 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Transformer based Urdu Handwritten Text Optical Character Reader
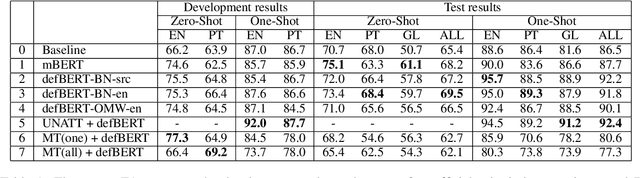
Jun 09, 2022
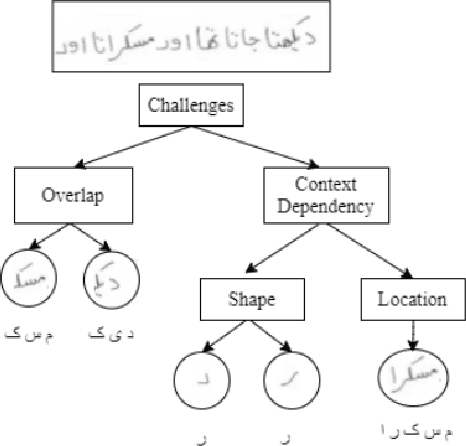
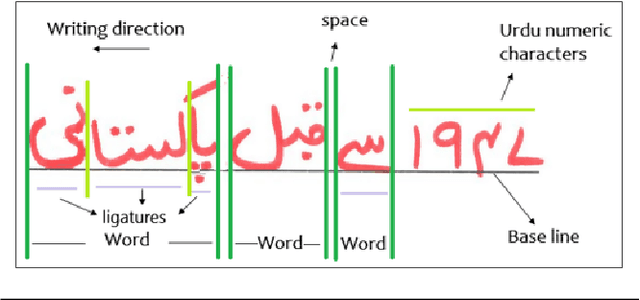
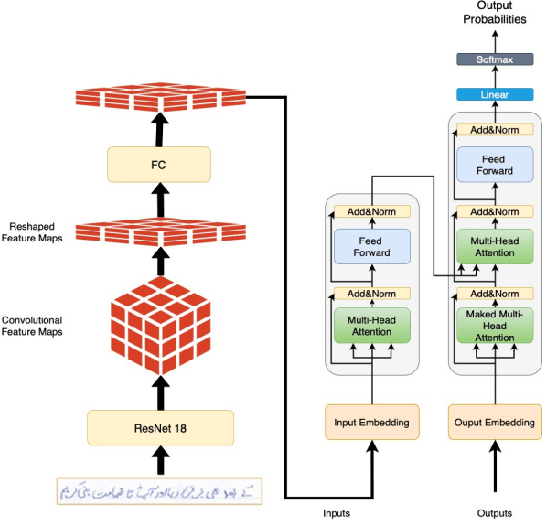

Extracting Handwritten text is one of the most important components of digitizing information and making it available for large scale setting. Handwriting Optical Character Reader (OCR) is a research problem in computer vision and natural language processing computing, and a lot of work has been done for English, but unfortunately, very little work has been done for low resourced languages such as Urdu. Urdu language script is very difficult because of its cursive nature and change of shape of characters based on it's relative position, therefore, a need arises to propose a model which can understand complex features and generalize it for every kind of handwriting style. In this work, we propose a transformer based Urdu Handwritten text extraction model. As transformers have been very successful in Natural Language Understanding task, we explore them further to understand complex Urdu Handwriting.
