 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
OSIC: A New One-Stage Image Captioner Coined
Nov 04, 2022
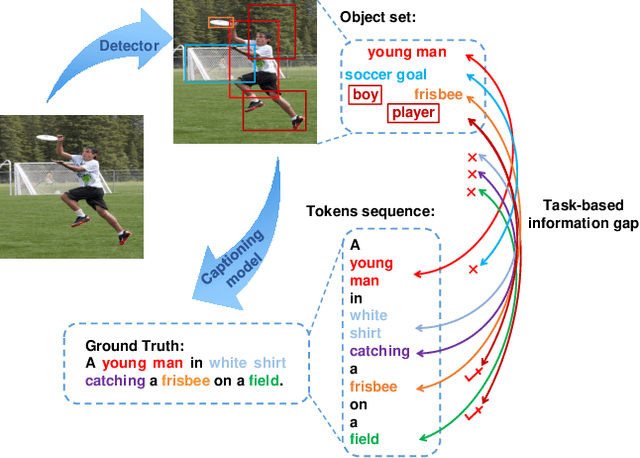
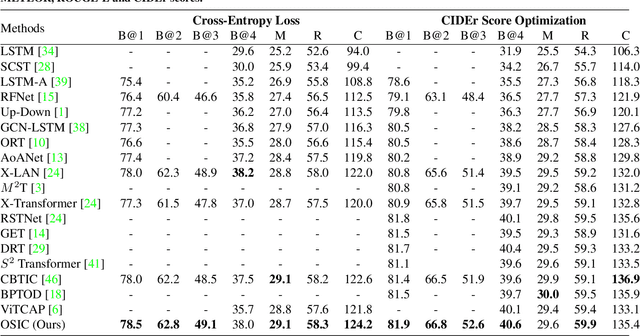
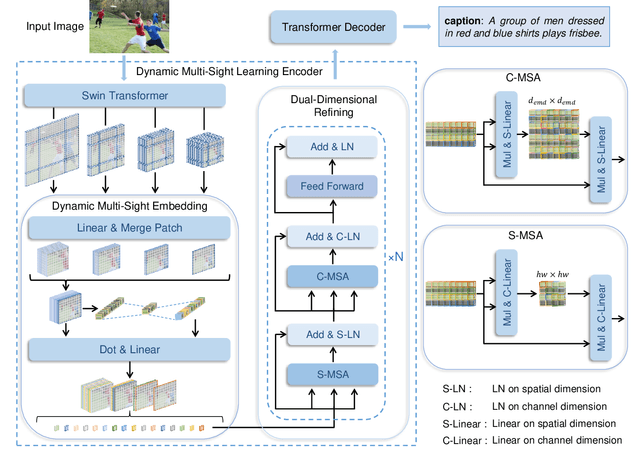
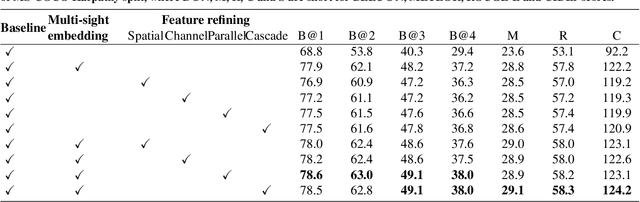
Mainstream image caption models are usually two-stage captioners, i.e., calculating object features by pre-trained detector, and feeding them into a language model to generate text descriptions. However, such an operation will cause a task-based information gap to decrease the performance, since the object features in detection task are suboptimal representation and cannot provide all necessary information for subsequent text generation. Besides, object features are usually represented by the last layer features that lose the local details of input images. In this paper, we propose a novel One-Stage Image Captioner (OSIC) with dynamic multi-sight learning, which directly transforms input image into descriptive sentences in one stage. As a result, the task-based information gap can be greatly reduced. To obtain rich features, we use the Swin Transformer to calculate multi-level features, and then feed them into a novel dynamic multi-sight embedding module to exploit both global structure and local texture of input images. To enhance the global modeling of encoder for caption, we propose a new dual-dimensional refining module to non-locally model the interaction of the embedded features. Finally, OSIC can obtain rich and useful information to improve the image caption task. Extensive comparisons on benchmark MS-COCO dataset verified the superior performance of our method.
