 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Collaborative Perception for Autonomous Driving: Current Status and Future Trend
Aug 22, 2022

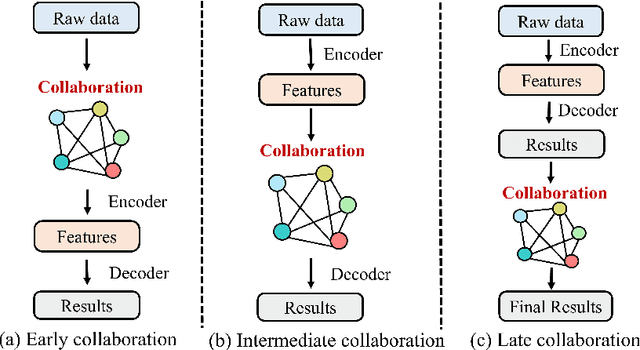
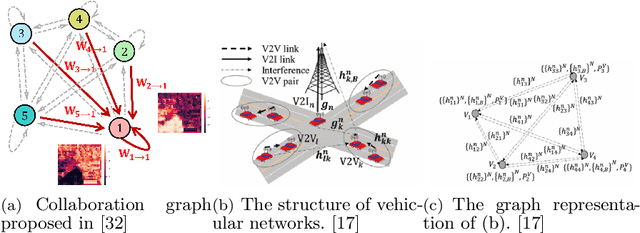

Perception is one of the crucial module of the autonomous driving system, which has made great progress recently. However, limited ability of individual vehicles results in the bottleneck of improvement of the perception performance. To break through the limits of individual perception, collaborative perception has been proposed which enables vehicles to share information to perceive the environments beyond line-of-sight and field-of-view. In this paper, we provide a review of the related work about the promising collaborative perception technology, including introducing the fundamental concepts, generalizing the collaboration modes and summarizing the key ingredients and applications of collaborative perception. Finally, we discuss the open challenges and issues of this research area and give some potential further directions.
Estimation and Navigation Methods with Limited Information for Autonomous Urban Driving
Aug 11, 2021



Urban environments offer a challenging scenario for autonomous driving. Globally localizing information, such as a GPS signal, can be unreliable due to signal shadowing and multipath errors. Detailed a priori maps of the environment with sufficient information for autonomous navigation typically require driving the area multiple times to collect large amounts of data, substantial post-processing on that data to obtain the map, and then maintaining updates on the map as the environment changes. This dissertation addresses the issue of autonomous driving in an urban environment by investigating algorithms and an architecture to enable fully functional autonomous driving with limited information.
Automatically Score Tissue Images Like a Pathologist by Transfer Learning
Sep 09, 2022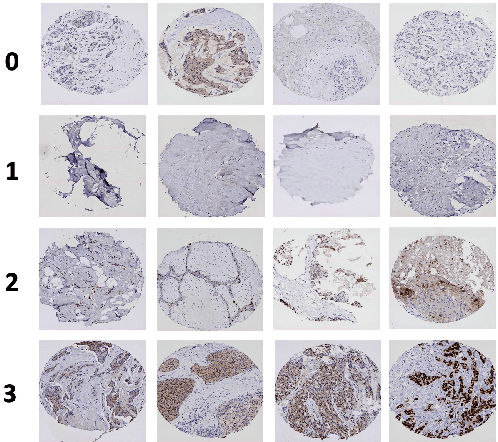
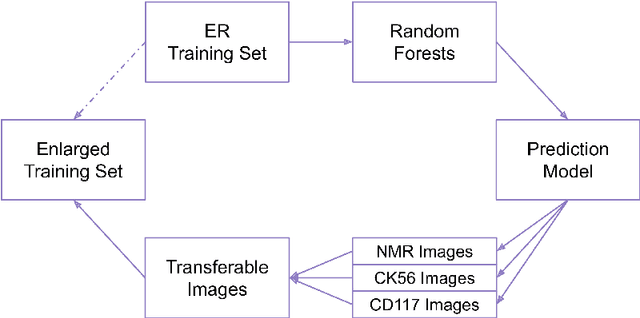
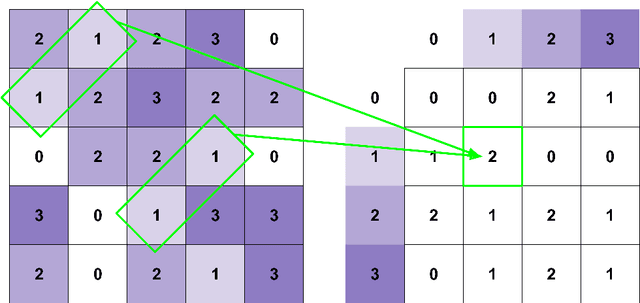
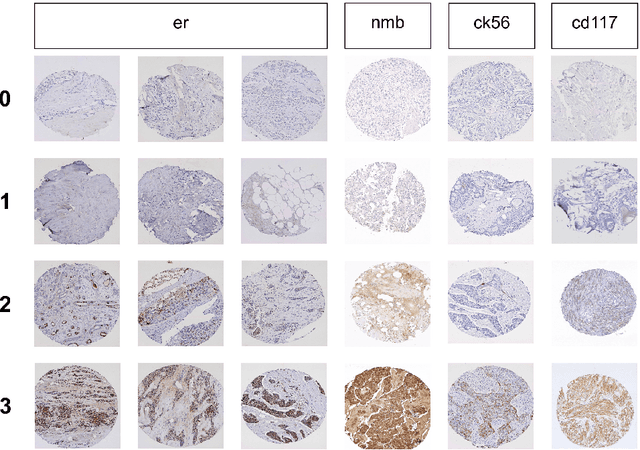
Cancer is the second leading cause of death in the world. Diagnosing cancer early on can save many lives. Pathologists have to look at tissue microarray (TMA) images manually to identify tumors, which can be time-consuming, inconsistent and subjective. Existing algorithms that automatically detect tumors have either not achieved the accuracy level of a pathologist or require substantial human involvements. A major challenge is that TMA images with different shapes, sizes, and locations