 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Event-related data conditioning for acoustic event classification
Jun 16, 2022
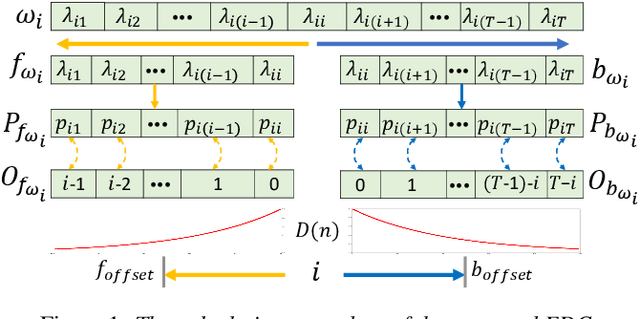
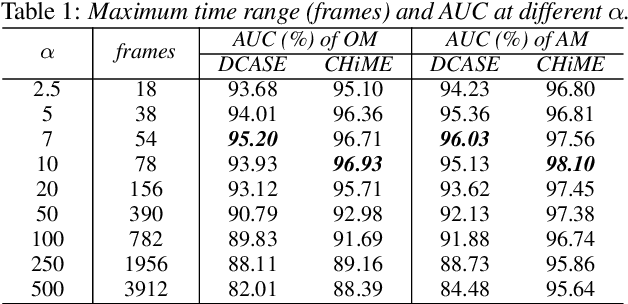
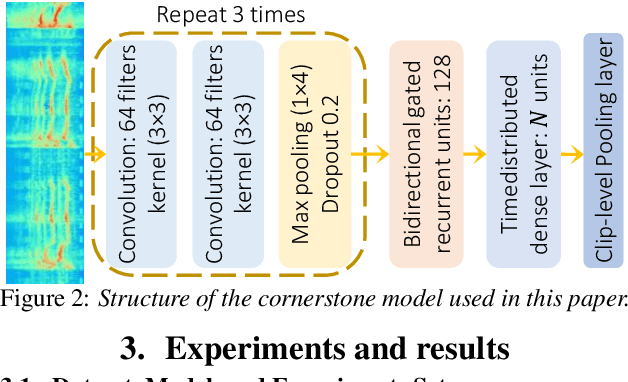
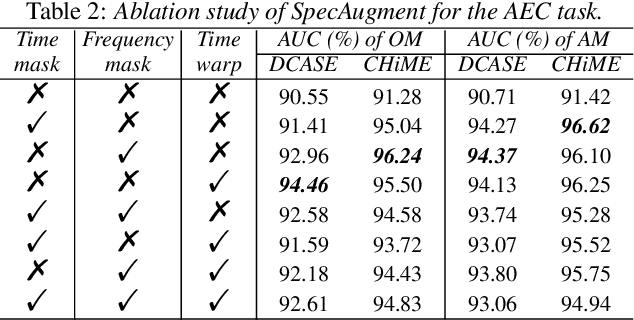
Models based on diverse attention mechanisms have recently shined in tasks related to acoustic event classification (AEC). Among them, self-attention is often used in audio-only tasks to help the model recognize different acoustic events. Self-attention relies on the similarity between time frames, and uses global information from the whole segment to highlight specific features within a frame. In real life, information related to acoustic events will attenuate over time, which means the information within some frames around the event deserves more attention than distant time global information that may be unrelated to the event. This paper shows that self-attention may over-enhance certain segments of audio representations, and smooth out the boundaries between events representations and background noises. Hence, this paper proposes an event-related data conditioning (EDC) for AEC. EDC directly works on spectrograms. The idea of EDC is to adaptively select the frame-related attention range based on acoustic features, and gather the event-related local information to represent the frame. Experiments show that: 1) compared with spectrogram-based data augmentation methods and trainable feature weighting and self-attention, EDC outperforms them in both the original-size mode and the augmented mode; 2) EDC effectively gathers event-related local information and enhances boundaries between events and backgrounds, improving the performance of AEC.
