 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Are Attribute Inference Attacks Just Imputation?
Sep 02, 2022
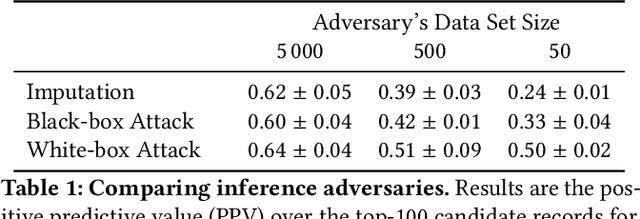
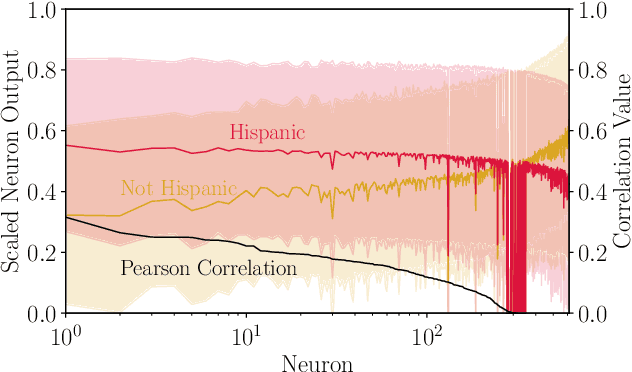
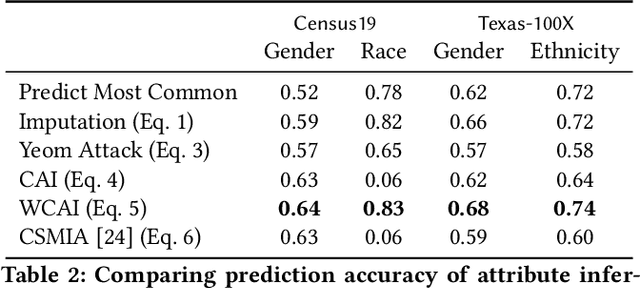
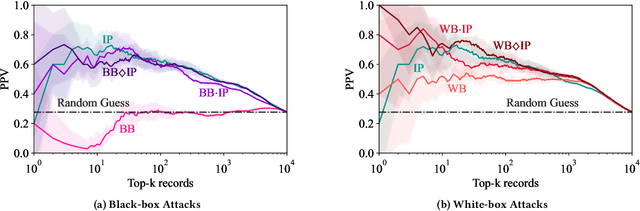
Models can expose sensitive information about their training data. In an attribute inference attack, an adversary has partial knowledge of some training records and access to a model trained on those records, and infers the unknown values of a sensitive feature of those records. We study a fine-grained variant of attribute inference we call \emph{sensitive value inference}, where the adversary's goal is to identify with high confidence some records from a candidate set where the unknown attribute has a particular sensitive value. We explicitly compare attribute inference with data imputation that captures the training distribution statistics, under various assumptions about the training data available to the adversary. Our main conclusions are: (1) previous attribute inference methods do not reveal more about the training data from the model than can be inferred by an adversary without access to the trained model, but with the same knowledge of the underlying distribution as needed to train the attribute inference attack; (2) black-box attribute inference attacks rarely learn anything that cannot be learned without the model; but (3) white-box attacks, which we introduce and evaluate in the paper, can reliably identify some records with the sensitive value attribute that would not be predicted without having access to the model. Furthermore, we show that proposed defenses such as differentially private training and removing vulnerable records from training do not mitigate this privacy risk. The code for our experiments is available at \url{https://github.com/bargavj/EvaluatingDPML}.
Interactive Visualization for Exploring Information Fragments in Software Repositories
Apr 28, 2021Software developers explore and inspect software repository data to obtain detailed information archived in the development history. However, developers who are not acquainted with the development context suffer from delving into the repositories with a handful of information; they have difficulty discovering and expanding information fragments considering the topological and sequential multi-dimensional structure of repositories. We introduce ExIF, an interactive visualization for exploring information fragments in software repositories. ExIF helps users discover new information fragments within clusters or topological neighbors and identify revisions incorporating user-collected fragments.
