 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A practical distributed active noise control algorithm overcoming communication restrictions
Mar 15, 2023
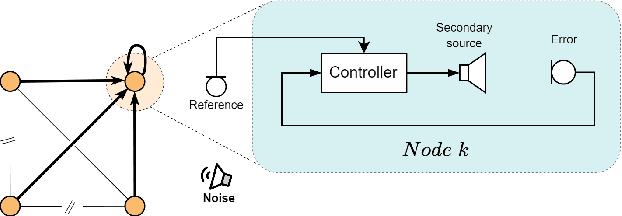
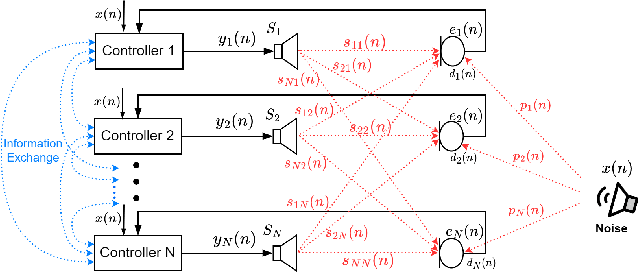
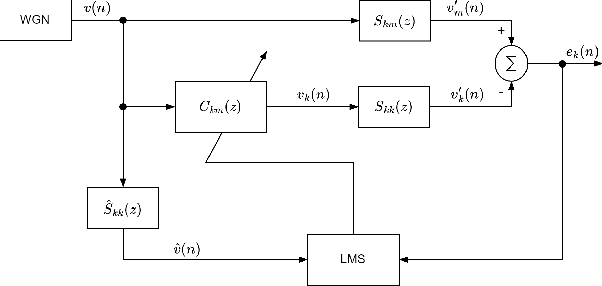
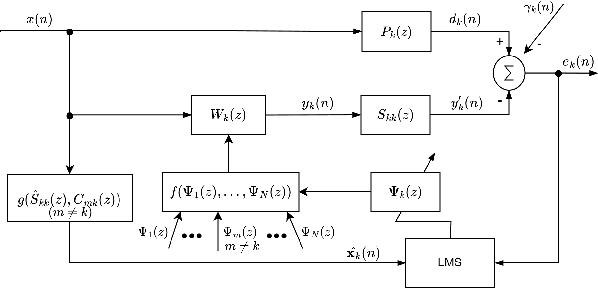
By assigning the massive computing tasks of the traditional multichannel active noise control (MCANC) system to several distributed control nodes, distributed multichannel active noise control (DMCANC) techniques have become effective global noise reduction solutions with low computational costs. However, existing DMCANC algorithms simply complete the distribution of traditional centralized algorithms by combining neighbour nodes' information but rarely consider the degraded control performance and system stability of distributed units caused by delays and interruptions in communication. Hence, this paper develops a novel DMCANC algorithm that utilizes the compensation filters and neighbour nodes' information to counterbalance the cross-talk effect between channels while maintaining independent weight updating. Since the neighbours' information required barely affects the local control filter updating in each node, this approach can tolerate communication delay and interruption to some extent. Numerical simulations demonstrate that the proposed algorithm can achieve satisfactory noise reduction performance and high robustness to real-world communication challenges.
