 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Camera Pose Auto-Encoders for Improving Pose Regression
Jul 12, 2022
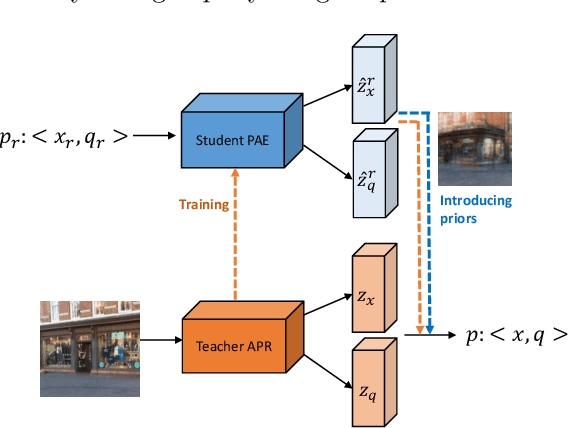

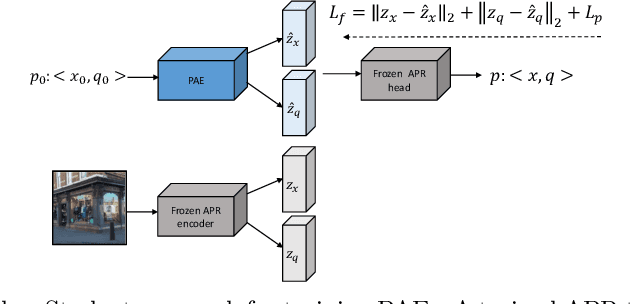
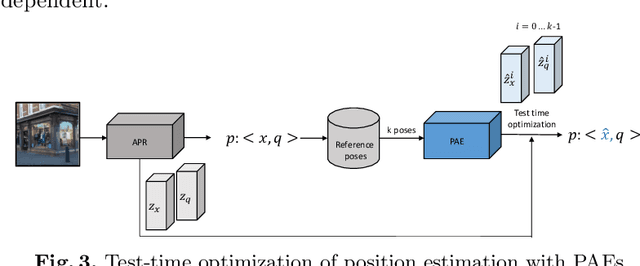
Absolute pose regressor (APR) networks are trained to estimate the pose of the camera given a captured image. They compute latent image representations from which the camera position and orientation are regressed. APRs provide a different tradeoff between localization accuracy, runtime, and memory, compared to structure-based localization schemes that provide state-of-the-art accuracy. In this work, we introduce Camera Pose Auto-Encoders (PAEs), multilayer perceptrons that are trained via a Teacher-Student approach to encode camera poses using APRs as their teachers. We show that the resulting latent pose representations can closely reproduce APR performance and demonstrate their effectiveness for related tasks. Specifically, we propose a light-weight test-time optimization in which the closest train poses are encoded and used to refine camera position estimation. This procedure achieves a new state-of-the-art position accuracy for APRs, on both the CambridgeLandmarks and 7Scenes benchmarks. We also show that train images can be reconstructed from the learned pose encoding, paving the way for integrating visual information from the train set at a low memory cost. Our code and pre-trained models are available at https://github.com/yolish/camera-pose-auto-encoders.
