 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Mapping Computer Science Research: Trends, Influences, and Predictions
Aug 01, 2023
This paper explores the current trending research areas in the field of Computer Science (CS) and investigates the factors contributing to their emergence. Leveraging a comprehensive dataset comprising papers, citations, and funding information, we employ advanced machine learning techniques, including Decision Tree and Logistic Regression models, to predict trending research areas. Our analysis reveals that the number of references cited in research papers (Reference Count) plays a pivotal role in determining trending research areas making reference counts the most relevant factor that drives trend in the CS field. Additionally, the influence of NSF grants and patents on trending topics has increased over time. The Logistic Regression model outperforms the Decision Tree model in predicting trends, exhibiting higher accuracy, precision, recall, and F1 score. By surpassing a random guess baseline, our data-driven approach demonstrates higher accuracy and efficacy in identifying trending research areas. The results offer valuable insights into the trending research areas, providing researchers and institutions with a data-driven foundation for decision-making and future research direction.
VL-Grasp: a 6-Dof Interactive Grasp Policy for Language-Oriented Objects in Cluttered Indoor Scenes
Aug 01, 2023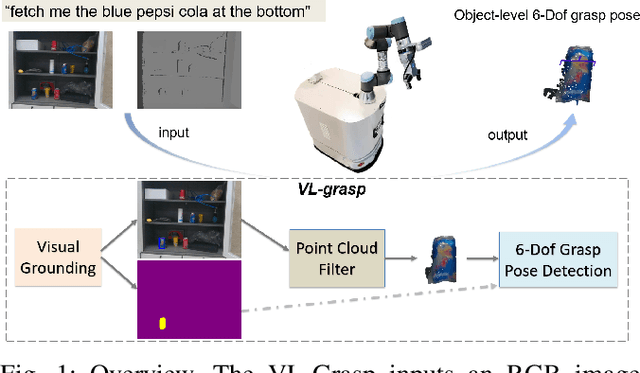

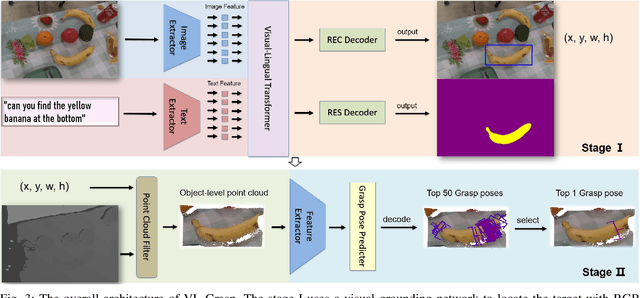
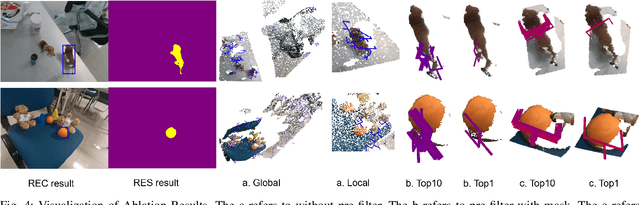
Robotic grasping faces new challenges in human-robot-interaction scenarios. We consider the task that the robot grasps a target object designated by human's language directives. The robot not only needs to locate a target based on vision-and-language information, but also needs to predict the reasonable grasp pose candidate at various views and postures. In this work, we propose a novel interactive grasp policy, named Visual-Lingual-Grasp (VL-Grasp), to grasp the target specified by human language. First, we build a new challenging visual grounding dataset to provide functional training data for robotic interactive perception in indoor environments. Second, we propose a 6-Dof interactive grasp policy combined with visual grounding and 6-Dof grasp pose detection to extend the universality of interactive grasping. Third, we design a grasp pose filter module to enhance the performance of the policy. Experiments demonstrate the effectiveness and extendibility of the VL-Grasp in real world. The VL-Grasp achieves a success rate of 72.5\% in different indoor scenes. The code and dataset is available at https://github.com/luyh20/VL-Grasp.
