 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Contextual Information Based Anomaly Detection for a Multi-Scene UAV Aerial Videos
Mar 29, 2022
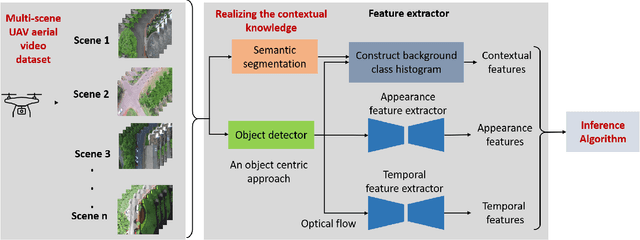

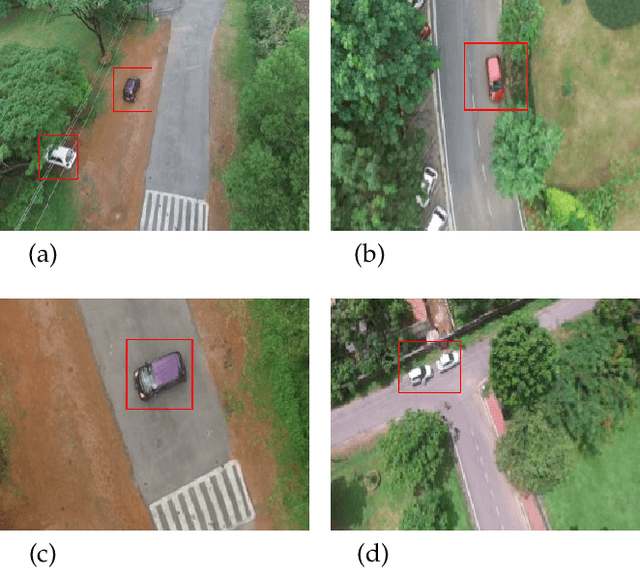
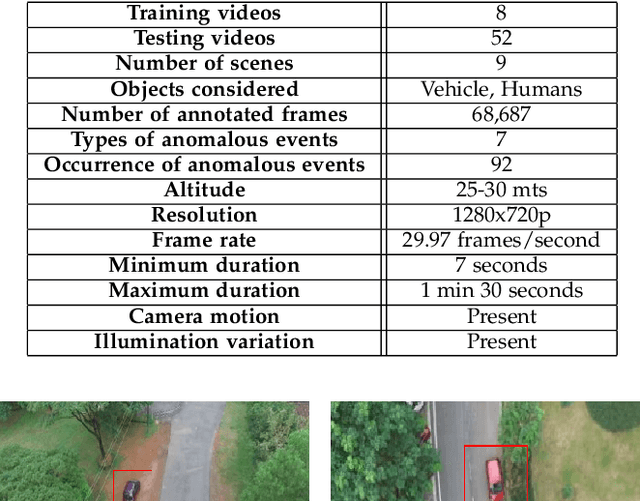
UAV based surveillance is gaining much interest worldwide due to its extensive applications in monitoring wildlife, urban planning, disaster management, campus security, etc. These videos are analyzed for strange/odd/anomalous patterns which are essential aspects of surveillance. But manual analysis of these videos is tedious and laborious. Hence, the development of computer-aided systems for the analysis of UAV based surveillance videos is crucial. Despite this interest, in literature, several computer aided systems are developed focusing only on CCTV based surveillance videos. These methods are designed for single scene scenarios and lack contextual knowledge which is required for multi-scene scenarios. Furthermore, the lack of standard UAV based anomaly detection datasets limits the development of these systems. In this regard, the present work aims at the development of a Computer Aided Decision support system to analyse UAV based surveillance videos. A new UAV based multi-scene anomaly detection dataset is developed with frame-level annotations for the development of computer aided systems. It holistically uses contextual, temporal and appearance features for accurate detection of anomalies. Furthermore, a new inference strategy is proposed that utilizes few anomalous samples along with normal samples to identify better decision boundaries. The proposed method is extensively evaluated on the UAV based anomaly detection dataset and performed competitively with respect to state-of-the-art methods.
