 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Theoretical Analysis of Submodular Information Measures for Targeted Data Subset Selection
Feb 21, 2024
With increasing volume of data being used across machine learning tasks, the capability to target specific subsets of data becomes more important. To aid in this capability, the recently proposed Submodular Mutual Information (SMI) has been effectively applied across numerous tasks in literature to perform targeted subset selection with the aid of a exemplar query set. However, all such works are deficient in providing theoretical guarantees for SMI in terms of its sensitivity to a subset's relevance and coverage of the targeted data. For the first time, we provide such guarantees by deriving similarity-based bounds on quantities related to relevance and coverage of the targeted data. With these bounds, we show that the SMI functions, which have empirically shown success in multiple applications, are theoretically sound in achieving good query relevance and query coverage.
Kernel Correlation-Dissimilarity for Multiple Kernel k-Means Clustering
Mar 06, 2024The main objective of the Multiple Kernel k-Means (MKKM) algorithm is to extract non-linear information and achieve optimal clustering by optimizing base kernel matrices. Current methods enhance information diversity and reduce redundancy by exploiting interdependencies among multiple kernels based on correlations or dissimilarities. Nevertheless, relying solely on a single metric, such as correlation or dissimilarity, to define kernel relationships introduces bias and incomplete characterization. Consequently, this limitation hinders efficient information extraction, ultimately compromising clustering performance. To tackle this challenge, we introduce a novel method that systematically integrates both kernel correlation and dissimilarity. Our approach comprehensively captures kernel relationships, facilitating more efficient classification information extraction and improving clustering performance. By emphasizing the coherence between kernel correlation and dissimilarity, our method offers a more objective and transparent strategy for extracting non-linear information and significantly improving clustering precision, supported by theoretical rationale. We assess the performance of our algorithm on 13 challenging benchmark datasets, demonstrating its superiority over contemporary state-of-the-art MKKM techniques.
* 36 pages. This paper was accepted by Pattern Recognition on January 31, 2024
SoK: Can Trajectory Generation Combine Privacy and Utility?
Mar 12, 2024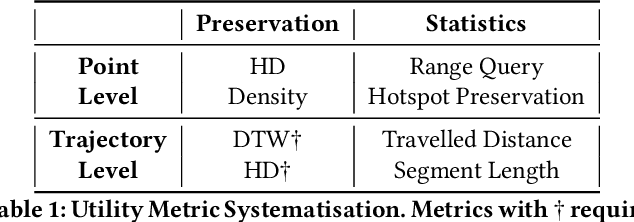
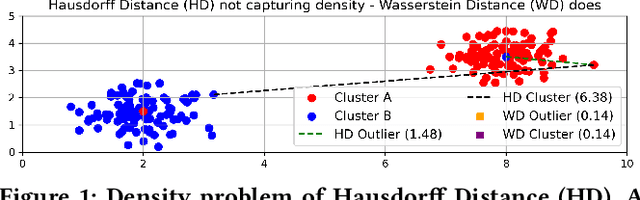
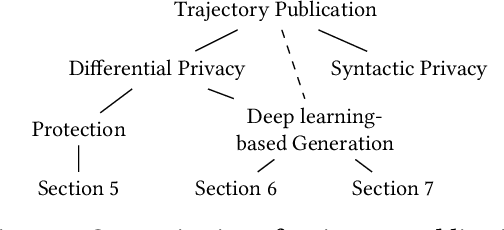
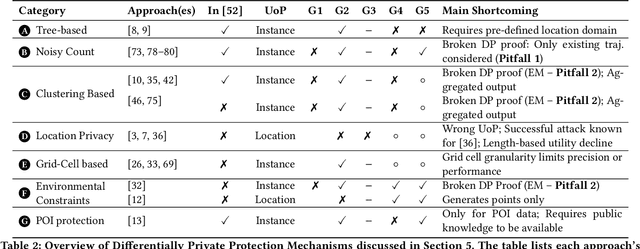
While location trajectories represent a valuable data source for analyses and location-based services, they can reveal sensitive information, such as political and religious preferences. Differentially private publication mechanisms have been proposed to allow for analyses under rigorous privacy guarantees. However, the traditional protection schemes suffer from a limiting privacy-utility trade-off and are vulnerable to correlation and reconstruction attacks. Synthetic trajectory data generation and release represent a promising alternative to protection algorithms. While initial proposals achieve remarkable utility, they fail to provide rigorous privacy guarantees. This paper proposes a framework for designing a privacy-preserving trajectory publication approach by defining five design goals, particularly stressing the importance of choosing an appropriate Unit of Privacy. Based on this framework, we briefly discuss the existing trajectory protection approaches, emphasising their shortcomings. This work focuses on the systematisation of the state-of-the-art generative models for trajectories in the context of the proposed framework. We find that no existing solution satisfies all requirements. Thus, we perform an experimental study evaluating the applicability of six sequential generative models to the trajectory domain. Finally, we conclude that a generative trajectory model providing semantic guarantees remains an open research question and propose concrete next steps for future research.
