 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Self-Supervised Approach for Cluster Assessment of High-Dimensional Data
May 29, 2023
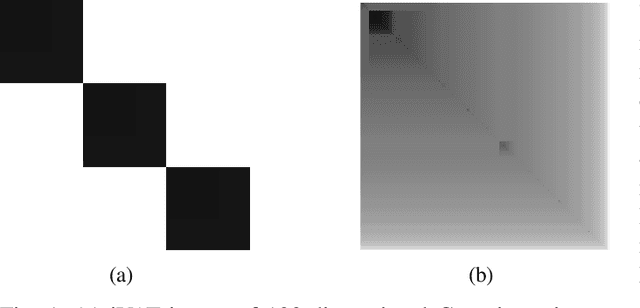
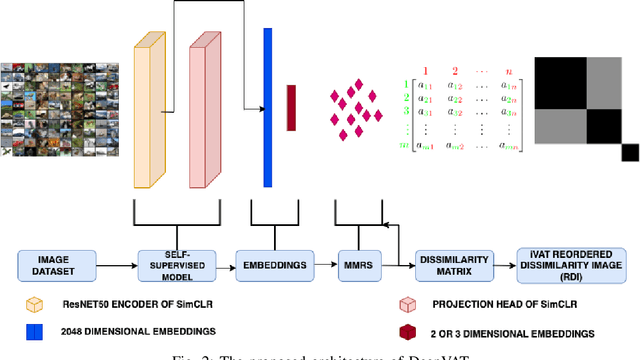

Estimating the number of clusters and underlying cluster structure in a dataset is a crucial task. Real-world data are often unlabeled, complex and high-dimensional, which makes it difficult for traditional clustering algorithms to perform well. In recent years, a matrix reordering based algorithm, called "visual assessment of tendency" (VAT), and its variants have attracted many researchers from various domains to estimate the number of clusters and inherent cluster structure present in the data. However, these algorithms fail when applied to high-dimensional data due to the curse of dimensionality, as they rely heavily on the notions of closeness and farness between data points. To address this issue, we propose a deep-learning based framework for cluster structure assessment in complex, image datasets. First, our framework generates representative embeddings for complex data using a self-supervised deep neural network, and then, these low-dimensional embeddings are fed to VAT/iVAT algorithms to estimate the underlying cluster structure. In this process, we ensured not to use any prior knowledge for the number of clusters (i.e k). We present our results on four real-life image datasets, and our findings indicate that our framework outperforms state-of-the-art VAT/iVAT algorithms in terms of clustering accuracy and normalized mutual information (NMI).
Autoencoding Conditional Neural Processes for Representation Learning
May 29, 2023
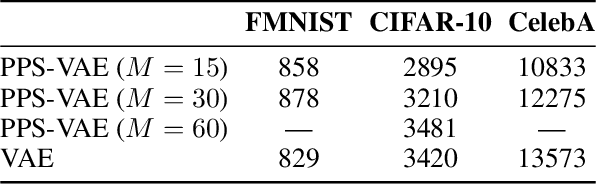
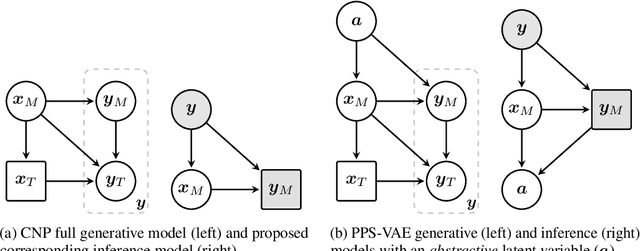
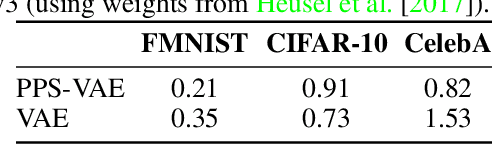
Conditional neural processes (CNPs) are a flexible and efficient family of models that learn to learn a stochastic process from observations. In the visual domain, they have seen particular application in contextual image completion - observing pixel values at some locations to predict a distribution over values at other unobserved locations. However, the choice of pixels in learning such a CNP is typically either random or derived from a simple statistical measure (e.g. pixel variance). Here, we turn the problem on its head and ask: which pixels would a CNP like to observe? That is, which pixels allow fitting CNP, and do such pixels tell us something about the underlying image? Viewing the context provided to the CNP as fixed-size latent representations, we construct an amortised variational framework, Partial Pixel Space Variational Autoencoder (PPS-VAE), for predicting this context simultaneously with learning a CNP. We evaluate PPS-VAE on a set of vision datasets, and find that not only is it possible to learn context points while also fitting CNPs, but that their spatial arrangement and values provides strong signal for the information contained in the image - evaluated through the lens of classification. We believe the PPS-VAE provides a promising avenue to explore learning interpretable and effective visual representations.
