 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
White-box Inference Attacks against Centralized Machine Learning and Federated Learning
Dec 15, 2022
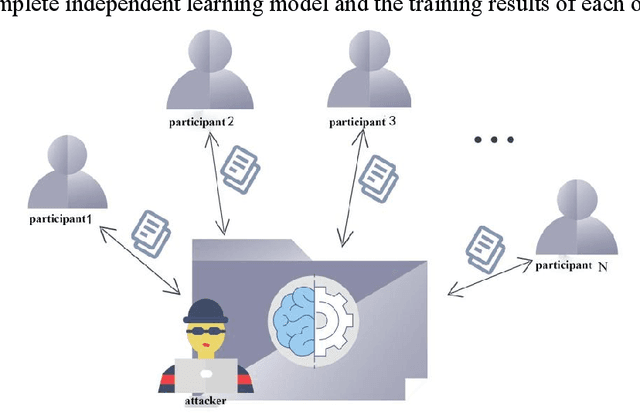

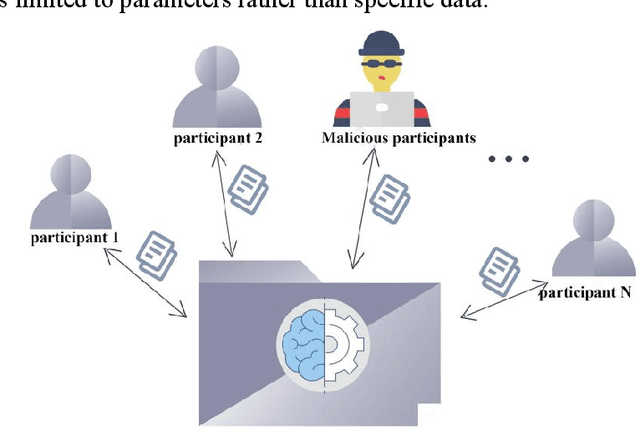

With the development of information science and technology, various industries have generated massive amounts of data, and machine learning is widely used in the analysis of big data. However, if the privacy of machine learning applications' customers cannot be guaranteed, it will cause security threats and losses to users' personal privacy information and service providers. Therefore, the issue of privacy protection of machine learning has received wide attention. For centralized machine learning models, we evaluate the impact of different neural network layers, gradient, gradient norm, and fine-tuned models on member inference attack performance with prior knowledge; For the federated learning model, we discuss the location of the attacker in the target model and its attack mode. The results show that the centralized machine learning model shows more serious member information leakage in all aspects, and the accuracy of the attacker in the central parameter server is significantly higher than the local Inference attacks as participants.
Is Semantic Communications Secure? A Tale of Multi-Domain Adversarial Attacks
Dec 20, 2022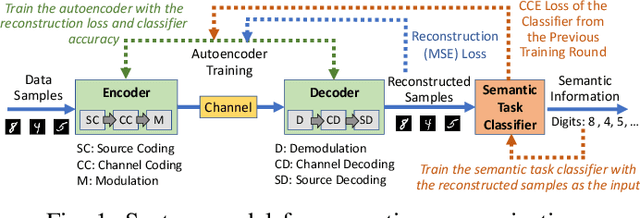
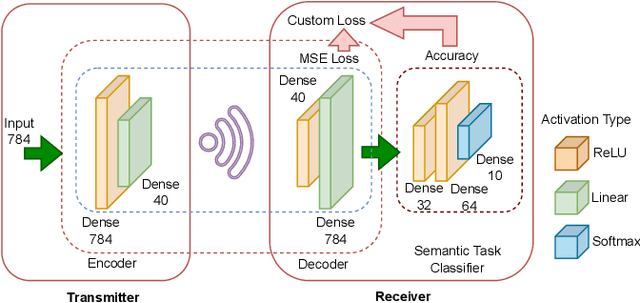
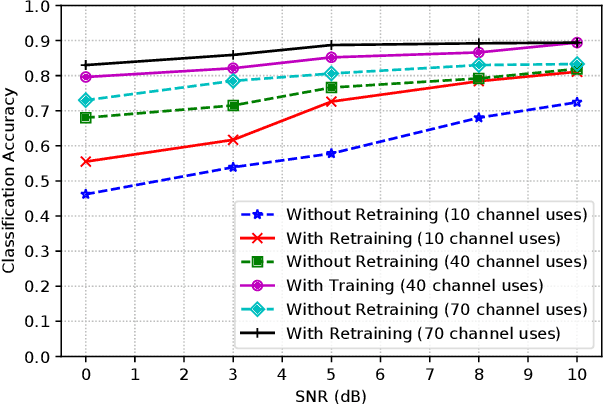
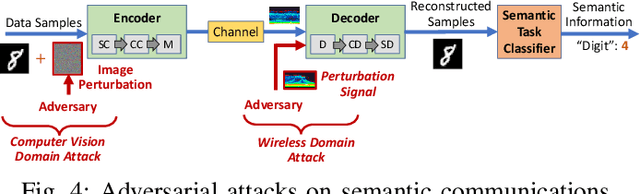
Semantic communications seeks to transfer information from a source while conveying a desired meaning to its destination. We model the transmitter-receiver functionalities as an autoencoder followed by a task classifier that evaluates the meaning of the information conveyed to the receiver. The autoencoder consists of an encoder at the transmitter to jointly model source coding, channel coding, and modulation, and a decoder at the receiver to jointly model demodulation, channel decoding and source decoding. By augmenting the reconstruction loss with a semantic loss, the two deep neural