 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Deep Learning Approach to the Prediction of Drug Side-Effects on Molecular Graphs
Nov 30, 2022
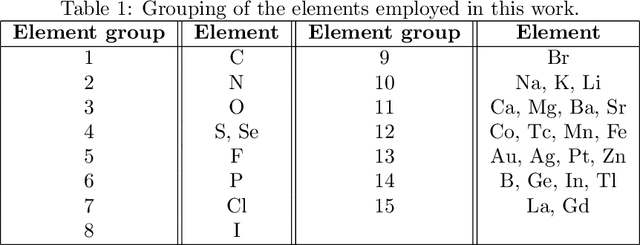
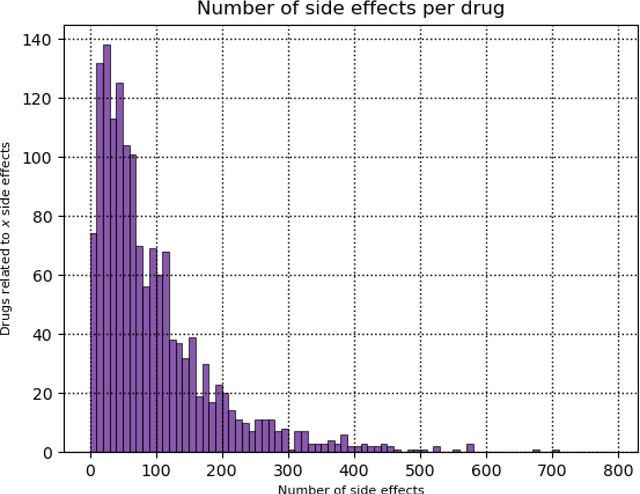
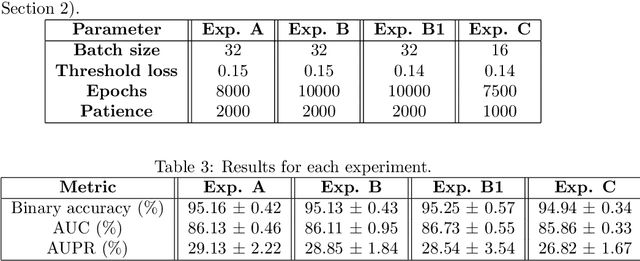
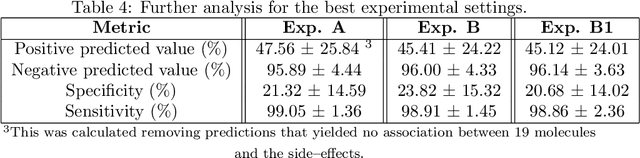
Predicting drug side-effects before they occur is a key task in keeping the number of drug-related hospitalizations low and to improve drug discovery processes. Automatic predictors of side-effects generally are not able to process the structure of the drug, resulting in a loss of information. Graph neural networks have seen great success in recent years, thanks to their ability of exploiting the information conveyed by the graph structure and labels. These models have been used in a wide variety of biological applications, among which the prediction of drug side-effects on a large knowledge graph. Exploiting the molecular graph encoding the structure of the drug represents a novel approach, in which the problem is formulated as a multi-class multi-label graph-focused classification. We developed a methodology to carry out this task, using recurrent Graph Neural Networks, and building a dataset from freely accessible and well established data sources. The results show that our method has an improved classification capability, under many parameters and metrics, with respect to previously available predictors.