Out-of-Distribution Detection with Semantic Mismatch under Masking
Jul 31, 2022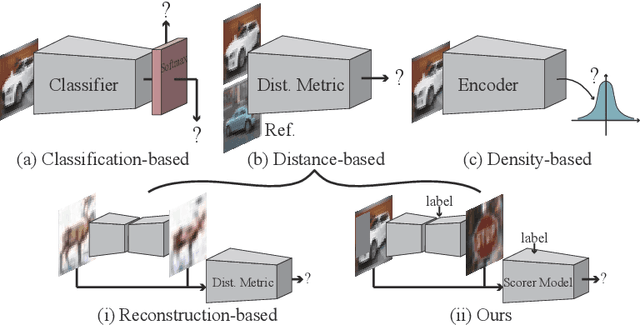
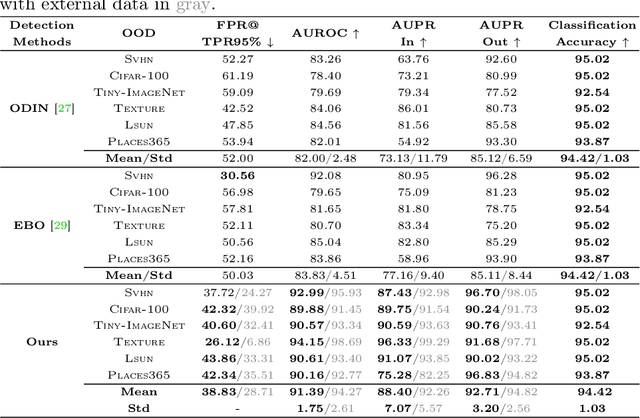
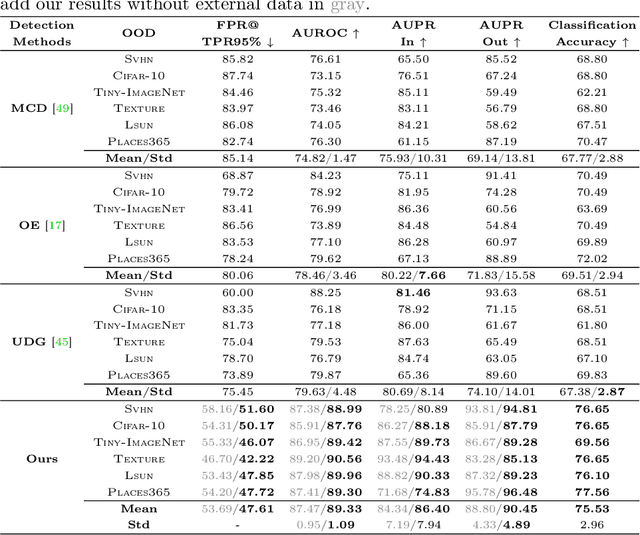
This paper proposes a novel out-of-distribution (OOD) detection framework named MoodCat for image classifiers. MoodCat masks a random portion of the input image and uses a generative model to synthesize the masked image to a new image conditioned on the classification result. It then calculates the semantic difference between the original image and the synthesized one for OOD detection. Compared to existing solutions, MoodCat naturally learns the semantic information of the in-distribution data with the proposed mask and conditional synthesis strategy, which is critical to identifying OODs. Experimental results demonstrate that MoodCat outperforms state-of-the-art OOD detection solutions by a large margin.