networks (DNNs) of this encoder-decoder pair are interactively trained with the DNN of the semantic task classifier. This approach effectively captures the latent feature space and reliably transfers compressed feature vectors with a small number of channel uses while keeping the semantic loss low. We identify the multi-domain security vulnerabilities of using the DNNs for semantic communications. Based on adversarial machine learning, we introduce test-time (targeted and non-targeted) adversarial attacks on the DNNs by manipulating their inputs at different stages of semantic communications. As a computer vision attack, small perturbations are injected to the images at the input of the transmitter's encoder. As a wireless attack, small perturbations signals are transmitted to interfere with the input of the receiver's decoder. By launching these stealth attacks individually or more effectively in a combined form as a multi-domain attack, we show that it is possible to change the semantics of the transferred information even when the reconstruction loss remains low. These multi-domain adversarial attacks pose as a serious threat to the semantics of information transfer (with larger impact than conventional jamming) and raise the need of defense methods for the safe adoption of semantic communications.
INFOrmation Prioritization through EmPOWERment in Visual Model-Based RL
Apr 18, 2022
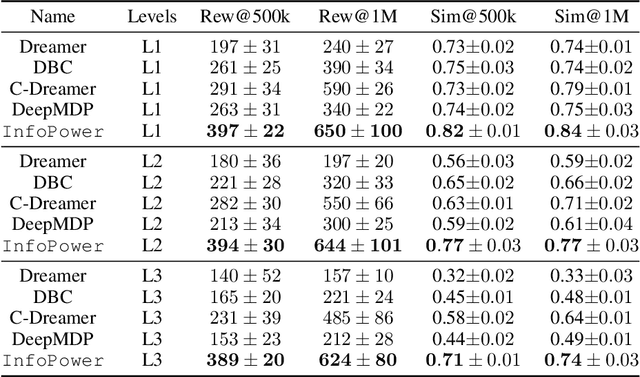
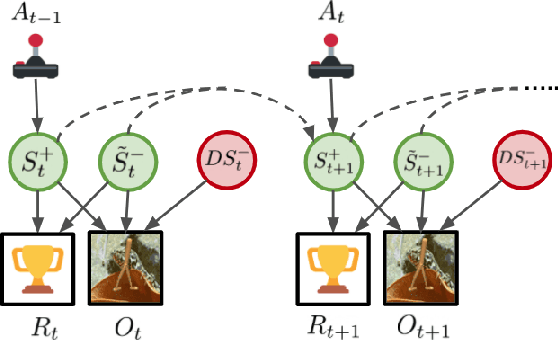
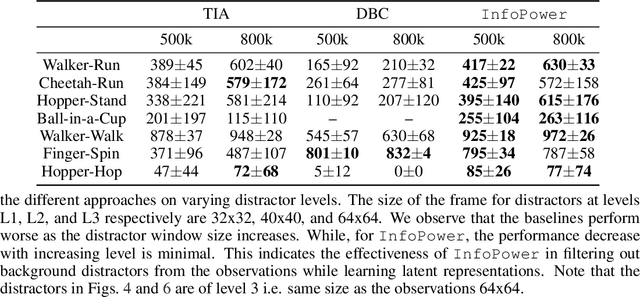
Model-based reinforcement learning (RL) algorithms designed for handling complex visual observations typically learn some sort of latent state representation, either explicitly or implicitly. Standard methods of this sort do not distinguish between functionally relevant aspects of the state and irrelevant distractors, instead aiming to represent all available information equally. We propose a modified objective for model-based RL that, in combination with mutual information maximization, allows us to learn representations and dynamics for visual model-based RL without reconstruction in a way that explicitly