Label2Label: A Language Modeling Framework for Multi-Attribute Learning
Jul 18, 2022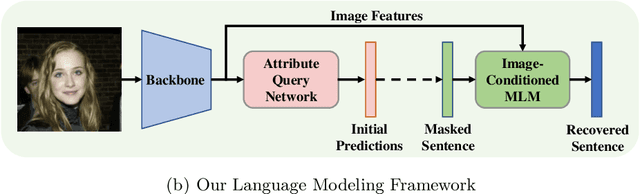

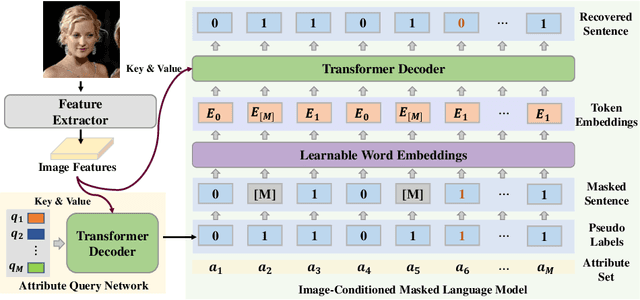
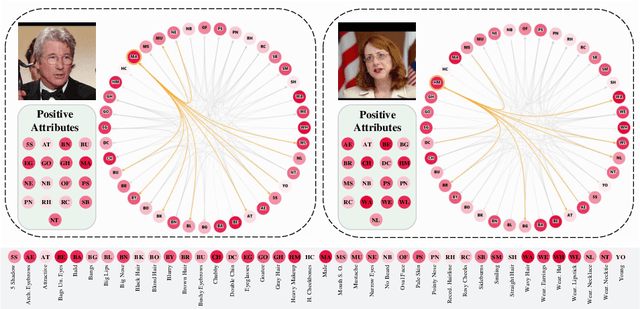
Objects are usually associated with multiple attributes, and these attributes often exhibit high correlations. Modeling complex relationships between attributes poses a great challenge for multi-attribute learning. This paper proposes a simple yet generic framework named Label2Label to exploit the complex attribute correlations. Label2Label is the first attempt for multi-attribute prediction from the perspective of language modeling. Specifically, it treats each attribute label as a "word" describing the sample. As each sample is annotated with multiple attribute labels, these "words" will naturally form an unordered but meaningful "sentence", which depicts the semantic information of the corresponding sample. Inspired by the remarkable success of pre-training language models in NLP, Label2Label introduces an image-conditioned masked language model, which randomly masks some of the "word" tokens from the label "sentence" and aims to recover them based on the masked "sentence" and the context conveyed by image features. Our intuition is that the instance-wise attribute relations are well grasped if the neural net can infer the missing attributes based on the context and the remaining attribute hints. Label2Label is conceptually simple and empirically powerful. Without incorporating task-specific prior knowledge and highly specialized network designs, our approach achieves state-of-the-art results on three different multi-attribute learning tasks, compared to highly customized domain-specific methods. Code is available at https://github.com/Li-Wanhua/Label2Label.
A Correlation-Ratio Transfer Learning and Variational Stein's Paradox
Jun 10, 2022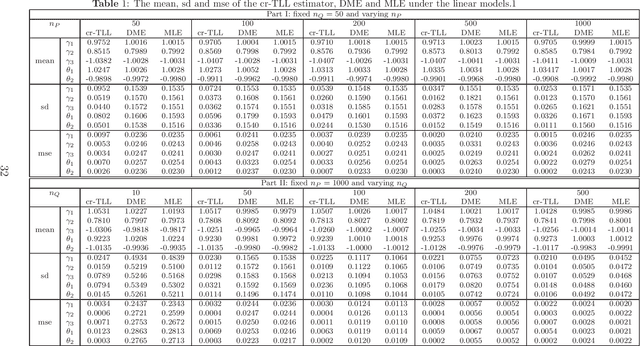
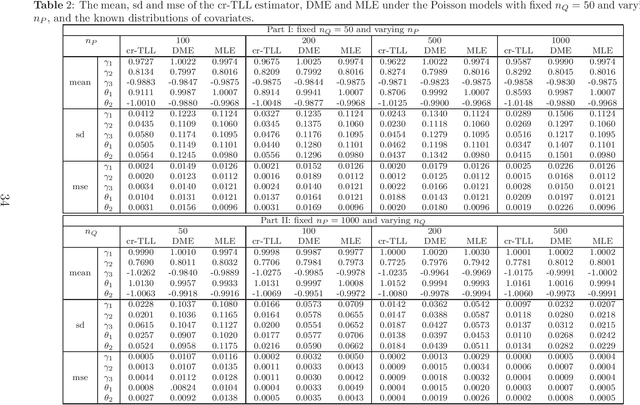
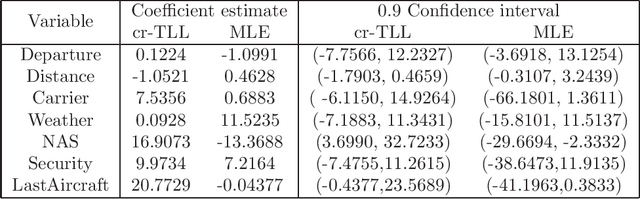
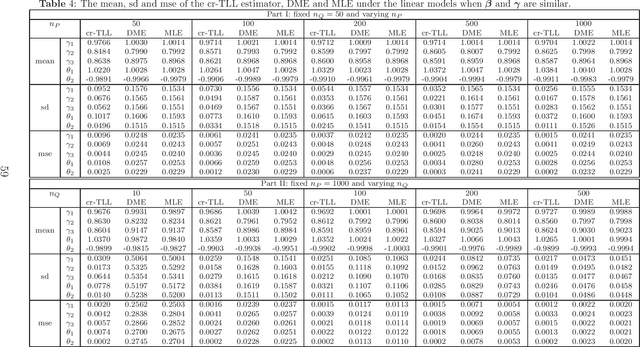