Datasets for Portuguese Legal Semantic Textual Similarity: Comparing weak supervision and an annotation process approaches
May 29, 2023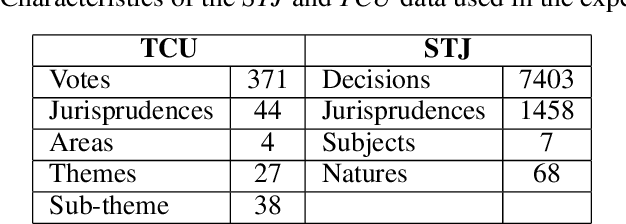

The Brazilian judiciary has a large workload, resulting in a long time to finish legal proceedings. Brazilian National Council of Justice has established in Resolution 469/2022 formal guidance for document and process digitalization opening up the possibility of using automatic techniques to help with everyday tasks in the legal field, particularly in a large number of texts yielded on the routine of law procedures. Notably, Artificial Intelligence (AI) techniques allow for processing and extracting useful information from textual data, potentially speeding up the process. However, datasets from the legal domain required by several AI techniques are scarce and difficult to obtain as they need labels from experts. To address this challenge, this article contributes with four datasets from the legal domain, two with documents and metadata but unlabeled, and another two labeled with a heuristic aiming at its use in textual semantic similarity tasks. Also, to evaluate the effectiveness of the proposed heuristic label process, this article presents a small ground truth dataset generated from domain expert annotations. The analysis of ground truth labels highlights that semantic analysis of domain text can be challenging even for domain experts. Also, the comparison between ground truth and heuristic labels shows that heuristic labels are useful.
Coeditor: Leveraging Contextual Changes for Multi-round Code Auto-editing
May 29, 2023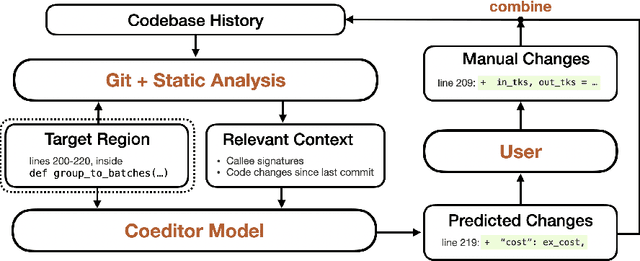
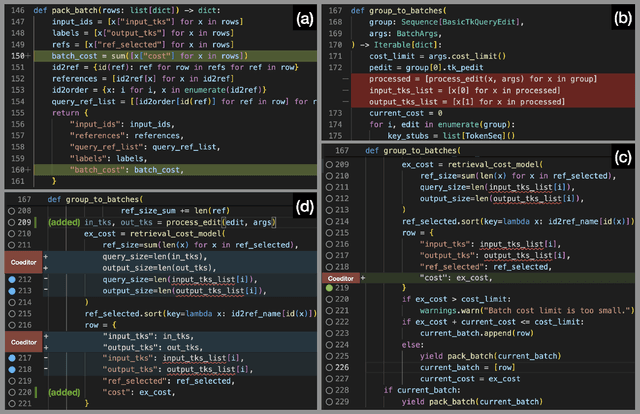

Developers often dedicate significant time to maintaining and refactoring existing code. However, most prior work on generative models for code focuses solely on creating new code, neglecting the unique requirements of editing existing code. In this work, we explore a multi-round code auto-editing setting, aiming to predict edits to a code region based on recent changes within the same codebase. Our model, Coeditor, is a fine-tuned CodeT5 model with enhancements specifically designed for code editing tasks. We encode code changes using a line diff format and employ static analysis to form large customized model contexts, ensuring appropriate information for prediction. We collect a code editing dataset from the commit histories of 1650 open-source Python projects for training and evaluation. In a simplified single-round, single-edit task, Coeditor significantly outperforms the best code completion approach -- nearly doubling its exact-match accuracy, despite using a much smaller model -- demonstrating the benefits of incorporating editing history for code completion. In a multi-round, multi-edit setting, we observe substantial gains by iteratively prompting the model with additional user edits. We open-source our code, data, and model weights to encourage future research and release a VSCode extension powered by our model for interactive usage.