DBLP-QuAD: A Question Answering Dataset over the DBLP Scholarly Knowledge Graph
Mar 29, 2023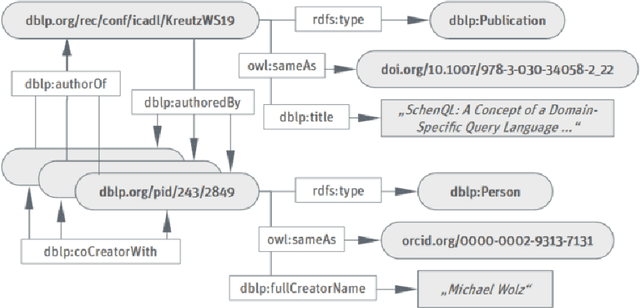
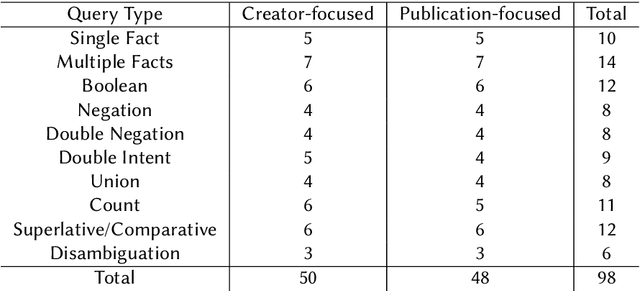
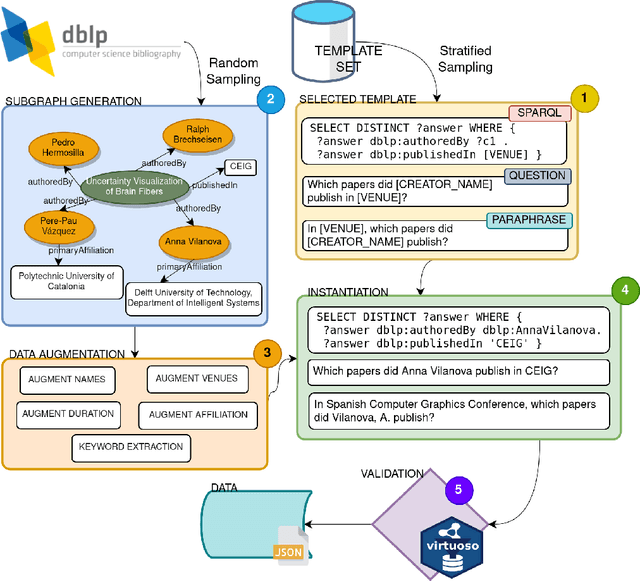

In this work we create a question answering dataset over the DBLP scholarly knowledge graph (KG). DBLP is an on-line reference for bibliographic information on major computer science publications that indexes over 4.4 million publications published by more than 2.2 million authors. Our dataset consists of 10,000 question answer pairs with the corresponding SPARQL queries which can be executed over the DBLP KG to fetch the correct answer. DBLP-QuAD is the largest scholarly question answering dataset.
MDAESF: Cine MRI Reconstruction Based on Motion-Guided Deformable Alignment and Efficient Spatiotemporal Self-Attention Fusion
Mar 09, 2023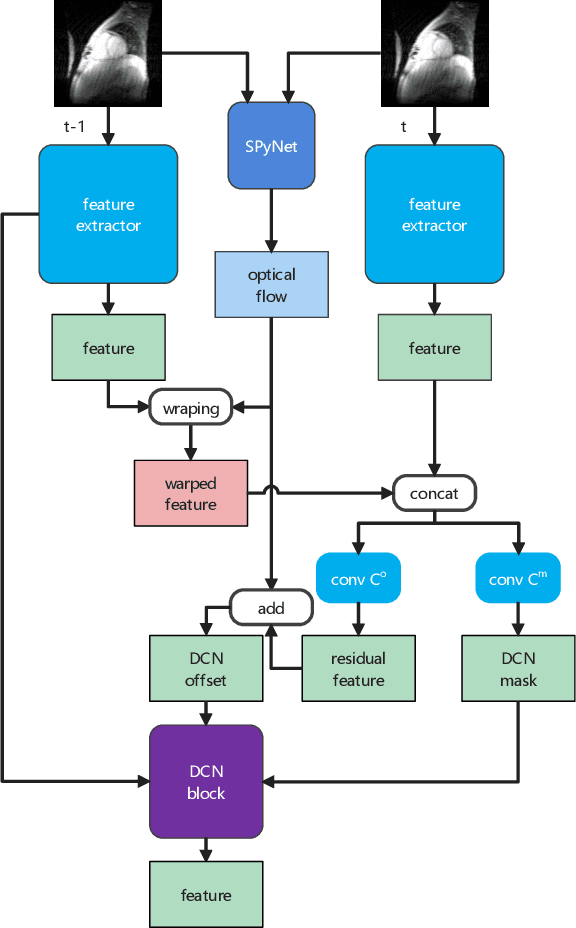

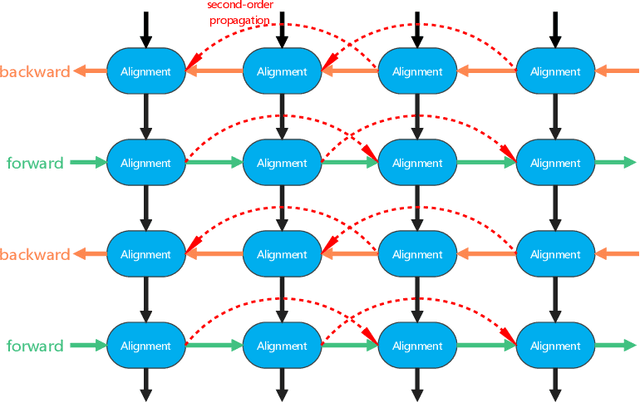

Cine MRI can jointly obtain the continuous influence of the anatomical structure and physiological and pathological mechanisms of organs in the two dimensions of time domain and space domain. Compared with ordinary two-dimensional static MRI images, the information in the time dimension of cine MRI contains many important information. But the information in the temporal dimension is not well utilized in past methods. To make full use of spatiotemporal information and reduce the influence of artifacts, this paper proposes a cine MRI reconstruction model based on second-order bidirectional propagation, motion-guided deformable alignment, and efficient spatiotemporal self-attention fusion. Compared to other advanced methods, our proposed method achieved better image reconstruction quality in terms of peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM) metrics as well as visual effects. The source code will be made available on https://github.com/GtLinyer/MDAESF.
On the Capacity Limits of Privileged ERM
Mar 05, 2023We study the supervised learning paradigm called Learning Using Privileged Information, first suggested by Vapnik and Vashist (2009). In this paradigm, in addition to the examples and labels, additional (privileged) information is provided only for training examples. The goal is to use this information to improve the classification accuracy of the resulting classifier, where this classifier can only use the non-privileged information of new example instances to predict their label. We study the theory of privileged learning with the zero-one loss under the natural Privileged ERM algorithm proposed in Pechyony and Vapnik (2010a). We provide a counter example to a claim made in that work regarding the VC dimension of the loss class induced by this problem; We conclude that the claim is incorrect. We then provide a correct VC dimension analysis which gives both lower and upper bounds on the capacity of the Privileged ERM loss class. We further show, via a generalization analysis, that worst-case guarantees for Privileged ERM cannot improve over standard non-privileged ERM, unless the capacity of the privileged information is similar or smaller to that of the non-privileged information. This result points to an important limitation of the Privileged ERM approach. In our closing discussion, we suggest another way in which Privileged ERM might still be helpful, even when the capacity of the privileged information is large.