A basic condition for efficient transfer learning is the similarity between a target model and source models. In practice, however, the similarity condition is difficult to meet or is even violated. Instead of the similarity condition, a brand-new strategy, linear correlation-ratio, is introduced in this paper to build an accurate relationship between the models. Such a correlation-ratio can be easily estimated by historical data or a part of sample. Then, a correlation-ratio transfer learning likelihood is established based on the correlation-ratio combination. On the practical side, the new framework is applied to some application scenarios, especially the areas of data streams and medical studies. Methodologically, some techniques are suggested for transferring the information from simple source models to a relatively complex target model. Theoretically, some favorable properties, including the global convergence rate, are achieved, even for the case where the source models are not similar to the target model. All in all, it can be seen from the theories and experimental results that the inference on the target model is significantly improved by the information from similar or dissimilar source models. In other words, a variational Stein's paradox is illustrated in the context of transfer learning.
TraClets: Harnessing the power of computer vision for trajectory classification
May 30, 2022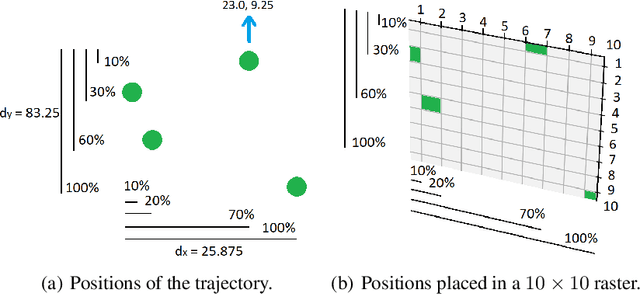
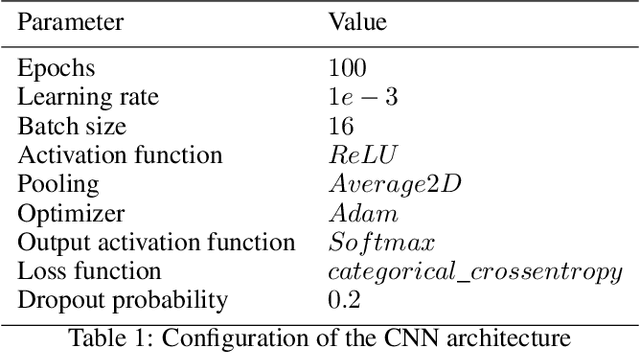
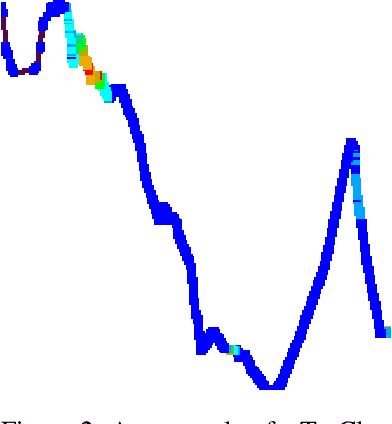
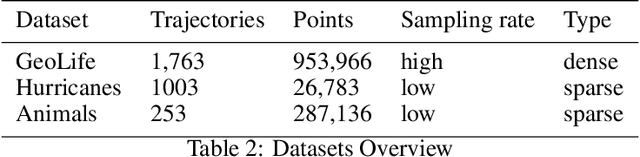
Due to the advent of new mobile devices and tracking sensors in recent years, huge amounts of data are being produced every day. Therefore, novel methodologies need to emerge that dive through this vast sea of information and generate insights and meaningful information. To this end, researchers have developed several trajectory classification algorithms over the years that are able to annotate tracking data. Similarly, in this research, a novel methodology is presented that exploits image representations of trajectories, called TraClets, in order to classify trajectories in an intuitive humans way, through computer vision techniques. Several real-world datasets are used to evaluate the proposed approach and compare its classification performance to other state-of-the-art trajectory classification algorithms. Experimental results demonstrate that TraClets achieves a classification performance that is comparable to, or in most cases, better than the state-of-the-art, acting as a universal, high-accuracy approach for trajectory classification.