prioritizes functionally relevant factors. The key principle behind our design is to integrate a term inspired by variational empowerment into a state-space model based on mutual information. This term prioritizes information that is correlated with action, thus ensuring that functionally relevant factors are captured first. Furthermore, the same empowerment term also promotes faster exploration during the RL process, especially for sparse-reward tasks where the reward signal is insufficient to drive exploration in the early stages of learning. We evaluate the approach on a suite of vision-based robot control tasks with natural video backgrounds, and show that the proposed prioritized information objective outperforms state-of-the-art model based RL approaches with higher sample efficiency and episodic returns. https://sites.google.com/view/information-empowerment
FGAHOI: Fine-Grained Anchors for Human-Object Interaction Detection
Jan 08, 2023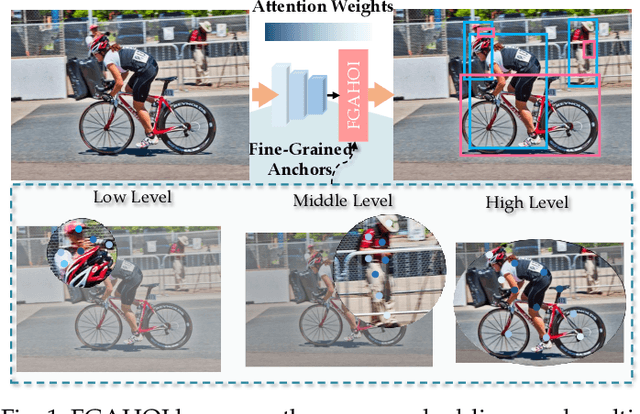
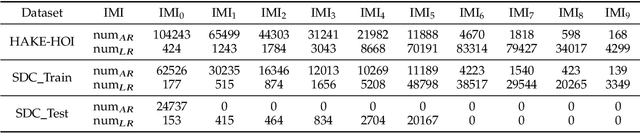

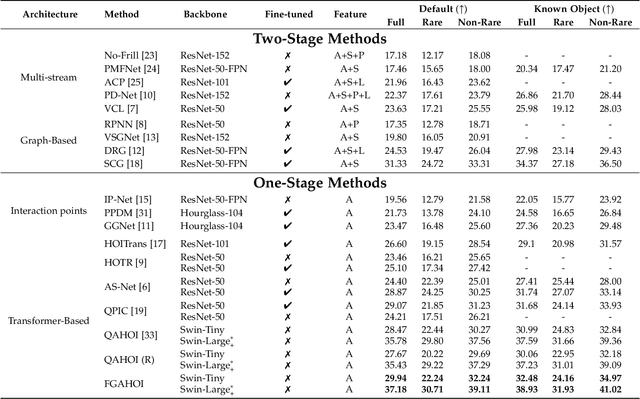
Human-Object Interaction (HOI), as an important problem in computer vision, requires locating the human-object pair and identifying the interactive relationships between them. The HOI instance has a greater span in spatial, scale, and task than the individual object instance, making its detection more susceptible to noisy backgrounds. To alleviate the disturbance of noisy backgrounds on HOI detection, it is necessary to consider the input image information to generate fine-grained anchors which are then leveraged to guide the detection of HOI instances. However, it is challenging for the following reasons. i) how to extract pivotal features from the images with complex background information is still an open question. ii) how to semantically align the extracted features and query embeddings is also a difficult issue. In this paper, a novel end-to-end transformer-based framework (FGAHOI) is proposed to alleviate the above problems. FGAHOI comprises three dedicated components namely, multi-scale sampling (MSS), hierarchical spatial-aware merging (HSAM) and task-aware merging mechanism (TAM). MSS extracts features of humans, objects and interaction areas from noisy backgrounds for HOI instances of various scales. HSAM and TAM semantically align and merge the extracted features and query embeddings in the hierarchical spatial and task perspectives in turn. In the meanwhile, a novel training strategy Stage-wise Training Strategy is designed to reduce the training pressure caused by overly complex tasks done by FGAHOI. In addition, we propose two ways to measure the difficulty of HOI detection and a novel dataset, i.e., HOI-SDC for the two challenges (Uneven Distributed Area in Human-Object Pairs and Long Distance Visual Modeling of Human-Object Pairs) of HOI instances detection.
Multi-Modal Domain Fusion for Multi-modal Aerial View Object Classification
Dec 14, 2022
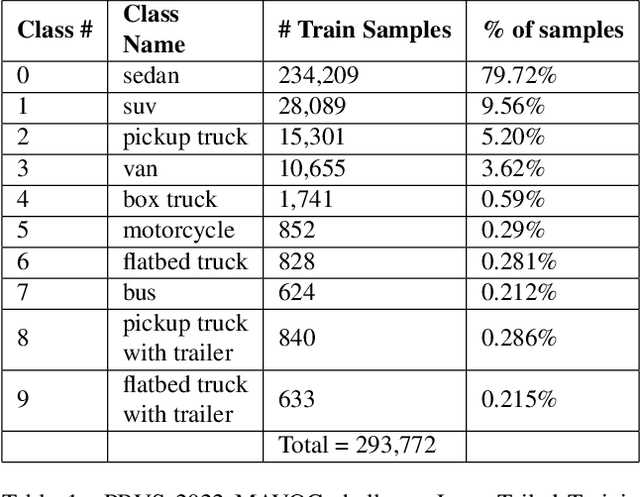
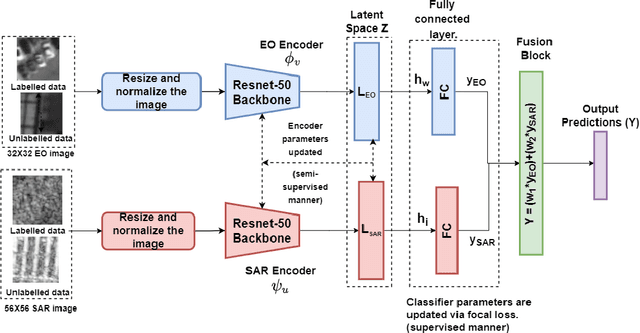
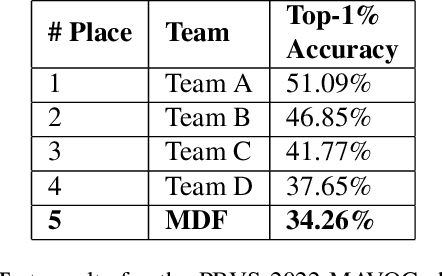
Object detection and classification using aerial images is a challenging task as the information regarding targets are not abundant. Synthetic Aperture Radar(SAR) images can be used for Automatic Target Recognition(ATR) systems as it can operate in all-weather conditions and in low light settings. But, SAR images contain salt and pepper noise(speckle noise) that cause hindrance for the deep learning models to extract meaningful features. Using just aerial view Electro-optical(EO) images for ATR systems may also not result in high accuracy as these images are of low resolution and also do not provide ample information in extreme weather conditions. Therefore, information from multiple sensors can be used to enhance the performance of Automatic Target Recognition(ATR) systems. In this paper, we explore a methodology to use both EO and SAR sensor information to effectively improve the performance of the ATR systems by handling the shortcomings of each of the sensors. A novel Multi-Modal Domain Fusion(MDF) network is proposed to learn the domain invariant features from multi-modal data and use it to accurately classify the aerial view objects. The proposed MDF network achieves top-10 performance in the Track-1 with an accuracy of 25.3 % and top-5 performance in Track-2 with an accuracy of 34.26 % in the test phase on the PBVS MAVOC Challenge dataset [18].