Edge Ranking of Graphs in Transportation Networks using a Graph Neural Network (GNN)
Mar 25, 2023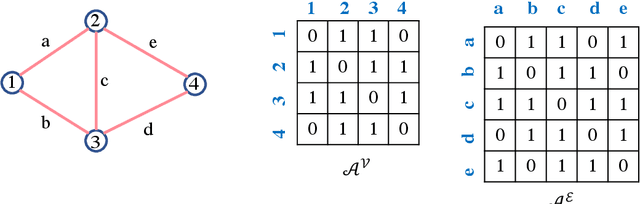
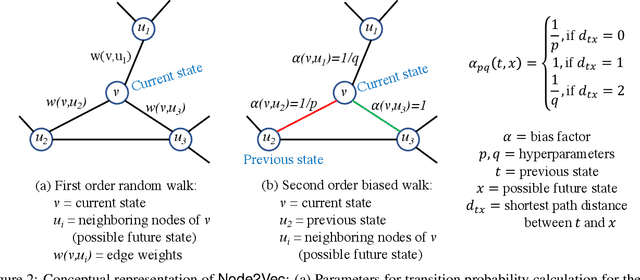
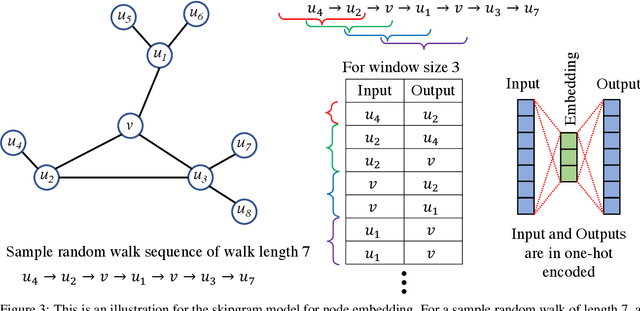
Many networks, such as transportation, power, and water distribution, can be represented as graphs. Crucial challenge in graph representations is identifying the importance of graph edges and their influence on overall network efficiency and information flow performance. For example, important edges in a transportation network are those roads that, when affected, will significantly alter the network's overall efficiency. Commonly used approach to finding such important edges is ``edge betweenness centrality'' (EBC), an edge ranking measure to determine the influential edges of the graph based on connectivity and information spread. Computing the EBC utilizing the common Brandes algorithm involves calculating the shortest paths for every node pair, which can be computationally expensive and restrictive, especially for large graphs. Changes in the graph parameters, e.g., in the edge weight or the addition and deletion of nodes or edges, require the recalculation of the EBC. As the main contribution, we propose an approximate method to estimate the EBC using a Graph Neural Network (GNN), a deep learning-based approach. We show that it is computationally efficient compared to the conventional method, especially for large graphs. The proposed method of GNN-based edge ranking is evaluated on several synthetic graphs and a real-world transportation data set. We show that this framework can estimate the approximate edge ranking much faster compared to the conventional method. This approach is inductive, i.e., training and testing are performed on different sets of graphs with varying numbers of nodes and edges. The proposed method is especially suitable for applications on large-scale networks when edge information is desired, for example, in urban infrastructure improvement projects, power, and water network resilience analyses, and optimizing resource allocations in engineering networks.