Uncertainty-Aware Image Captioning
Nov 30, 2022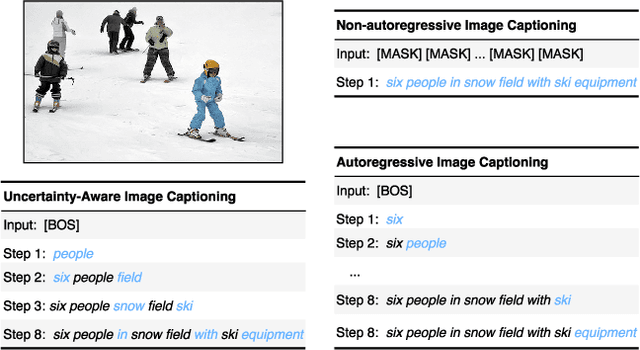
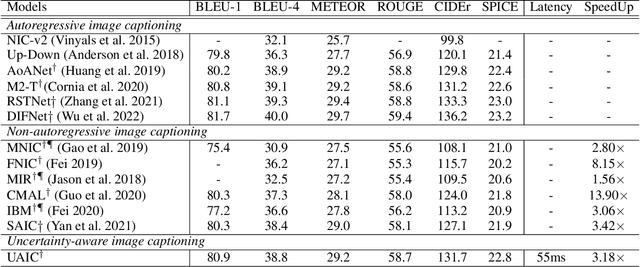
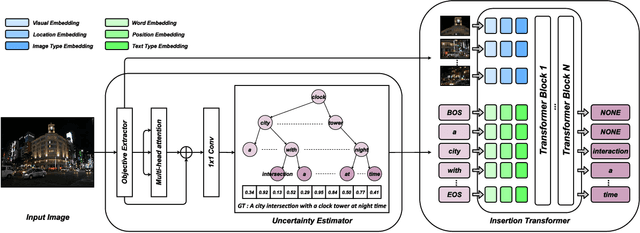
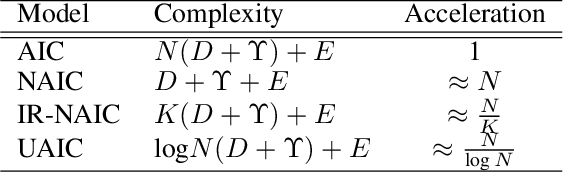
It is well believed that the higher uncertainty in a word of the caption, the more inter-correlated context information is required to determine it. However, current image captioning methods usually consider the generation of all words in a sentence sequentially and equally. In this paper, we propose an uncertainty-aware image captioning framework, which parallelly and iteratively operates insertion of discontinuous candidate words between existing words from easy to difficult until converged. We hypothesize that high-uncertainty words in a sentence need more prior information to make a correct decision and should be produced at a later stage. The resulting non-autoregressive hierarchy makes the caption generation explainable and intuitive. Specifically, we utilize an image-conditioned bag-of-word model to measure the word uncertainty and apply a dynamic programming algorithm to construct the training pairs. During inference, we devise an uncertainty-adaptive parallel beam search technique that yields an empirically logarithmic time complexity. Extensive experiments on the MS COCO benchmark reveal that our approach outperforms the strong baseline and related methods on both captioning quality as well as decoding speed.
FPGA Implementation of An Event-driven Saliency-based Selective Attention Model
Nov 25, 2022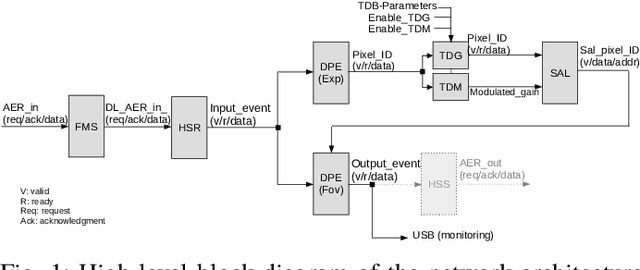
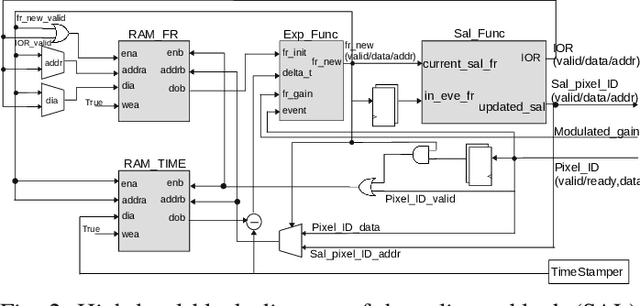
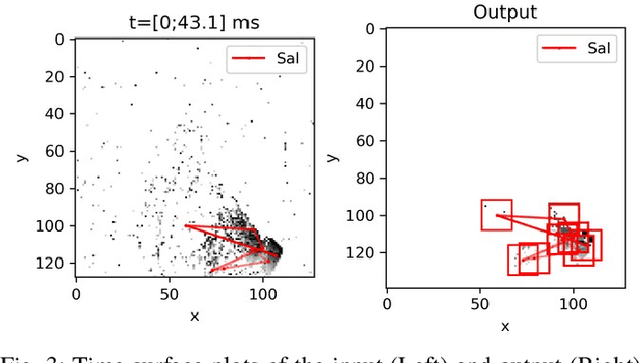
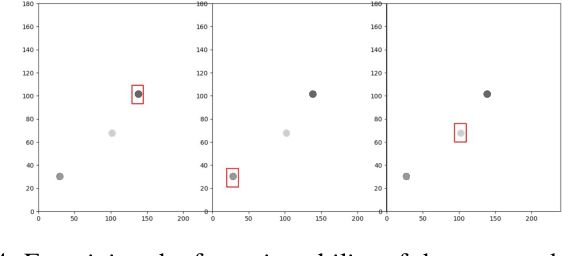
