 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towards Better Domain Adaptation for Self-supervised Models: A Case Study of Child ASR
Apr 28, 2023
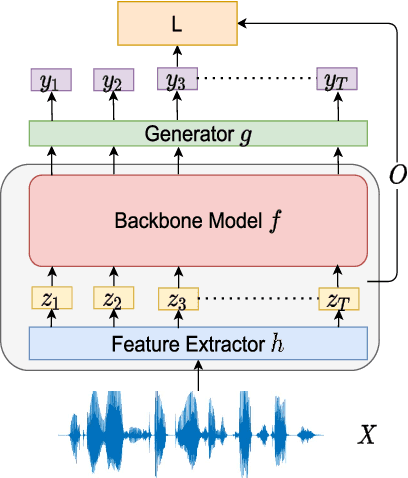
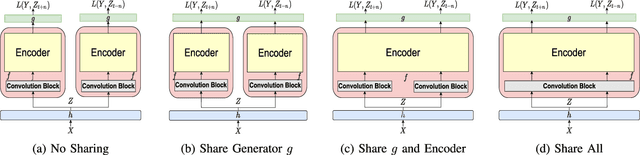
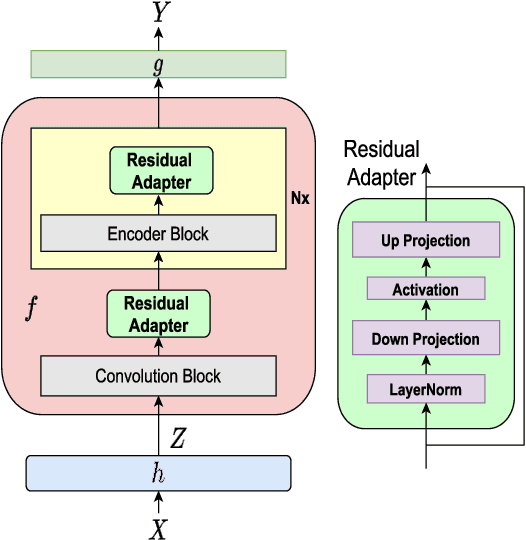
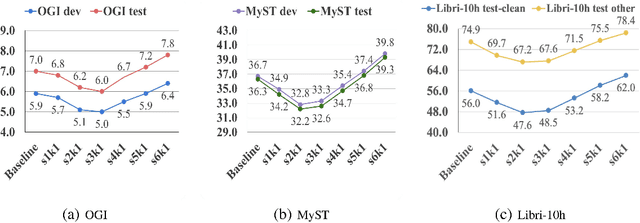
Recently, self-supervised learning (SSL) from unlabelled speech data has gained increased attention in the automatic speech recognition (ASR) community. Typical SSL methods include autoregressive predictive coding (APC), Wav2vec2.0, and hidden unit BERT (HuBERT). However, SSL models are biased to the pretraining data. When SSL models are finetuned with data from another domain, domain shifting occurs and might cause limited knowledge transfer for downstream tasks. In this paper, we propose a novel framework, domain responsible adaptation and finetuning (DRAFT), to reduce domain shifting in pretrained speech models, and evaluate it for a causal and non-causal transformer. For the causal transformer, an extension of APC (E-APC) is proposed to learn richer information from unlabelled data by using multiple temporally-shifted sequences to perform prediction. For the non-causal transformer, various solutions for using the bidirectional APC (Bi-APC) are investigated. In addition, the DRAFT framework is examined for Wav2vec2.0 and HuBERT methods, which use non-causal transformers as the backbone. The experiments are conducted on child ASR (using the OGI and MyST databases) using SSL models trained with unlabelled adult speech data from Librispeech. The relative WER improvements of up to 19.7% on the two child tasks are observed when compared to the pretrained models without adaptation. With the proposed methods (E-APC and DRAFT), the relative WER improvements are even larger (30% and 19% on the OGI and MyST data, respectively) when compared to the models without using pretraining methods.