Mirror Descent and the Information Ratio
Sep 25, 2020
We establish a connection between the stability of mirror descent and the information ratio by Russo and Van Roy [2014]. Our analysis shows that mirror descent with suitable loss estimators and exploratory distributions enjoys the same bound on the adversarial regret as the bounds on the Bayesian regret for information-directed sampling. Along the way, we develop the theory for information-directed sampling and provide an efficient algorithm for adversarial bandits for which the regret upper bound matches exactly the best known information-theoretic upper bound.
Memory Efficient Patch-based Training for INR-based GANs
Jul 09, 2022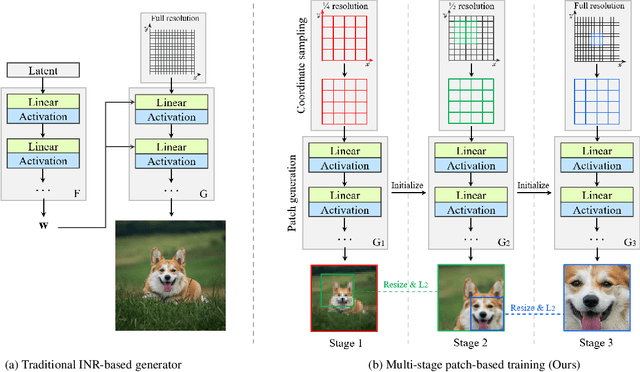
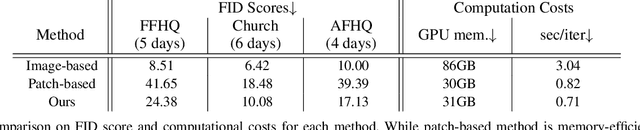


Recent studies have shown remarkable progress in GANs based on implicit neural representation (INR) - an MLP that produces an RGB value given its (x, y) coordinate. They represent an image as a continuous version of the underlying 2D signal instead of a 2D array of pixels, which opens new horizons for GAN applications (e.g., zero-shot super-resolution, image outpainting). However, training existing approaches require a heavy computational cost proportional to the image resolution, since they compute an MLP operation for every (x, y) coordinate. To alleviate this issue, we propose a multi-stage patch-based training, a novel and scalable approach that can train INR-based GANs with a flexible computational cost regardless of the image resolution. Specifically, our method allows to generate and discriminate by patch to learn the local details of the image and learn global structural information by a novel reconstruction loss to enable efficient GAN training. We conduct experiments on several benchmark datasets to demonstrate that our approach enhances baseline models in GPU memory while maintaining FIDs at a reasonable level.