Artificial vision systems of autonomous agents face very difficult challenges, as their vision sensors are required to transmit vast amounts of information to the processing stages, and to process it in real-time. One first approach to reduce data transmission is to use event-based vision sensors, whose pixels produce events only when there are changes in the input. However, even for event-based vision, transmission and processing of visual data can be quite onerous. Currently, these challenges are solved by using high-speed communication links and powerful machine vision processing hardware. But if resources are limited, instead of processing all the sensory information in parallel, an effective strategy is to divide the visual field into several small sub-regions, choose the region of highest saliency, process it, and shift serially the focus of attention to regions of decreasing saliency. This strategy, commonly used also by the visual system of many animals, is typically referred to as ``selective attention''. Here we present a digital architecture implementing a saliency-based selective visual attention model for processing asynchronous event-based sensory information received from a DVS. For ease of prototyping, we use a standard digital design flow and map the architecture on an FPGA. We describe the architecture block diagram highlighting the efficient use of the available hardware resources demonstrated through experimental results exploiting a hardware setup where the FPGA interfaced with the DVS camera.
AugShuffleNet: Improve ShuffleNetV2 via More Information Communication
Mar 13, 2022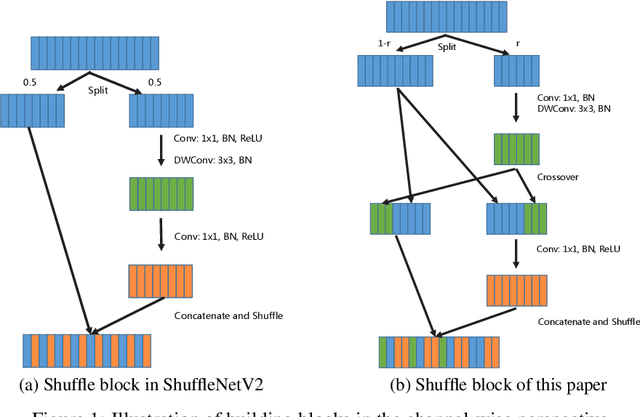
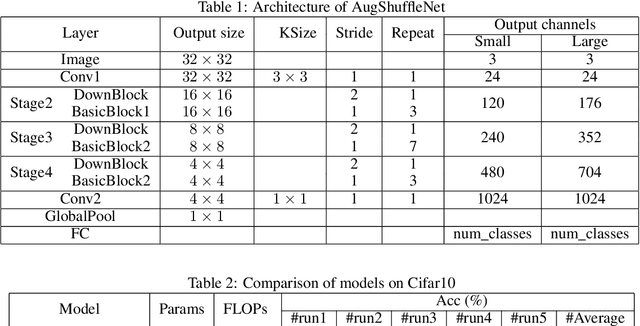


Based on ShuffleNetV2, we build a more powerful and efficient model family, termed as AugShuffleNets, by introducing higher frequency of cross-layer information communication for better model performance. Evaluated on the CIFAR-10 and CIFAR-100 datasets, AugShuffleNet consistently outperforms ShuffleNetV2 in terms of accuracy, with less computational cost, fewer parameter count.