MonoNext: A 3D Monocular Object Detection with ConvNext
Aug 01, 2023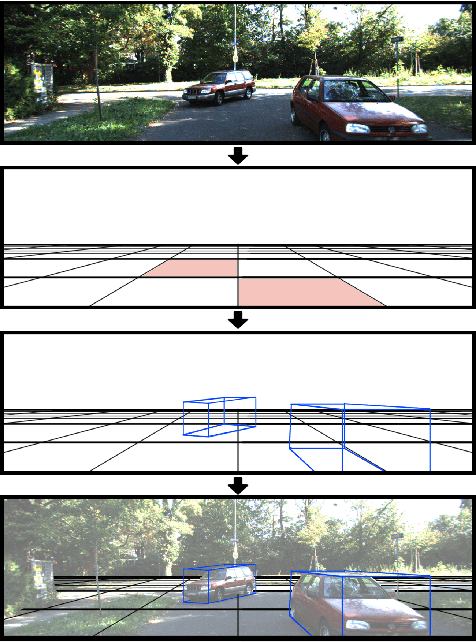
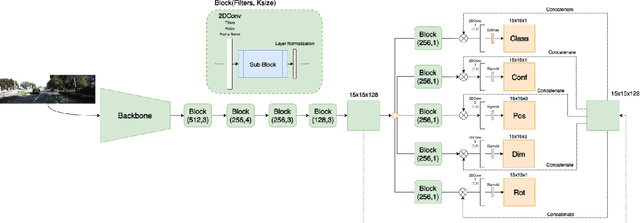
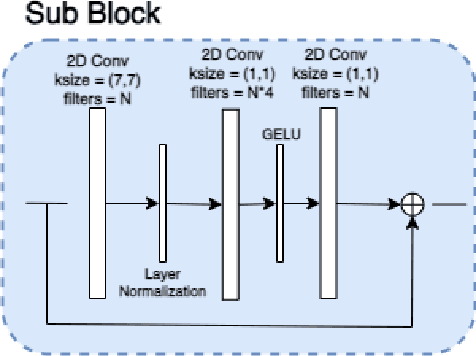
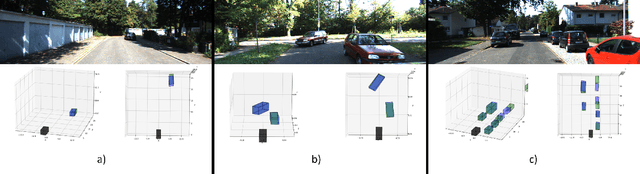
Autonomous driving perception tasks rely heavily on cameras as the primary sensor for Object Detection, Semantic Segmentation, Instance Segmentation, and Object Tracking. However, RGB images captured by cameras lack depth information, which poses a significant challenge in 3D detection tasks. To supplement this missing data, mapping sensors such as LIDAR and RADAR are used for accurate 3D Object Detection. Despite their significant accuracy, the multi-sensor models are expensive and require a high computational demand. In contrast, Monocular 3D Object Detection models are becoming increasingly popular, offering a faster, cheaper, and easier-to-implement solution for 3D detections. This paper introduces a different Multi-Tasking Learning approach called MonoNext that utilizes a spatial grid to map objects in the scene. MonoNext employs a straightforward approach based on the ConvNext network and requires only 3D bounding box annotated data. In our experiments with the KITTI dataset, MonoNext achieved high precision and competitive performance comparable with state-of-the-art approaches. Furthermore, by adding more training data, MonoNext surpassed itself and achieved higher accuracies.