Preprocessing Source Code Comments for Linguistic Models
Aug 23, 2022
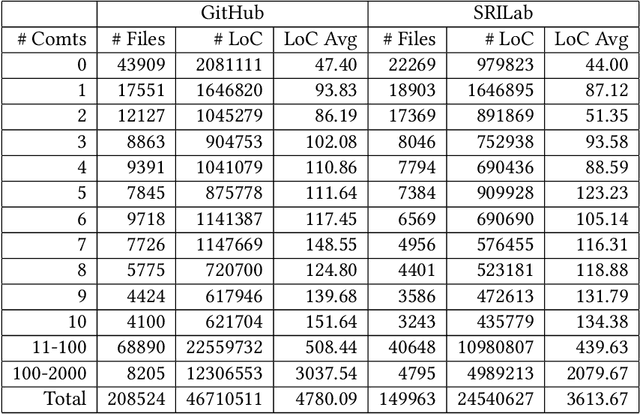
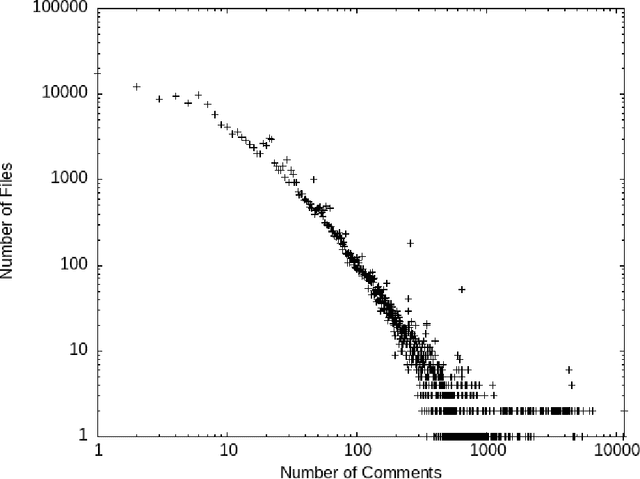
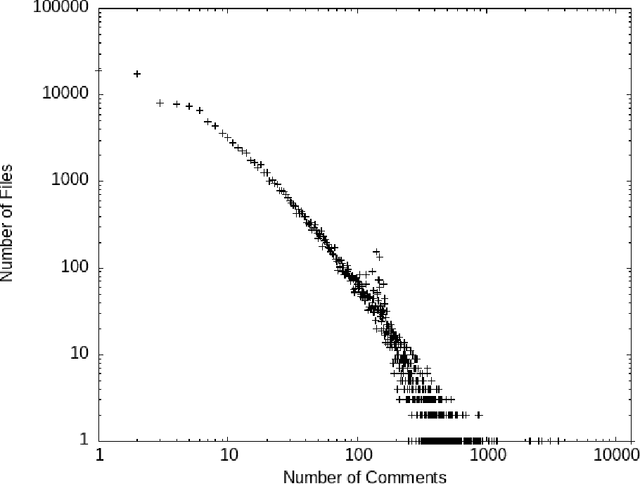
Comments are an important part of the source code and are a primary source of documentation. This has driven interest in using large bodies of comments to train or evaluate tools that consume or produce them -- such as generating oracles or even code from comments, or automatically generating code summaries. Most of this work makes strong assumptions about the structure and quality of comments, such as assuming they consist mostly of proper English sentences. However, we know little about the actual quality of existing comments for these use cases. Comments often contain unique structures and elements that are not seen in other types of text, and filtering or extracting information from them requires some extra care. This paper explores the contents and quality of Python comments drawn from 840 most popular open source projects from GitHub and 8422 projects from SriLab dataset, and the impact of na\"ive vs. in-depth filtering can have on the use of existing comments for training and evaluation of systems that generate comments.