Multiformer: A Head-Configurable Transformer-Based Model for Direct Speech Translation
May 14, 2022
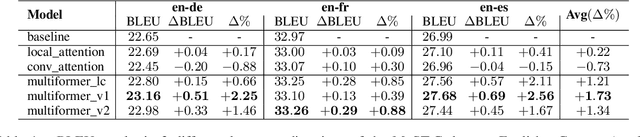
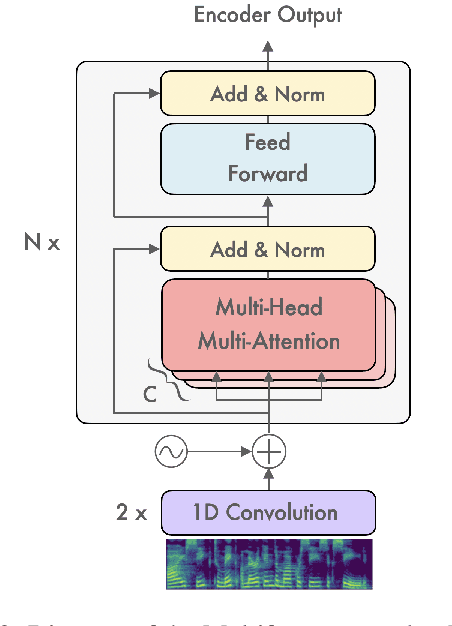
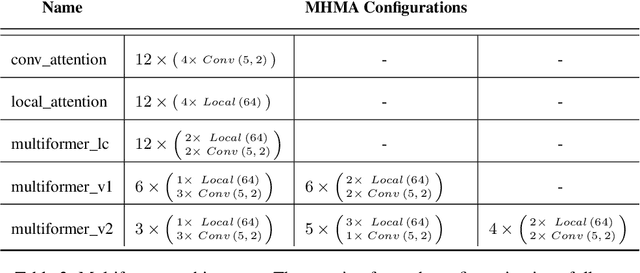
Transformer-based models have been achieving state-of-the-art results in several fields of Natural Language Processing. However, its direct application to speech tasks is not trivial. The nature of this sequences carries problems such as long sequence lengths and redundancy between adjacent tokens. Therefore, we believe that regular self-attention mechanism might not be well suited for it. Different approaches have been proposed to overcome these problems, such as the use of efficient attention mechanisms. However, the use of these methods usually comes with a cost, which is a performance reduction caused by information loss. In this study, we present the Multiformer, a Transformer-based model which allows the use of different attention mechanisms on each head. By doing this, the model is able to bias the self-attention towards the extraction of more diverse token interactions, and the information loss is reduced. Finally, we perform an analysis of the head contributions, and we observe that those architectures where all heads relevance is uniformly distributed obtain better results. Our results show that mixing attention patterns along the different heads and layers outperforms our baseline by up to 0.7 BLEU.
Knowledge Graph Fusion for Language Model Fine-tuning
Jun 21, 2022
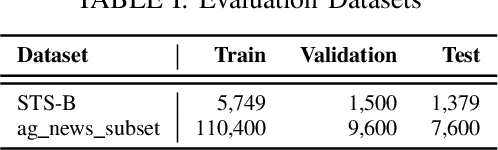
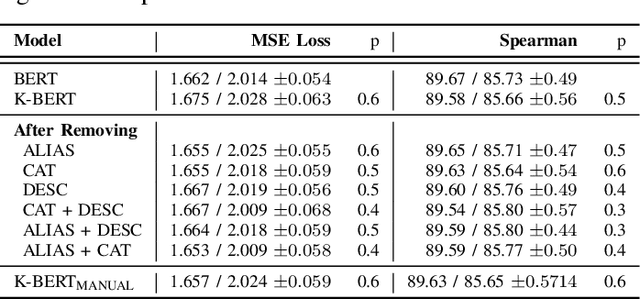
Language Models such as BERT have grown in popularity due to their ability to be pre-trained and perform robustly on a wide range of Natural Language Processing tasks. Often seen as an evolution over traditional word embedding techniques, they can produce semantic representations of text, useful for tasks such as semantic similarity. However, state-of-the-art models often have high computational requirements and lack global context or domain knowledge which is required for complete language understanding. To address these limitations, we investigate the benefits of knowledge incorporation into the fine-tuning stages of BERT. An existing K-BERT model, which enriches sentences with triplets from a Knowledge Graph, is adapted for the English language and extended to inject contextually relevant information into sentences. As a side-effect, changes made to K-BERT for accommodating the English language also extend to other word-based languages. Experiments conducted indicate that injected knowledge introduces noise. We see statistically significant improvements for knowledge-driven tasks when this noise is minimised. We show evidence that, given the appropriate task, modest injection with relevant, high-quality knowledge is most performant.