Privacy-Preserving Collaborative Split Learning Framework for Smart Grid Load Forecasting
Mar 12, 2024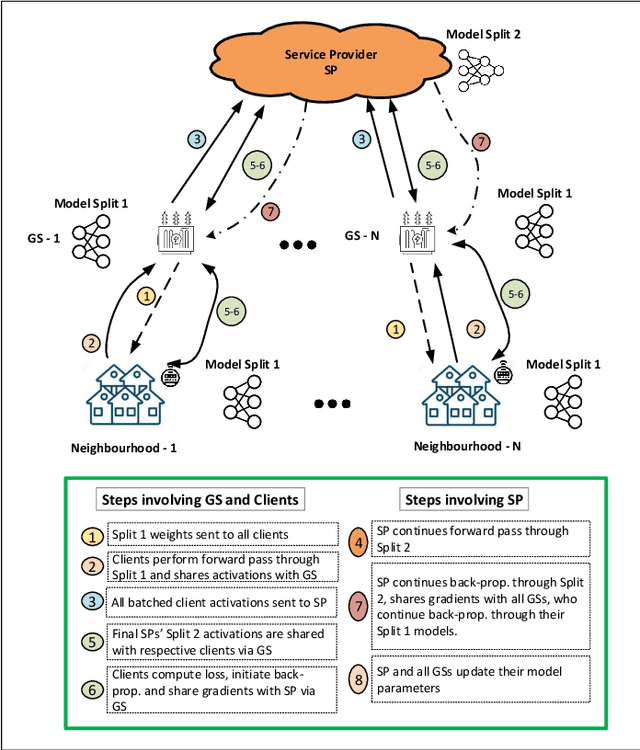
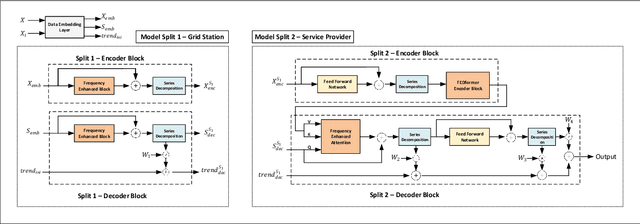
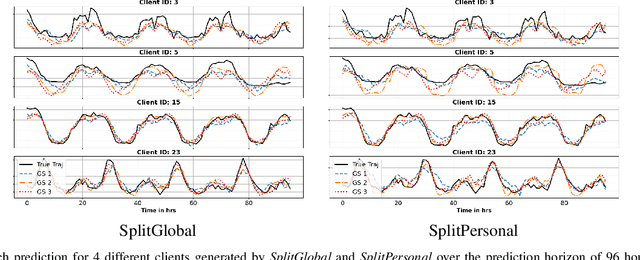
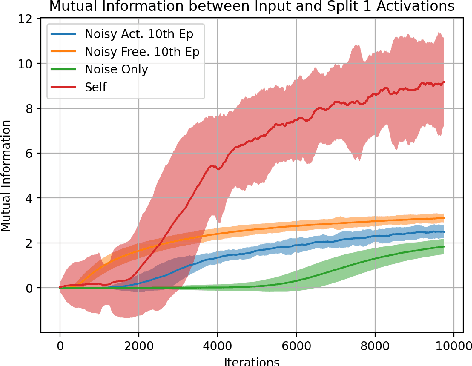
Accurate load forecasting is crucial for energy management, infrastructure planning, and demand-supply balancing. Smart meter data availability has led to the demand for sensor-based load forecasting. Conventional ML allows training a single global model using data from multiple smart meters requiring data transfer to a central server, raising concerns for network requirements, privacy, and security. We propose a split learning-based framework for load forecasting to alleviate this issue. We split a deep neural network model into two parts, one for each Grid Station (GS) responsible for an entire neighbourhood's smart meters and the other for the Service Provider (SP). Instead of sharing their data, client smart meters use their respective GSs' model split for forward pass and only share their activations with the GS. Under this framework, each GS is responsible for training a personalized model split for their respective neighbourhoods, whereas the SP can train a single global or personalized model for each GS. Experiments show that the proposed models match or exceed a centrally trained model's performance and generalize well. Privacy is analyzed by assessing information leakage between data and shared activations of the GS model split. Additionally, differential privacy enhances local data privacy while examining its impact on performance. A transformer model is used as our base learner.