An efficient Deep Spatio-Temporal Context Aware decision Network (DST-CAN) for Predictive Manoeuvre Planning
May 20, 2022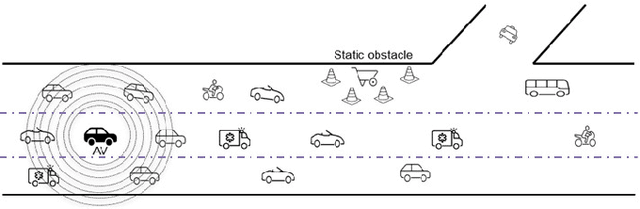
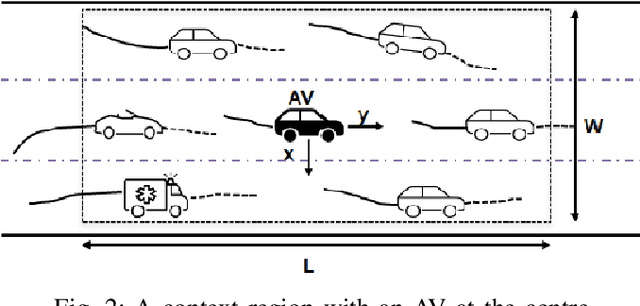
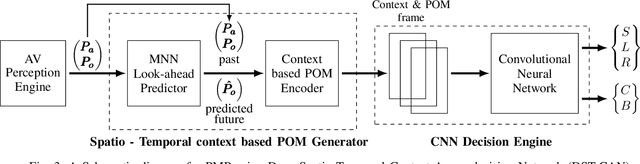
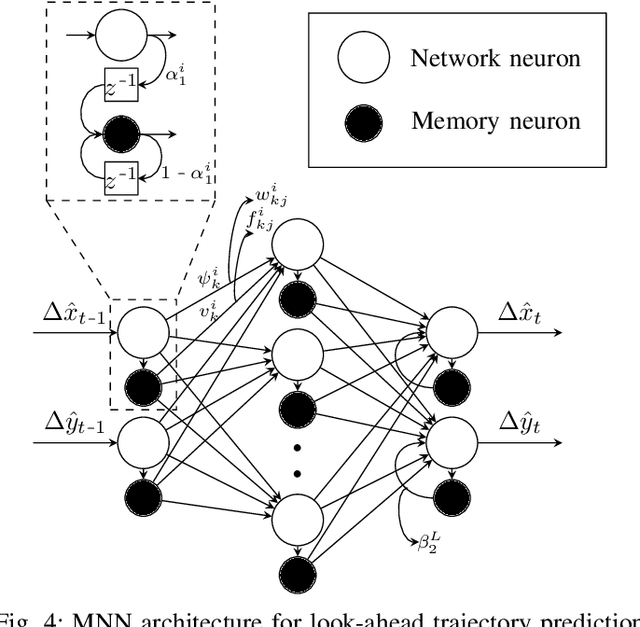
To ensure the safety and efficiency of its maneuvers, an Autonomous Vehicle (AV) should anticipate the future intentions of surrounding vehicles using its sensor information. If an AV can predict its surrounding vehicles' future trajectories, it can make safe and efficient manoeuvre decisions. In this paper, we present such a Deep Spatio-Temporal Context-Aware decision Network (DST-CAN) model for predictive manoeuvre planning of AVs. A memory neuron network is used to predict future trajectories of its surrounding vehicles. The driving environment's spatio-temporal information (past, present, and predicted future trajectories) are embedded into a context-aware grid. The proposed DST-CAN model employs these context-aware grids as inputs to a convolutional neural network to understand the spatial relationships between the vehicles and determine a safe and efficient manoeuvre decision. The DST-CAN model also uses information of human driving behavior on a highway. Performance evaluation of DST-CAN has been carried out using two publicly available NGSIM US-101 and I-80 datasets. Also, rule-based ground truth decisions have been compared with those generated by DST-CAN. The results clearly show that DST-CAN can make much better decisions with 3-sec of predicted trajectories of neighboring vehicles compared to currently existing methods that do not use this prediction.