Topological Pooling on Graphs
Mar 25, 2023
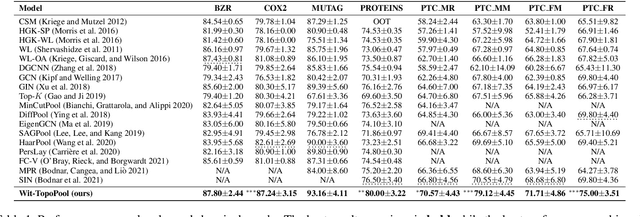
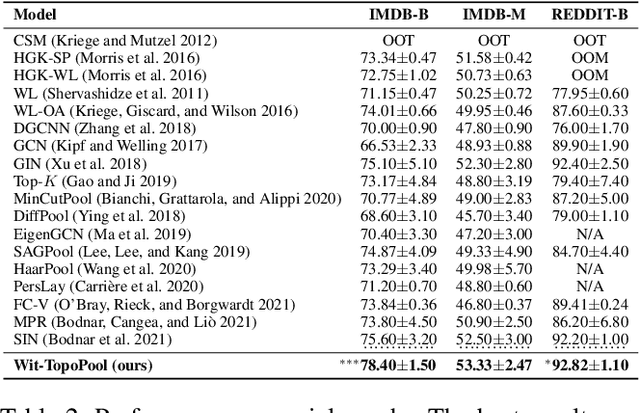
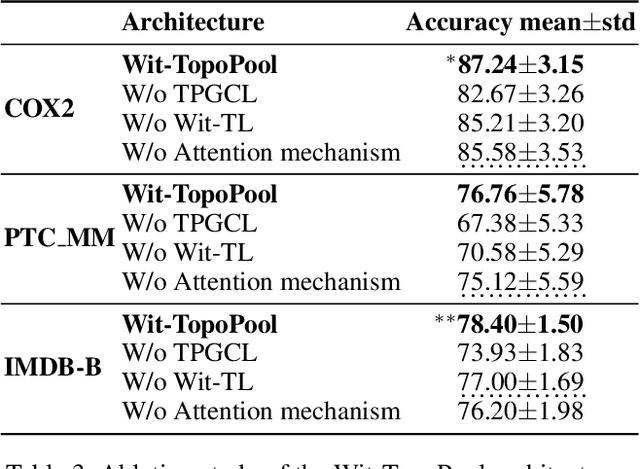
Graph neural networks (GNNs) have demonstrated a significant success in various graph learning tasks, from graph classification to anomaly detection. There recently has emerged a number of approaches adopting a graph pooling operation within GNNs, with a goal to preserve graph attributive and structural features during the graph representation learning. However, most existing graph pooling operations suffer from the limitations of relying on node-wise neighbor weighting and embedding, which leads to insufficient encoding of rich topological structures and node attributes exhibited by real-world networks. By invoking the machinery of persistent homology and the concept of landmarks, we propose a novel topological pooling layer and witness complex-based topological embedding mechanism that allow us to systematically integrate hidden topological information at both local and global levels. Specifically, we design new learnable local and global topological representations Wit-TopoPool which allow us to simultaneously extract rich discriminative topological information from graphs. Experiments on 11 diverse benchmark datasets against 18 baseline models in conjunction with graph classification tasks indicate that Wit-TopoPool significantly outperforms all competitors across all datasets.
Learning with Explanation Constraints
Mar 25, 2023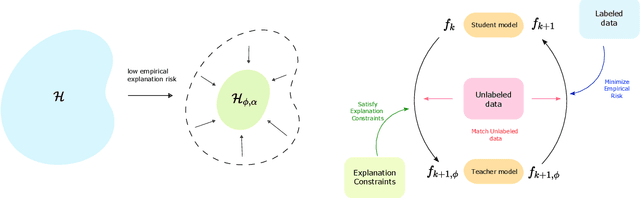
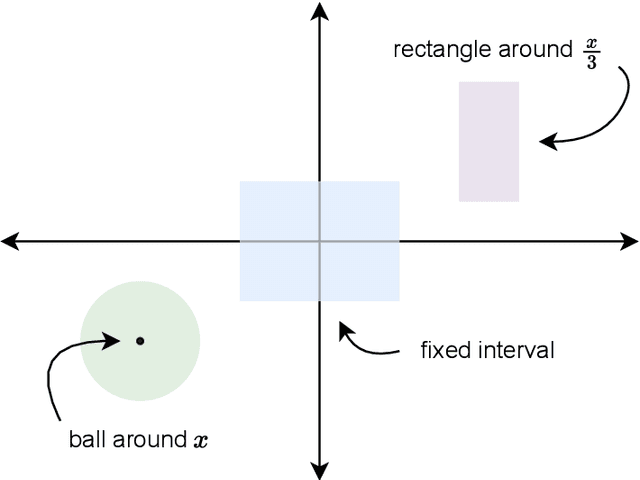
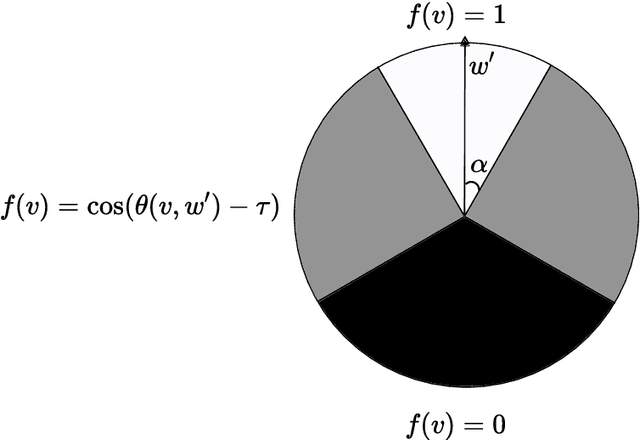