Intelligent Surface Empowered Sensing and Communication: A Novel Mutual Assistance Design
Dec 25, 2022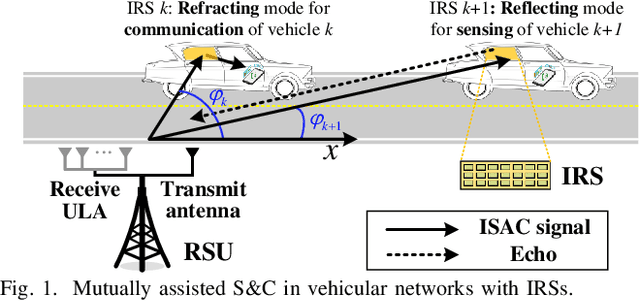
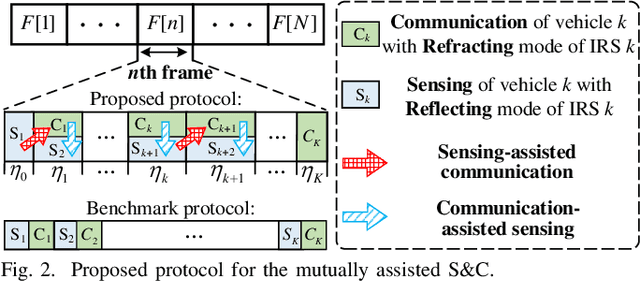
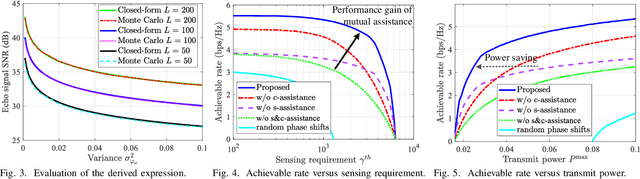
Integrated sensing and communication (ISAC) is a promising paradigm to provide both sensing and communication (S&C) services in vehicular networks. However, the power of echo signals reflected from vehicles may be too weak to be used for future precise positioning, due to the practically small radar cross section of vehicles with random reflection/scattering coefficient. To tackle this issue, we propose a novel mutual assistance scheme for intelligent surface-mounted vehicles, where S&C are innovatively designed to assist each other for achieving an efficient win-win integration, i.e., sensing-assisted phase shift design and communication-assisted high-precision sensing. Specifically, we first derive closed-form expressions of the echo power and achievable rate under uncertain angle information. Then, the communication rate is maximized while satisfying sensing requirements, which is proved to be a monotonic optimization problem on time allocation. Furthermore, we unveil the feasible condition of the problem and propose a polyblock-based optimal algorithm. Simulation results validate that the performance trade-off bound of S&C is significantly enlarged by the novel design exploiting mutual assistance in intelligent surface-aided vehicular networks.
GAE-ISumm: Unsupervised Graph-Based Summarization of Indian Languages
Dec 25, 2022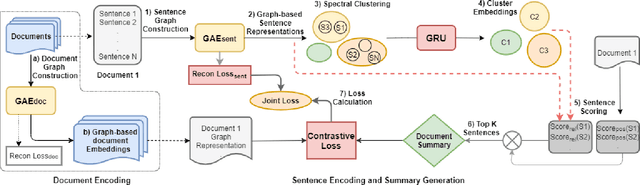
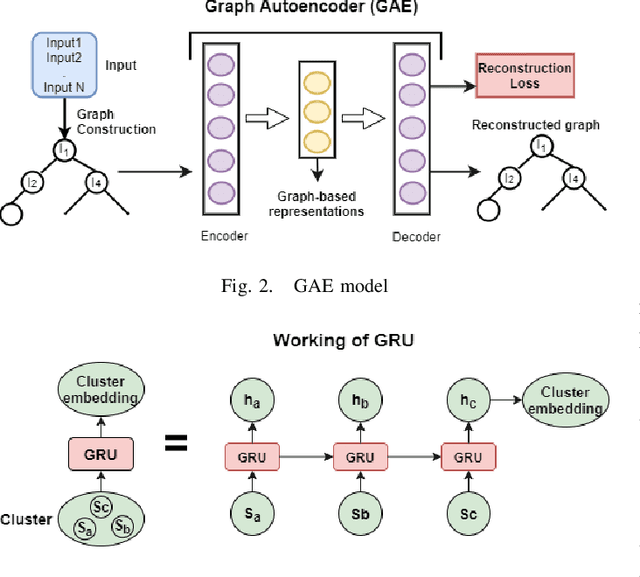
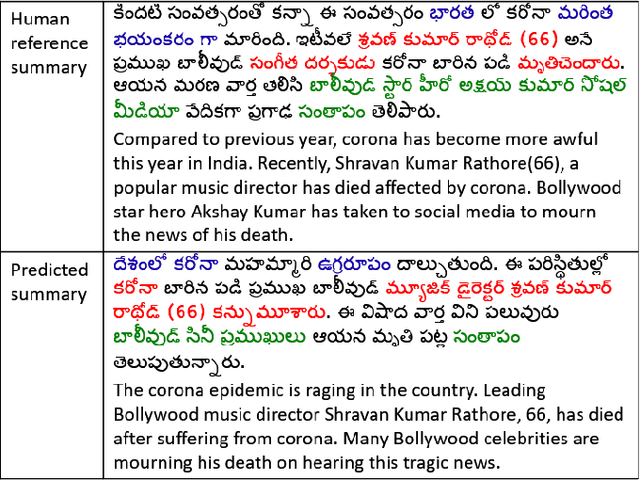
Document summarization aims to create a precise and coherent summary of a text document. Many deep learning summarization models are developed mainly for English, often requiring a large training corpus and efficient pre-trained language models and tools. However, English summarization models for low-resource Indian languages are often limited by rich morphological variation, syntax, and semantic differences. In this paper, we propose GAE-ISumm, an unsupervised Indic summarization model that extracts summaries from text documents. In particular, our proposed