Reconstructing the Mind's Eye: fMRI-to-Image with Contrastive Learning and Diffusion Priors
May 29, 2023
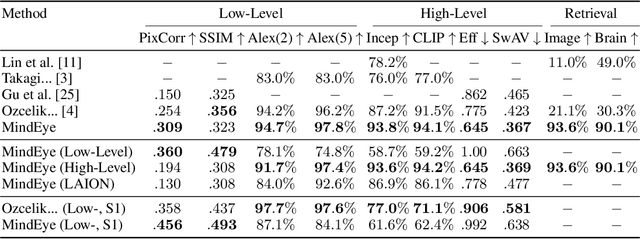
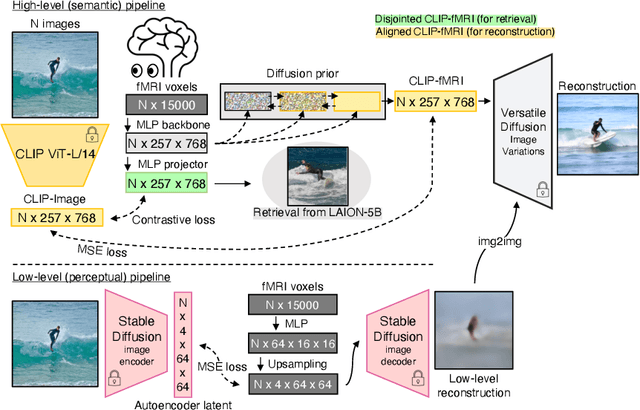
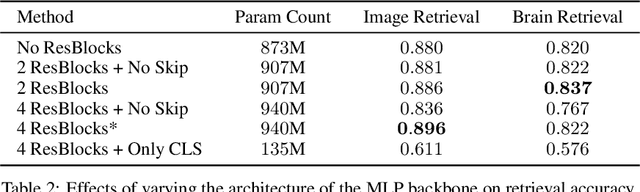
We present MindEye, a novel fMRI-to-image approach to retrieve and reconstruct viewed images from brain activity. Our model comprises two parallel submodules that are specialized for retrieval (using contrastive learning) and reconstruction (using a diffusion prior). MindEye can map fMRI brain activity to any high dimensional multimodal latent space, like CLIP image space, enabling image reconstruction using generative models that accept embeddings from this latent space. We comprehensively compare our approach with other existing methods, using both qualitative side-by-side comparisons and quantitative evaluations, and show that MindEye achieves state-of-the-art performance in both reconstruction and retrieval tasks. In particular, MindEye can retrieve the exact original image even among highly similar candidates indicating that its brain embeddings retain fine-grained image-specific information. This allows us to accurately retrieve images even from large-scale databases like LAION-5B. We demonstrate through ablations that MindEye's performance improvements over previous methods result from specialized submodules for retrieval and reconstruction, improved training techniques, and training models with orders of magnitude more parameters. Furthermore, we show that MindEye can better preserve low-level image features in the reconstructions by using img2img, with outputs from a separate autoencoder. All code is available on GitHub.
Monocular 2D Camera-based Proximity Monitoring for Human-Machine Collision Warning on Construction Sites
May 29, 2023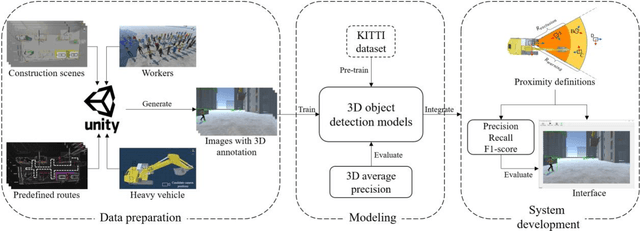

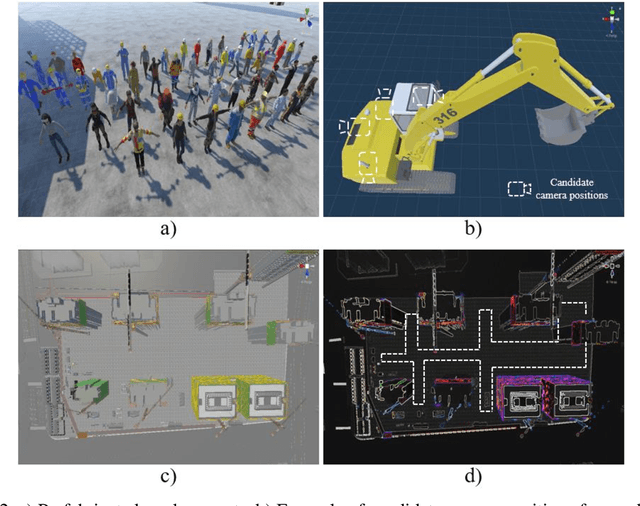

Accident of struck-by machines is one of the leading causes of casualties on construction sites. Monitoring workers' proximities to avoid human-machine collisions has aroused great concern in construction safety management. Existing methods are either too laborious and costly to apply extensively, or lacking spatial perception for accurate monitoring. Therefore, this study proposes a novel framework for proximity monitoring using only an ordinary 2D camera to realize real-time human-machine collision warning, which is designed to integrate a monocular 3D object detection model to perceive spatial information from 2D images and a post-processing classification module to identify the proximity as