can have the same score. Learning staining patterns in TMA images requires a huge number of images, which are severely limited due to privacy concerns and regulations in medical organizations. TMA images from different cancer types may have common characteristics that could provide valuable information, but using them directly harms the accuracy. Transfer learning is adopted to increase the training sample size by extracting knowledge from tissue images from different cancer types. Transfer learning has made it possible for the algorithm to break the critical accuracy barrier. The proposed algorithm reports an accuracy of 75.9% on breast cancer TMA images from the Stanford Tissue Microarray Database, achieving the 75% accuracy level of pathologists. This will allow pathologists to confidently use automatic algorithms to assist them in recognizing tumors consistently with a higher accuracy in real time.
Attitude-Guided Loop Closure for Cameras with Negative Plane
Sep 12, 2022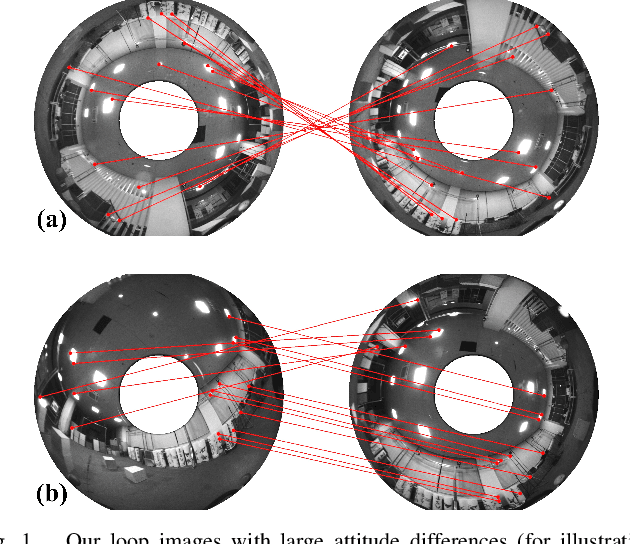

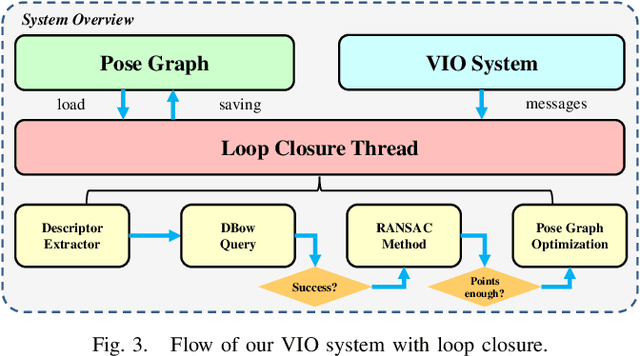

Loop closure is an important component of Simultaneous Localization and Mapping (SLAM) systems. Large Field-of-View (FoV) cameras have received extensive attention in the SLAM field as they can exploit more surrounding features on the panoramic image. In large-FoV VIO, for incorporating the informative cues located on the negative plane of the panoramic lens, image features are represented by a three-dimensional vector with a unit length. While the panoramic FoV is seemingly advantageous for loop closure, the benefits cannot easily be materialized under large-attitude-angle differences, where loop-closure frames can hardly be matched by existing methods. In this work, to fully unleash the potential of ultra-wide FoV, we propose to leverage the attitude information of a VIO system to guide the feature point detection of the loop closure. As loop closure on wide-FoV panoramic data further comes with a large number of outliers, traditional outlier rejection methods are not directly applicable. To tackle this issue, we propose a loop closure framework with a new outlier rejection method based on the unit length representation, to improve the accuracy of LF-VIO. On the public PALVIO dataset, a comprehensive set of experiments is carried out and the proposed LF-VIO-Loop outperforms state-of-the-art visual-inertial-odometry methods. Our code will be open-sourced at https://github.com/flysoaryun/LF-VIO-Loop.
Differentiable WORLD Synthesizer-based Neural Vocoder With Application To End-To-End Audio Style Transfer
Sep 01, 2022