Transformer-CNN Cohort: Semi-supervised Semantic Segmentation by the Best of Both Students
Sep 06, 2022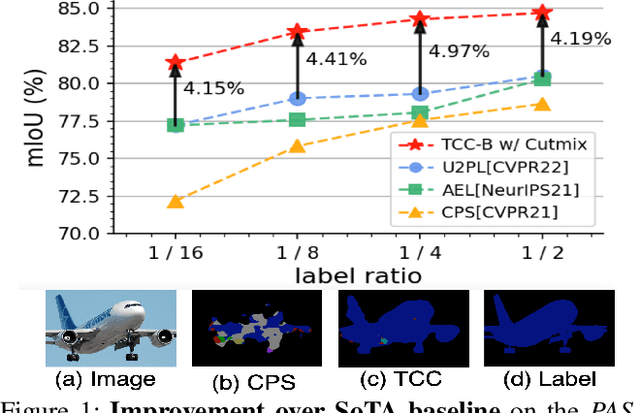
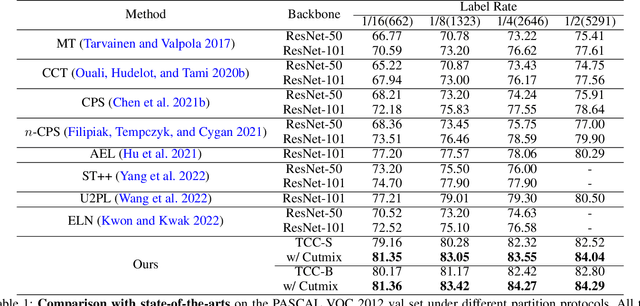
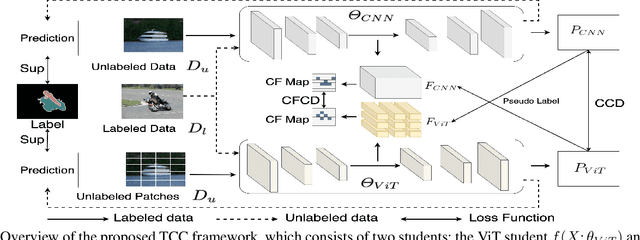
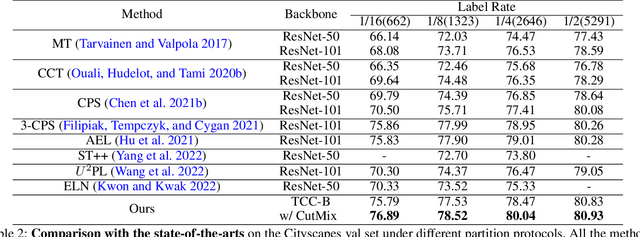
The popular methods for semi-supervised semantic segmentation mostly adopt a unitary network model using convolutional neural networks (CNNs) and enforce consistency of the model predictions over small perturbations applied to the inputs or model. However, such a learning paradigm suffers from a) limited learning capability of the CNN-based model; b) limited capacity of learning the discriminative features for the unlabeled data; c) limited learning for both global and local information from the whole image. In this paper, we propose a novel Semi-supervised Learning approach, called Transformer-CNN Cohort (TCC), that consists of two students with one based on the vision transformer (ViT) and the other based on the CNN. Our method subtly incorporates the multi-level consistency regularization on the predictions and the heterogeneous feature spaces via pseudo labeling for the unlabeled data. First, as the inputs of the ViT student are image patches, the feature maps extracted encode crucial class-wise statistics. To this end, we propose class-aware feature consistency distillation (CFCD) that first leverages the outputs of each student as the pseudo labels and generates class-aware feature (CF) maps. It then transfers knowledge via the CF maps between the students. Second, as the ViT student has more uniform representations for all layers, we propose consistency-aware cross distillation to transfer knowledge between the pixel-wise predictions from the cohort. We validate the TCC framework on Cityscapes and Pascal VOC 2012 datasets, which significantly outperforms existing semi-supervised methods by a large margin.
Vapor Cloud Delayed-DPPM Modulation Technique for nonlinear Optoacoustic Communication
Aug 29, 2022



The optoacoustic process can solve the longstanding challenge of wireless information transmission from an airborne unit to an underwater node (UWN). The nonlinear optoacoustic signal generated by proper laser parameters can propagate long distances in water. However, forming such a signal requires a high-power laser, and the buildup of a vapor cloud precludes the subsequent acoustic signal generation. Therefore, pursuing the traditional on-off keying (OOK) modulation technique will limit the data rate and power efficiency. In this paper, we analyze different modulation techniques and propose a vapor cloud delayed-differential pulse position modulation (VCD-DPPM) technique to improve the data rate and achieve high power efficiency for a single stationary laser transmitter. The symbol rate of VCD-DPPM is approximately 6.9 times and 1.69 times higher than OOK in our text communication simulation using a laser repetition rate of 10 kHz and 40 Hz, respectively. Furthermore, VCD-DPPM is 137% more power efficient than the OOK technique for both cases. We have generated different acoustic signal levels in laboratory conditions and simulated the bit error rate (BER) for different depths and positions of the UWN, while considering ambient underwater noises. Our results indicate that VCD-DPPM enables efficient data transmission.