Balancing Fairness and Accuracy in Data-Restricted Binary Classification
Mar 12, 2024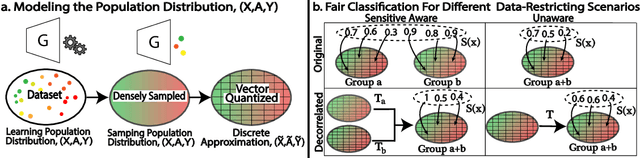
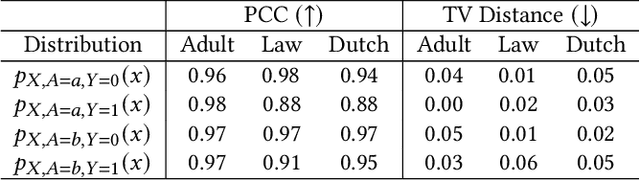
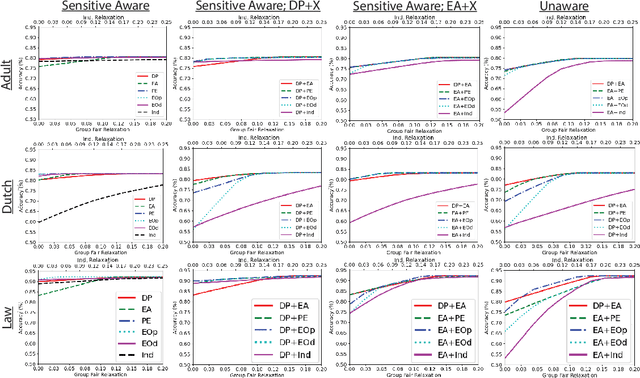
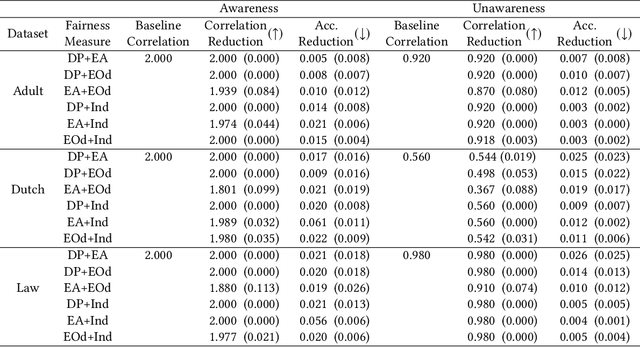
Applications that deal with sensitive information may have restrictions placed on the data available to a machine learning (ML) classifier. For example, in some applications, a classifier may not have direct access to sensitive attributes, affecting its ability to produce accurate and fair decisions. This paper proposes a framework that models the trade-off between accuracy and fairness under four practical scenarios that dictate the type of data available for analysis. Prior works examine this trade-off by analyzing the outputs of a scoring function that has been trained to implicitly learn the underlying distribution of the feature vector, class label, and sensitive attribute of a dataset. In contrast, our framework directly analyzes the behavior of the optimal Bayesian classifier on this underlying distribution by constructing a discrete approximation it from the dataset itself. This approach enables us to formulate multiple convex optimization problems, which allow us to answer the question: How is the accuracy of a Bayesian classifier affected in different data restricting scenarios when constrained to be fair? Analysis is performed on a set of fairness definitions that include group and individual fairness. Experiments on three datasets demonstrate the utility of the proposed framework as a tool for quantifying the trade-offs among different fairness notions and their distributional dependencies.