model, GAE-ISumm uses Graph Autoencoder (GAE) to learn text representations and a document summary jointly. We also provide a manually-annotated Telugu summarization dataset TELSUM, to experiment with our model GAE-ISumm. Further, we experiment with the most publicly available Indian language summarization datasets to investigate the effectiveness of GAE-ISumm on other Indian languages. Our experiments of GAE-ISumm in seven languages make the following observations: (i) it is competitive or better than state-of-the-art results on all datasets, (ii) it reports benchmark results on TELSUM, and (iii) the inclusion of positional and cluster information in the proposed model improved the performance of summaries.
A Generalization of ViT/MLP-Mixer to Graphs
Dec 27, 2022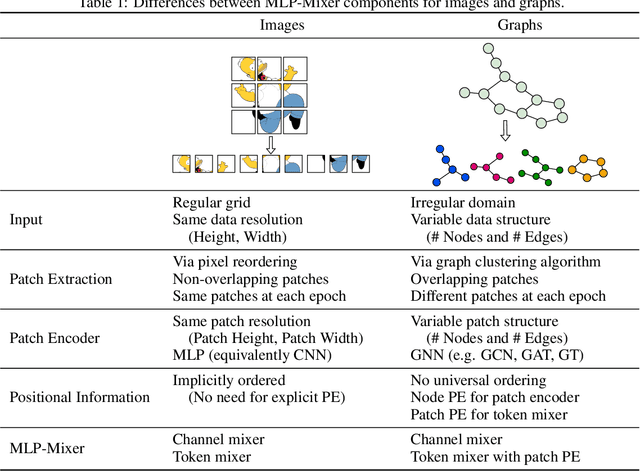
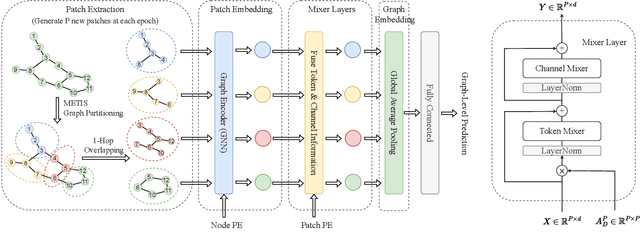
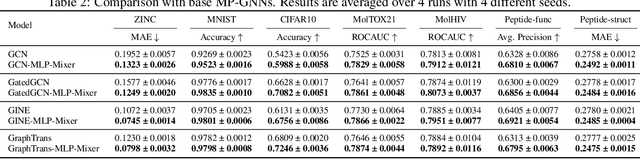
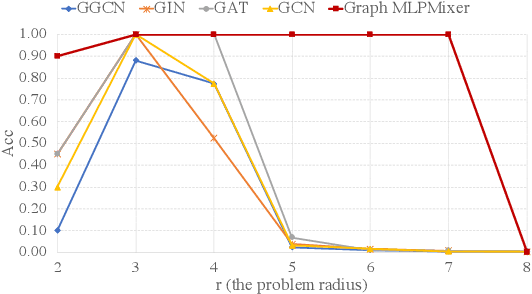
Graph Neural Networks (GNNs) have shown great potential in the field of graph representation learning. Standard GNNs define a local message-passing mechanism which propagates information over the whole graph domain by stacking multiple layers. This paradigm suffers from two major limitations, over-squashing and poor long-range dependencies, that can be solved using global attention but significantly increases the computational cost to quadratic complexity. In this work, we propose an alternative approach to overcome these structural limitations by leveraging the ViT/MLP-Mixer architectures introduced in computer vision. We introduce a new class of GNNs, called Graph MLP-Mixer, that holds three key properties. First, they capture long-range dependency and mitigate the issue of over-squashing as demonstrated on the Long Range Graph Benchmark (LRGB) and the TreeNeighbourMatch datasets. Second, they offer better speed and memory efficiency with a complexity linear to the number of nodes and edges, surpassing the related Graph Transformer and expressive GNN models. Third, they show high expressivity in terms of graph isomorphism as they can distinguish at least 3-WL non-isomorphic graphs. We test our architecture on 4 simulated datasets and 7 real-world benchmarks, and show highly competitive results on all of them.