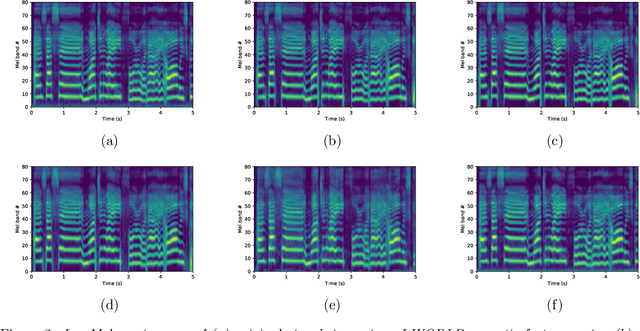
In this paper, we propose a differentiable WORLD synthesizer and demonstrate its use in end-to-end audio style transfer tasks such as (singing) voice conversion and the DDSP timbre transfer task. Accordingly, our baseline differentiable synthesizer has no model parameters, yet it yields adequate synthesis quality. We can extend the baseline synthesizer by appending lightweight black-box postnets which apply further processing to the baseline output in order to improve fidelity. An alternative differentiable approach considers extraction of the source excitation spectrum directly, which can improve naturalness albeit for a narrower class of style transfer applications. The acoustic feature parameterization used by our approaches has the added benefit that it naturally disentangles pitch and timbral information so that they can be modeled separately. Moreover, as there exists a robust means of estimating these acoustic features from monophonic audio sources, it allows for parameter loss terms to be added to an end-to-end objective function, which can help convergence and/or further stabilize (adversarial) training.
Continual Variational Autoencoder Learning via Online Cooperative Memorization
Jul 20, 2022



Due to their inference, data representation and reconstruction properties, Variational Autoencoders (VAE) have been successfully used in continual learning classification tasks. However, their ability to generate images with specifications corresponding to the classes and databases learned during Continual Learning (CL) is not well understood and catastrophic forgetting remains a significant challenge. In this paper, we firstly analyze the forgetting behaviour of VAEs by developing a new theoretical framework that formulates CL as a dynamic optimal transport problem. This framework proves approximate bounds to the data likelihood without requiring the task information and explains how the prior knowledge is lost during the training process. We then propose a novel memory buffering approach, namely the Online Cooperative Memorization (OCM) framework, which consists of a Short-Term Memory (STM) that continually stores recent samples to provide future information for the model, and a Long-Term Memory (LTM) aiming to preserve a wide diversity of samples. The proposed OCM transfers certain samples from STM to LTM according to the information diversity selection criterion without requiring any supervised signals. The OCM framework is then combined with a dynamic VAE expansion mixture network for further enhancing its performance.