Predicting blood pressure under circumstances of missing data: An analysis of missing data patterns and imputation methods using NHANES
May 01, 2023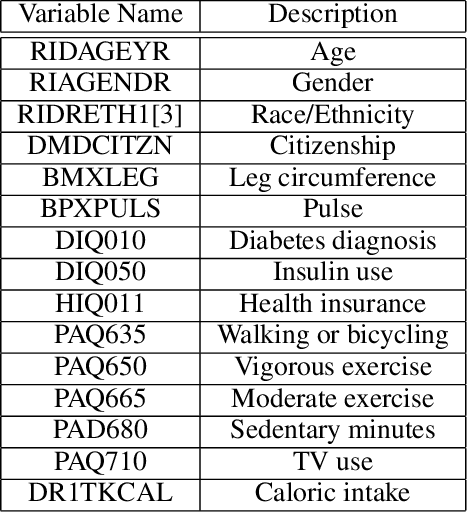
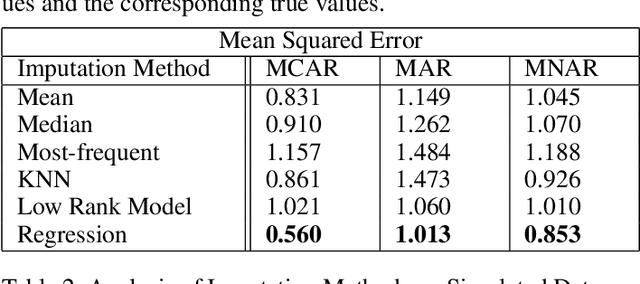
The World Health Organization defines cardio-vascular disease (CVD) as "a group of disorders of the heart and blood vessels," including coronary heart disease and stroke (WHO 21). CVD is affected by "intermediate risk factors" such as raised blood pressure, raised blood glucose, raised blood lipids, and obesity. These are predominantly influenced by lifestyle and behaviour, including physical inactivity, unhealthy diets, high intake of salt, and tobacco and alcohol use. However, genetics and social/environmental factors such as poverty, stress, and racism also play an important role. Researchers studying the behavioural and environmental factors associated with these "intermediate risk factors" need access to high quality and detailed information on diet and physical activity. However, missing data are a pervasive problem in clinical and public health research, affecting both randomized trials and observational studies. Reasons for missing data can vary substantially across studies because of loss to follow-up, missed study visits, refusal to answer survey questions, or an unrecorded measurement during an office visit. One method of handling missing values is to simply delete observations for which there is missingness (called Complete Case Analysis). This is rarely used as deleting the data point containing missing data (List wise deletion) results in a smaller number of samples and thus affects accuracy. Additional methods of handling missing data exists, such as summarizing the variables with its observed values (Available Case Analysis). Motivated by the pervasiveness of missing data in the NHANES dataset, we will conduct an analysis of imputation methods under different simulated patterns of missing data. We will then apply these imputation methods to create a complete dataset upon which we can use ordinary least squares to predict blood pressure from diet and physical activity.
Automated Static Camera Calibration with Intelligent Vehicles
Apr 21, 2023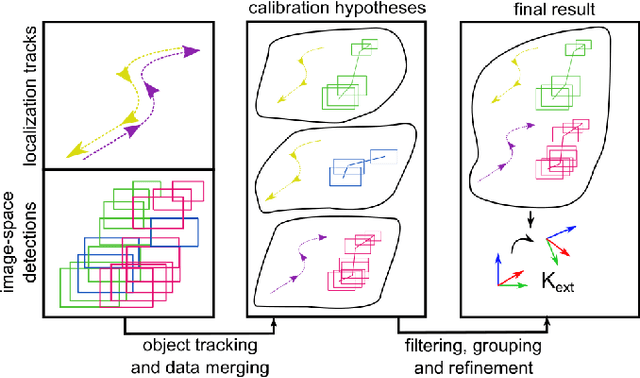
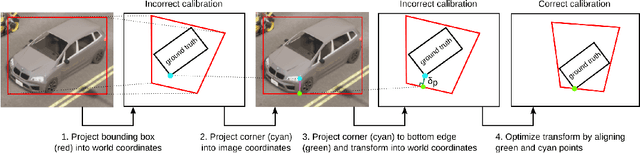
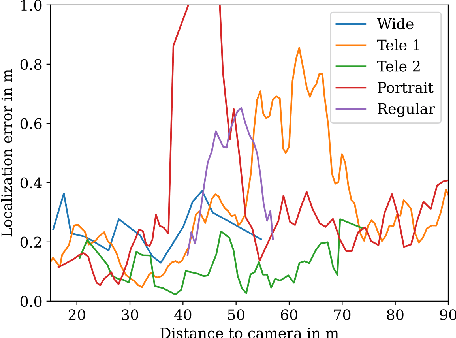
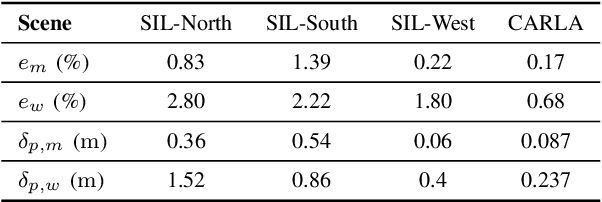