MVTN: Learning Multi-View Transformations for 3D Understanding
Dec 27, 2022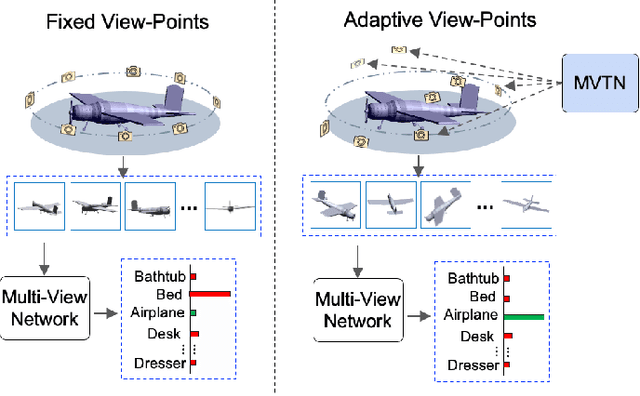
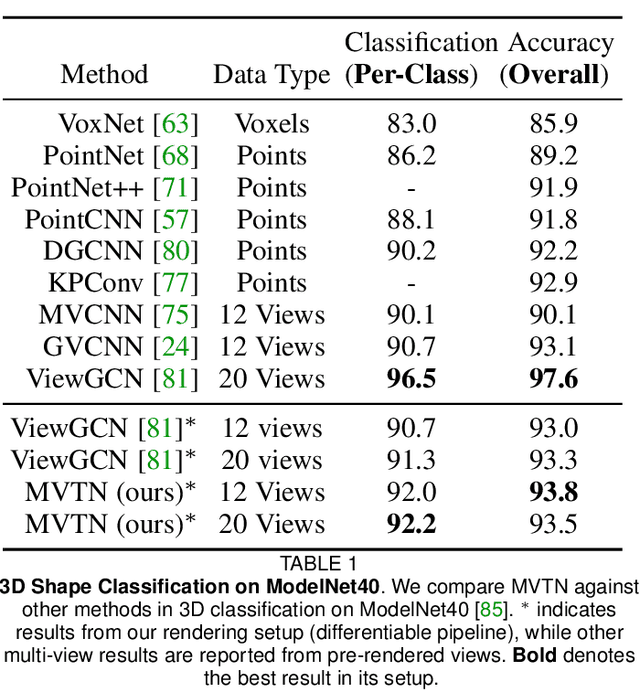
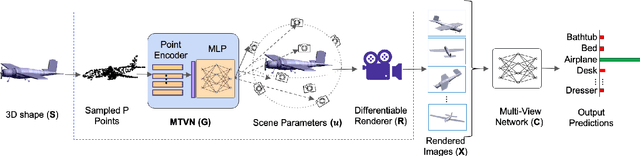
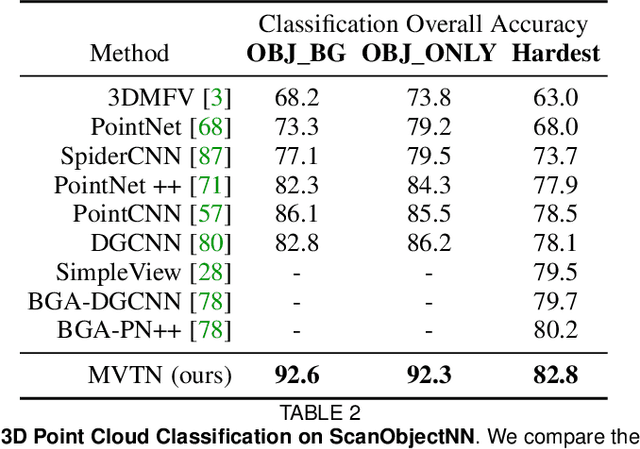
Multi-view projection techniques have shown themselves to be highly effective in achieving top-performing results in the recognition of 3D shapes. These methods involve learning how to combine information from multiple view-points. However, the camera view-points from which these views are obtained are often fixed for all shapes. To overcome the static nature of current multi-view techniques, we propose learning these view-points. Specifically, we introduce the Multi-View Transformation Network (MVTN), which uses differentiable rendering to determine optimal view-points for 3D shape recognition. As a result, MVTN can be trained end-to-end with any multi-view network for 3D shape classification. We integrate MVTN into a novel adaptive multi-view pipeline that is capable of rendering both 3D meshes and point clouds. Our approach demonstrates state-of-the-art performance in 3D classification and shape retrieval on several benchmarks (ModelNet40, ScanObjectNN, ShapeNet Core55). Further analysis indicates that our approach exhibits improved robustness to occlusion compared to other methods. We also investigate additional aspects of MVTN, such as 2D pretraining and its use for segmentation. To support further research in this area, we have released MVTorch, a PyTorch library for 3D understanding and generation using multi-view projections.