Physical-Layer Authentication of Commodity Wi-Fi Devices via Micro-Signals on CSI Curves
Aug 01, 2023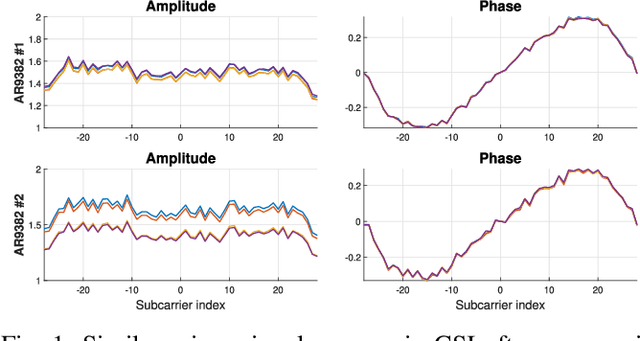
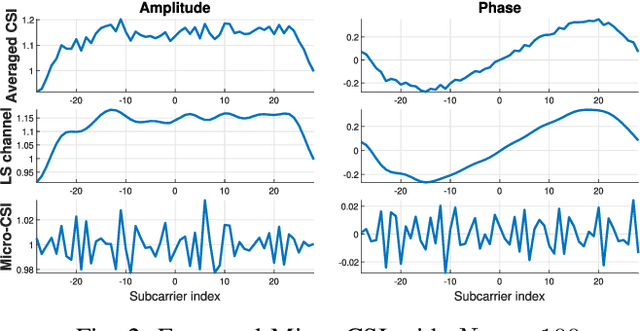
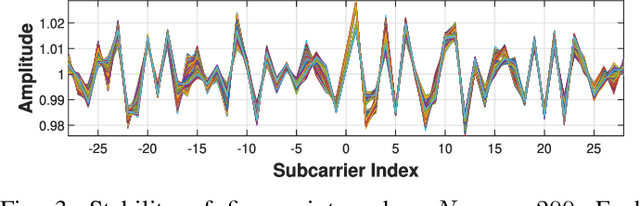
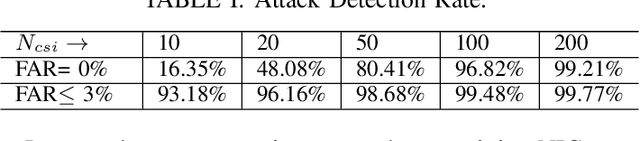
This paper presents a new radiometric fingerprint that is revealed by micro-signals in the channel state information (CSI) curves extracted from commodity Wi-Fi devices. We refer to this new fingerprint as "micro-CSI". Our experiments show that micro-CSI is likely to be caused by imperfections in the radio-frequency circuitry and is present in Wi-Fi 4/5/6 network interface cards (NICs). We conducted further experiments to determine the most effective CSI collection configuration to stabilize micro-CSI. To extract micro-CSI from varying CSI curves, we developed a signal space-based extraction algorithm that effectively separates distortions caused by wireless channels and hardware imperfections under line-of-sight (LoS) scenarios. Finally, we implemented a micro-CSI-based device authentication algorithm that uses the k-Nearest Neighbors (KNN) method to identify 11 COTS Wi-Fi NICs from the same manufacturer in typical indoor environments. Our experimental results demonstrate that the micro-CSI-based authentication algorithm can achieve an average attack detection rate of over 99% with a false alarm rate of 0%.
Collaborative filtering to capture AI user's preferences as norms
Aug 01, 2023Customising AI technologies to each user's preferences is fundamental to them functioning well. Unfortunately, current methods require too much user involvement and fail to capture their true preferences. In fact, to avoid the nuisance of manually setting preferences, users usually accept the default settings even if these do not conform to their true preferences. Norms can be useful to regulate behaviour and ensure it adheres to user preferences but, while the literature has thoroughly studied norms, most proposals take a formal perspective. Indeed, while there has been some research on constructing norms to capture a user's privacy preferences, these methods rely on domain knowledge which, in the case of AI technologies, is difficult to obtain and maintain. We argue that a new perspective is required when constructing norms, which is to exploit the large amount of preference information readily available from whole systems of users. Inspired by recommender systems, we believe that collaborative filtering can offer a suitable approach to identifying a user's norm preferences without excessive user involvement.