Quantifying Feature Contributions to Overall Disparity Using Information Theory
Jun 16, 2022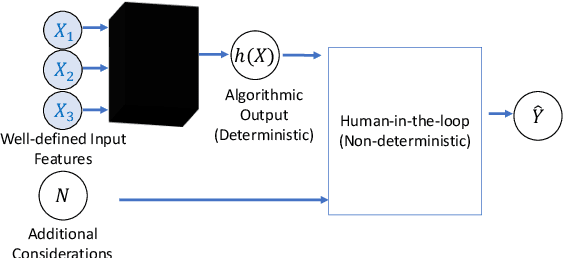
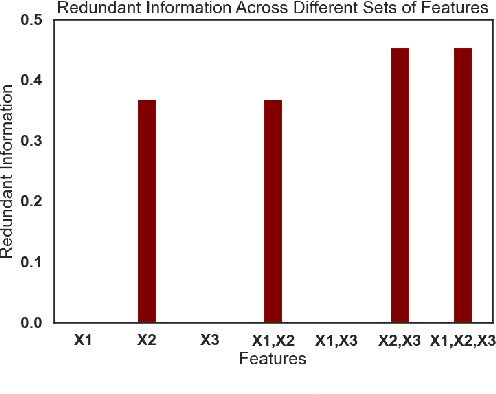
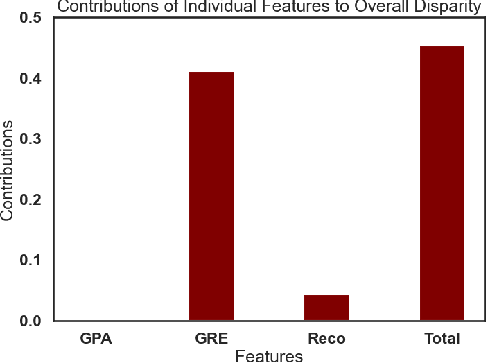
When a machine-learning algorithm makes biased decisions, it can be helpful to understand the sources of disparity to explain why the bias exists. Towards this, we examine the problem of quantifying the contribution of each individual feature to the observed disparity. If we have access to the decision-making model, one potential approach (inspired from intervention-based approaches in explainability literature) is to vary each individual feature (while keeping the others fixed) and use the resulting change in disparity to quantify its contribution. However, we may not have access to the model or be able to test/audit its outputs for individually varying features. Furthermore, the decision may not always be a deterministic function of the input features (e.g., with human-in-the-loop). For these situations, we might need to explain contributions using purely distributional (i.e., observational) techniques, rather than interventional. We ask the question: what is the "potential" contribution of each individual feature to the observed disparity in the decisions when the exact decision-making mechanism is not accessible? We first provide canonical examples (thought experiments) that help illustrate the difference between distributional and interventional approaches to explaining contributions, and when either is better suited. When unable to intervene on the inputs, we quantify the "redundant" statistical dependency about the protected attribute that is present in both the final decision and an individual feature, by leveraging a body of work in information theory called Partial Information Decomposition. We also perform a simple case study to show how this technique could be applied to quantify contributions.