Temporal Link Prediction via Adjusted Sigmoid Function and 2-Simplex Sructure
Jun 20, 2022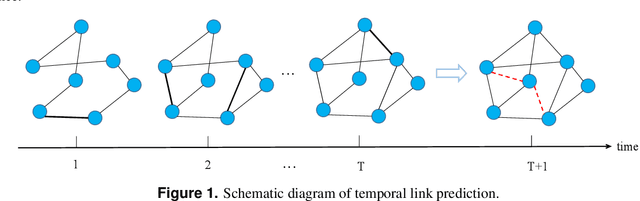
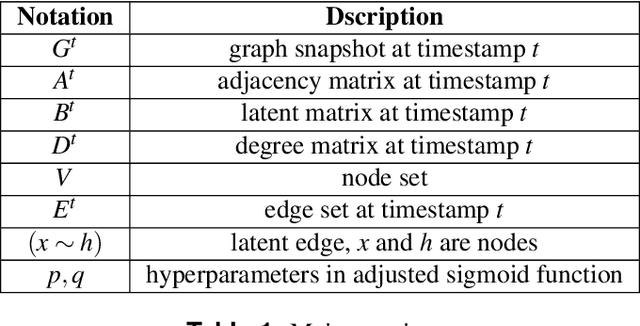
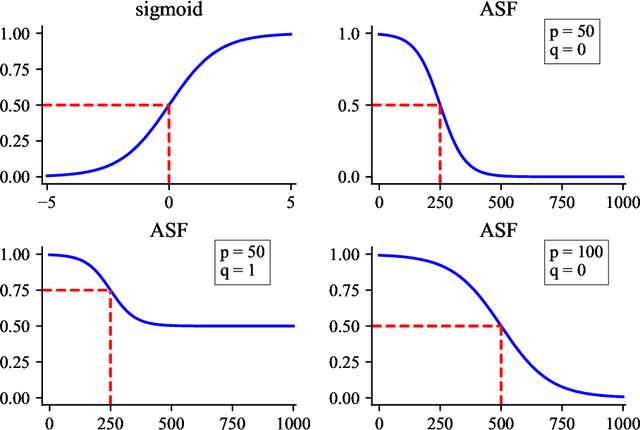

Temporal network link prediction is an important task in the field of network science, and has a wide range of applications in practical scenarios. Revealing the evolutionary mechanism of the network is essential for link prediction, and how to effectively utilize the historical information for temporal links and efficiently extract the high-order patterns of network structure remains a vital challenge. To address these issues, in this paper, we propose a novel temporal link prediction model with adjusted sigmoid function and 2-simplex structure (TLPSS). The adjusted sigmoid decay mode takes the active, decay and stable states of edges into account, which properly fits the life cycle of information. Moreover, the latent matrix sequence is introduced, which is composed of simplex high-order structure, to enhance the performance of link prediction method since it is highly feasible in sparse network. Combining the life cycle of information and simplex high-order structure, the overall performance of TLPSS is achieved by satisfying the consistency of temporal and structural information in dynamic networks. Experimental results on six real-world datasets demonstrate the effectiveness of TLPSS, and our proposed model improves the performance of link prediction by an average of 15% compared to other baseline methods.