Curbing Task Interference using Representation Similarity-Guided Multi-Task Feature Sharing
Aug 19, 2022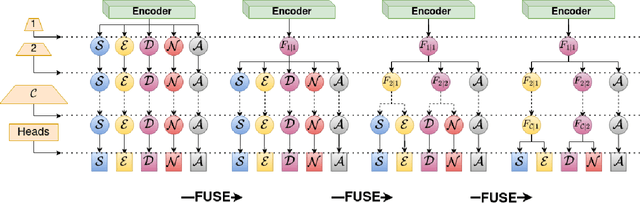

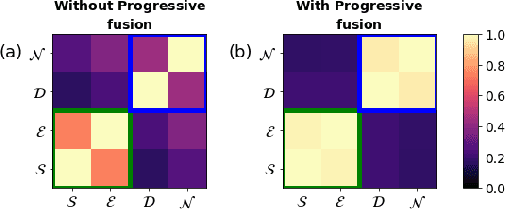
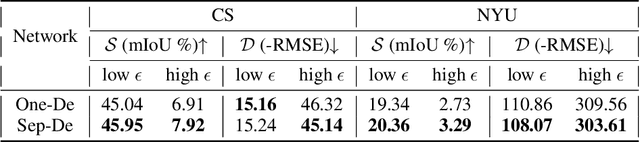
Multi-task learning of dense prediction tasks, by sharing both the encoder and decoder, as opposed to sharing only the encoder, provides an attractive front to increase both accuracy and computational efficiency. When the tasks are similar, sharing the decoder serves as an additional inductive bias providing more room for tasks to share complementary information among themselves. However, increased sharing exposes more parameters to task interference which likely hinders both generalization and robustness. Effective ways to curb this interference while exploiting the inductive bias of sharing the decoder remains an open challenge. To address this challenge, we propose Progressive Decoder Fusion (PDF) to progressively combine task decoders based on inter-task representation similarity. We show that this procedure leads to a multi-task network with better generalization to in-distribution and out-of-distribution data and improved robustness to adversarial attacks. Additionally, we observe that the predictions of different tasks of this multi-task network are more consistent with each other.
Intelligence and Unambitiousness Using Algorithmic Information Theory
May 13, 2021
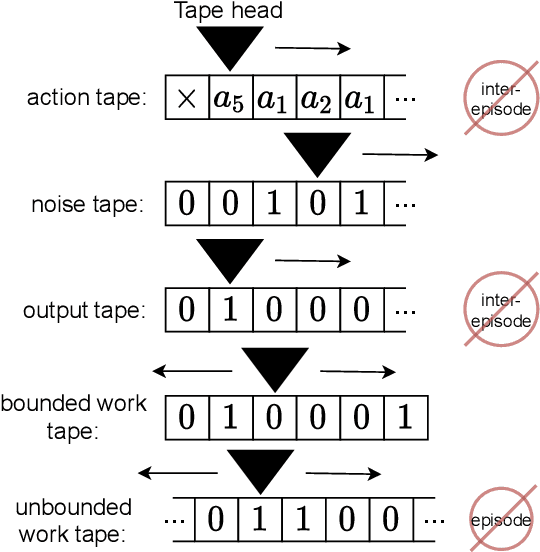
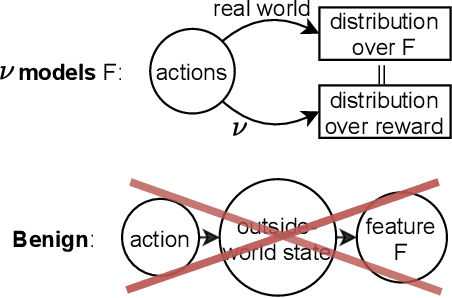
Algorithmic Information Theory has inspired intractable constructions of general intelligence (AGI), and undiscovered tractable approximations are likely feasible. Reinforcement Learning (RL), the dominant paradigm by which an agent might learn to solve arbitrary solvable problems, gives an agent a dangerous incentive: to gain arbitrary "power" in order to intervene in the provision of their own reward. We review the arguments that generally intelligent algorithmic-information-theoretic reinforcement learners such as Hutter's (2005) AIXI would seek arbitrary power, including over us. Then, using an information-theoretic exploration schedule, and a setup inspired by causal influence theory, we present a variant of AIXI which learns to not seek arbitrary power; we call it "unambitious". We show that our agent learns to accrue reward at least as well as a human mentor, while relying on that mentor with diminishing probability. And given a formal assumption that we probe empirically, we show that eventually, the agent's world-model incorporates the following true fact: intervening in the "outside world" will have no effect on reward acquisition; hence, it has no incentive to shape the outside world.