four predefined categories: Dangerous, Potentially Dangerous, Concerned, and Safe. A virtual dataset containing 22000 images with 3D annotations is constructed and publicly released to facilitate the system development and evaluation. Experimental results show that the trained 3D object detection model achieves 75% loose AP within 20 meters. Besides, the implemented system is real-time and camera carrier-independent, achieving an F1 of roughly 0.8 within 50 meters under specified settings for machines of different sizes. This study preliminarily reveals the potential and feasibility of proximity monitoring using only a 2D camera, providing a new promising and economical way for early warning of human-machine collisions.
FedPDD: A Privacy-preserving Double Distillation Framework for Cross-silo Federated Recommendation
May 09, 2023
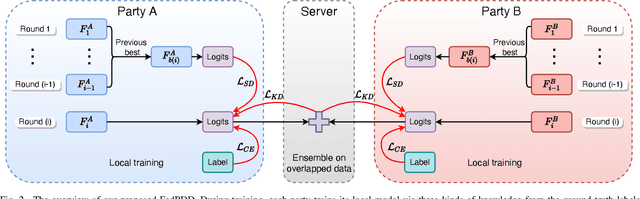
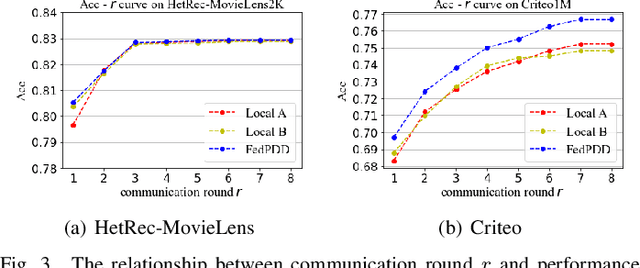
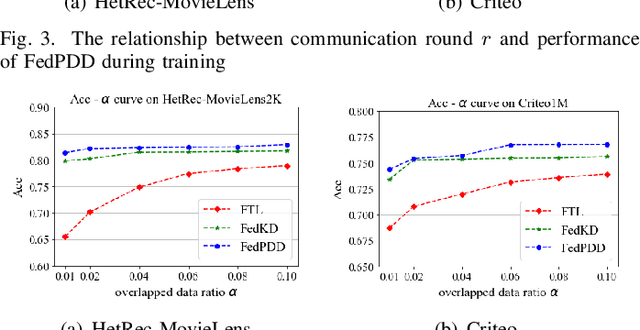
Cross-platform recommendation aims to improve recommendation accuracy by gathering heterogeneous features from different platforms. However, such cross-silo collaborations between platforms are restricted by increasingly stringent privacy protection regulations, thus data cannot be aggregated for training. Federated learning (FL) is a practical solution to deal with the data silo problem in recommendation scenarios. Existing cross-silo FL methods transmit model information to collaboratively build a global model by leveraging the data of overlapped users. However, in reality, the number of overlapped users is often very small, thus largely limiting the performance of such approaches. Moreover, transmitting model information during training requires high communication costs and may cause serious privacy leakage. In this paper, we propose a novel privacy-preserving double distillation framework named FedPDD for cross-silo federated recommendation, which efficiently transfers knowledge when overlapped users are limited. Specifically, our double distillation strategy enables local models to learn not only explicit knowledge from the other party but also implicit knowledge from its past predictions. Moreover, to ensure privacy and high efficiency, we employ an offline training scheme to reduce communication needs and privacy leakage risk. In addition, we adopt differential privacy to further protect the transmitted information. The experiments on two real-world recommendation datasets, HetRec-MovieLens and Criteo, demonstrate the effectiveness of FedPDD compared to the state-of-the-art approaches.