Semi-supervised multiscale dual-encoding method for faulty traffic data detection
Dec 27, 2022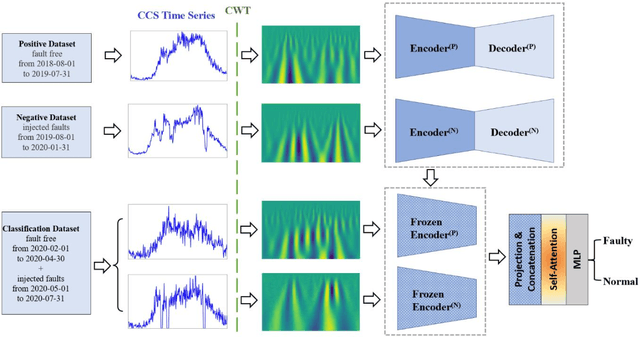
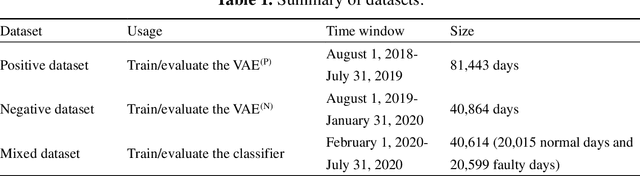
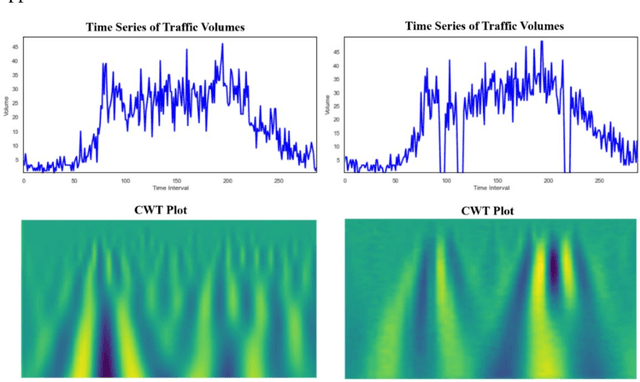
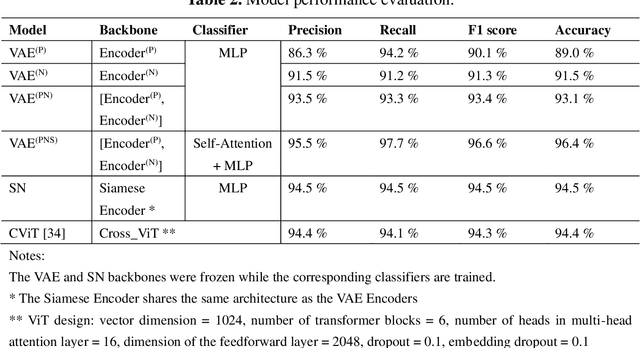
Inspired by the recent success of deep learning in multiscale information encoding, we introduce a variational autoencoder (VAE) based semi-supervised method for detection of faulty traffic data, which is cast as a classification problem. Continuous wavelet transform (CWT) is applied to the time series of traffic volume data to obtain rich features embodied in time-frequency representation, followed by a twin of VAE models to separately encode normal data and faulty data. The resulting multiscale dual encodings are concatenated and fed to an attention-based classifier, consisting of a self-attention module and a multilayer perceptron. For comparison, the proposed architecture is evaluated against five different encoding schemes, including (1) VAE with only normal data encoding, (2) VAE with only faulty data encoding, (3) VAE with both normal and faulty data encodings, but without attention module in the classifier, (4) siamese encoding, and (5) cross-vision transformer (CViT) encoding. The first four encoding schemes adopted the same convolutional neural network (CNN) architecture while the fifth encoding scheme follows the transformer architecture of CViT. Our experiments show that the proposed architecture with the dual encoding scheme, coupled with attention module, outperforms other encoding schemes and results in classification accuracy of 96.4%, precision of 95.5%, and recall of 97.7%.