MMD-B-Fair: Learning Fair Representations with Statistical Testing
Nov 15, 2022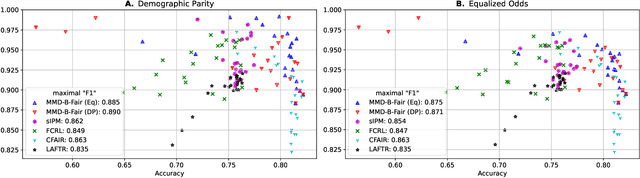
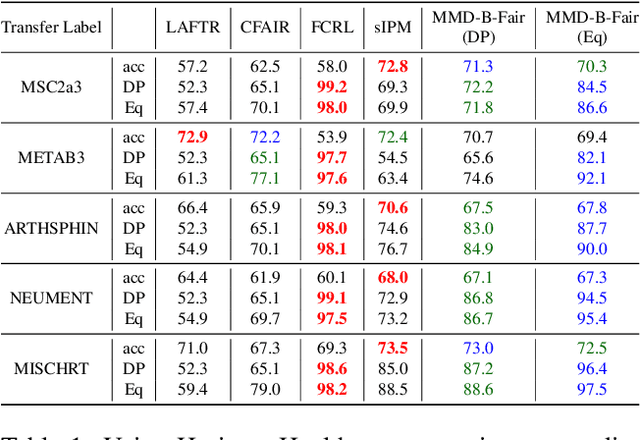
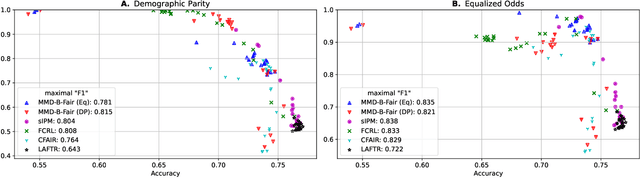
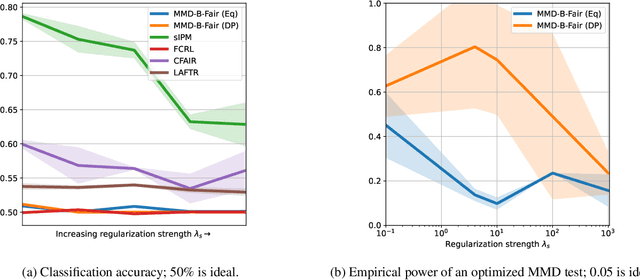
We introduce a method, MMD-B-Fair, to learn fair representations of data via kernel two-sample testing. We find neural features of our data where a maximum mean discrepancy (MMD) test cannot distinguish between different values of sensitive attributes, while preserving information about the target. Minimizing the power of an MMD test is more difficult than maximizing it (as done in previous work), because the test threshold's complex behavior cannot be simply ignored. Our method exploits the simple asymptotics of block testing schemes to efficiently find fair representations without requiring the complex adversarial optimization or generative modelling schemes widely used by existing work on fair representation learning. We evaluate our approach on various datasets, showing its ability to "hide" information about sensitive attributes, and its effectiveness in downstream transfer tasks.