* 13 pages, 6 figures, 5-page appendix. arXiv admin note: text overlap with arXiv:1905.12186
Identification of feasible pathway information for c-di-GMP binding proteins in cellulose production
Apr 26, 2022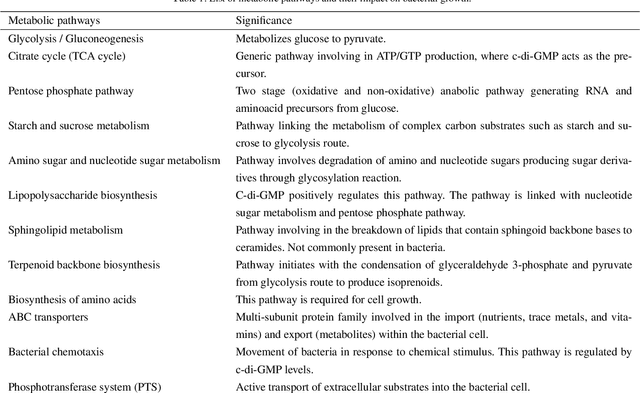
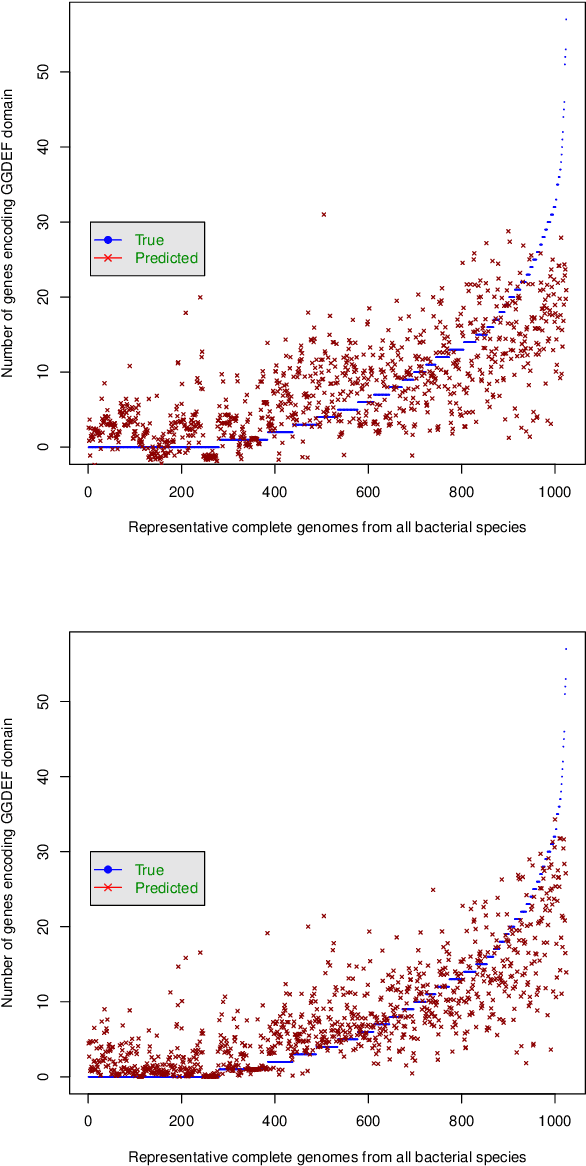
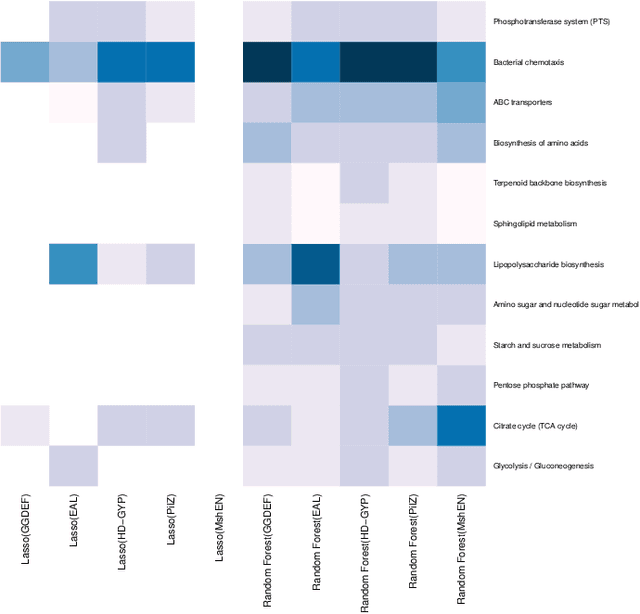
In this paper, we utilize a machine learning approach to identify the significant pathways for c-di-GMP signaling proteins. The dataset involves gene counts from 12 pathways and 5 essential c-di-GMP binding domains for 1024 bacterial genomes. Two novel approaches, Least absolute shrinkage and selection operator (Lasso) and Random forests, have been applied for analyzing and modeling the dataset. Both approaches show that bacterial chemotaxis is the most essential pathway for c-di-GMP encoding domains. Though popular for feature selection, the strong regularization of Lasso method fails to associate any pathway to MshE domain. Results from the analysis may help to understand and emphasize the supporting pathways involved in bacterial cellulose production. These findings demonstrate the need for a chassis to restrict the behavior or functionality by deactivating the selective pathways in cellulose production.
Modularity Optimization as a Training Criterion for Graph Neural Networks
Jun 30, 2022Graph convolution is a recent scalable method for performing deep feature learning on attributed graphs by aggregating local node information over multiple layers. Such layers only consider attribute information of node neighbors in the forward model and do not incorporate knowledge of global network structure in the learning task. In particular, the modularity function provides a convenient source of information about the community structure of networks. In this work we investigate the effect on the quality of learned representations by the incorporation of community structure preservation objectives of networks in the graph convolutional model. We incorporate the objectives in two ways, through an explicit regularization term in the cost function in the output layer and as an additional loss term computed via an auxiliary layer. We report the effect of community structure preserving terms in the graph convolutional architectures. Experimental evaluation on two attributed bibilographic networks showed that the incorporation of the community-preserving objective improves semi-supervised node classification accuracy in the sparse label regime.
* CompleNet 2018
Discovering the Information that is lost in our Databases -- Why bother storing data if you can't find the information?