Universality and diversity in word patterns
Aug 23, 2022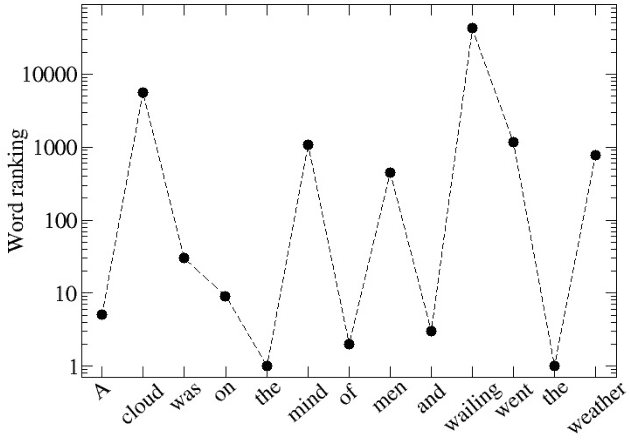
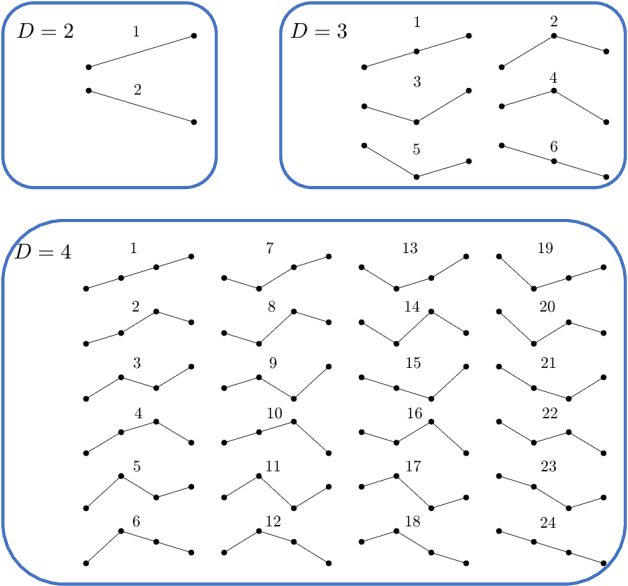
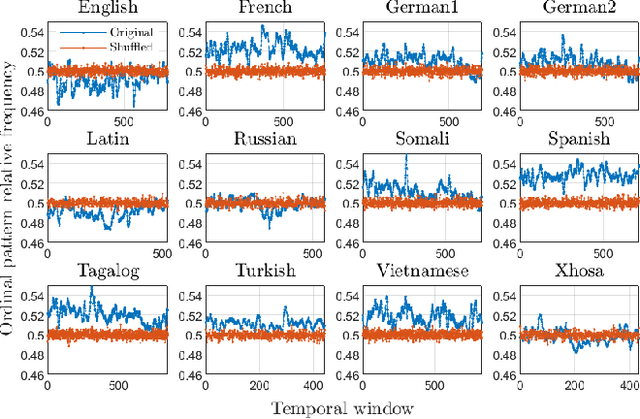
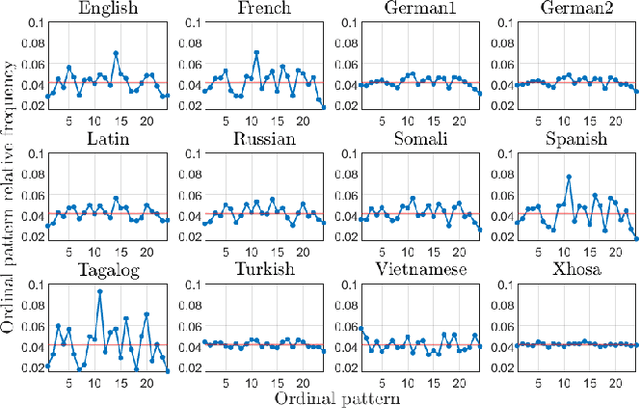
Words are fundamental linguistic units that connect thoughts and things through meaning. However, words do not appear independently in a text sequence. The existence of syntactic rules induce correlations among neighboring words. Further, words are not evenly distributed but approximately follow a power law since terms with a pure semantic content appear much less often than terms that specify grammar relations. Using an ordinal pattern approach, we present an analysis of lexical statistical connections for eleven major languages. We find that the diverse manners that languages utilize to express word relations give rise to unique pattern distributions. Remarkably, we find that these relations can be modeled with a Markov model of order 2 and that this result is universally valid for all the studied languages. Furthermore, fluctuations of the pattern distributions can allow us to determine the historical period when the text was written and its author. Taken together, these results emphasize the relevance of time series analysis and information-theoretic methods for the understanding of statistical correlations in natural languages.