Semi-Supervised Representative Region Texture Extraction of Façade
Dec 05, 2022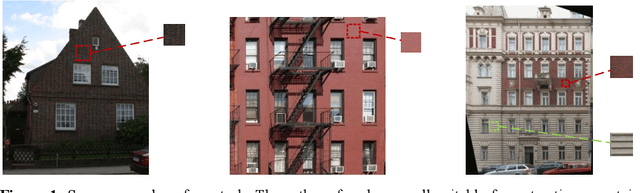

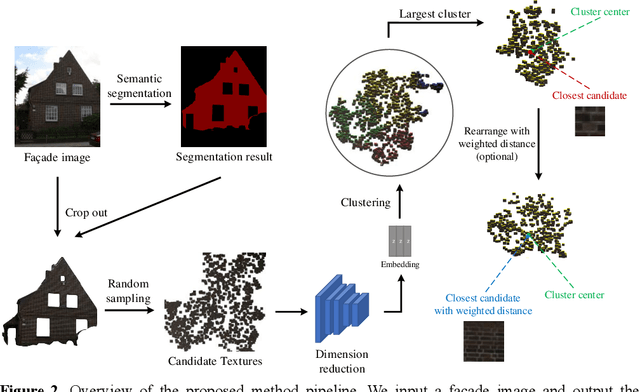

Researches of analysis and parsing around fa\c{c}ades to enrich the 3D feature of fa\c{c}ade models by semantic information raised some attention in the community, whose main idea is to generate higher resolution components with similar shapes and textures to increase the overall resolution at the expense of reconstruction accuracy. While this approach works well for components like windows and doors, there is no solution for fa\c{c}ade background at present. In this paper, we introduce the concept of representative region texture, which can be used in the above modeling approach by tiling the representative texture around the fa\c{c}ade region, and propose a semi-supervised way to do representative region texture extraction from a fa\c{c}ade image. Our method does not require any additional labelled data to train as long as the semantic information is given, while a traditional end-to-end model requires plenty of data to increase its performance. Our method can extract texture from any repetitive images, not just fa\c{c}ade, which is not capable in an end-to-end model as it relies on the distribution of training set. Clustering with weighted distance is introduced to further increase the robustness to noise or an imprecise segmentation, and make the extracted texture have a higher resolution and more suitable for tiling. We verify our method on various fa\c{c}ade images, and the result shows our method has a significant performance improvement compared to only a random crop on fa\c{c}ade. We also demonstrate some application scenarios and proposed a fa\c{c}ade modeling workflow with the representative region texture, which has a better visual resolution for a regular fa\c{c}ade.
'If you build they will come': Automatic Identification of News-Stakeholders to detect Party Preference in News Coverage
Dec 17, 2022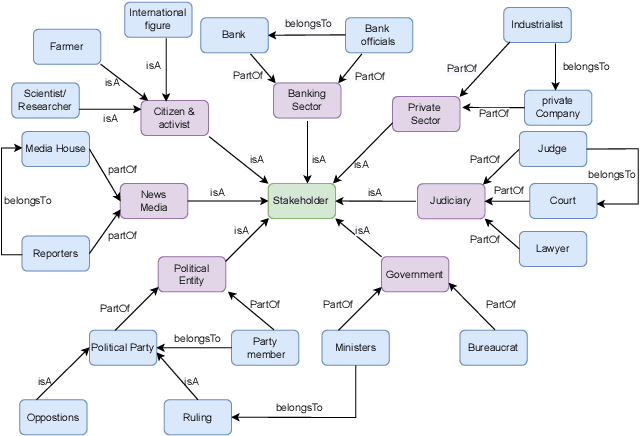

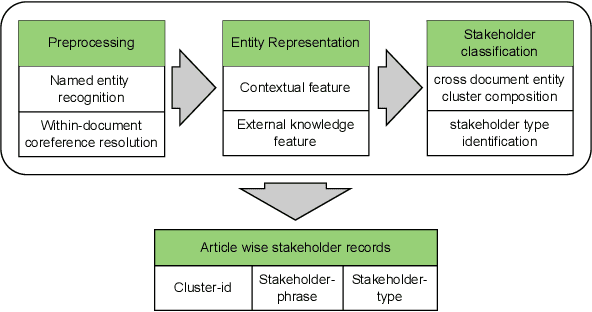

The coverage of different stakeholders mentioned in the news articles significantly impacts the slant or polarity detection of the concerned news publishers. For instance, the pro-government media outlets would give more coverage to the government stakeholders to increase their accessibility to the news audiences. In contrast, the anti-government news agencies would focus more on the views of the opponent stakeholders to inform the readers about the shortcomings of government policies. In this paper, we address the problem of stakeholder extraction from news articles and thereby determine the inherent bias present in news reporting. Identifying potential stakeholders in multi-topic news scenarios is challenging because each news topic has different stakeholders. The research presented in this paper utilizes both contextual information and external knowledge to identify the topic-specific stakeholders from news articles. We also apply a sequential incremental clustering algorithm to group the entities with similar stakeholder types. We carried out all our experiments on news articles on four Indian government policies published by numerous national and international news agencies. We also further generalize our system, and the experimental results show that the proposed model can be extended to other news topics.