Certifiably Robust Policy Learning against Adversarial Communication in Multi-agent Systems
Jun 21, 2022
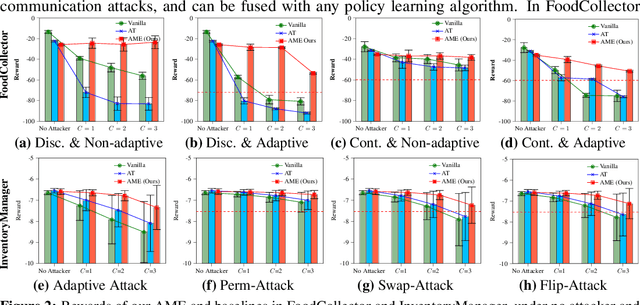
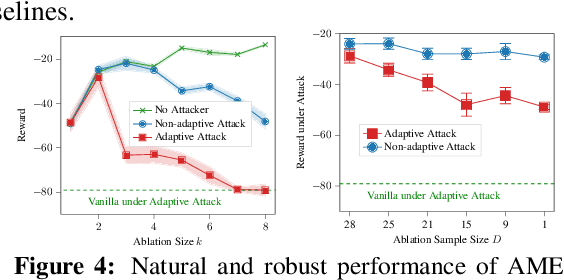
Communication is important in many multi-agent reinforcement learning (MARL) problems for agents to share information and make good decisions. However, when deploying trained communicative agents in a real-world application where noise and potential attackers exist, the safety of communication-based policies becomes a severe issue that is underexplored. Specifically, if communication messages are manipulated by malicious attackers, agents relying on untrustworthy communication may take unsafe actions that lead to catastrophic consequences. Therefore, it is crucial to ensure that agents will not be misled by corrupted communication, while still benefiting from benign communication. In this work, we consider an environment with $N$ agents, where the attacker may arbitrarily change the communication from any $C<\frac{N-1}{2}$ agents to a victim agent. For this strong threat model, we propose a certifiable defense by constructing a message-ensemble policy that aggregates multiple randomly ablated message sets. Theoretical analysis shows that this message-ensemble policy can utilize benign communication while being certifiably robust to adversarial communication, regardless of the attacking algorithm. Experiments in multiple environments verify that our defense significantly improves the robustness of trained policies against various types of attacks.