XCon: Learning with Experts for Fine-grained Category Discovery
Aug 03, 2022

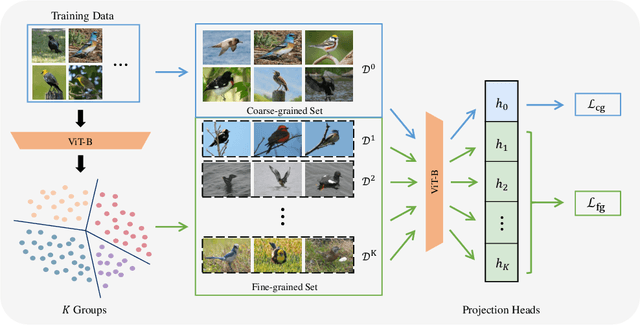
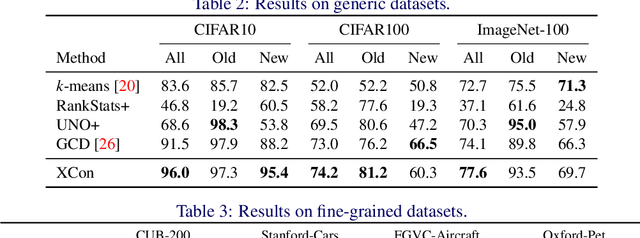
We address the problem of generalized category discovery (GCD) in this paper, i.e. clustering the unlabeled images leveraging the information from a set of seen classes, where the unlabeled images could contain both seen classes and unseen classes. The seen classes can be seen as an implicit criterion of classes, which makes this setting different from unsupervised clustering where the cluster criteria may be ambiguous. We mainly concern the problem of discovering categories within a fine-grained dataset since it is one of the most direct applications of category discovery, i.e. helping experts discover novel concepts within an unlabeled dataset using the implicit criterion set forth by the seen classes. State-of-the-art methods for generalized category discovery leverage contrastive learning to learn the representations, but the large inter-class similarity and intra-class variance pose a challenge for the methods because the negative examples may contain irrelevant cues for recognizing a category so the algorithms may converge to a local-minima. We present a novel method called Expert-Contrastive Learning (XCon) to help the model to mine useful information from the images by first partitioning the dataset into sub-datasets using k-means clustering and then performing contrastive learning on each of the sub-datasets to learn fine-grained discriminative features. Experiments on fine-grained datasets show a clear improved performance over the previous best methods, indicating the effectiveness of our method.
Multi-view hierarchical Variational AutoEncoders with Factor Analysis latent space
Jul 19, 2022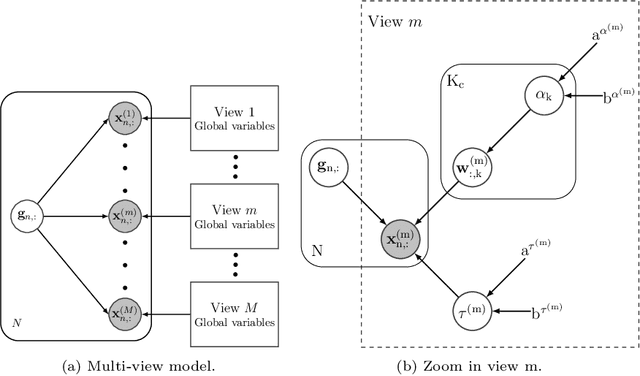


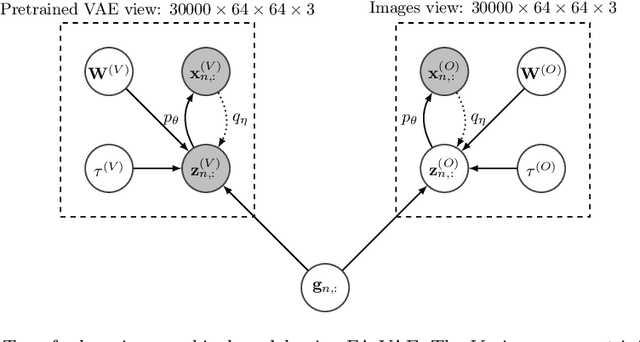
Real-world databases are complex, they usually present redundancy and shared correlations between heterogeneous and multiple representations of the same data. Thus, exploiting and disentangling shared information between views is critical. For this purpose, recent studies often fuse all views into a shared nonlinear complex latent space but they lose the interpretability. To overcome this limitation, here we propose a novel method to combine multiple Variational AutoEncoders (VAE) architectures with a Factor Analysis latent space (FA-VAE). Concretely, we use a VAE to learn a private representation of each heterogeneous view in a continuous latent space. Then, we model the shared latent space by projecting every private variable to a low-dimensional latent space using a linear projection matrix. Thus, we create an interpretable hierarchical dependency between private and shared information. This way, the novel model is able to simultaneously: (i) learn from multiple heterogeneous views, (ii) obtain an interpretable hierarchical shared space, and, (iii) perform transfer learning between generative models.