A Temporal Extension of Latent Dirichlet Allocation for Unsupervised Acoustic Unit Discovery
Jun 29, 2022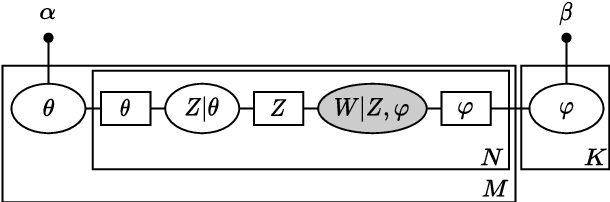
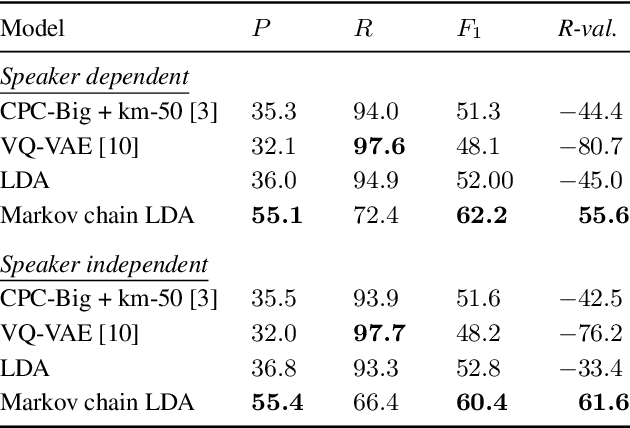
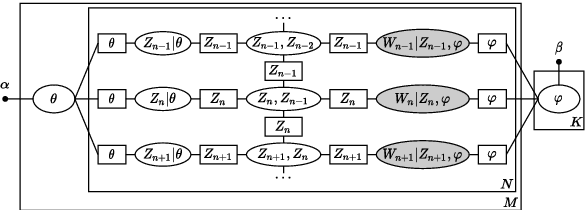
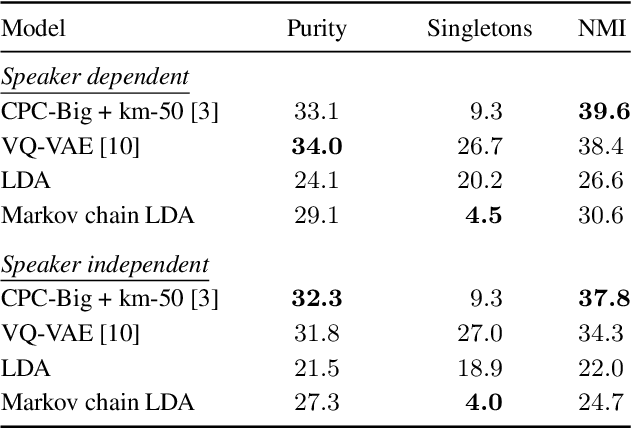
Latent Dirichlet allocation (LDA) is widely used for unsupervised topic modelling on sets of documents. No temporal information is used in the model. However, there is often a relationship between the corresponding topics of consecutive tokens. In this paper, we present an extension to LDA that uses a Markov chain to model temporal information. We use this new model for acoustic unit discovery from speech. As input tokens, the model takes a discretised encoding of speech from a vector quantised (VQ) neural network with 512 codes. The goal is then to map these 512 VQ codes to 50 phone-like units (topics) in order to more closely resemble true phones. In contrast to the base LDA, which only considers how VQ codes co-occur within utterances (documents), the Markov chain LDA additionally captures how consecutive codes follow one another. This extension leads to an increase in cluster quality and phone segmentation results compared to the base LDA. Compared to a recent vector quantised neural network approach that also learns 50 units, the extended LDA model performs better in phone segmentation but worse in mutual information.
Generating gender-ambiguous voices for privacy-preserving speech recognition
Jul 03, 2022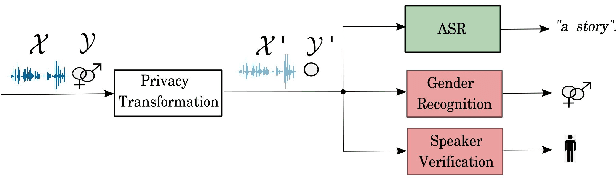
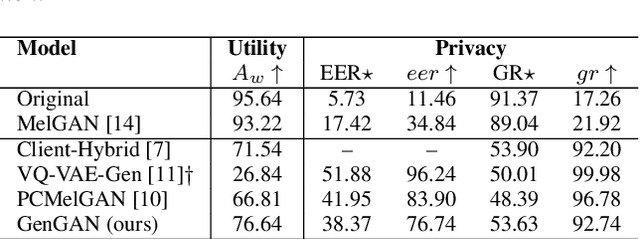
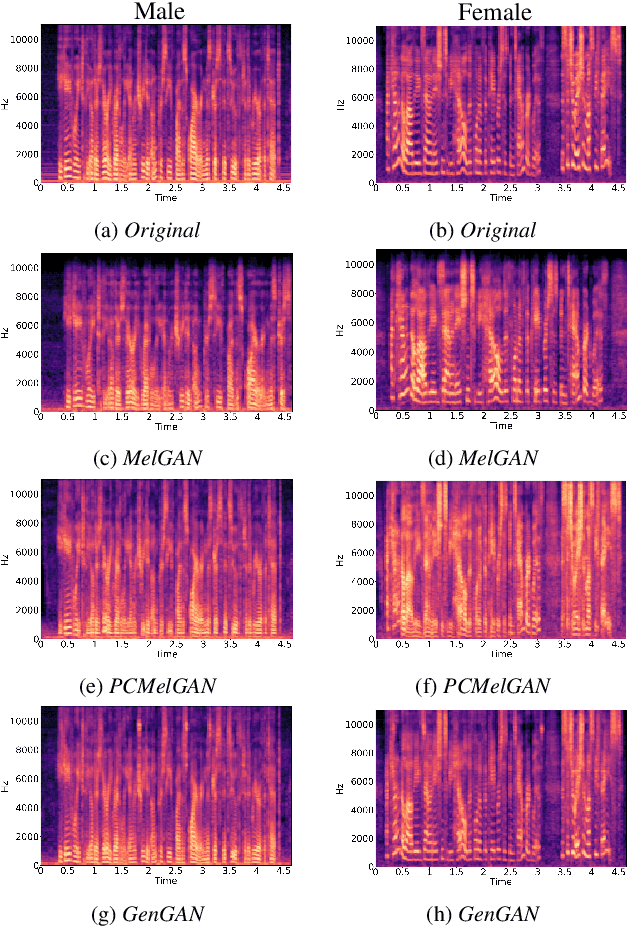