While supervised learning assumes the presence of labeled data, we may have prior information about how models should behave. In this paper, we formalize this notion as learning from explanation constraints and provide a learning theoretic framework to analyze how such explanations can improve the learning of our models. For what models would explanations be helpful? Our first key contribution addresses this question via the definition of what we call EPAC models (models that satisfy these constraints in expectation over new data), and we analyze this class of models using standard learning theoretic tools. Our second key contribution is to characterize these restrictions (in terms of their Rademacher complexities) for a canonical class of explanations given by gradient information for linear models and two layer neural networks. Finally, we provide an algorithmic solution for our framework, via a variational approximation that achieves better performance and satisfies these constraints more frequently, when compared to simpler augmented Lagrangian methods to incorporate these explanations. We demonstrate the benefits of our approach over a large array of synthetic and real-world experiments.
Speck: A Smart event-based Vision Sensor with a low latency 327K Neuron Convolutional Neuronal Network Processing Pipeline
Apr 13, 2023
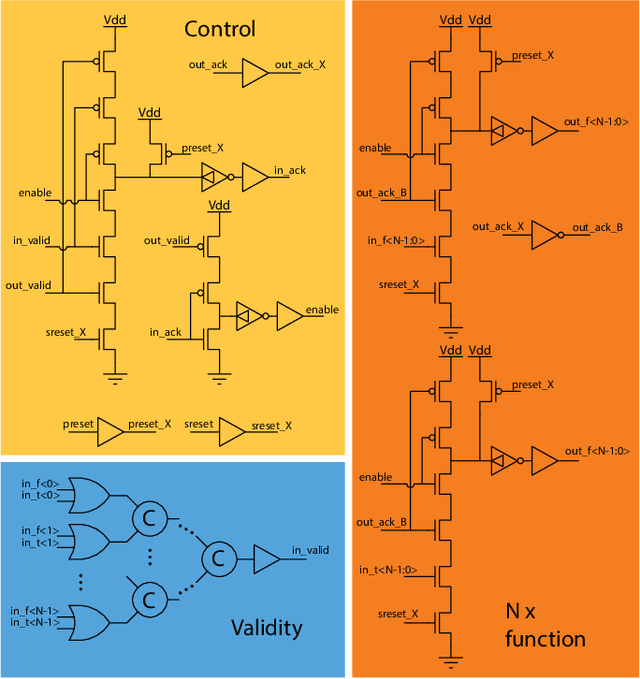
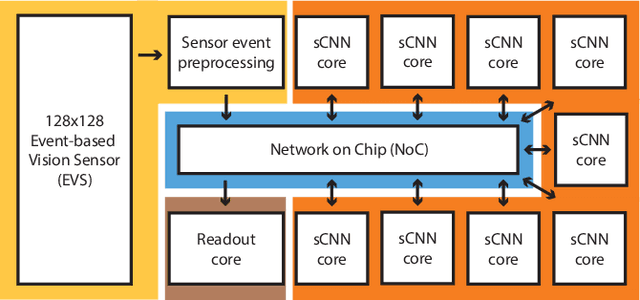
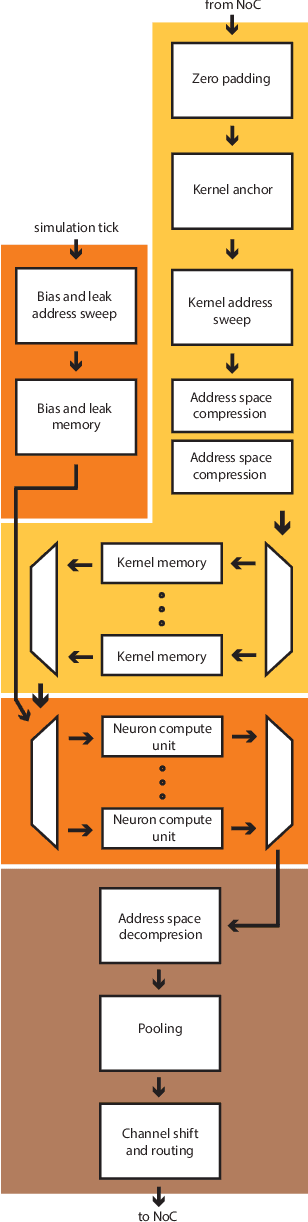
Edge computing solutions that enable the extraction of high level information from a variety of sensors is in increasingly high demand. This is due to the increasing number of smart devices that require sensory processing for their application on the edge. To tackle this problem, we present a smart vision sensor System on Chip (Soc), featuring an event-based camera and a low power asynchronous spiking Convolutional Neuronal Network (sCNN) computing architecture embedded on a single chip. By combining both sensor and processing on a single die, we can lower unit production costs significantly. Moreover, the simple end-to-end nature of the SoC facilitates small stand-alone applications as well as functioning as an edge node in a larger systems. The event-driven nature of the vision sensor delivers high-speed signals in a sparse data stream. This is reflected in