Theoretical Understanding of the Information Flow on Continual Learning Performance
May 02, 2022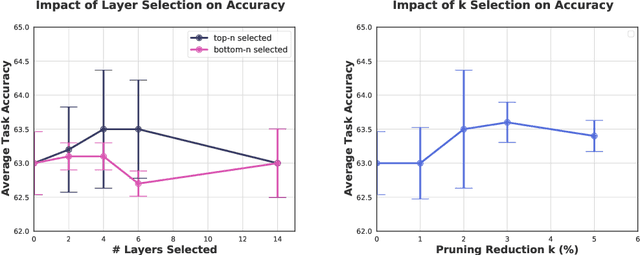
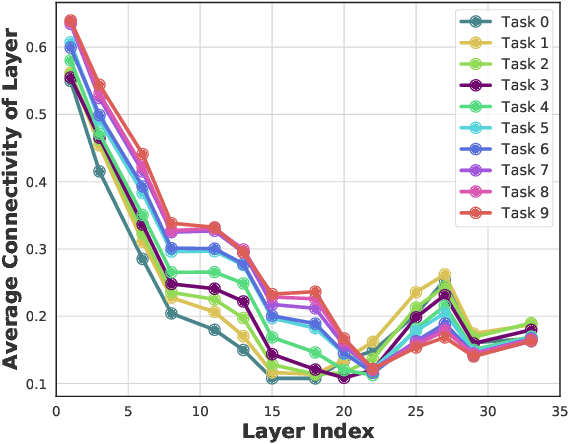
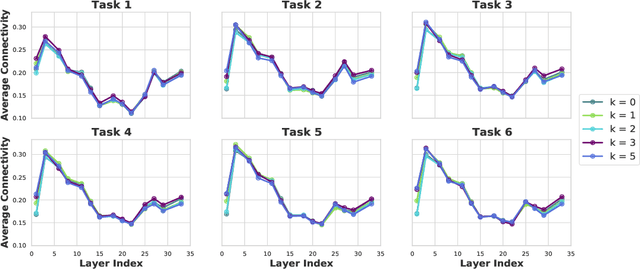
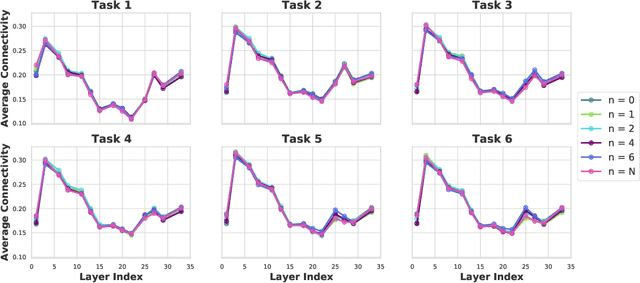
Continual learning (CL) is a setting in which an agent has to learn from an incoming stream of data sequentially. CL performance evaluates the model's ability to continually learn and solve new problems with incremental available information over time while retaining previous knowledge. Despite the numerous previous solutions to bypass the catastrophic forgetting (CF) of previously seen tasks during the learning process, most of them still suffer significant forgetting, expensive memory cost, or lack of theoretical understanding of neural networks' conduct while learning new tasks. While the issue that CL performance degrades under different training regimes has been extensively studied empirically, insufficient attention has been paid from a theoretical angle. In this paper, we establish a probabilistic framework to analyze information flow through layers in networks for task sequences and its impact on learning performance. Our objective is to optimize the information preservation between layers while learning new tasks to manage task-specific knowledge passing throughout the layers while maintaining model performance on previous tasks. In particular, we study CL performance's relationship with information flow in the network to answer the question "How can knowledge of information flow between layers be used to alleviate CF?". Our analysis provides novel insights of information adaptation within the layers during the incremental task learning process. Through our experiments, we provide empirical evidence and practically highlight the performance improvement across multiple tasks.