Predicting Team Performance with Spatial Temporal Graph Convolutional Networks
Jun 21, 2022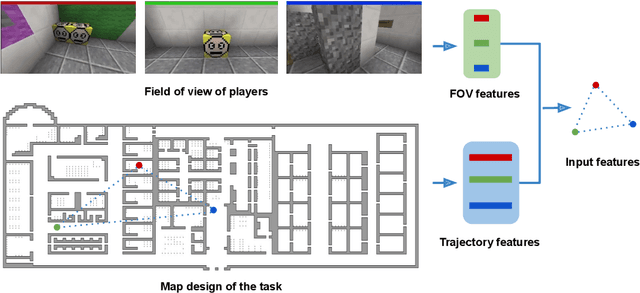
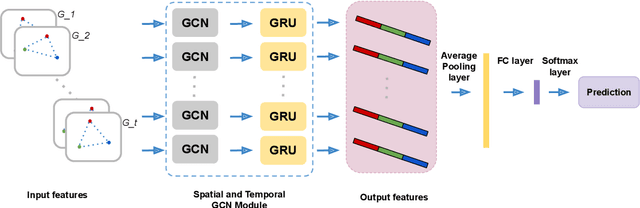
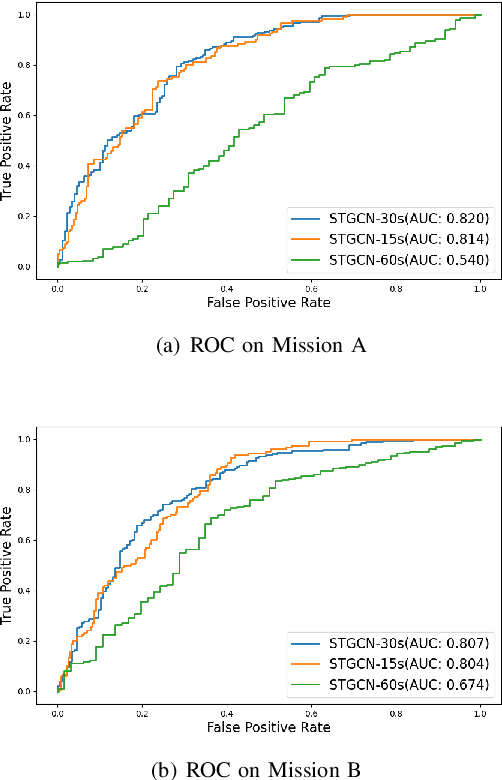
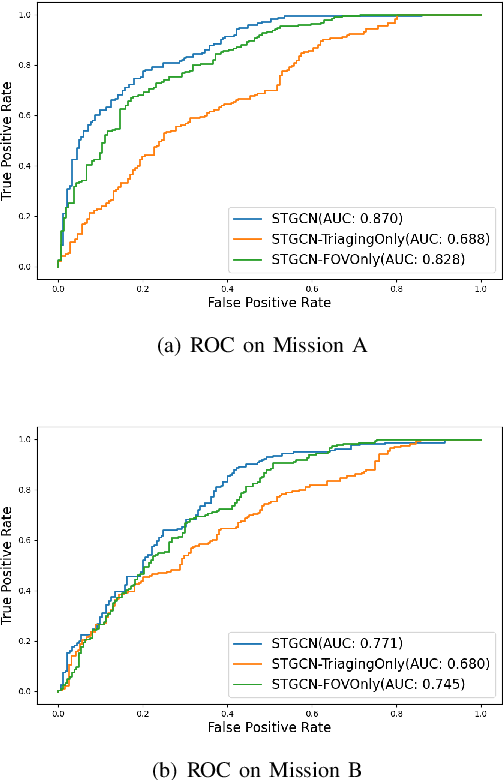
This paper presents a new approach for predicting team performance from the behavioral traces of a set of agents. This spatiotemporal forecasting problem is very relevant to sports analytics challenges such as coaching and opponent modeling. We demonstrate that our proposed model, Spatial Temporal Graph Convolutional Networks (ST-GCN), outperforms other classification techniques at predicting game score from a short segment of player movement and game features. Our proposed architecture uses a graph convolutional network to capture the spatial relationships between team members and Gated Recurrent Units to analyze dynamic motion information. An ablative evaluation was performed to demonstrate the contributions of different aspects of our architecture.