Our voice encodes a uniquely identifiable pattern which can be used to infer private attributes, such as gender or identity, that an individual might wish not to reveal when using a speech recognition service. To prevent attribute inference attacks alongside speech recognition tasks, we present a generative adversarial network, GenGAN, that synthesises voices that conceal the gender or identity of a speaker. The proposed network includes a generator with a U-Net architecture that learns to fool a discriminator. We condition the generator only on gender information and use an adversarial loss between signal distortion and privacy preservation. We show that GenGAN improves the trade-off between privacy and utility compared to privacy-preserving representation learning methods that consider gender information as a sensitive attribute to protect.
CNN-based Local Vision Transformer for COVID-19 Diagnosis
Jul 05, 2022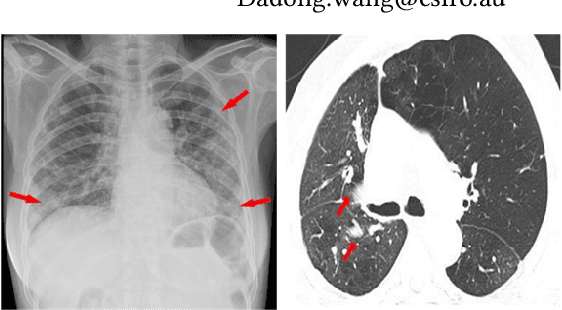

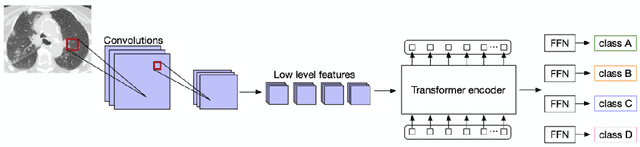

Deep learning technology can be used as an assistive technology to help doctors quickly and accurately identify COVID-19 infections. Recently, Vision Transformer (ViT) has shown great potential towards image classification due to its global receptive field. However, due to the lack of inductive biases inherent to CNNs, the ViT-based structure leads to limited feature richness and difficulty in model training. In this paper, we propose a new structure called Transformer for COVID-19 (COVT) to improve the performance of ViT-based architectures on small COVID-19 datasets. It uses CNN as a feature extractor to effectively extract local structural information, and introduces average pooling to ViT's Multilayer Perception(MLP) module for global information. Experiments show the effectiveness of our method on the two COVID-19 datasets and the ImageNet dataset.