Doubly Adversarial Federated Bandits
Jan 22, 2023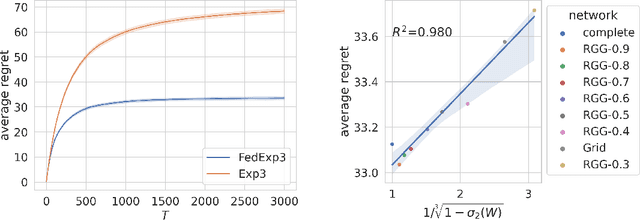
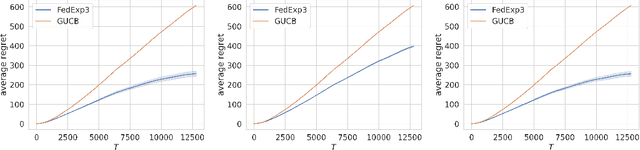
We study a new non-stochastic federated multi-armed bandit problem with multiple agents collaborating via a communication network. The losses of the arms are assigned by an oblivious adversary that specifies the loss of each arm not only for each time step but also for each agent, which we call ``doubly adversarial". In this setting, different agents may choose the same arm in the same time step but observe different feedback. The goal of each agent is to find a globally best arm in hindsight that has the lowest cumulative loss averaged over all agents, which necessities the communication among agents. We provide regret lower bounds for any federated bandit algorithm under different settings, when agents have access to full-information feedback, or the bandit feedback. For the bandit feedback setting, we propose a near-optimal federated bandit algorithm called FEDEXP3. Our algorithm gives a positive answer to an open question proposed in Cesa-Bianchi et al. (2016): FEDEXP3 can guarantee a sub-linear regret without exchanging sequences of selected arm identities or loss sequences among agents. We also provide numerical evaluations of our algorithm to validate our theoretical results and demonstrate its effectiveness on synthetic and real-world datasets
An Entropy-Based Model for Hierarchical Learning
Dec 30, 2022
Machine learning is the dominant approach to artificial intelligence, through which computers learn from data and experience. In the framework of supervised learning, for a computer to learn from data accurately and efficiently, some auxiliary information about the data distribution and target function should be provided to it through the learning model. This notion of auxiliary information relates to the concept of regularization in statistical learning theory. A common feature among real-world datasets is that data domains are multiscale and target functions are well-behaved and smooth. In this paper, we propose a learning model that exploits this multiscale data structure and discuss its statistical and computational benefits. The hierarchical learning model is inspired by the logical and progressive easy-to-hard learning mechanism of human beings and has interpretable levels. The model apportions computational resources according to the complexity of data instances and target functions. This property can have multiple benefits, including higher inference speed and computational savings in training a model for many users or when training is interrupted. We provide a statistical analysis of the learning mechanism using multiscale entropies and show that it can yield significantly stronger guarantees than uniform convergence bounds.