* 16 pages, 8 figures
Semi-supervised Fashion Compatibility Prediction by Color Distortion Prediction
Dec 27, 2022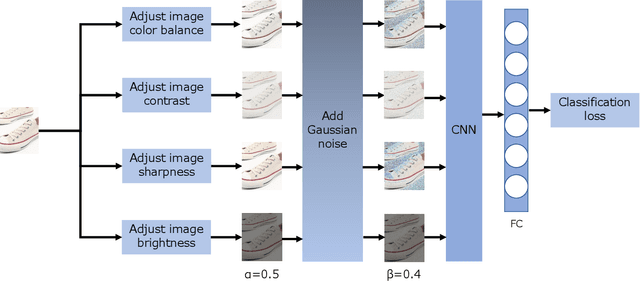
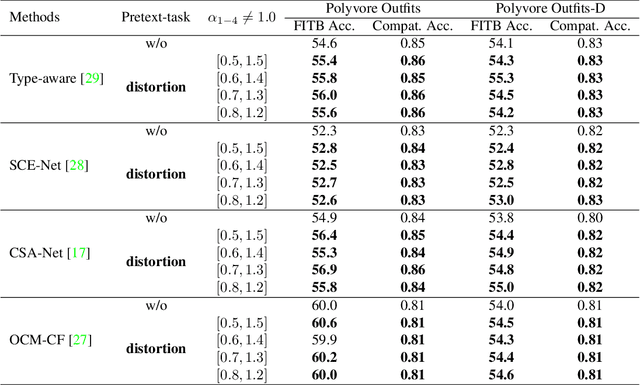

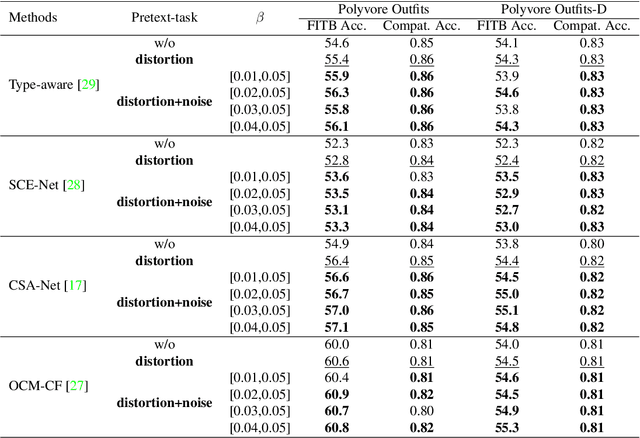
Supervised learning methods have been suffering from the fact that a large-scale labeled dataset is mandatory, which is difficult to obtain. This has been a more significant issue for fashion compatibility prediction because compatibility aims to capture people's perception of aesthetics, which are sparse and changing. Thus, the labeled dataset may become outdated quickly due to fast fashion. Moreover, labeling the dataset always needs some expert knowledge; at least they should have a good sense of aesthetics. However, there are limited self/semi-supervised learning techniques in this field. In this paper, we propose a general color distortion prediction task forcing the baseline to recognize low-level image information to learn more discriminative representation for fashion compatibility prediction. Specifically, we first propose to distort the image by adjusting the image color balance, contrast, sharpness, and brightness. Then, we propose adding Gaussian noise to the distorted image before passing them to the convolutional neural network (CNN) backbone to learn a probability distribution over all possible distortions. The proposed pretext task is adopted in the state-of-the-art methods in fashion compatibility and shows its effectiveness in improving these methods' ability in extracting better feature representations. Applying the proposed pretext task to the baseline can consistently outperform the original baseline.