An Exploration of Post-Editing Effectiveness in Text Summarization
Jun 13, 2022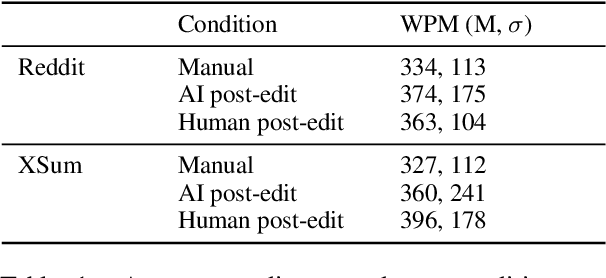
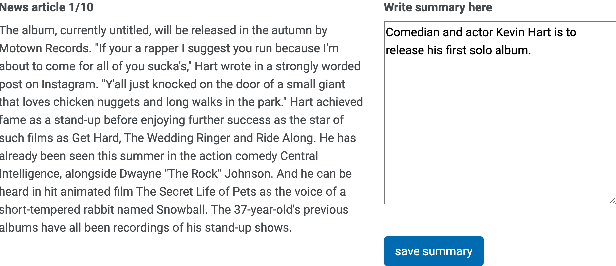
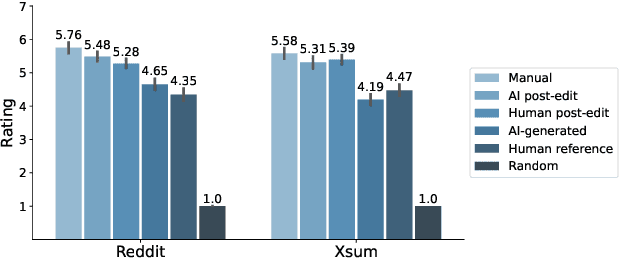

Automatic summarization methods are efficient but can suffer from low quality. In comparison, manual summarization is expensive but produces higher quality. Can humans and AI collaborate to improve summarization performance? In similar text generation tasks (e.g., machine translation), human-AI collaboration in the form of "post-editing" AI-generated text reduces human workload and improves the quality of AI output. Therefore, we explored whether post-editing offers advantages in text summarization. Specifically, we conducted an experiment with 72 participants, comparing post-editing provided summaries with manual summarization for summary quality, human efficiency, and user experience on formal (XSum news) and informal (Reddit posts) text. This study sheds valuable insights on when post-editing is useful for text summarization: it helped in some cases (e.g., when participants lacked domain knowledge) but not in others (e.g., when provided summaries include inaccurate information). Participants' different editing strategies and needs for assistance offer implications for future human-AI summarization systems.
Graph-Time Convolutional Neural Networks: Architecture and Theoretical Analysis
Jun 30, 2022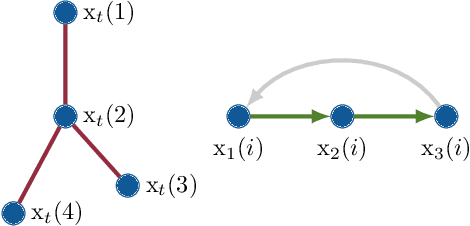
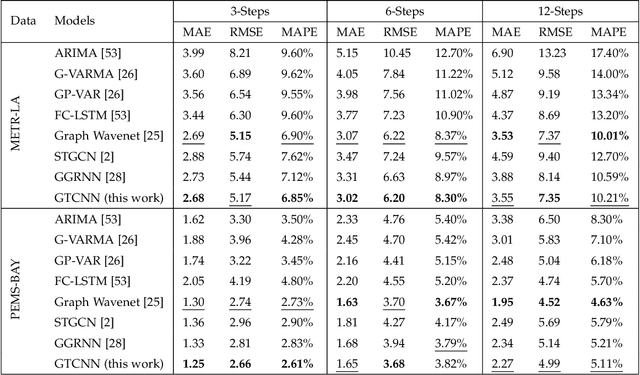
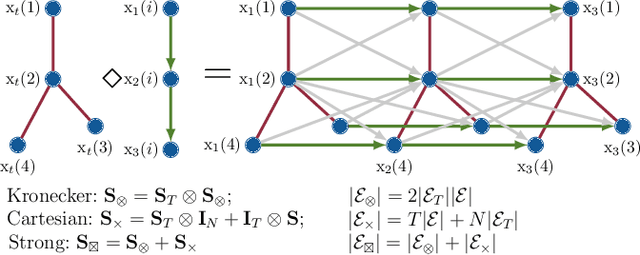
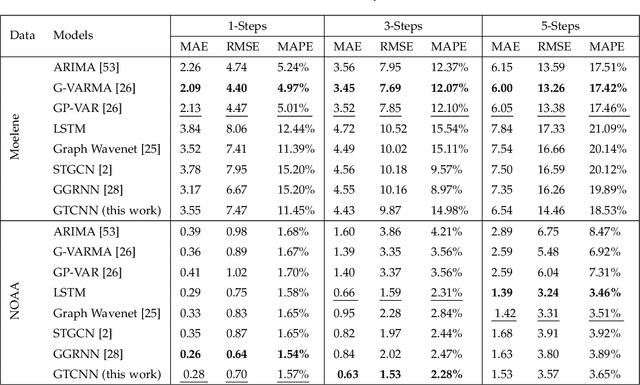
Devising and analyzing learning models for spatiotemporal network data is of importance for tasks including forecasting, anomaly detection, and multi-agent coordination, among others. Graph Convolutional Neural Networks (GCNNs) are an established approach to learn from time-invariant network