EM-Based Estimation and Compensation of Phase Noise in Massive-MIMO Uplink Communications
Jul 17, 2022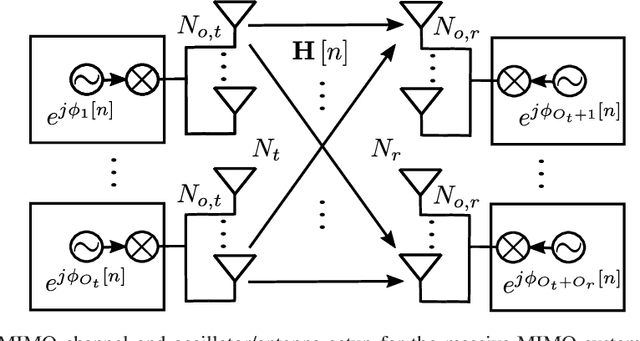
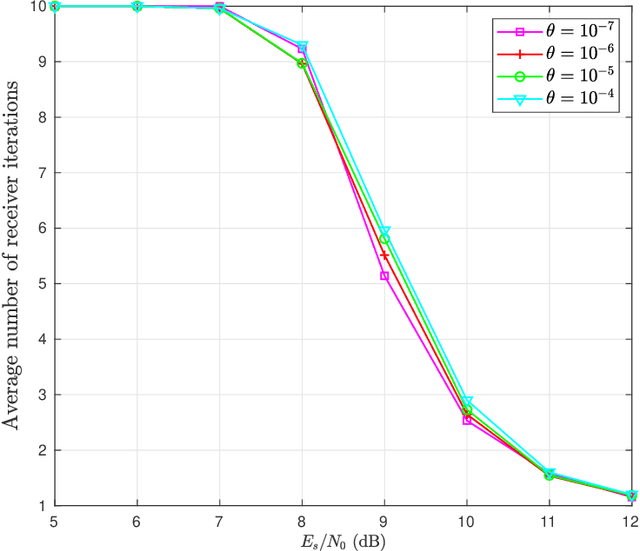
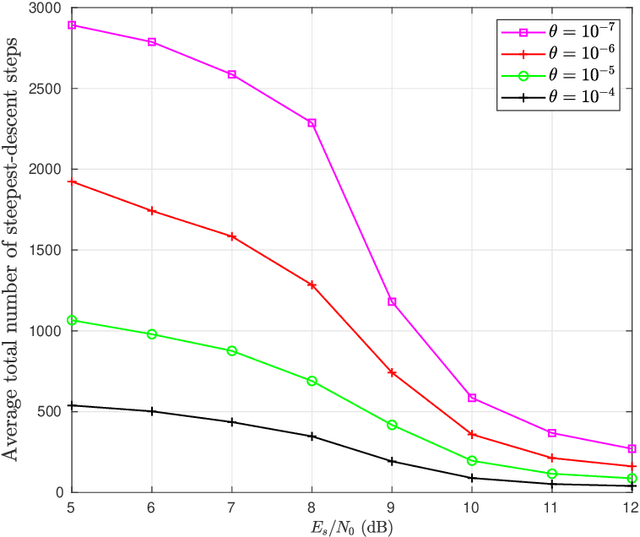

Phase noise (PN) is a major disturbance in MIMO systems, where the contribution of different oscillators at the transmitter and the receiver side may degrade the overall performance and offset the gains offered by MIMO techniques. This is even more crucial in the case of massive MIMO, since the number of PN sources may increase considerably. In this work, we propose an iterative receiver based on the application of the expectation-maximization algorithm. We consider a massive MIMO framework with a general association of oscillators to antennas, and include other channel disturbances like imperfect channel state information and Rician block fading. At each receiver iteration, given the information on the transmitted symbols, steepest descent is used to estimate the PN samples, with an optimized adaptive step size and a threshold-based stopping rule. The results obtained for several test cases show how the bit error rate and mean square error can benefit from the proposed phase-detection algorithm, even to the point of reaching the same performance as in the case where no PN is present. Further analysis of the results allow to draw some useful trade-offs respecting final performance and consumption of resources.