Graph Learning: A Comprehensive Survey and Future Directions
Dec 17, 2022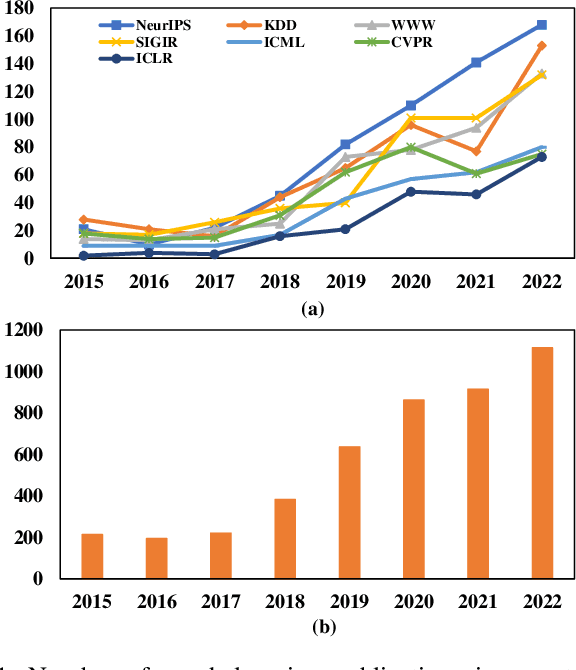
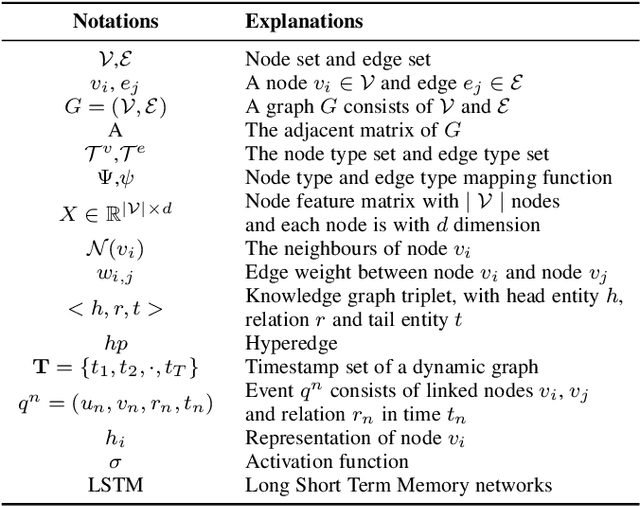
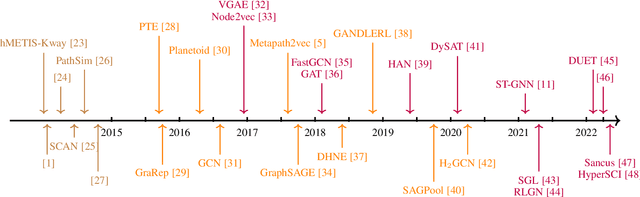

Graph learning aims to learn complex relationships among nodes and the topological structure of graphs, such as social networks, academic networks and e-commerce networks, which are common in the real world. Those relationships make graphs special compared with traditional tabular data in which nodes are dependent on non-Euclidean space and contain rich information to explore. Graph learning developed from graph theory to graph data mining and now is empowered with representation learning, making it achieve great performances in various scenarios, even including text, image, chemistry, and biology. Due to the broad application prospects in the real world, graph learning has become a popular and promising area in machine learning. Thousands of works have been proposed to solve various kinds of problems in graph learning and is appealing more and more attention in academic community, which makes it pivotal to survey previous valuable works. Although some of the researchers have noticed this phenomenon and finished impressive surveys on graph learning. However, they failed to link related objectives, methods and applications in a more logical way and cover current ample scenarios as well as challenging problems due to the rapid expansion of the graph learning.