data. The graph convolution operation offers a principled approach to aggregate multiresolution information. However, extending the convolution principled learning and respective analysis to the spatiotemporal domain is challenging because spatiotemporal data have more intrinsic dependencies. Hence, a higher flexibility to capture jointly the spatial and the temporal dependencies is required to learn meaningful higher-order representations. Here, we leverage product graphs to represent the spatiotemporal dependencies in the data and introduce Graph-Time Convolutional Neural Networks (GTCNNs) as a principled architecture to aid learning. The proposed approach can work with any type of product graph and we also introduce a parametric product graph to learn also the spatiotemporal coupling. The convolution principle further allows a similar mathematical tractability as for GCNNs. In particular, the stability result shows GTCNNs are stable to spatial perturbations but there is an implicit trade-off between discriminability and robustness; i.e., the more complex the model, the less stable. Extensive numerical results on benchmark datasets corroborate our findings and show the GTCNN compares favorably with state-of-the-art solutions. We anticipate the GTCNN to be a starting point for more sophisticated models that achieve good performance but are also fundamentally grounded.
Biographical: A Semi-Supervised Relation Extraction Dataset
May 02, 2022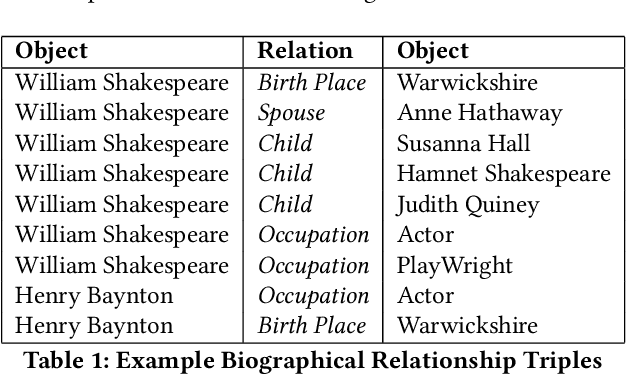
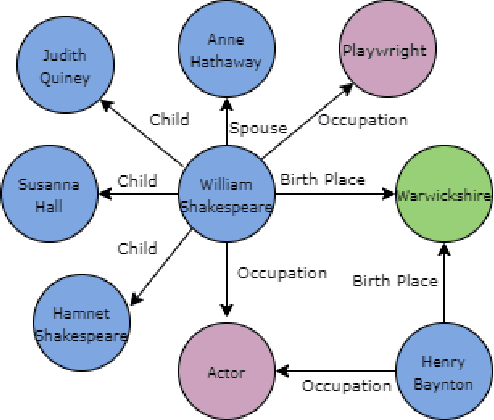
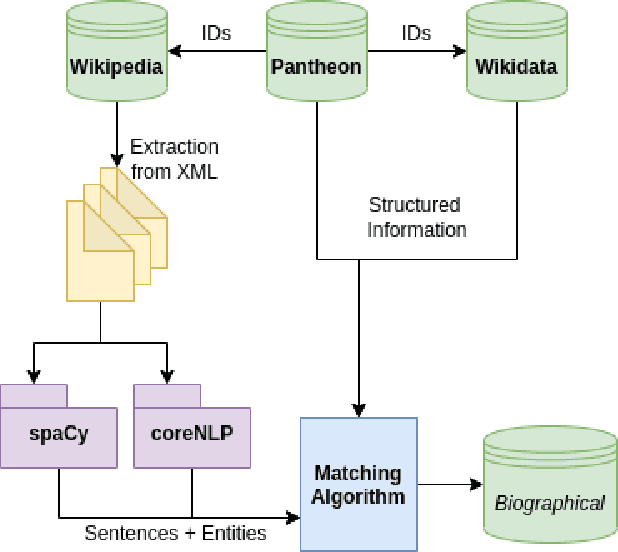
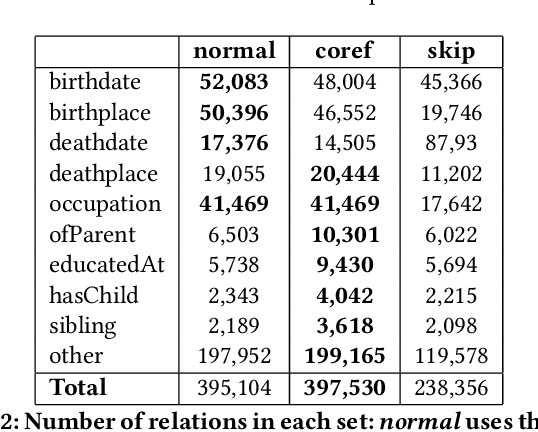
