 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task Structural Learning using Local Task Similarity induced Neuron Creation and Removal
Apr 30, 2023Multi-task learning has the potential to improve generalization by maximizing positive transfer between tasks while reducing task interference. Fully achieving this potential is hindered by manually designed architectures that remain static throughout training. On the contrary, learning in the brain occurs through structural changes that are in tandem with changes in synaptic strength. Thus, we propose \textit{Multi-Task Structural Learning (MTSL)} that simultaneously learns the multi-task architecture and its parameters. MTSL begins with an identical single-task network for each task and alternates between a task-learning phase and a structural-learning phase. In the task learning phase, each network specializes in the corresponding task. In each of the structural learning phases, starting from the earliest layer, locally similar task layers first transfer their knowledge to a newly created group layer before being removed. MTSL then uses the group layer in place of the corresponding removed task layers and moves on to the next layers. Our empirical results show that MTSL achieves competitive generalization with various baselines and improves robustness to out-of-distribution data.
Curbing Task Interference using Representation Similarity-Guided Multi-Task Feature Sharing
Aug 19, 2022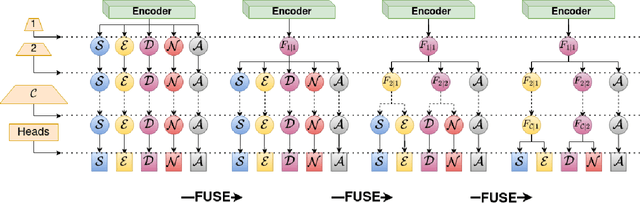

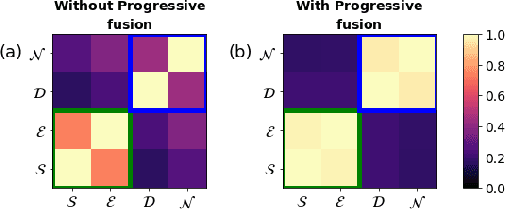
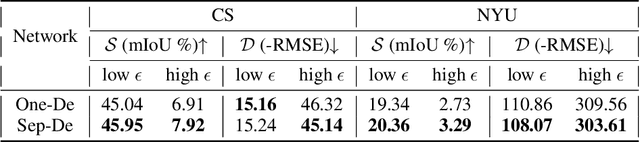
Multi-task learning of dense prediction tasks, by sharing both the encoder and decoder, as opposed to sharing only the encoder, provides an attractive front to increase both accuracy and computational efficiency. When the tasks are similar, sharing the decoder serves as an additional inductive bias providing more room for tasks to share complementary information among themselves. However, increased sharing exposes more parameters to task interference which likely hinders both generalization and robustness. Effective ways to curb this interference while exploiting the inductive bias of sharing the decoder remains an open challenge. To address this challenge, we propose Progressive Decoder Fusion (PDF) to progressively combine task decoders based on inter-task representation similarity. We show that this procedure leads to a multi-task network with better generalization to in-distribution and out-of-distribution data and improved robustness to adversarial attacks. Additionally, we observe that the predictions of different tasks of this multi-task network are more consistent with each other.