the processing pipeline, focuses on optimising highly sparse computation and minimising latency for 9 sCNN layers to $3.36\mu s$. Overall, this results in an extremely low-latency visual processing pipeline deployed on a small form factor with a low energy budget and sensor cost. We present the asynchronous architecture, the individual blocks, the sCNN processing principle and benchmark against other sCNN capable processors.
ODAM: Gradient-based instance-specific visual explanations for object detection
Apr 13, 2023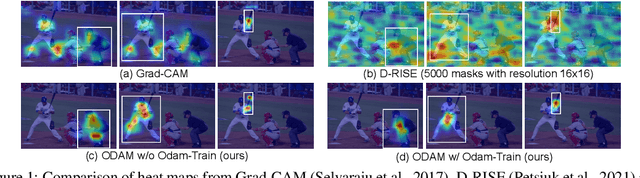
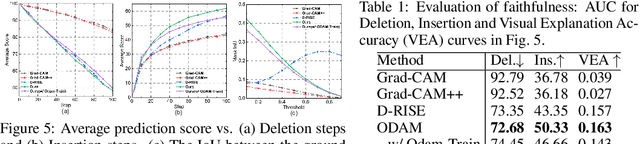
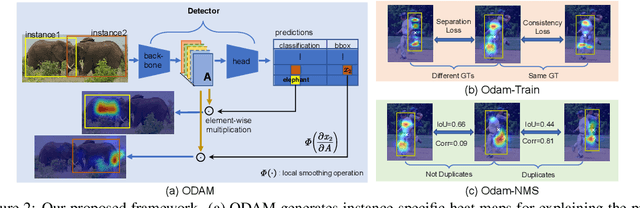

We propose the gradient-weighted Object Detector Activation Maps (ODAM), a visualized explanation technique for interpreting the predictions of object detectors. Utilizing the gradients of detector targets flowing into the intermediate feature maps, ODAM produces heat maps that show the influence of regions on the detector's decision for each predicted attribute. Compared to previous works classification activation maps (CAM), ODAM generates instance-specific explanations rather than class-specific ones. We show that ODAM is applicable to both one-stage detectors and two-stage detectors with different types of detector backbones and heads, and produces higher-quality visual explanations than the state-of-the-art both effectively and efficiently. We next propose a training scheme, Odam-Train, to improve the explanation ability on object discrimination of the detector through encouraging consistency between explanations for detections on the same object, and distinct explanations for detections on different objects. Based on the heat maps produced by ODAM with Odam-Train, we propose Odam-NMS, which considers the information of the model's explanation for each prediction to distinguish the duplicate detected objects. We present a detailed analysis of the visualized explanations of detectors and carry out extensive experiments to validate the effectiveness of the proposed ODAM.