Extracting biographical information from online documents is a popular research topic among the information extraction (IE) community. Various natural language processing (NLP) techniques such as text classification, text summarisation and relation extraction are commonly used to achieve this. Among these techniques, RE is the most common since it can be directly used to build biographical knowledge graphs. RE is usually framed as a supervised machine learning (ML) problem, where ML models are trained on annotated datasets. However, there are few annotated datasets for RE since the annotation process can be costly and time-consuming. To address this, we developed Biographical, the first semi-supervised dataset for RE. The dataset, which is aimed towards digital humanities (DH) and historical research, is automatically compiled by aligning sentences from Wikipedia articles with matching structured data from sources including Pantheon and Wikidata. By exploiting the structure of Wikipedia articles and robust named entity recognition (NER), we match information with relatively high precision in order to compile annotated relation pairs for ten different relations that are important in the DH domain. Furthermore, we demonstrate the effectiveness of the dataset by training a state-of-the-art neural model to classify relation pairs, and evaluate it on a manually annotated gold standard set. Biographical is primarily aimed at training neural models for RE within the domain of digital humanities and history, but as we discuss at the end of this paper, it can be useful for other purposes as well.
Learning Fair Representation via Distributional Contrastive Disentanglement
Jun 17, 2022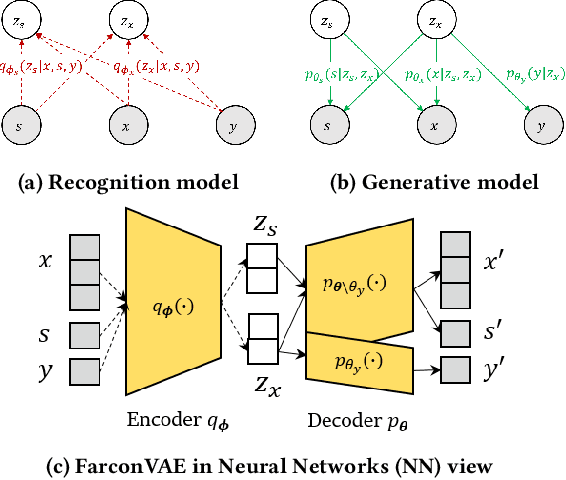
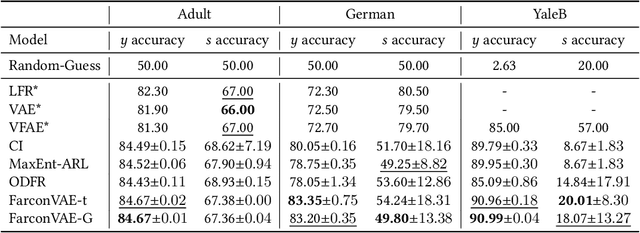
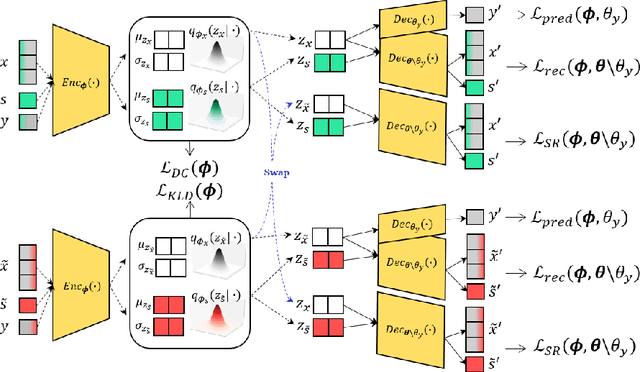
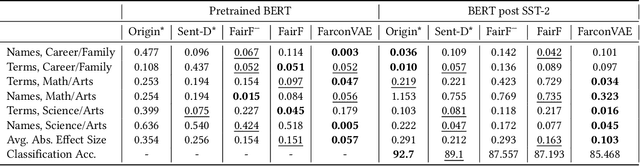