DAG: Depth-Aware Guidance with Denoising Diffusion Probabilistic Models
Dec 17, 2022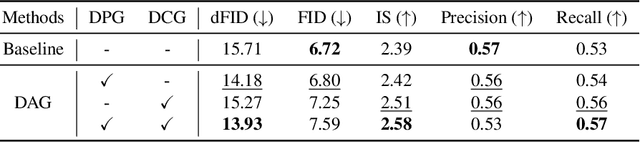
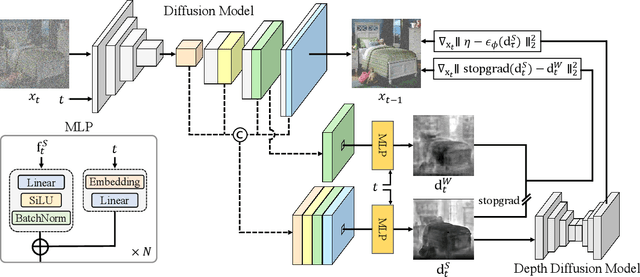
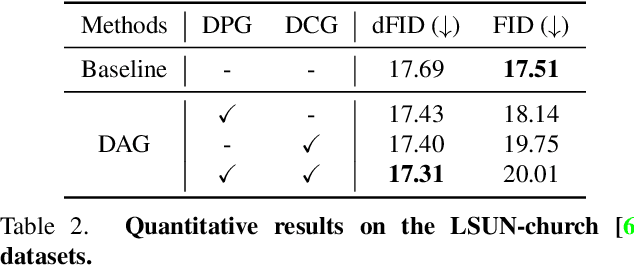

In recent years, generative models have undergone significant advancement due to the success of diffusion models. The success of these models is often attributed to their use of guidance techniques, such as classifier and classifier-free methods, which provides effective mechanisms to trade-off between fidelity and diversity. However, these methods are not capable of guiding a generated image to be aware of its geometric configuration, e.g., depth, which hinders the application of diffusion models to areas that require a certain level of depth awareness. To address this limitation, we propose a novel guidance approach for diffusion models that uses estimated depth information derived from the rich intermediate representations of diffusion models. To do this, we first present a label-efficient depth estimation framework using the internal representations of diffusion models. At the sampling phase, we utilize two guidance techniques to self-condition the generated image using the estimated depth map, the first of which uses pseudo-labeling, and the subsequent one uses a depth-domain diffusion prior. Experiments and extensive ablation studies demonstrate the effectiveness of our method in guiding the diffusion models toward geometrically plausible image generation. Project page is available at https://ku-cvlab.github.io/DAG/.