Group Property Inference Attacks Against Graph Neural Networks
Sep 02, 2022


With the fast adoption of machine learning (ML) techniques, sharing of ML models is becoming popular. However, ML models are vulnerable to privacy attacks that leak information about the training data. In this work, we focus on a particular type of privacy attacks named property inference attack (PIA) which infers the sensitive properties of the training data through the access to the target ML model. In particular, we consider Graph Neural Networks (GNNs) as the target model, and distribution of particular groups of nodes and links in the training graph as the target property. While the existing work has investigated PIAs that target at graph-level properties, no prior works have studied the inference of node and link properties at group level yet. In this work, we perform the first systematic study of group property inference attacks (GPIA) against GNNs. First, we consider a taxonomy of threat models under both black-box and white-box settings with various types of adversary knowledge, and design six different attacks for these settings. We evaluate the effectiveness of these attacks through extensive experiments on three representative GNN models and three real-world graphs. Our results demonstrate the effectiveness of these attacks whose accuracy outperforms the baseline approaches. Second, we analyze the underlying factors that contribute to GPIA's success, and show that the target model trained on the graphs with or without the target property represents some dissimilarity in model parameters and/or model outputs, which enables the adversary to infer the existence of the property. Further, we design a set of defense mechanisms against the GPIA attacks, and demonstrate that these mechanisms can reduce attack accuracy effectively with small loss on GNN model accuracy.
Class-Aware Visual Prompt Tuning for Vision-Language Pre-Trained Model
Aug 22, 2022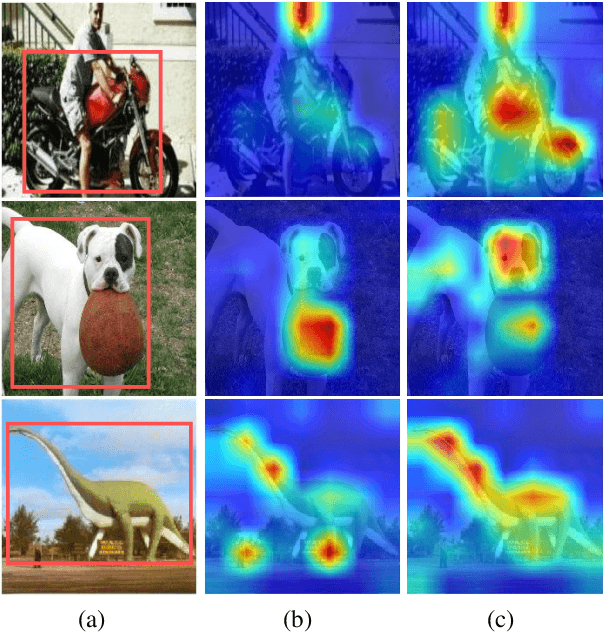
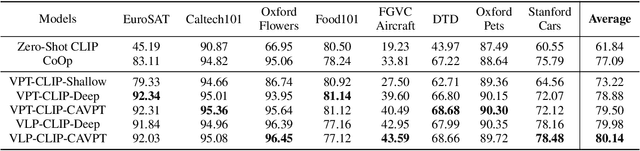
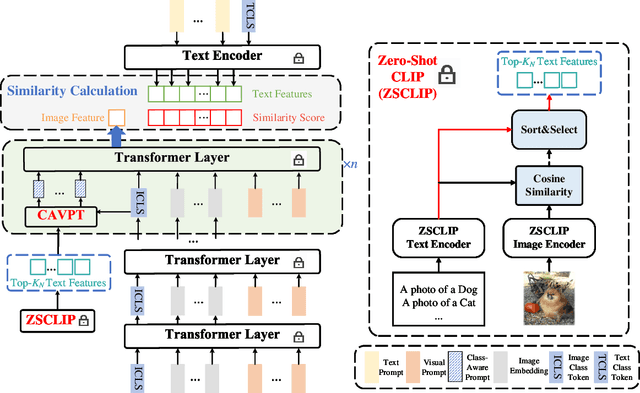