Entropy is not Enough for Test-Time Adaptation: From the Perspective of Disentangled Factors
Mar 12, 2024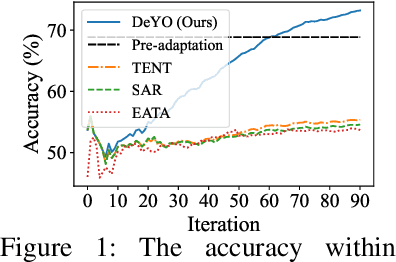
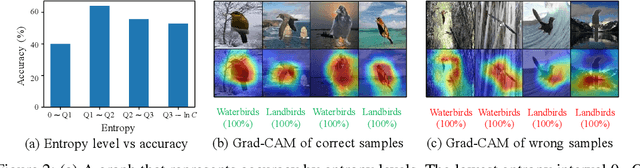
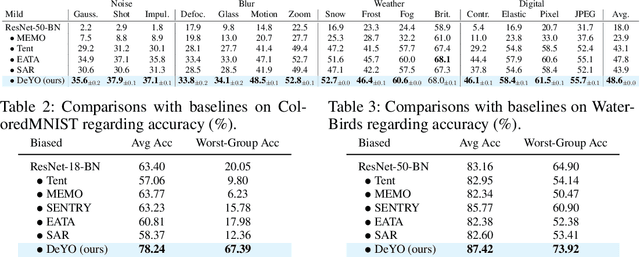

Test-time adaptation (TTA) fine-tunes pre-trained deep neural networks for unseen test data. The primary challenge of TTA is limited access to the entire test dataset during online updates, causing error accumulation. To mitigate it, TTA methods have utilized the model output's entropy as a confidence metric that aims to determine which samples have a lower likelihood of causing error. Through experimental studies, however, we observed the unreliability of entropy as a confidence metric for TTA under biased scenarios and theoretically revealed that it stems from the neglect of the influence of latent disentangled factors of data on predictions. Building upon these findings, we introduce a novel TTA method named Destroy Your Object (DeYO), which leverages a newly proposed confidence metric named Pseudo-Label Probability Difference (PLPD). PLPD quantifies the influence of the shape of an object on prediction by measuring the difference between predictions before and after applying an object-destructive transformation. DeYO consists of sample selection and sample weighting, which employ entropy and PLPD concurrently. For robust adaptation, DeYO prioritizes samples that dominantly incorporate shape information when making predictions. Our extensive experiments demonstrate the consistent superiority of DeYO over baseline methods across various scenarios, including biased and wild. Project page is publicly available at https://whitesnowdrop.github.io/DeYO/.
A Question-centric Multi-experts Contrastive Learning Framework for Improving the Accuracy and Interpretability of Deep Sequential Knowledge Tracing Models
Mar 12, 2024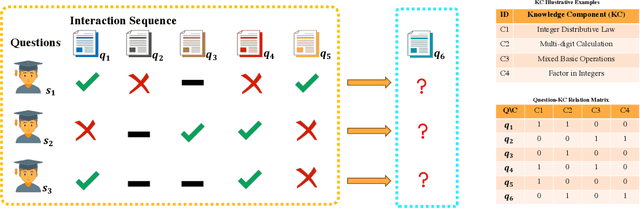
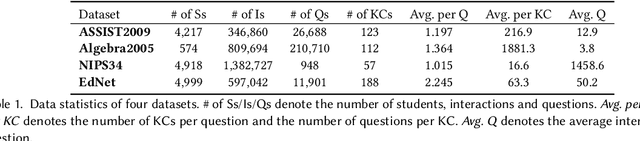
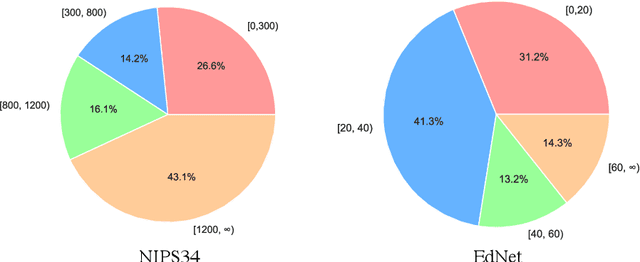
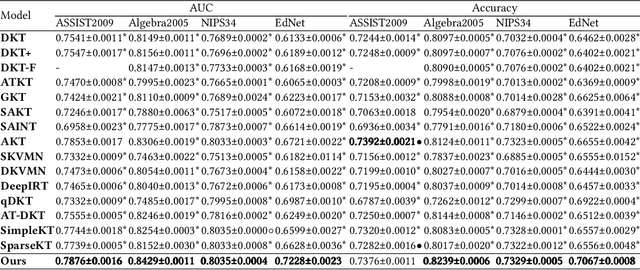
Knowledge tracing (KT) plays a crucial role in predicting students' future performance by analyzing their historical learning processes. Deep neural networks (DNNs) have shown great potential in solving the KT problem. However, there still exist some important challenges when applying deep learning techniques to model the KT process. The first challenge lies in taking the individual information of the question into modeling. This is crucial because, despite questions sharing the