Improving the Trainability of Deep Neural Networks through Layerwise Batch-Entropy Regularization
Aug 01, 2022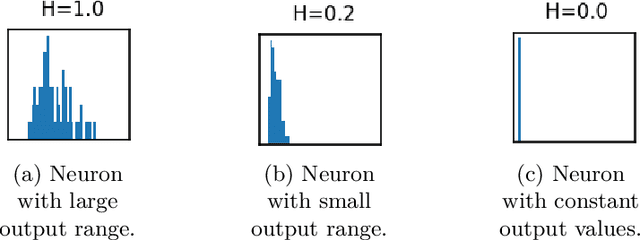
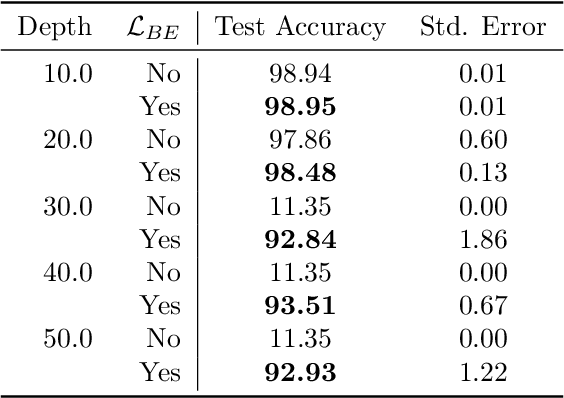
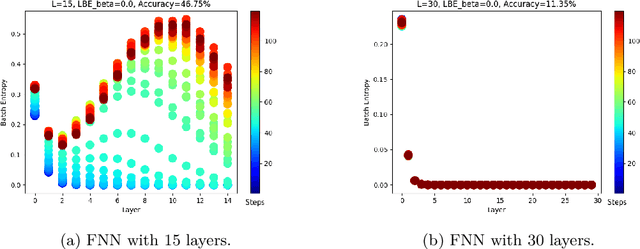
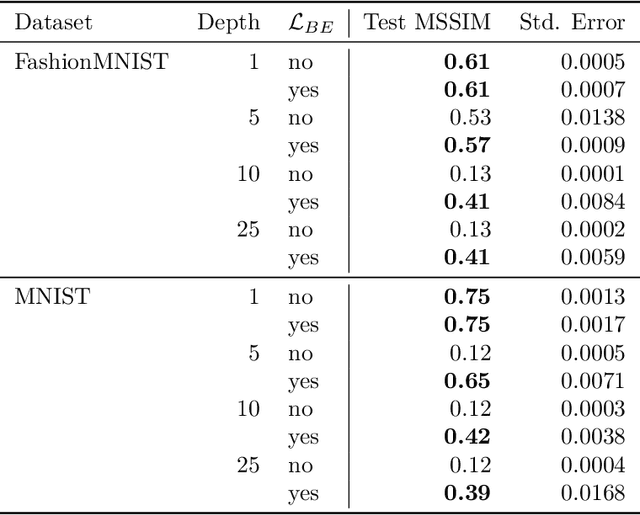
Training deep neural networks is a very demanding task, especially challenging is how to adapt architectures to improve the performance of trained models. We can find that sometimes, shallow networks generalize better than deep networks, and the addition of more layers results in higher training and test errors. The deep residual learning framework addresses this degradation problem by adding skip connections to several neural network layers. It would at first seem counter-intuitive that such skip connections are needed to train deep networks successfully as the expressivity of a network would grow exponentially with depth. In this paper, we first analyze the flow of information through neural networks. We introduce and evaluate the batch-entropy which quantifies the flow of information through each layer of a neural network. We prove empirically and theoretically that a positive batch-entropy is required for gradient descent-based training approaches to optimize a given loss function successfully. Based on those insights, we introduce batch-entropy regularization to enable gradient descent-based training algorithms to optimize the flow of information through each hidden layer individually. With batch-entropy regularization, gradient descent optimizers can transform untrainable networks into trainable networks. We show empirically that we can therefore train a "vanilla" fully connected network and convolutional neural network -- no skip connections, batch normalization, dropout, or any other architectural tweak -- with 500 layers by simply adding the batch-entropy regularization term to the loss function. The effect of batch-entropy regularization is not only evaluated on vanilla neural networks, but also on residual networks, autoencoders, and also transformer models over a wide range of computer vision as well as natural language processing tasks.