A Critical Review of Information Bottleneck Theory and its Applications to Deep Learning
May 11, 2021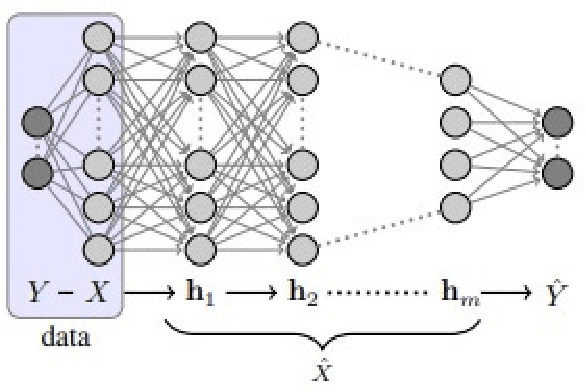
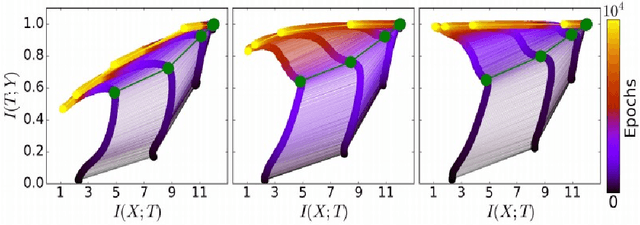
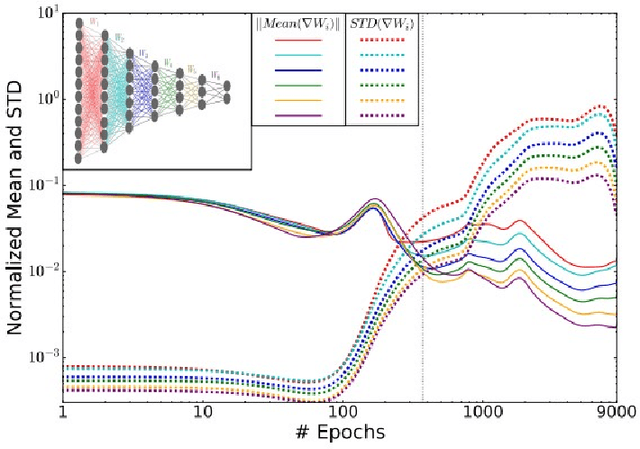
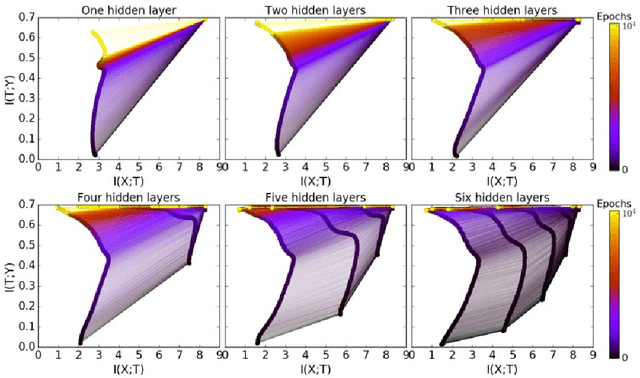
In the past decade, deep neural networks have seen unparalleled improvements that continue to impact every aspect of today's society. With the development of high performance GPUs and the availability of vast amounts of data, learning capabilities of ML systems have skyrocketed, going from classifying digits in a picture to beating world-champions in games with super-human performance. However, even as ML models continue to achieve new frontiers, their practical success has been hindered by the lack of a deep theoretical understanding of their inner workings. Fortunately, a known information-theoretic method called the information bottleneck theory has emerged as a promising approach to better understand the learning dynamics of neural networks. In principle, IB theory models learning as a trade-off between the compression of the data and the retainment of information. The goal of this survey is to provide a comprehensive review of IB theory covering it's information theoretic roots and the recently proposed applications to understand deep learning models.