Connected and cooperative driving requires precise calibration of the roadside infrastructure for having a reliable perception system. To solve this requirement in an automated manner, we present a robust extrinsic calibration method for automated geo-referenced camera calibration. Our method requires a calibration vehicle equipped with a combined GNSS/RTK receiver and an inertial measurement unit (IMU) for self-localization. In order to remove any requirements for the target's appearance and the local traffic conditions, we propose a novel approach using hypothesis filtering. Our method does not require any human interaction with the information recorded by both the infrastructure and the vehicle. Furthermore, we do not limit road access for other road users during calibration. We demonstrate the feasibility and accuracy of our approach by evaluating our approach on synthetic datasets as well as a real-world connected intersection, and deploying the calibration on real infrastructure. Our source code is publicly available.
Deep Multiview Clustering by Contrasting Cluster Assignments
Apr 21, 2023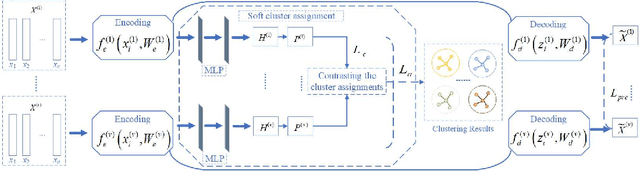
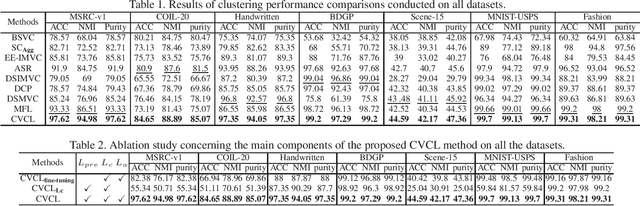
Multiview clustering (MVC) aims to reveal the underlying structure of multiview data by categorizing data samples into clusters. Deep learning-based methods exhibit strong feature learning capabilities on large-scale datasets. For most existing deep MVC methods, exploring the invariant representations of multiple views is still an intractable problem. In this paper, we propose a cross-view contrastive learning (CVCL) method that learns view-invariant representations and produces clustering results by contrasting the cluster assignments among multiple views. Specifically, we first employ deep autoencoders to extract view-dependent features in the pretraining stage. Then, a cluster-level CVCL strategy is presented to explore consistent semantic label information among the multiple views in the fine-tuning stage. Thus, the proposed CVCL method is able to produce more discriminative cluster assignments by virtue of this learning strategy. Moreover, we provide a theoretical analysis of soft cluster assignment alignment. Extensive experimental results obtained on several datasets demonstrate that the proposed CVCL method outperforms several state-of-the-art approaches.