same knowledge component (KC), students' knowledge acquisition on homogeneous questions can vary significantly. The second challenge lies in interpreting the prediction results from existing deep learning-based KT models. In real-world applications, while it may not be necessary to have complete transparency and interpretability of the model parameters, it is crucial to present the model's prediction results in a manner that teachers find interpretable. This makes teachers accept the rationale behind the prediction results and utilize them to design teaching activities and tailored learning strategies for students. However, the inherent black-box nature of deep learning techniques often poses a hurdle for teachers to fully embrace the model's prediction results. To address these challenges, we propose a Question-centric Multi-experts Contrastive Learning framework for KT called Q-MCKT.
FPT: Fine-grained Prompt Tuning for Parameter and Memory Efficient Fine Tuning in High-resolution Medical Image Classification
Mar 12, 2024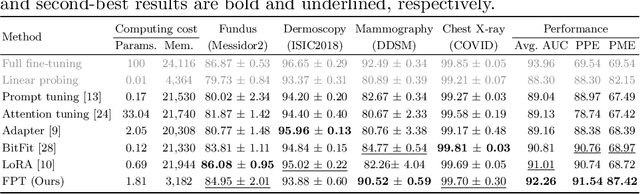
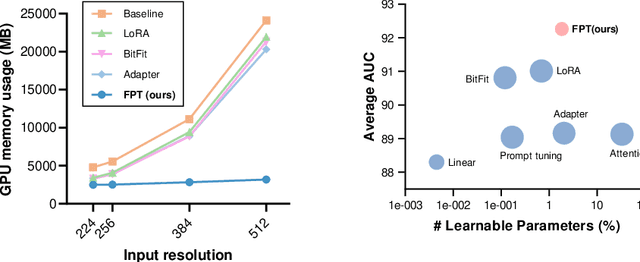
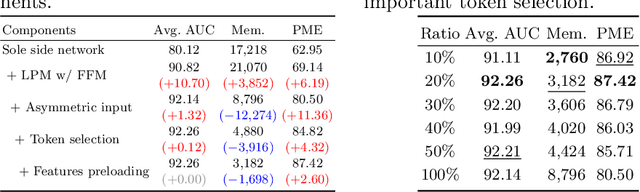
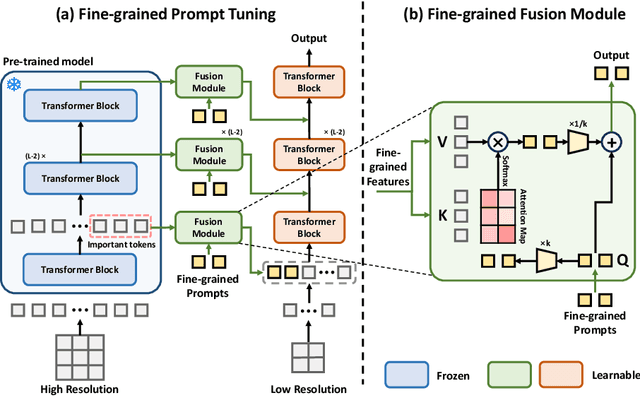
Parameter-efficient fine-tuning (PEFT) is proposed as a cost-effective way to transfer pre-trained models to downstream tasks, avoiding the high cost of updating entire large-scale pre-trained models (LPMs). In this work, we present Fine-grained Prompt Tuning (FPT), a novel PEFT method for medical image classification. FPT significantly reduces memory consumption compared to other PEFT methods, especially in high-resolution contexts. To achieve this, we first freeze the weights of the LPM and construct a learnable lightweight side network. The frozen LPM takes high-resolution images as input to extract fine-grained features, while the side network is fed low-resolution images to reduce memory usage. To allow the side network to access pre-trained knowledge, we introduce fine-grained prompts that summarize information from the LPM through a fusion module. Important tokens selection and preloading techniques are employed to further reduce training cost and memory requirements. We evaluate FPT on four medical datasets with varying sizes, modalities, and complexities. Experimental results demonstrate that FPT achieves comparable performance to fine-tuning the entire LPM while using only 1.8% of the learnable parameters and 13% of the memory costs of an encoder ViT-B model with a 512 x 512 input resolution.