Latent Augmentation For Better Graph Self-Supervised Learning
Jun 26, 2022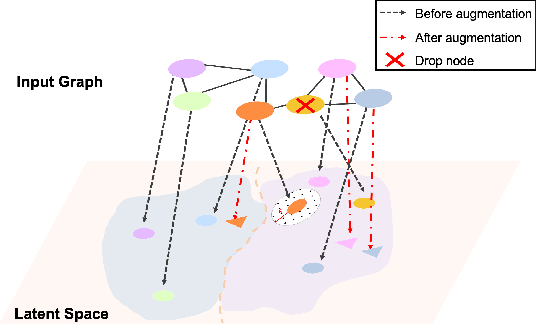
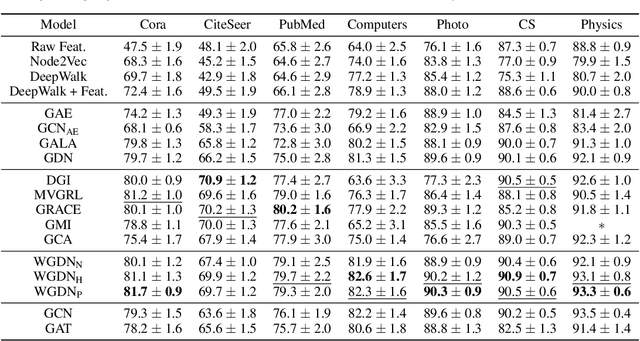
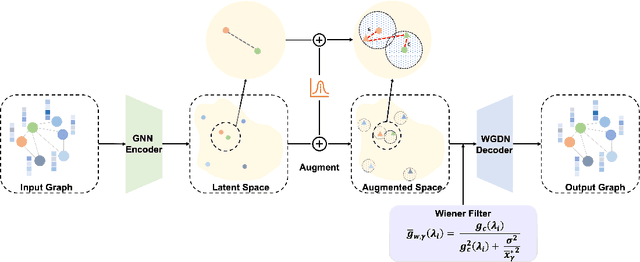
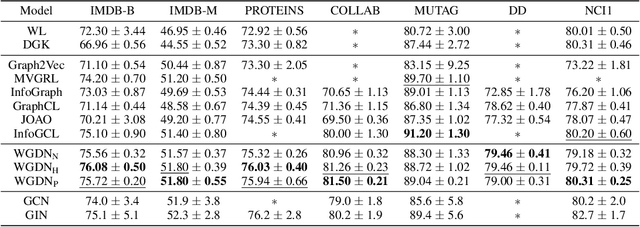
Graph self-supervised learning has been vastly employed to learn representations from unlabeled graphs. Existing methods can be roughly divided into predictive learning and contrastive learning, where the latter one attracts more research attention with better empirical performance. We argue that, however, predictive models weaponed with latent augmentations and powerful decoder could achieve comparable or even better representation power than contrastive models. In this work, we introduce data augmentations into latent space for superior generalization and better efficiency. A novel graph decoder named Wiener Graph Deconvolutional Network is correspondingly designed to perform information reconstruction from augmented latent representations. Theoretical analysis proves the superior reconstruction ability of graph wiener filter. Extensive experimental results on various datasets demonstrate the effectiveness of our approach.