An Analysis of Human-Robot Information Streams to Inform Dynamic Autonomy Allocation
Aug 03, 2021
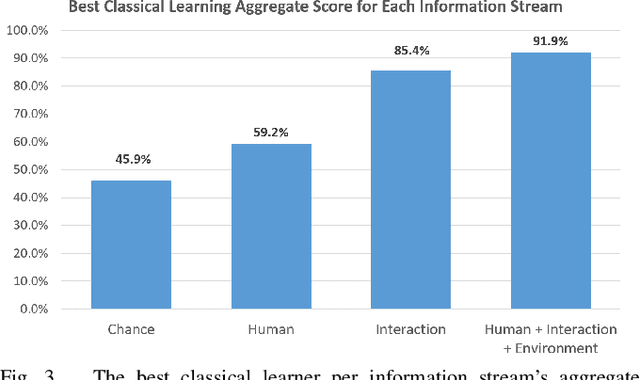
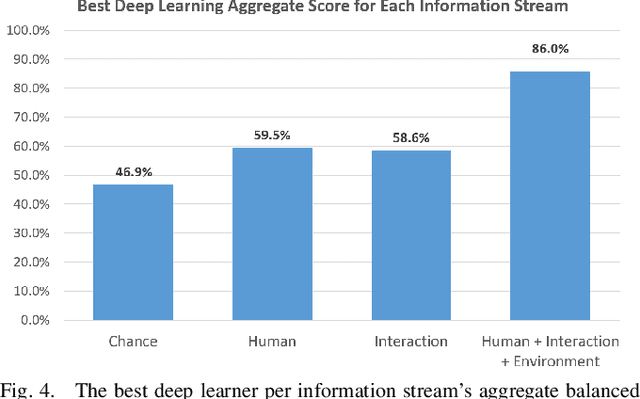
A dynamic autonomy allocation framework automatically shifts how much control lies with the human versus the robotics autonomy, for example based on factors such as environmental safety or user preference. To investigate the question of which factors should drive dynamic autonomy allocation, we perform a human subject study to collect ground truth data that shifts between levels of autonomy during shared-control robot operation. Information streams from the human, the interaction between the human and the robot, and the environment are analyzed. Machine learning methods -- both classical and deep learning -- are trained on this data. An analysis of information streams from the human-robot team suggests features which capture the interaction between the human and the robotics autonomy are the most informative in predicting when to shift autonomy levels. Even the addition of data from the environment does little to improve upon this predictive power. The features learned by deep networks, in comparison to the hand-engineered features, prove variable in their ability to represent shift-relevant information. This work demonstrates the classification power of human-only and human-robot interaction information streams for use in the design of shared-control frameworks, and provides insights into the comparative utility of various data streams and methods to extract shift-relevant information from those data.