A Review of Cybersecurity Incidents in the Food and Agriculture Sector
Mar 12, 2024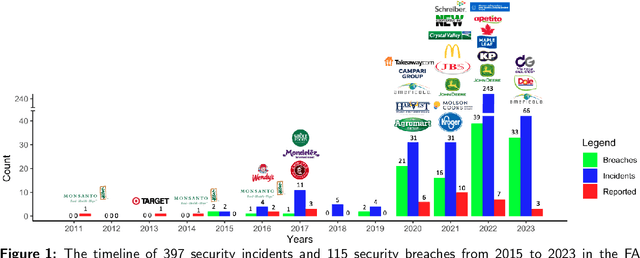
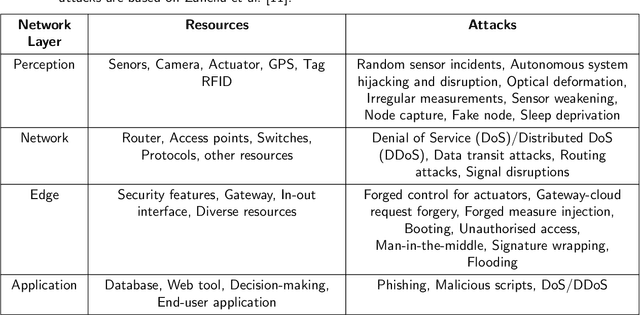
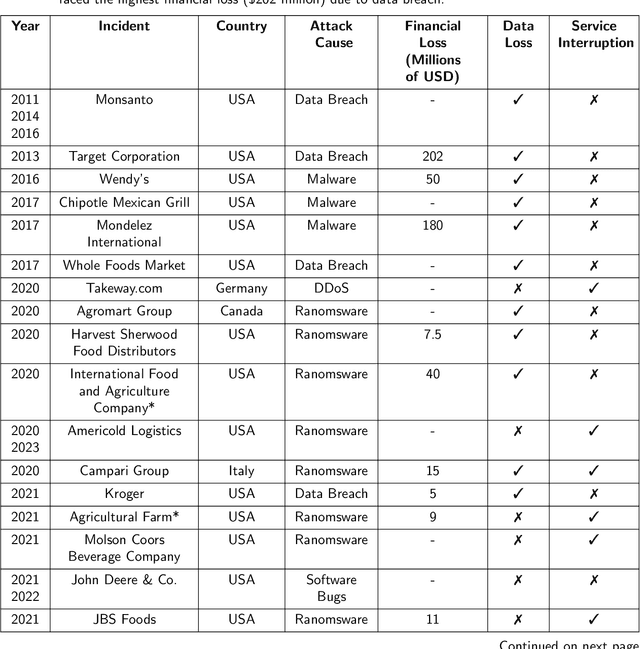
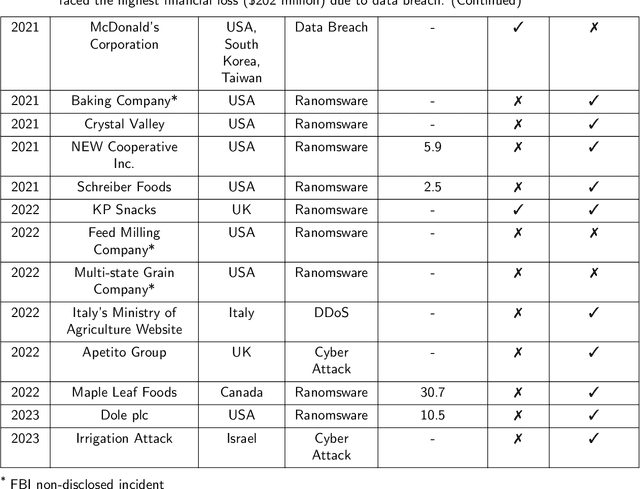
The increasing utilization of emerging technologies in the Food & Agriculture (FA) sector has heightened the need for security to minimize cyber risks. Considering this aspect, this manuscript reviews disclosed and documented cybersecurity incidents in the FA sector. For this purpose, thirty cybersecurity incidents were identified, which took place between July 2011 and April 2023. The details of these incidents are reported from multiple sources such as: the private industry and flash notifications generated by the Federal Bureau of Investigation (FBI), internal reports from the affected organizations, and available media sources. Considering the available information, a brief description of the security threat, ransom amount, and impact on the organization are discussed for each incident. This review reports an increased frequency of cybersecurity threats to the FA sector. To minimize these cyber risks, popular cybersecurity frameworks and recent agriculture-specific cybersecurity solutions are also discussed. Further, the need for AI assurance in the FA sector is explained, and the Farmer-Centered AI (FCAI) framework is proposed. The main aim of the FCAI framework is to support farmers in decision-making for agricultural production, by incorporating AI assurance. Lastly, the effects of the reported cyber incidents on other critical infrastructures, food security, and the economy are noted, along with specifying the open issues for future development.