With the emergence of large pre-trained vison-language model like CLIP, transferrable representations can be adapted to a wide range of downstream tasks via prompt tuning. Prompt tuning tries to probe the beneficial information for downstream tasks from the general knowledge stored in both the image and text encoders of the pre-trained vision-language model. A recently proposed method named Context Optimization (CoOp) introduces a set of learnable vectors as text prompt from the language side, while tuning the text prompt alone can not affect the computed visual features of the image encoder, thus leading to sub-optimal. In this paper, we propose a dual modality prompt tuning paradigm through learning text prompts and visual prompts for both the text and image encoder simultaneously. In addition, to make the visual prompt concentrate more on the target visual concept, we propose Class-Aware Visual Prompt Tuning (CAVPT), which is generated dynamically by performing the cross attention between language descriptions of template prompts and visual class token embeddings. Our method provides a new paradigm for tuning the large pre-trained vision-language model and extensive experimental results on 8 datasets demonstrate the effectiveness of the proposed method. Our code is available in the supplementary materials.
A Dataset Generation Framework for profiling Disassembly attacks using Side-Channel Leakages and Deep Neural Networks
Aug 12, 2022
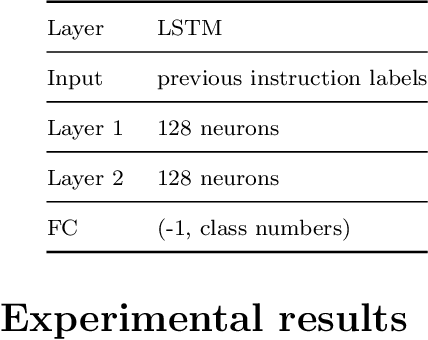
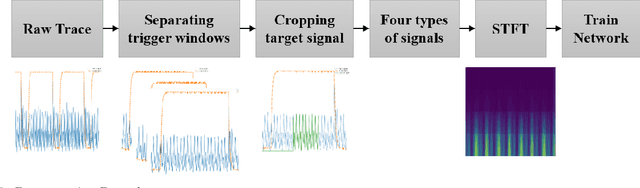
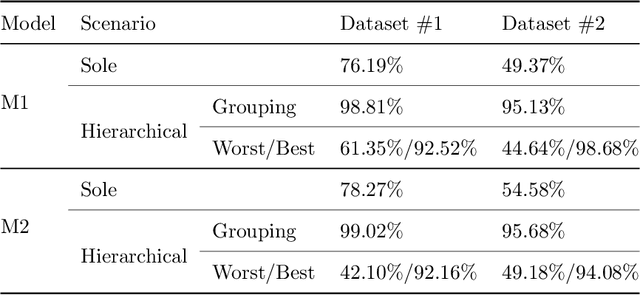
Various studies among side-channel attacks have tried to extract information through leakages from electronic devices to reach the instruction flow of some appliances. However, previous methods highly depend on the resolution of traced data. Obtaining low-noise traces is not always feasible in real attack scenarios. This study proposes two deep models to extract low and high-level features from side-channel traces and classify them to related instructions. We aim to evaluate the accuracy of a side-channel attack on low-resolution data with a more robust feature extractor thanks to neural networks. As inves-tigated, instruction flow in real programs is predictable and follows specific distributions. This leads to proposing a LSTM model to estimate these distributions, which could expedite the reverse engineering process and also raise the accuracy. The proposed model for leakage classification reaches 54.58% accuracy on average and outperforms other existing methods on our datasets. Also, LSTM model reaches 94.39% accuracy for instruction prediction on standard implementation of cryptographic algorithms.