What Do GNNs Actually Learn? Towards Understanding their Representations
Apr 21, 2023
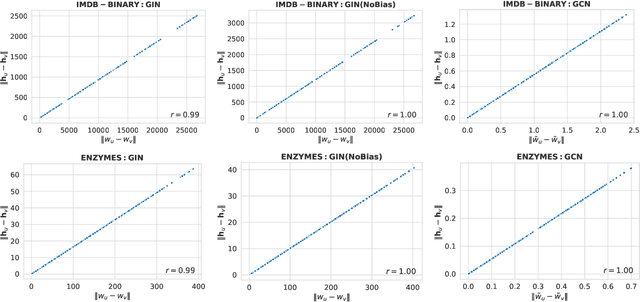
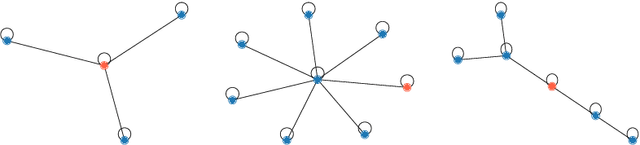
In recent years, graph neural networks (GNNs) have achieved great success in the field of graph representation learning. Although prior work has shed light into the expressiveness of those models (\ie whether they can distinguish pairs of non-isomorphic graphs), it is still not clear what structural information is encoded into the node representations that are learned by those models. In this paper, we investigate which properties of graphs are captured purely by these models, when no node attributes are available. Specifically, we study four popular GNN models, and we show that two of them embed all nodes into the same feature vector, while the other two models generate representations that are related to the number of walks over the input graph. Strikingly, structurally dissimilar nodes can have similar representations at some layer $k>1$, if they have the same number of walks of length $k$. We empirically verify our theoretical findings on real datasets.
DEIR: Efficient and Robust Exploration through Discriminative-Model-Based Episodic Intrinsic Rewards
Apr 21, 2023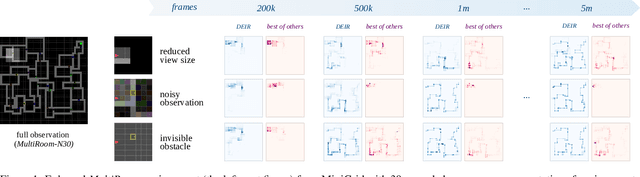
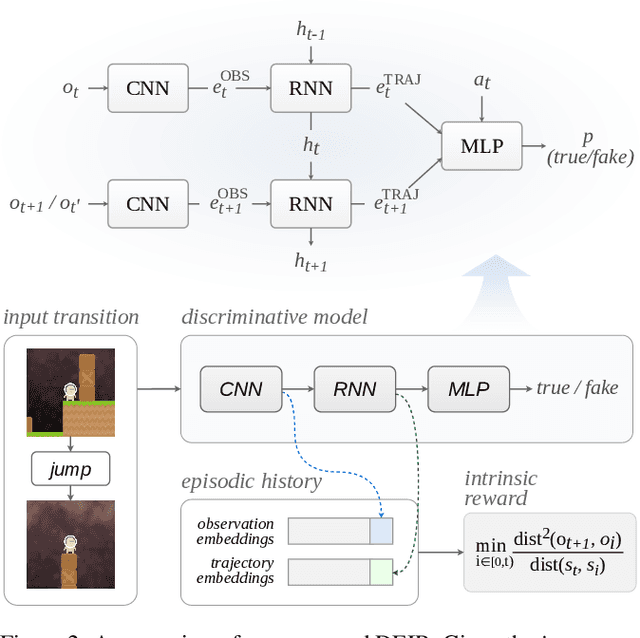
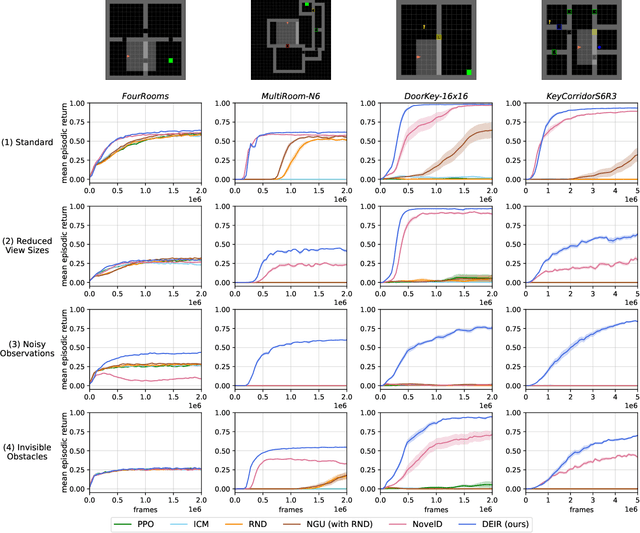
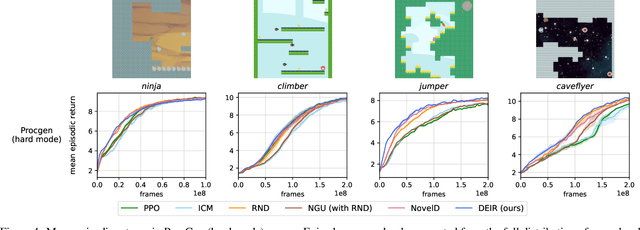
Exploration is a fundamental aspect of reinforcement learning (RL), and its effectiveness crucially decides the performance of RL algorithms, especially when facing sparse extrinsic rewards. Recent studies showed the effectiveness of encouraging exploration with intrinsic rewards estimated from novelty in observations. However, there is a gap between the novelty of an observation and an exploration in general, because the stochasticity in the environment as well as the behavior of an agent may affect the observation. To estimate exploratory behaviors accurately, we propose DEIR, a novel method where we theoretically derive an intrinsic reward from a conditional mutual information term that principally scales with the novelty contributed by agent explorations, and materialize the reward with a discriminative forward model. We conduct extensive experiments in both standard and hardened exploration games in MiniGrid to show that DEIR quickly learns a better policy than baselines. Our evaluations in ProcGen demonstrate both generalization capabilities and the general applicability of our intrinsic reward.