Contrastive Distillation Is a Sample-Efficient Self-Supervised Loss Policy for Transfer Learning
Dec 21, 2022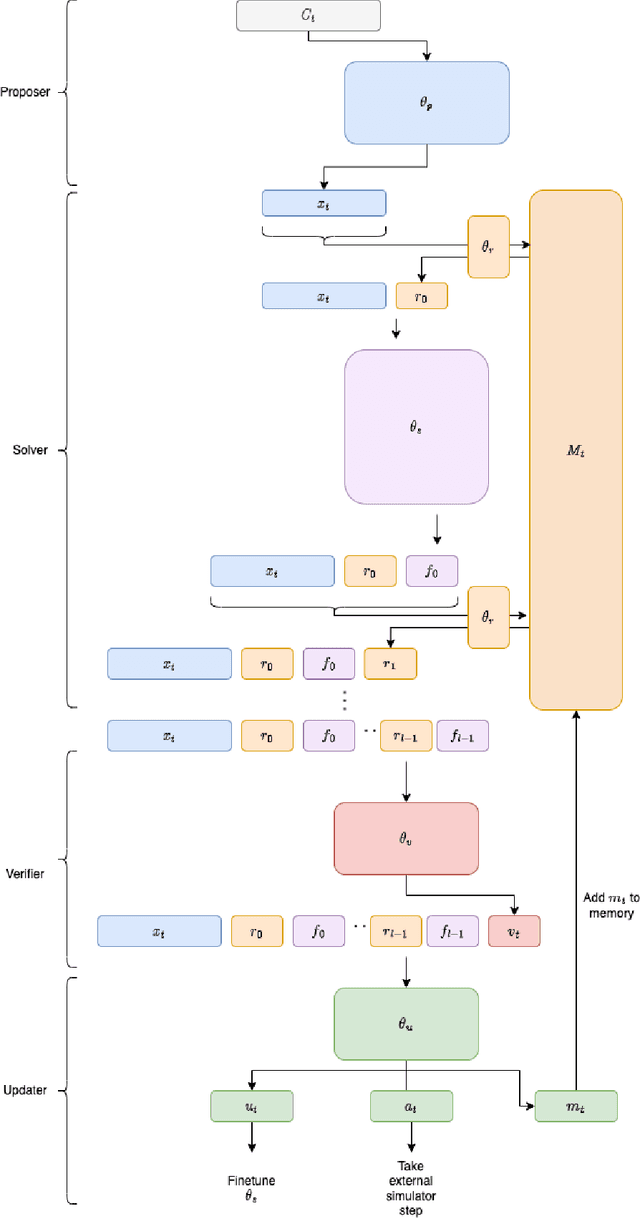
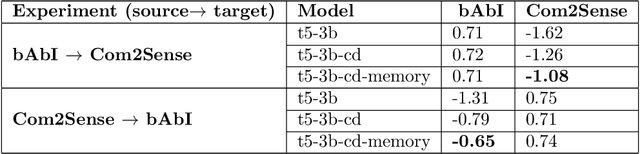
Traditional approaches to RL have focused on learning decision policies directly from episodic decisions, while slowly and implicitly learning the semantics of compositional representations needed for generalization. While some approaches have been adopted to refine representations via auxiliary self-supervised losses while simultaneously learning decision policies, learning compositional representations from hand-designed and context-independent self-supervised losses (multi-view) still adapts relatively slowly to the real world, which contains many non-IID subspaces requiring rapid distribution shift in both time and spatial attention patterns at varying levels of abstraction. In contrast, supervised language model cascades have shown the flexibility to adapt to many diverse manifolds, and hints of self-learning needed for autonomous task transfer. However, to date, transfer methods for language models like few-shot learning and fine-tuning still require human supervision and transfer learning using self-learning methods has been underexplored. We propose a self-supervised loss policy called contrastive distillation which manifests latent variables with high mutual information with both source and target tasks from weights to tokens. We show how this outperforms common methods of transfer learning and suggests a useful design axis of trading off compute for generalizability for online transfer. Contrastive distillation is improved through sampling from memory and suggests a simple algorithm for more efficiently sampling negative examples for contrastive losses than random sampling.