Quantifying Sample Anonymity in Score-Based Generative Models with Adversarial Fingerprinting
Jun 02, 2023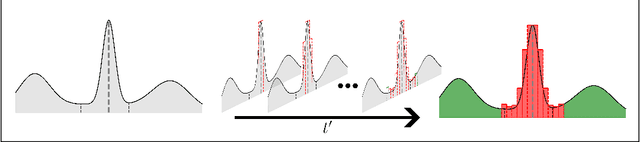
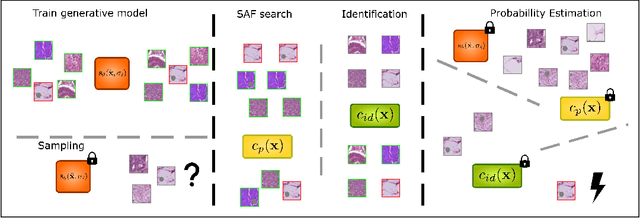
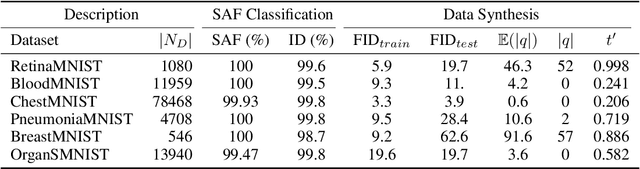
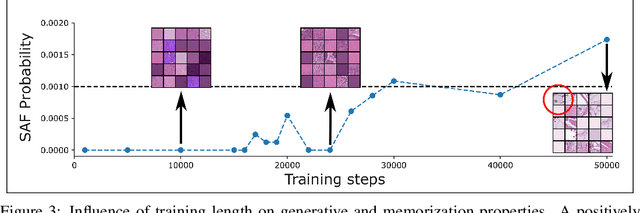
Recent advances in score-based generative models have led to a huge spike in the development of downstream applications using generative models ranging from data augmentation over image and video generation to anomaly detection. Despite publicly available trained models, their potential to be used for privacy preserving data sharing has not been fully explored yet. Training diffusion models on private data and disseminating the models and weights rather than the raw dataset paves the way for innovative large-scale data-sharing strategies, particularly in healthcare, where safeguarding patients' personal health information is paramount. However, publishing such models without individual consent of, e.g., the patients from whom the data was acquired, necessitates guarantees that identifiable training samples will never be reproduced, thus protecting personal health data and satisfying the requirements of policymakers and regulatory bodies. This paper introduces a method for estimating the upper bound of the probability of reproducing identifiable training images during the sampling process. This is achieved by designing an adversarial approach that searches for anatomic fingerprints, such as medical devices or dermal art, which could potentially be employed to re-identify training images. Our method harnesses the learned score-based model to estimate the probability of the entire subspace of the score function that may be utilized for one-to-one reproduction of training samples. To validate our estimates, we generate anomalies containing a fingerprint and investigate whether generated samples from trained generative models can be uniquely mapped to the original training samples. Overall our results show that privacy-breaching images are reproduced at sampling time if the models were trained without care.
Unique Brain Network Identification Number for Parkinson's Individuals Using Structural MRI
Jun 02, 2023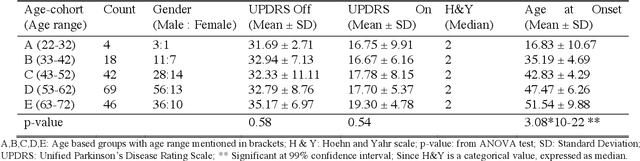
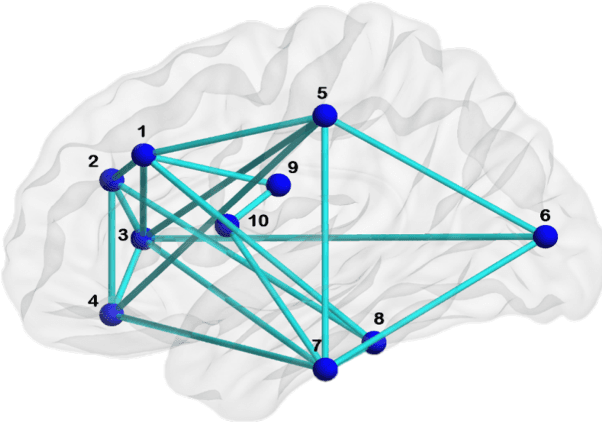
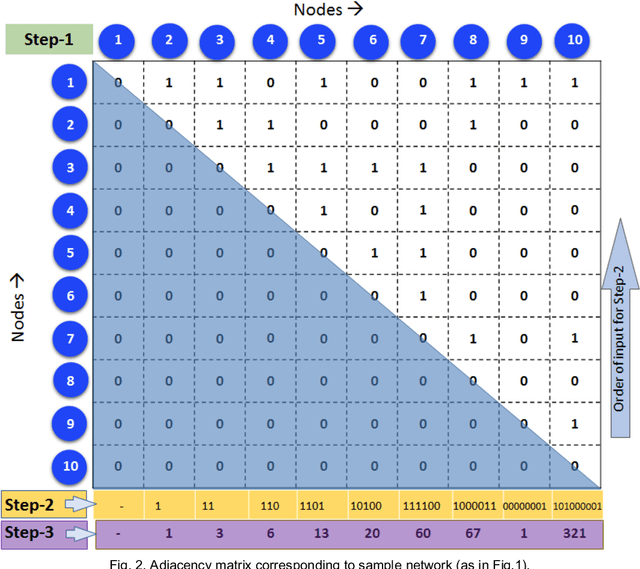
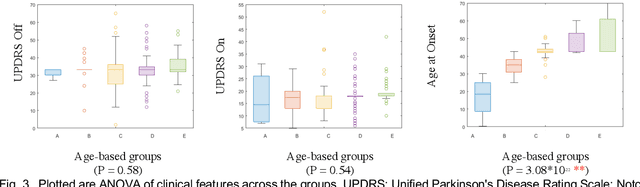
We propose a novel algorithm called Unique Brain Network Identification Number (UBNIN) for encoding brain networks of individual subject. To realize this objective, we employed T1-weighted structural MRI of 180 Parkinson's disease (PD) patients from National Institute of Mental Health and Neurosciences, India. We parcellated each subject's brain volume and constructed individual adjacency matrix using correlation between grey matter (GM) volume of every pair of regions. The unique code is derived from values representing connections of every node (i), weighted by a factor of 2^-(i-1). The numerical representation UBNIN was observed to be distinct for each individual brain network, which