Identity-driven Three-Player Generative Adversarial Network for Synthetic-based Face Recognition
Apr 30, 2023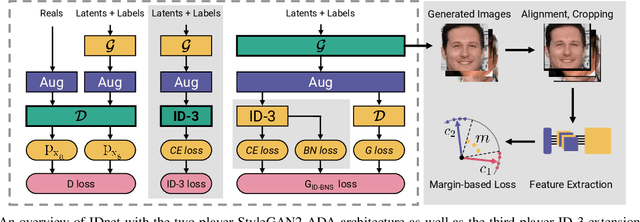
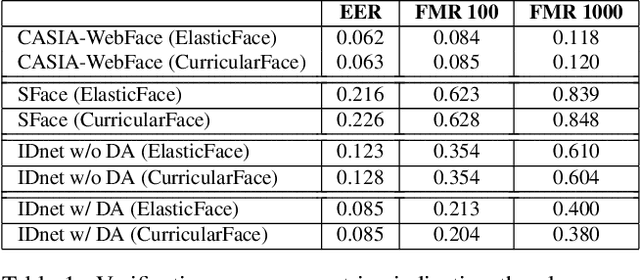

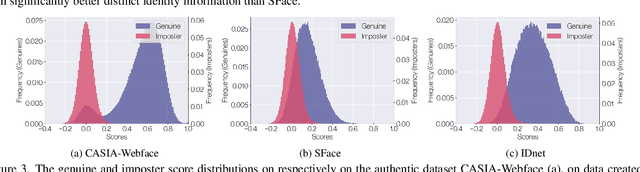
Many of the commonly used datasets for face recognition development are collected from the internet without proper user consent. Due to the increasing focus on privacy in the social and legal frameworks, the use and distribution of these datasets are being restricted and strongly questioned. These databases, which have a realistically high variability of data per identity, have enabled the success of face recognition models. To build on this success and to align with privacy concerns, synthetic databases, consisting purely of synthetic persons, are increasingly being created and used in the development of face recognition solutions. In this work, we present a three-player generative adversarial network (GAN) framework, namely IDnet, that enables the integration of identity information into the generation process. The third player in our IDnet aims at forcing the generator to learn to generate identity-separable face images. We empirically proved that our IDnet synthetic images are of higher identity discrimination in comparison to the conventional two-player GAN, while maintaining a realistic intra-identity variation. We further studied the identity link between the authentic identities used to train the generator and the generated synthetic identities, showing very low similarities between these identities. We demonstrated the applicability of our IDnet data in training face recognition models by evaluating these models on a wide set of face recognition benchmarks. In comparison to the state-of-the-art works in synthetic-based face recognition, our solution achieved comparable results to a recent rendering-based approach and outperformed all existing GAN-based approaches. The training code and the synthetic face image dataset are publicly available ( https://github.com/fdbtrs/Synthetic-Face-Recognition ).