May 18, 2021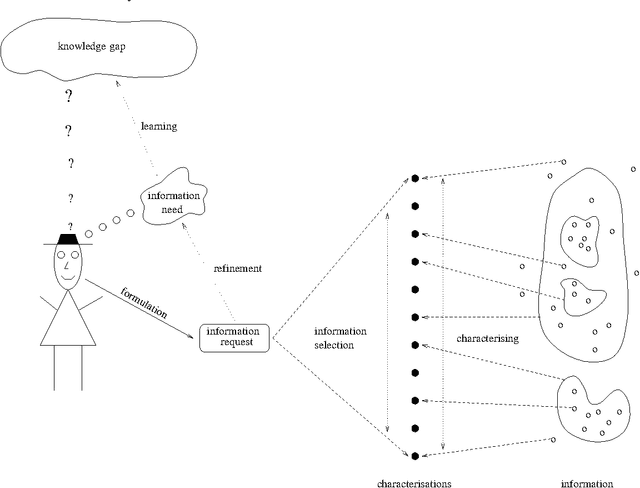
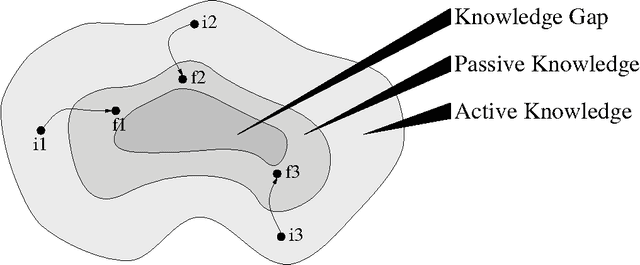
We are surrounded by an ever increasing amount of data that is stored in a variety of databases. In this article we will use a very liberal definition of \EM{database}. Basically any collection of data can be regarded as a database, ranging from the files in a directory on a disk, to ftp and web servers, through to relational or object-oriented databases. The sole reason for storing data in databases is that there is an anticipated need for the stored data at some time in the future. This means that providing smooth access paths by which stored information can be retrieved is at least as important as ensuring integrity of the stored information. In practice, however, providing users with adequate avenues by which to access stored information has received far less attention.
Uncertainty quantification for predictions of atomistic neural networks
Jul 14, 2022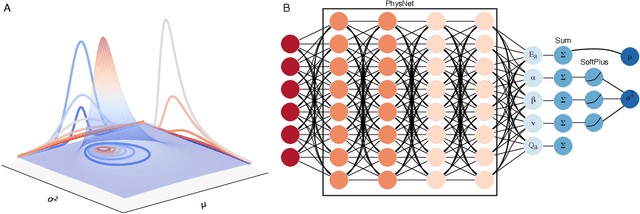
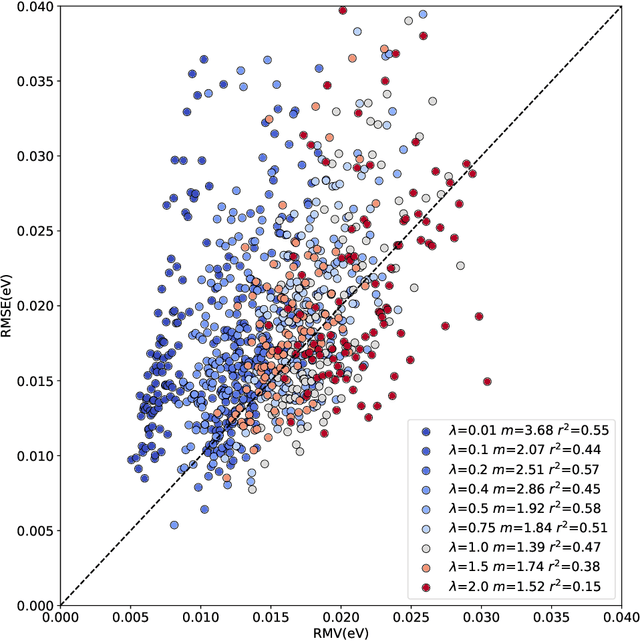
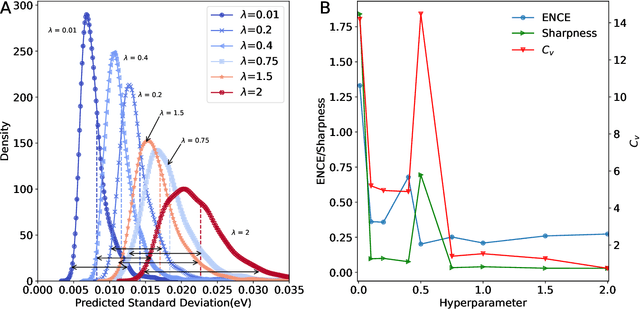
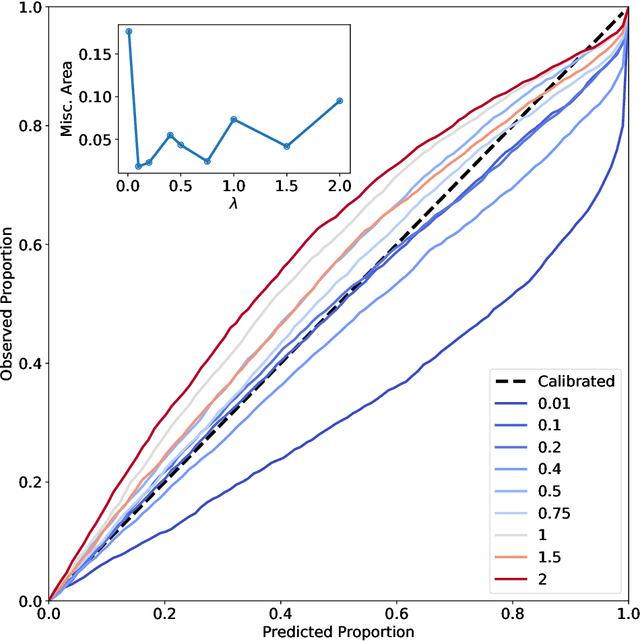
The value of uncertainty quantification on predictions for trained neural networks (NNs) on quantum chemical reference data is quantitatively explored. For this, the architecture of the PhysNet NN was suitably modified and the resulting model was evaluated with different metrics to quantify calibration, quality of predictions, and whether prediction error and the predicted uncertainty can be correlated. The results from training on the QM9 database and evaluating data from the test set within and outside the distribution indicate that error and uncertainty are not linearly related. The results clarify that noise and redundancy complicate property prediction for molecules even in cases for which changes - e.g. double bond migration in two otherwise identical