Deep Active Learning with Budget Annotation
Jul 31, 2022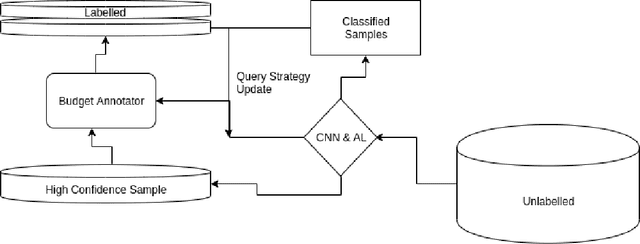
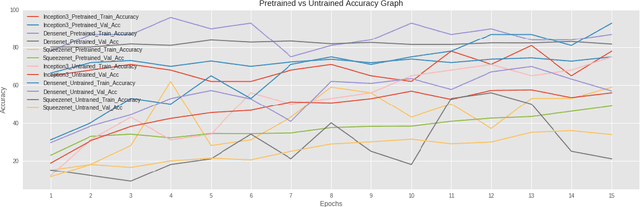
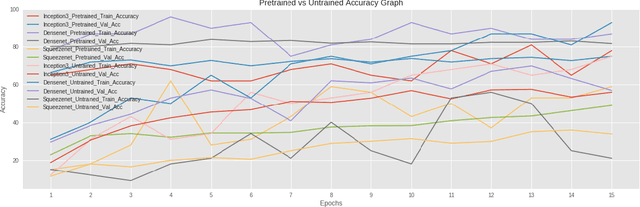
Digital data collected over the decades and data currently being produced with use of information technology is vastly the unlabeled data or data without description. The unlabeled data is relatively easy to acquire but expensive to label even with use of domain experts. Most of the recent works focus on use of active learning with uncertainty metrics measure to address this problem. Although most uncertainty selection strategies are very effective, they fail to take informativeness of the unlabeled instances into account and are prone to querying outliers. In order to address these challenges we propose an hybrid approach of computing both the uncertainty and informativeness of an instance, then automaticaly label the computed instances using budget annotator. To reduce the annotation cost, we employ the state-of-the-art pre-trained models in order to avoid querying information already contained in those models. Our extensive experiments on different sets of datasets demonstrate the efficacy of the proposed approach.
Quantitative Stopword Generation for Sentiment Analysis via Recursive and Iterative Deletion
Sep 04, 2022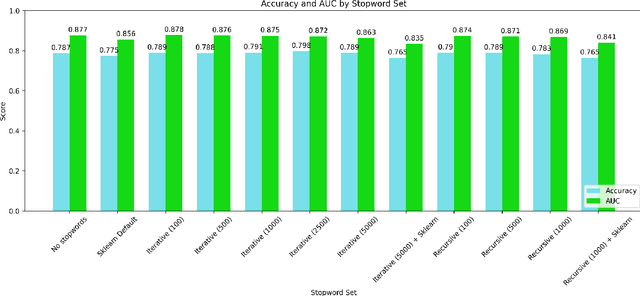
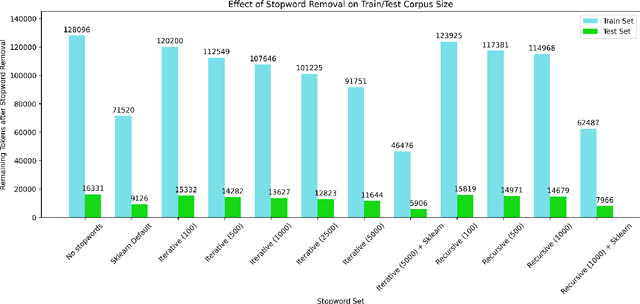
Stopwords carry little semantic information and are often removed from text data to reduce dataset size and improve machine learning model performance. Consequently, researchers have sought to develop techniques for generating effective stopword sets. Previous approaches have ranged from qualitative techniques relying upon linguistic experts, to statistical approaches that extract word importance using correlations or frequency-dependent metrics computed on a corpus. We present a novel quantitative approach that employs iterative and recursive feature deletion algorithms to see which words can be deleted from a pre-trained transformer's vocabulary with the least degradation to its performance, specifically for the task of sentiment analysis. Empirically, stopword lists generated via this approach drastically reduce dataset size while negligibly impacting model performance, in one such example shrinking the corpus by 28.4% while improving the accuracy of a trained logistic regression model by 0.25%. In another instance, the corpus was shrunk by 63.7% with a 2.8% decrease in accuracy. These promising results indicate that our approach can generate highly effective stopword sets for specific NLP tasks.