Ariadne and Theseus: Exploration and Rendezvous with Two Mobile Agents in an Unknown Graph
Mar 12, 2024
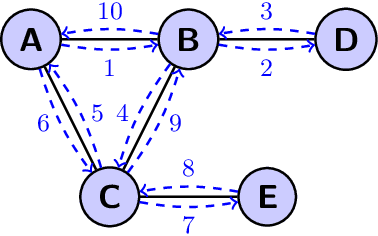
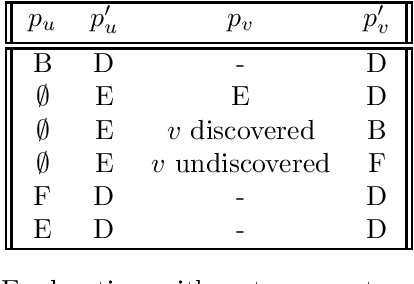
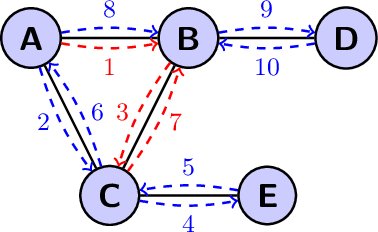
We investigate two fundamental problems in mobile computing: exploration and rendezvous, with two distinct mobile agents in an unknown graph. The agents can read and write information on whiteboards that are located at all nodes. They both move along one adjacent edge at every time-step. In the exploration problem, both agents start from the same node of the graph and must traverse all of its edges. We show that a simple variant of depth-first search achieves collective exploration in $m$ synchronous time-steps, where $m$ is the number of edges of the graph. This improves the competitive ratio of collective graph exploration. In the rendezvous problem, the agents start from different nodes of the graph and must meet as fast as possible. We introduce an algorithm guaranteeing rendezvous in at most $\frac{3}{2}m$ time-steps. This improves over the so-called `wait for Mommy' algorithm which requires $2m$ time-steps. All our guarantees are derived from a more general asynchronous setting in which the speeds of the agents are controlled by an adversary at all times. Our guarantees also generalize to weighted graphs, if the number of edges $m$ is replaced by the sum of all edge lengths.