molecules - are small. The model was then applied to a real database of tautomerization reactions. Analysis of the distance between members in feature space combined with other parameters shows that redundant information in the training dataset can lead to large variances and small errors whereas the presence of similar but unspecific information returns large errors but small variances. This was, e.g., observed for nitro-containing aliphatic chains for which predictions were difficult although the training set contained several examples for nitro groups bound to aromatic molecules. This underlines the importance of the composition of the training data and provides chemical insight into how this affects the prediction capabilities of a ML model. Finally, the approach put forward can be used for information-based improvement of chemical databases for target applications through active learning optimization.
Igeood: An Information Geometry Approach to Out-of-Distribution Detection
Mar 15, 2022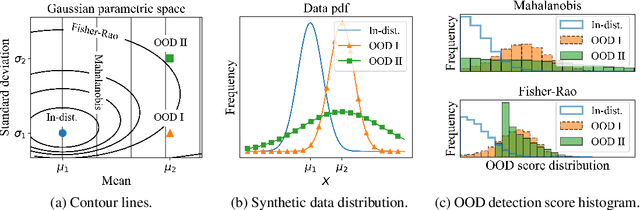

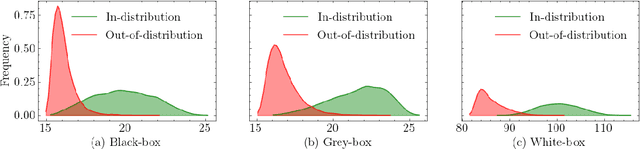
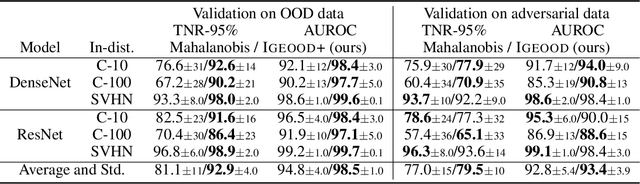
Reliable out-of-distribution (OOD) detection is fundamental to implementing safer modern machine learning (ML) systems. In this paper, we introduce Igeood, an effective method for detecting OOD samples. Igeood applies to any pre-trained neural network, works under various degrees of access to the ML model, does not require OOD samples or assumptions on the OOD data but can also benefit (if available) from OOD samples. By building on the geodesic (Fisher-Rao) distance between the underlying data distributions, our discriminator can combine confidence scores from the logits outputs and the learned features of a deep neural network. Empirically, we show that Igeood outperforms competing state-of-the-art methods on a variety of network architectures and datasets.
