to reveal the potential failure. We evaluated this approach on two different experimental scenarios and able to speed up the discovery of such failures a thousand-fold faster than the traditional randomized search.
Stereographic Markov Chain Monte Carlo
May 24, 2022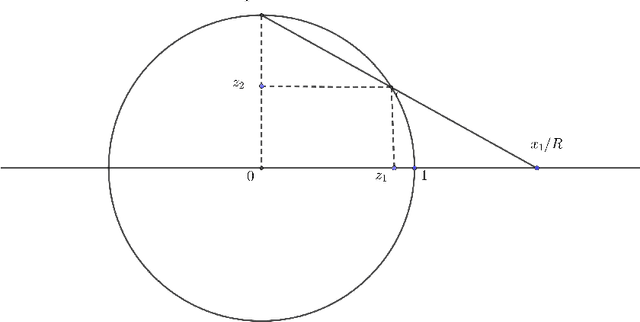

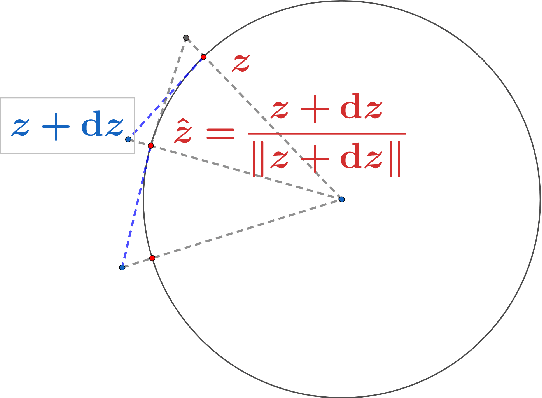
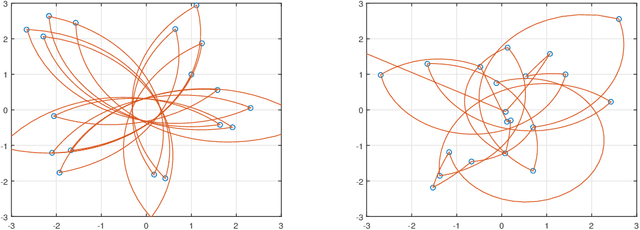
High dimensional distributions, especially those with heavy tails, are notoriously difficult for off-the-shelf MCMC samplers: the combination of unbounded state spaces, diminishing gradient information, and local moves, results in empirically observed "stickiness" and poor theoretical mixing properties -- lack of geometric ergodicity. In this paper, we introduce a new class of MCMC samplers that map the original high dimensional problem in Euclidean space onto a sphere and remedy these notorious mixing problems. In particular, we develop random-walk Metropolis type algorithms as well as versions of Bouncy Particle Sampler that are uniformly ergodic for a large class of light and heavy-tailed distributions and also empirically exhibit rapid convergence in high dimensions. In the best scenario, the proposed samplers can enjoy the ``blessings of dimensionality'' that the mixing time decreases with dimension.
IB-DRR: Incremental Learning with Information-Back Discrete Representation Replay
Apr 21, 2021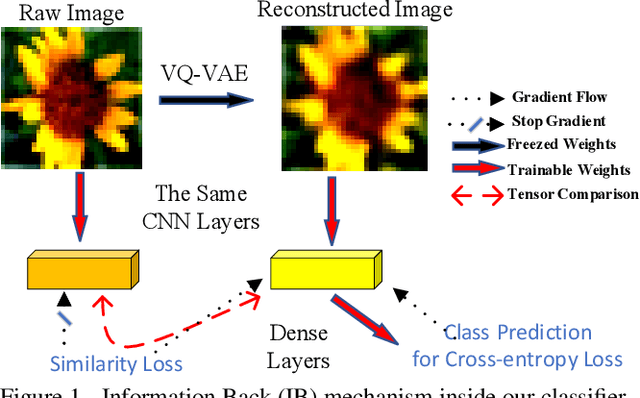
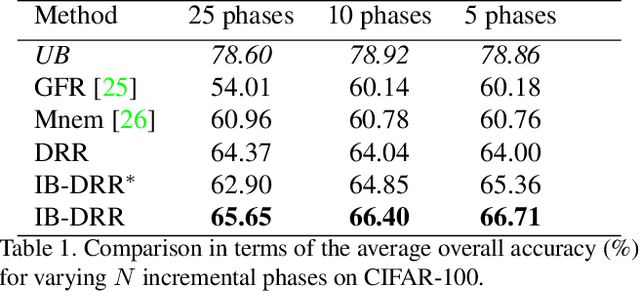
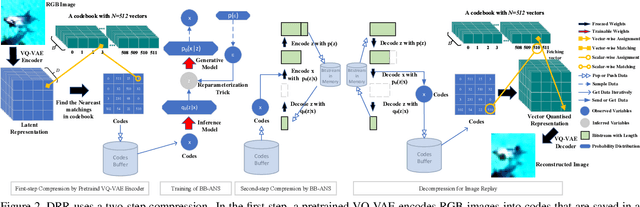
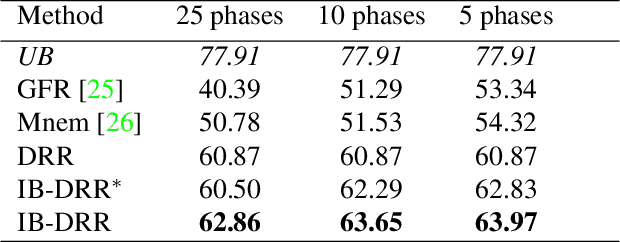
Incremental learning aims to enable machine learning models to continuously acquire new knowledge given new classes, while maintaining the knowledge already learned for old classes. Saving a subset of training samples of previously seen classes in the memory and replaying them during new training phases is proven to be an efficient and effective way to fulfil this aim. It is evident that the larger number of exemplars the model inherits the better performance it can achieve. However, finding a trade-off between the model performance and the number of samples to save for each class is still an open problem for replay-based incremental learning and is increasingly desirable for real-life applications. In this paper, we approach this open problem by tapping into a two-step compression approach. The first step is a lossy compression, we propose to encode input images and save their discrete latent representations in the form of codes that are learned using a hierarchical Vector Quantised Variational Autoencoder (VQ-VAE). In the second step, we further compress codes losslessly by learning a hierarchical latent variable model with bits-back asymmetric numeral systems (BB-ANS). To compensate for the information lost in the first step compression, we introduce an Information Back (IB) mechanism that utilizes real exemplars for a contrastive learning loss to regularize the training of a classifier. By maintaining all seen exemplars' representations in the format of `codes', Discrete Representation Replay (DRR) outperforms the state-of-art method on CIFAR-100 by a margin of 4% accuracy with a much less memory cost required for saving samples. Incorporated with IB and saving a small set of old raw exemplars as well, the accuracy of DRR can be further improved by 2% accuracy.