Gated Multi-Resolution Transfer Network for Burst Restoration and Enhancement
Apr 13, 2023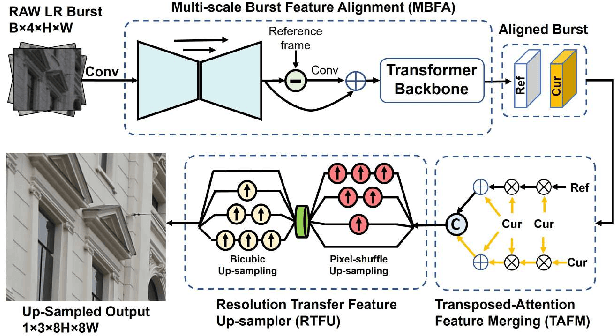
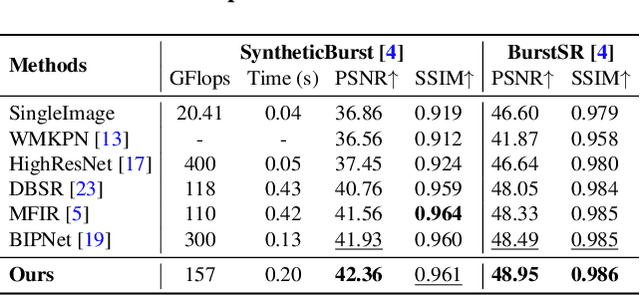
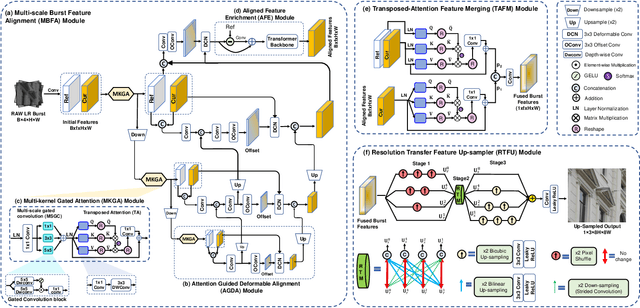
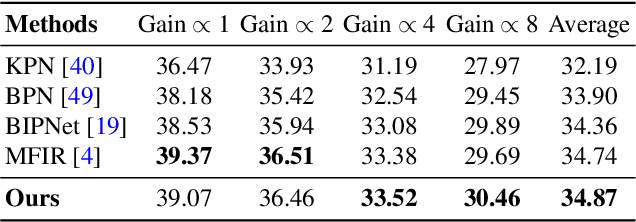
Burst image processing is becoming increasingly popular in recent years. However, it is a challenging task since individual burst images undergo multiple degradations and often have mutual misalignments resulting in ghosting and zipper artifacts. Existing burst restoration methods usually do not consider the mutual correlation and non-local contextual information among burst frames, which tends to limit these approaches in challenging cases. Another key challenge lies in the robust up-sampling of burst frames. The existing up-sampling methods cannot effectively utilize the advantages of single-stage and progressive up-sampling strategies with conventional and/or recent up-samplers at the same time. To address these challenges, we propose a novel Gated Multi-Resolution Transfer Network (GMTNet) to reconstruct a spatially precise high-quality image from a burst of low-quality raw images. GMTNet consists of three modules optimized for burst processing tasks: Multi-scale Burst Feature Alignment (MBFA) for feature denoising and alignment, Transposed-Attention Feature Merging (TAFM) for multi-frame feature aggregation, and Resolution Transfer Feature Up-sampler (RTFU) to up-scale merged features and construct a high-quality output image. Detailed experimental analysis on five datasets validates our approach and sets a state-of-the-art for burst super-resolution, burst denoising, and low-light burst enhancement.