Information-theoretic Online Memory Selection for Continual Learning
Apr 10, 2022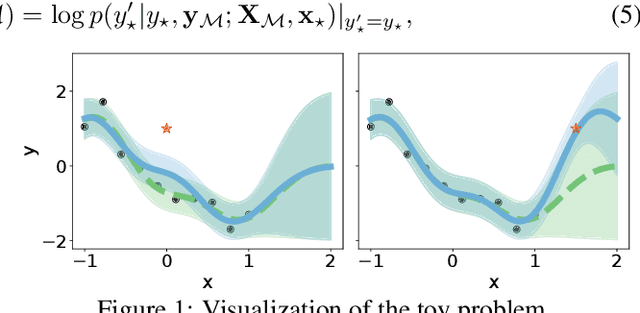
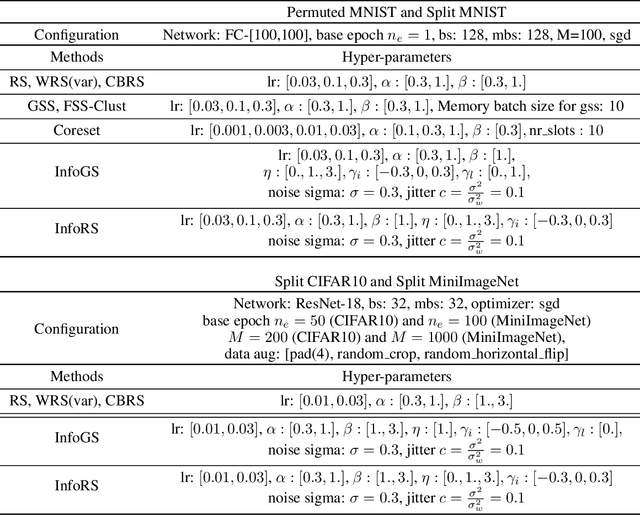
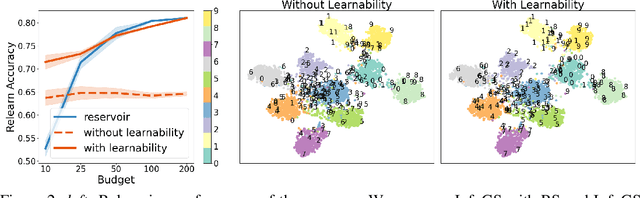
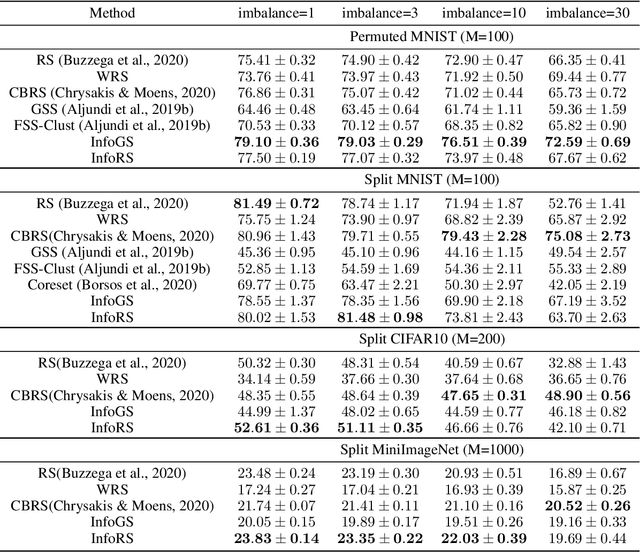
A challenging problem in task-free continual learning is the online selection of a representative replay memory from data streams. In this work, we investigate the online memory selection problem from an information-theoretic perspective. To gather the most information, we propose the \textit{surprise} and the \textit{learnability} criteria to pick informative points and to avoid outliers. We present a Bayesian model to compute the criteria efficiently by exploiting rank-one matrix structures. We demonstrate that these criteria encourage selecting informative points in a greedy algorithm for online memory selection. Furthermore, by identifying the importance of \textit{the timing to update the memory}, we introduce a stochastic information-theoretic reservoir sampler (InfoRS), which conducts sampling among selective points with high information. Compared to reservoir sampling, InfoRS demonstrates improved robustness against data imbalance. Finally, empirical performances over continual learning benchmarks manifest its efficiency and efficacy.