A Unified Approach to Semantic Information and Communication based on Probabilistic Logic
May 02, 2022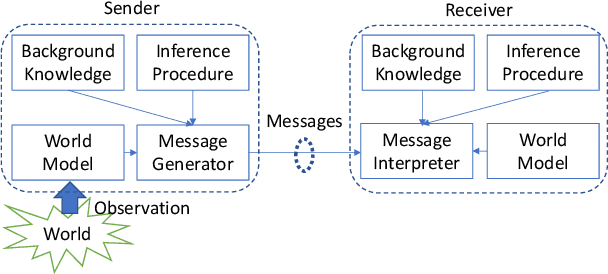
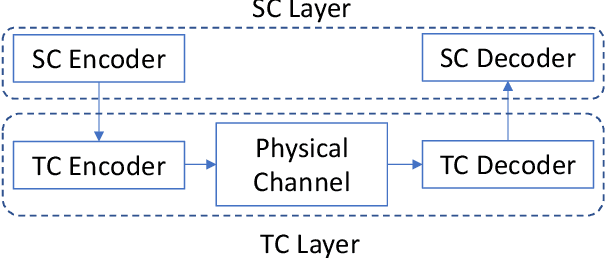
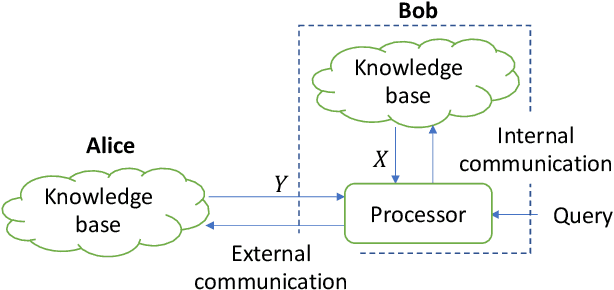
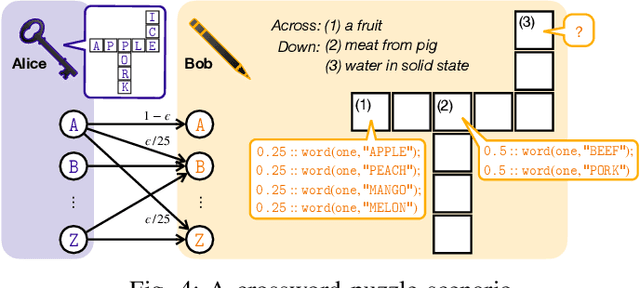
Traditionally, studies on technical communication (TC) are based on stochastic modeling and manipulation. This is not sufficient for semantic communication (SC) where semantic elements are logically connected, rather than stochastically correlated. To fill this void, by leveraging a logical programming language called probabilistic logic (ProbLog), we propose a unified approach to semantic information and communication through the interplay between TC and SC. On top of the well-established existing TC layer, we introduce a SC layer that utilizes knowledge bases of communicating parties for the exchange of semantic information. These knowledge bases are logically described, manipulated, and exploited using ProbLog. To make these SC and TC layers interact, we propose various measures based on the entropy of a clause in a knowledge base. These measures allow us to delineate various technical issues on SC such as a message selection problem for improving the knowledge base at a receiver. Extending this, we showcase selected examples in which SC and TC layers interact with each other while taking into account constraints on physical channels and efficiently utilizing channel resources.
Gold Doesn't Always Glitter: Spectral Removal of Linear and Nonlinear Guarded Attribute Information
Mar 15, 2022
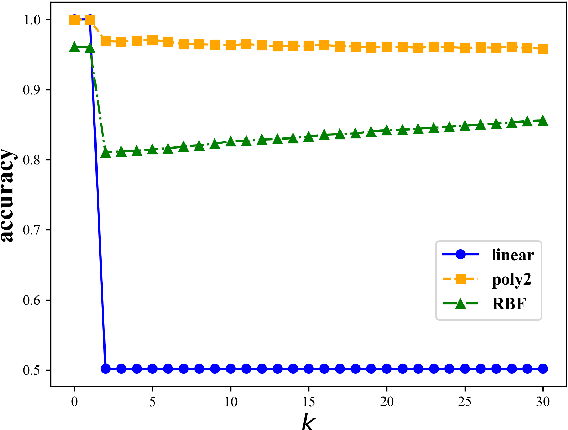

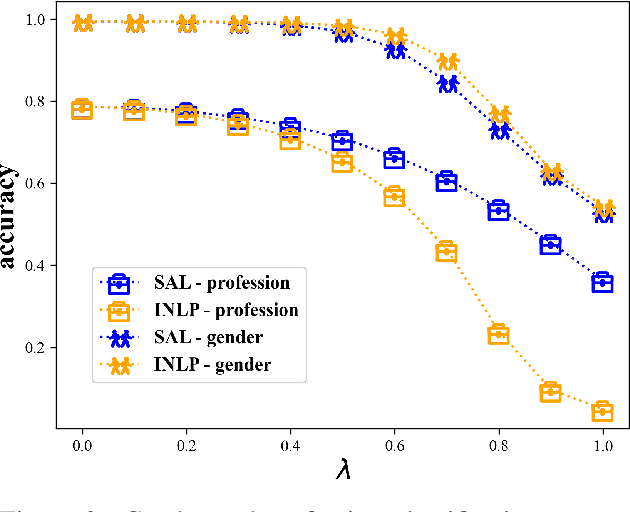
We describe a simple and effective method (Spectral Attribute removaL; SAL) to remove guarded information from neural representations. Our method uses singular value decomposition and eigenvalue decomposition to project the input representations into directions with reduced covariance with the guarded information rather than maximal covariance as normally these factorization methods are used. We begin with linear information removal and proceed to generalize our algorithm to the case of nonlinear information removal through the use of kernels. Our experiments demonstrate that our algorithm retains better main task performance after removing the guarded information compared to previous methods. In addition, our experiments demonstrate that we need a relatively small amount of guarded attribute data to remove information about these attributes, which lowers the exposure to such possibly sensitive data and fits better low-resource scenarios.