Towards Realistic Generative 3D Face Models
Apr 24, 2023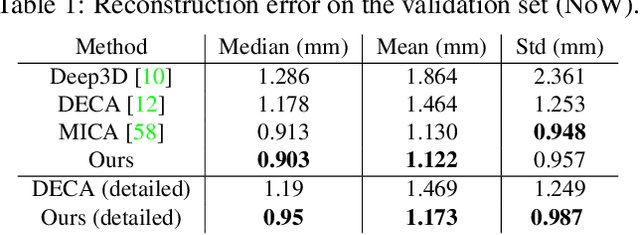
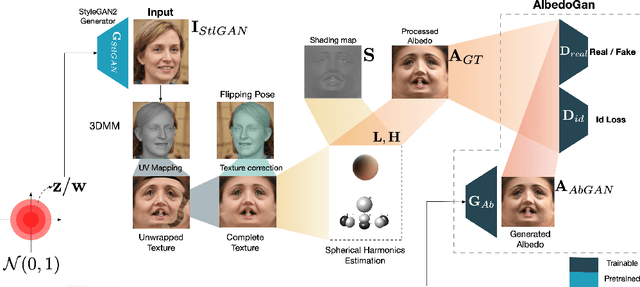

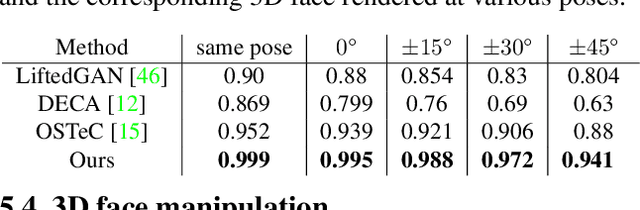
In recent years, there has been significant progress in 2D generative face models fueled by applications such as animation, synthetic data generation, and digital avatars. However, due to the absence of 3D information, these 2D models often struggle to accurately disentangle facial attributes like pose, expression, and illumination, limiting their editing capabilities. To address this limitation, this paper proposes a 3D controllable generative face model to produce high-quality albedo and precise 3D shape leveraging existing 2D generative models. By combining 2D face generative models with semantic face manipulation, this method enables editing of detailed 3D rendered faces. The proposed framework utilizes an alternating descent optimization approach over shape and albedo. Differentiable rendering is used to train high-quality shapes and albedo without 3D supervision. Moreover, this approach outperforms the state-of-the-art (SOTA) methods in the well-known NoW benchmark for shape reconstruction. It also outperforms the SOTA reconstruction models in recovering rendered faces' identities across novel poses by an average of 10%. Additionally, the paper demonstrates direct control of expressions in 3D faces by exploiting latent space leading to text-based editing of 3D faces.
Joint Client Assignment and UAV Route Planning for Indirect-Communication Federated Learning
Apr 24, 2023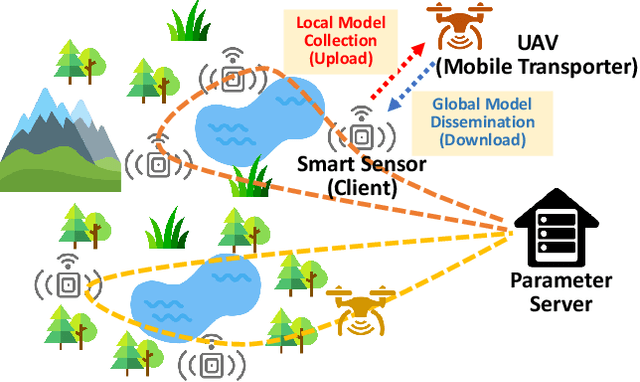
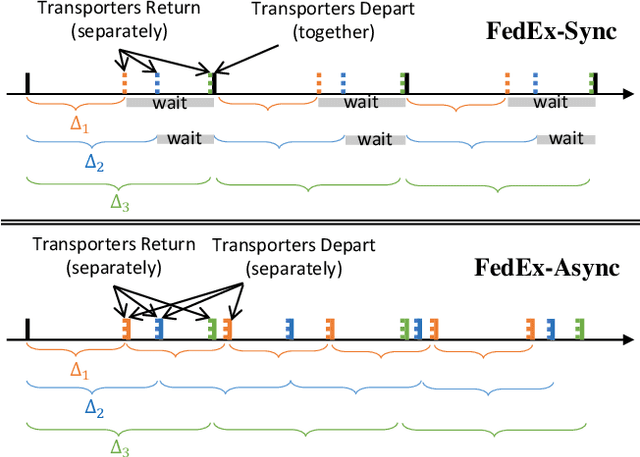

Federated Learning (FL) is a machine learning approach that enables the creation of shared models for powerful applications while allowing data to remain on devices. This approach provides benefits such as improved data privacy, security, and reduced latency. However, in some systems, direct communication between clients and servers may not be possible, such as remote areas without proper communication infrastructure. To overcome this challenge, a new framework called FedEx (Federated Learning via Model Express Delivery) is proposed. This framework employs mobile transporters, such as UAVs, to establish