GIMIRec: Global Interaction Information Aware Multi-Interest Framework for Sequential Recommendation
Dec 16, 2021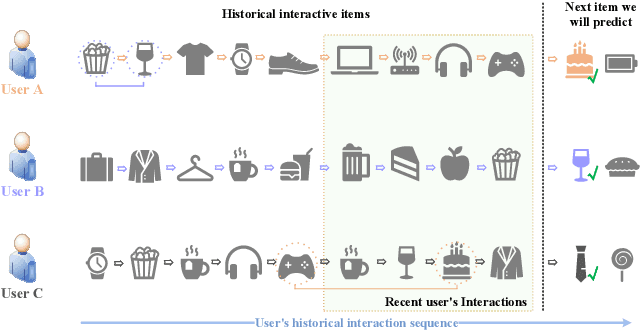
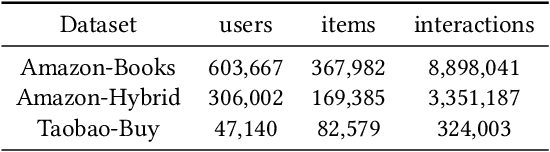
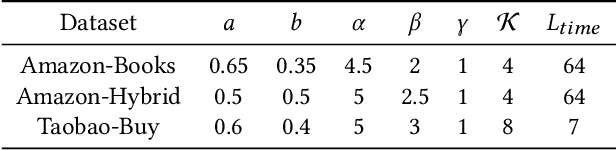
Sequential recommendation based on multi-interest framework models the user's recent interaction sequence into multiple different interest vectors, since a single low-dimensional vector cannot fully represent the diversity of user interests. However, most existing models only intercept users' recent interaction behaviors as training data, discarding a large amount of historical interaction sequences. This may raise two issues. On the one hand, data reflecting multiple interests of users is missing; on the other hand, the co-occurrence between items in historical user-item interactions is not fully explored. To tackle the two issues, this paper proposes a novel sequential recommendation model called "Global Interaction Aware Multi-Interest Framework for Sequential Recommendation (GIMIRec)". Specifically, a global context extraction module is firstly proposed without introducing any external information, which calculates a weighted co-occurrence matrix based on the constrained co-occurrence number of each item pair and their time interval from the historical interaction sequences of all users and then obtains the global context embedding of each item by using a simplified graph convolution. Secondly, the time interval of each item pair in the recent interaction sequence of each user is captured and combined with the global context item embedding to get the personalized item embedding. Finally, a self-attention based multi-interest framework is applied to learn the diverse interests of users for sequential recommendation. Extensive experiments on the three real-world datasets of Amazon-Books, Taobao-Buy and Amazon-Hybrid show that the performance of GIMIRec on the Recall, NDCG and Hit Rate indicators is significantly superior to that of the state-of-the-art methods. Moreover, the proposed global context extraction module can be easily transplanted to most sequential recommendation models.
Learned Indexing in Proteins: Substituting Complex Distance Calculations with Embedding and Clustering Techniques
Aug 18, 2022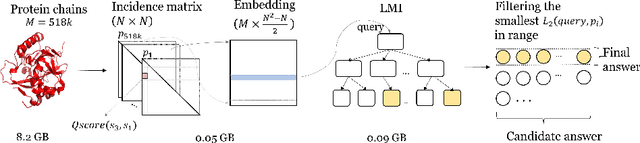

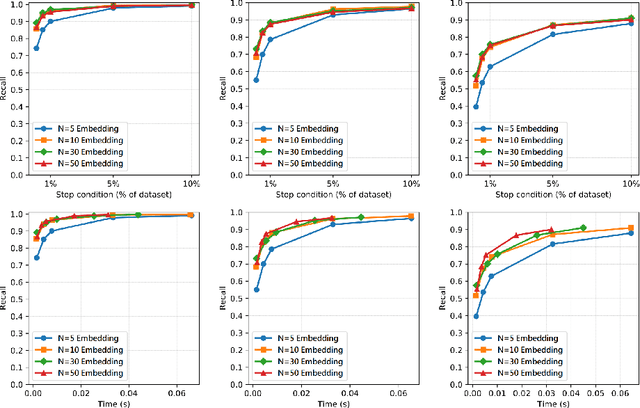
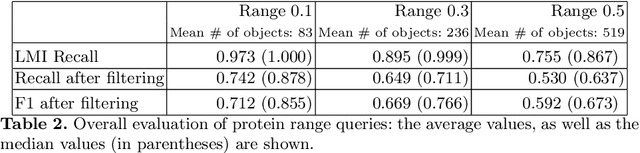
Despite the constant evolution of similarity searching research, it continues to face the same challenges stemming from the complexity of the data, such as the curse of dimensionality and computationally expensive distance functions. Various machine learning techniques have proven capable of replacing elaborate mathematical models with combinations of simple linear functions, often gaining speed and simplicity at the cost of formal guarantees of accuracy and correctness of querying. The authors explore the potential of this research trend by presenting a lightweight solution for the complex problem of 3D protein structure search. The solution consists of three steps -- (i) transformation of 3D protein structural information into very compact vectors, (ii) use of a probabilistic model to group these vectors and respond to queries by returning a given number of similar objects, and (iii) a final filtering step which applies basic vector distance functions to refine the result.