 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFGAHOI: Fine-Grained Anchors for Human-Object Interaction Detection
Paper and Code


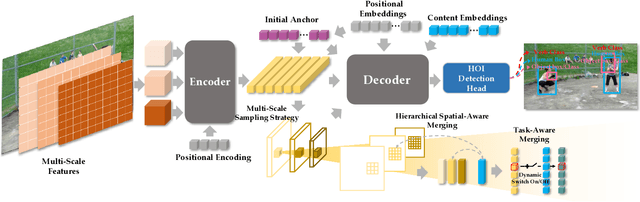

Human-Object Interaction (HOI), as an important problem in computer vision, requires locating the human-object pair and identifying the interactive relationships between them. The HOI instance has a greater span in spatial, scale, and task than the individual object instance, making its detection more susceptible to noisy backgrounds. To alleviate the disturbance of noisy backgrounds on HOI detection, it is necessary to consider the input image information to generate fine-grained anchors which are then leveraged to guide the detection of HOI instances. However, it is challenging for the following reasons. i) how to extract pivotal features from the images with complex background information is still an open question. ii) how to semantically align the extracted features and query embeddings is also a difficult issue. In this paper, a novel end-to-end transformer-based framework (FGAHOI) is proposed to alleviate the above problems. FGAHOI comprises three dedicated components namely, multi-scale sampling (MSS), hierarchical spatial-aware merging (HSAM) and task-aware merging mechanism (TAM). MSS extracts features of humans, objects and interaction areas from noisy backgrounds for HOI instances of various scales. HSAM and TAM semantically align and merge the extracted features and query embeddings in the hierarchical spatial and task perspectives in turn. In the meanwhile, a novel training strategy Stage-wise Training Strategy is designed to reduce the training pressure caused by overly complex tasks done by FGAHOI. In addition, we propose two ways to measure the difficulty of HOI detection and a novel dataset, i.e., HOI-SDC for the two challenges (Uneven Distributed Area in Human-Object Pairs and Long Distance Visual Modeling of Human-Object Pairs) of HOI instances detection.