Learning fair representation is crucial for achieving fairness or debiasing sensitive information. Most existing works rely on adversarial representation learning to inject some invariance into representation. However, adversarial learning methods are known to suffer from relatively unstable training, and this might harm the balance between fairness and predictiveness of representation. We propose a new approach, learning FAir Representation via distributional CONtrastive Variational AutoEncoder (FarconVAE), which induces the latent space to be disentangled into sensitive and nonsensitive parts. We first construct the pair of observations with different sensitive attributes but with the same labels. Then, FarconVAE enforces each non-sensitive latent to be closer, while sensitive latents to be far from each other and also far from the non-sensitive latent by contrasting their distributions. We provide a new type of contrastive loss motivated by Gaussian and Student-t kernels for distributional contrastive learning with theoretical analysis. Besides, we adopt a new swap-reconstruction loss to boost the disentanglement further. FarconVAE shows superior performance on fairness, pretrained model debiasing, and domain generalization tasks from various modalities, including tabular, image, and text.
UAlberta at SemEval 2022 Task 2: Leveraging Glosses and Translations for Multilingual Idiomaticity Detection
May 27, 2022
We describe the University of Alberta systems for the SemEval-2022 Task 2 on multilingual idiomaticity detection. Working under the assumption that idiomatic expressions are noncompositional, our first method integrates information on the meanings of the individual words of an expression into a binary classifier. Further hypothesizing that literal and idiomatic expressions translate differently, our second method translates an expression in context, and uses a lexical knowledge base to determine if the translation is literal. Our approaches are grounded in linguistic phenomena, and leverage existing sources of lexical knowledge. Our results offer support for both approaches, particularly the former.