indirect communication channels between the server and clients. These transporters act as intermediaries and allow for model information exchange. The use of indirect communication presents new challenges for convergence analysis and optimization, as the delay introduced by the transporters' movement creates issues for both global model dissemination and local model collection. To address this, two algorithms, FedEx-Sync and FedEx-Async, are proposed for synchronized and asynchronized learning at the transporter level. Additionally, a bi-level optimization algorithm is proposed to solve the joint client assignment and route planning problem. Experimental validation using two public datasets in a simulated network demonstrates consistent results with the theory, proving the efficacy of FedEx.
MoniLog: An Automated Log-Based Anomaly Detection System for Cloud Computing Infrastructures
Apr 24, 2023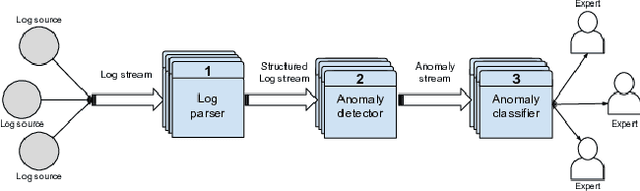
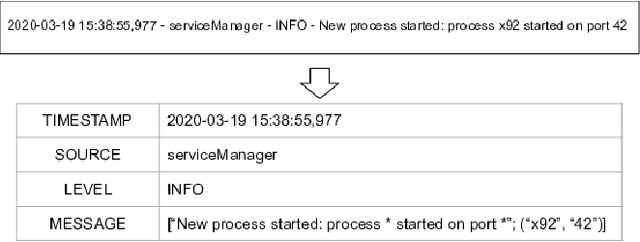
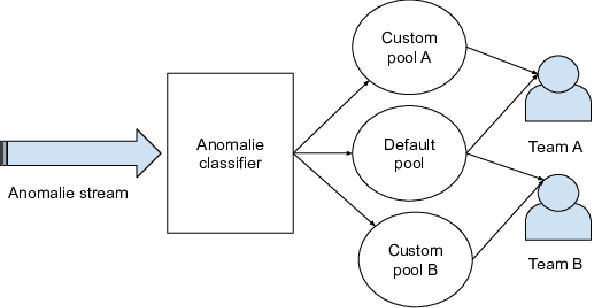

Within today's large-scale systems, one anomaly can impact millions of users. Detecting such events in real-time is essential to maintain the quality of services. It allows the monitoring team to prevent or diminish the impact of a failure. Logs are a core part of software development and maintenance, by recording detailed information at runtime. Such log data are universally available in nearly all computer systems. They enable developers as well as system maintainers to monitor and dissect anomalous events. For Cloud computing companies and large online platforms in general, growth is linked to the scaling potential. Automatizing the anomaly detection process is a promising way to ensure the scalability of monitoring capacities regarding the increasing volume of logs generated by modern systems. In this paper, we will introduce MoniLog, a distributed approach to detect real-time anomalies within large-scale environments. It aims to detect sequential and quantitative anomalies within a multi-source log stream. MoniLog is designed to structure a log stream and perform the monitoring of anomalous sequences. Its output classifier learns from the administrator's actions to label and evaluate the criticality level of anomalies.