Hard Negatives or False Negatives: Correcting Pooling Bias in Training Neural Ranking Models
Sep 12, 2022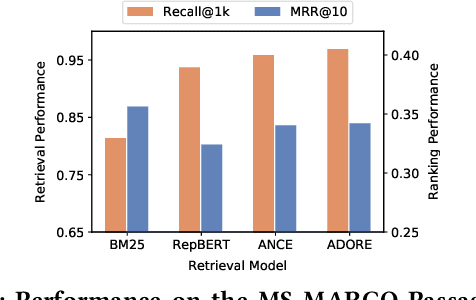
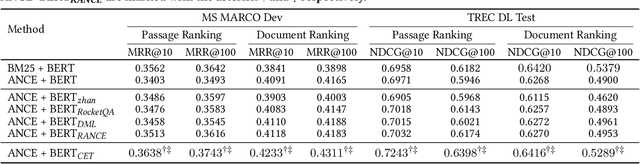
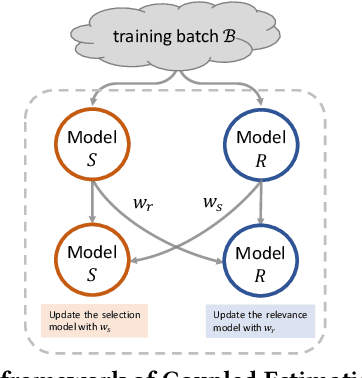
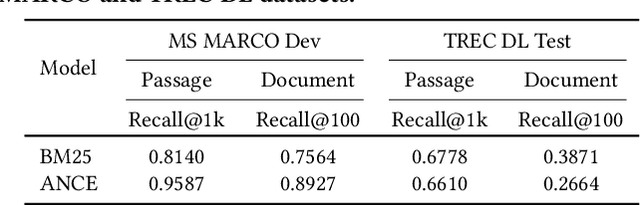
Neural ranking models (NRMs) have become one of the most important techniques in information retrieval (IR). Due to the limitation of relevance labels, the training of NRMs heavily relies on negative sampling over unlabeled data. In general machine learning scenarios, it has shown that training with hard negatives (i.e., samples that are close to positives) could lead to better performance. Surprisingly, we find opposite results from our empirical studies in IR. When sampling top-ranked results (excluding the labeled positives) as negatives from a stronger retriever, the performance of the learned NRM becomes even worse. Based on our investigation, the superficial reason is that there are more false negatives (i.e., unlabeled positives) in the top-ranked results with a stronger retriever, which may hurt the training process; The root is the existence of pooling bias in the dataset constructing process, where annotators only judge and label very few samples selected by some basic retrievers. Therefore, in principle, we can formulate the false negative issue in training NRMs as learning from labeled datasets with pooling bias. To solve this problem, we propose a novel Coupled Estimation Technique (CET) that learns both a relevance model and a selection model simultaneously to correct the pooling bias for training NRMs. Empirical results on three retrieval benchmarks show that NRMs trained with our technique can achieve significant gains on ranking effectiveness against other baseline strategies.