Pushing the Limit of Phase Shift Feedback Compression for Intelligent Reflecting Surface-Assisted Wireless Systems by Exploiting Global Attention
Jul 05, 2022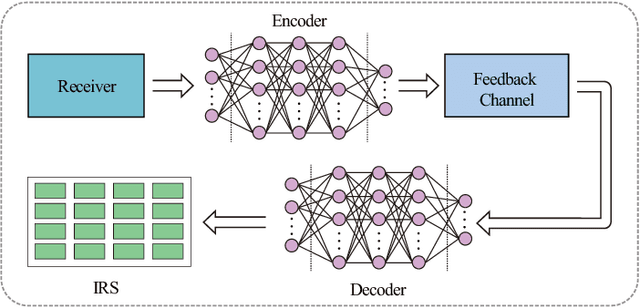
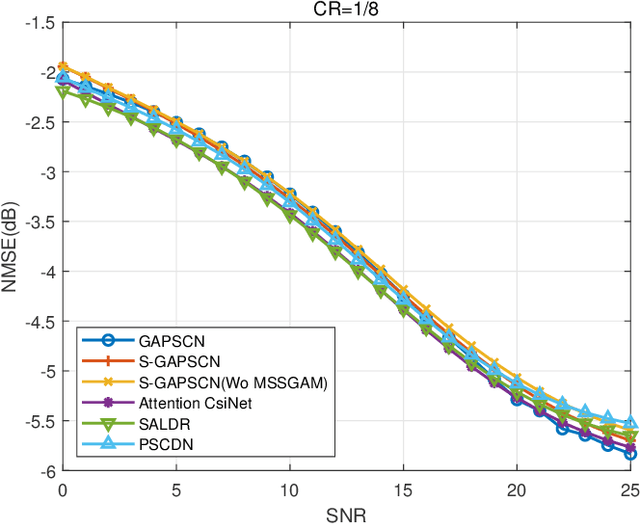
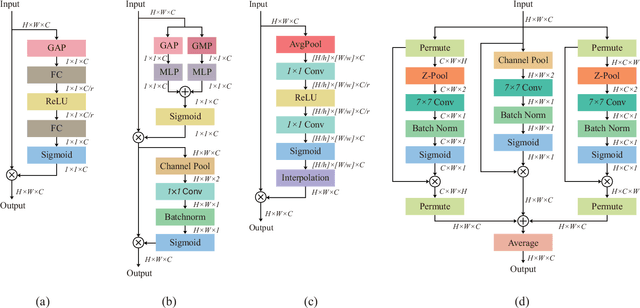
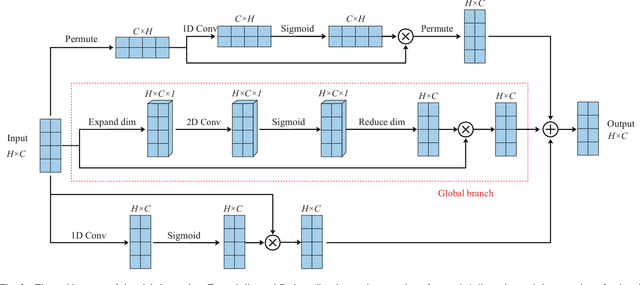
Intelligent reflecting surface (IRS) has recently appeared as a potential technology for 6G, and received much attention from academia and industry. However, most of existing works on IRS focus on how to compute the phase shift for performance enhancement, and the problem on how to obtain the computed phase shift at the IRS side is generally neglected. In this paper, we consider compressing the computed phase shift at the receiver side to the IRS through a bandwidth-limited feedback channel. In particular, we propose and investigate a novel attention mechanism named as global attention by exploiting the attention map over both spatial and channel dimensions. This allows us to to push the limit of phase shift feedback compression by utilizing the two-dimensional information, which is in sharp contrast to exiting works that only consider either the spatial or channel dimension. Besides, to cope with the problem of mismatched distribution of the phase shift, we introduce the generalized divisive normalization (GDN) layer and inverse generalized divisive normalization (IGDN) layer to the proposed global attention phase shift compression network (GAPSCN). Furthermore, due to practical constraints on the IRS, it is desirable to consider a simplified GAPSCN (S-GAPSCN), where a lightweight multi-scale simplified global attention module (MSSGAM) is proposed in the decoder located at the IRS side to compensate for the performance degradation due to the simplified structure. Simulation results show that the proposed GAPSCN is able to achieve a reconstruction accuracy close to 1 and performs much better than existing algorithms. The performance of the proposed S-GAPSCN can approach that of the GAPSCN but with a much lower computational load.