may also be applied to other neuroimaging modalities. This model may be implemented as neural signature of a person's unique brain connectivity, thereby useful for brainprinting applications. Additionally, we segregated the above dataset into five age-cohorts: A:22-32years, B:33-42years, C:43-52years, D:53-62years and E:63-72years to study the variation in network topology over age. Sparsity was adopted as the threshold estimate to binarize each age-based correlation matrix. Connectivity metrics were obtained using Brain Connectivity toolbox-based MATLAB functions. For each age-cohort, a decreasing trend was observed in mean clustering coefficient with increasing sparsity. Significantly different clustering coefficient was noted between age-cohort B and C (sparsity: 0.63,0.66), C and E (sparsity: 0.66,0.69). Our findings suggest network connectivity patterns change with age, indicating network disruption due to the underlying neuropathology. Varying clustering coefficient for different cohorts indicate that information transfer between neighboring nodes change with age. This provides evidence on age-related brain shrinkage and network degeneration.
Group channel pruning and spatial attention distilling for object detection
Jun 02, 2023Due to the over-parameterization of neural networks, many model compression methods based on pruning and quantization have emerged. They are remarkable in reducing the size, parameter number, and computational complexity of the model. However, most of the models compressed by such methods need the support of special hardware and software, which increases the deployment cost. Moreover, these methods are mainly used in classification tasks, and rarely directly used in detection tasks. To address these issues, for the object detection network we introduce a three-stage model compression method: dynamic sparse training, group channel pruning, and spatial attention distilling. Firstly, to select out the unimportant channels in the network and maintain a good balance between sparsity and accuracy, we put forward a dynamic sparse training method, which introduces a variable sparse rate, and the sparse rate will change with the training process of the network. Secondly, to reduce the effect of pruning on network accuracy, we propose a novel pruning method called group channel pruning. In particular, we divide the network into multiple groups according to the scales of the feature layer and the similarity of module structure in the network, and then we use different pruning thresholds to prune the channels in each group. Finally, to recover the accuracy of the pruned network, we use an improved knowledge distillation method for the pruned network. Especially, we extract spatial attention information from the feature maps of specific scales in each group as knowledge for distillation. In the experiments, we use YOLOv4 as the object detection network and PASCAL VOC as the training dataset. Our method reduces the parameters of the model by 64.7 % and the calculation by 34.9%.
* Appl Intell