Sustaining Fairness via Incremental Learning
Aug 25, 2022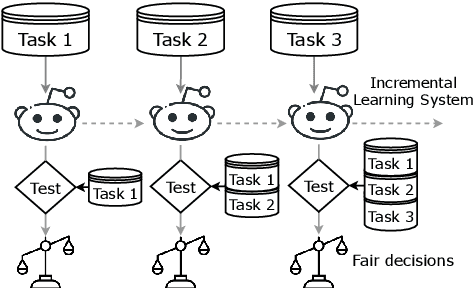
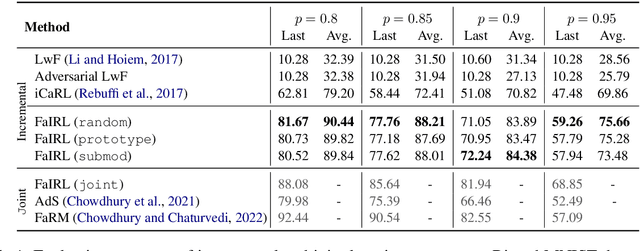
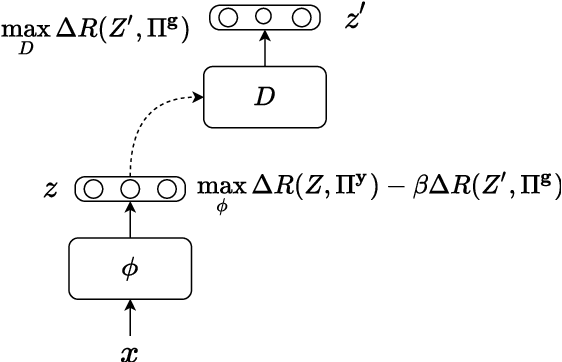
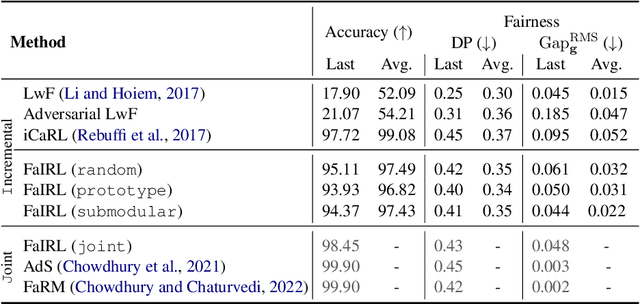
Machine learning systems are often deployed for making critical decisions like credit lending, hiring, etc. While making decisions, such systems often encode the user's demographic information (like gender, age) in their intermediate representations. This can lead to decisions that are biased towards specific demographics. Prior work has focused on debiasing intermediate representations to ensure fair decisions. However, these approaches fail to remain fair with changes in the task or demographic distribution. To ensure fairness in the wild, it is important for a system to adapt to such changes as it accesses new data in an incremental fashion. In this work, we propose to address this issue by introducing the problem of learning fair representations in an incremental learning setting. To this end, we present Fairness-aware Incremental Representation Learning (FaIRL), a representation learning system that can sustain fairness while incrementally learning new tasks. FaIRL is able to achieve fairness and learn new tasks by controlling the rate-distortion function of the learned representations. Our empirical evaluations show that FaIRL is able to make fair decisions while achieving high performance on the target task, outperforming several baselines.