Information Field Theory as Artificial Intelligence
Dec 19, 2021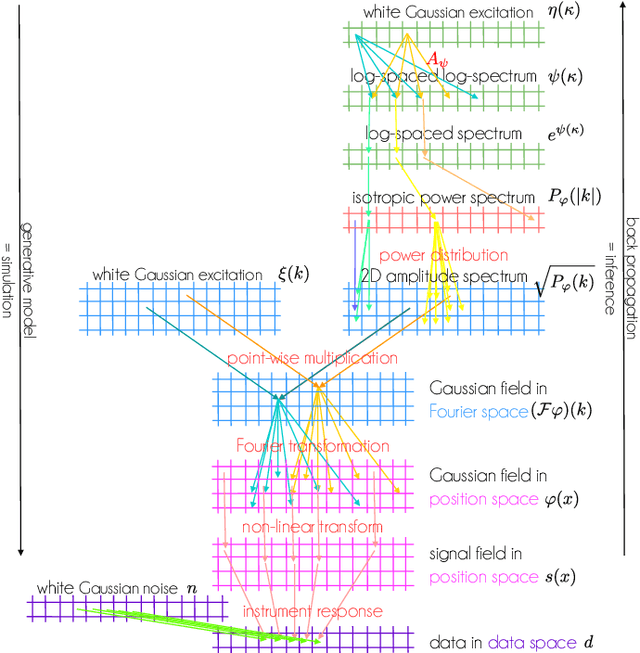
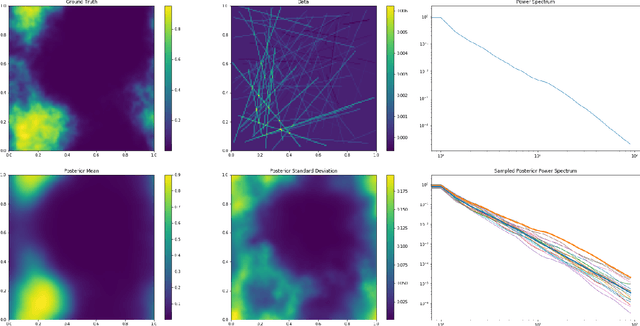
Information field theory (IFT), the information theory for fields, is a mathematical framework for signal reconstruction and non-parametric inverse problems. Here, fields denote physical quantities that change continuously as a function of space (and time) and information theory refers to Bayesian probabilistic logic equipped with the associated entropic information measures. Reconstructing a signal with IFT is a computational problem similar to training a generative neural network (GNN). In this paper, the inference in IFT is reformulated in terms of GNN training and the cross-fertilization of numerical variational inference methods used in IFT and machine learning are discussed. The discussion suggests that IFT inference can be regarded as a specific form of artificial intelligence. In contrast to classical neural networks, IFT based GNNs can operate without pre-training thanks to incorporating expert knowledge into their architecture.