Where Did the President Visit Last Week? Detecting Celebrity Trips from News Articles
Jul 17, 2023

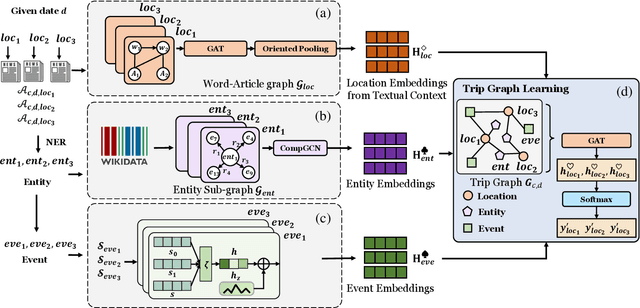

Celebrities' whereabouts are of pervasive importance. For instance, where politicians go, how often they visit, and who they meet, come with profound geopolitical and economic implications. Although news articles contain travel information of celebrities, it is not possible to perform large-scale and network-wise analysis due to the lack of automatic itinerary detection tools. To design such tools, we have to overcome difficulties from the heterogeneity among news articles: 1)One single article can be noisy, with irrelevant people and locations, especially when the articles are long. 2)Though it may be helpful if we consider multiple articles together to determine a particular trip, the key semantics are still scattered across different articles intertwined with various noises, making it hard to aggregate them effectively. 3)Over 20% of the articles refer to the celebrities' trips indirectly, instead of using the exact celebrity names or location names, leading to large portions of trips escaping regular detecting algorithms. We model text content across articles related to each candidate location as a graph to better associate essential information and cancel out the noises. Besides, we design a special pooling layer based on attention mechanism and node similarity, reducing irrelevant information from longer articles. To make up the missing information resulted from indirect mentions, we construct knowledge sub-graphs for named entities (person, organization, facility, etc.). Specifically, we dynamically update embeddings of event entities like the G7 summit from news descriptions since the properties (date and location) of the event change each time, which is not captured by the pre-trained event representations. The proposed CeleTrip jointly trains these modules, which outperforms all baseline models and achieves 82.53% in the F1 metric.
Latent Positional Information is in the Self-Attention Variance of Transformer Language Models Without Positional Embeddings
May 23, 2023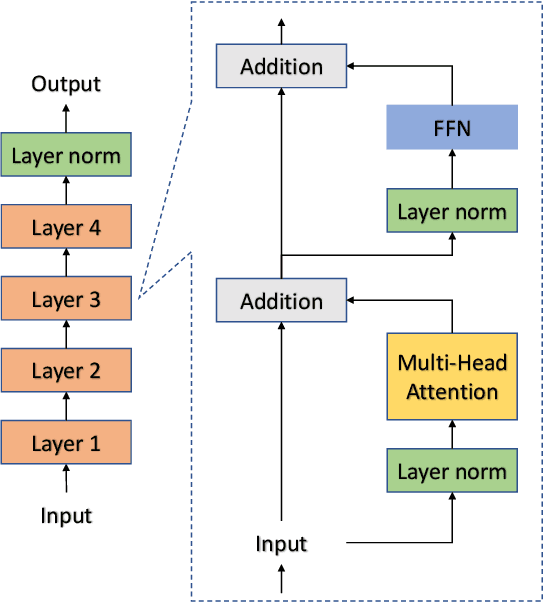

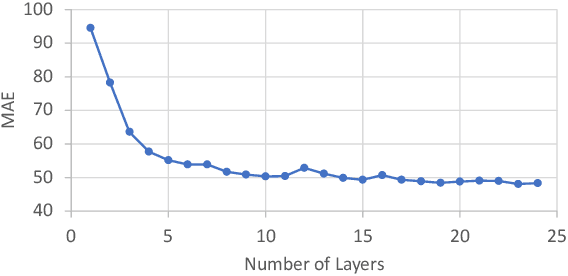
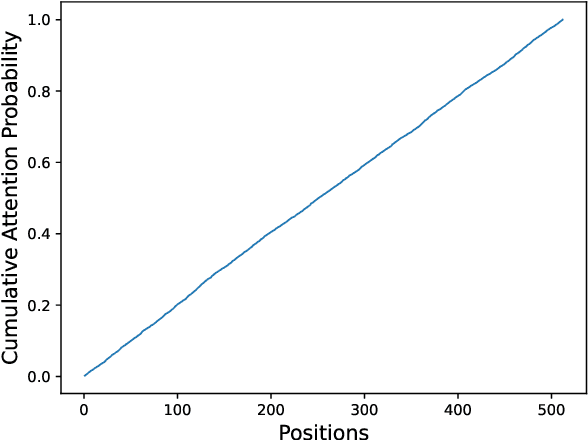
The use of positional embeddings in transformer language models is widely accepted. However, recent research has called into question the necessity of such embeddings. We further extend this inquiry by demonstrating that a randomly initialized and frozen transformer language model, devoid of positional embeddings, inherently encodes strong positional information through the shrinkage of self-attention variance. To quantify this variance, we derive the underlying distribution of each step within a transformer layer. Through empirical validation using a fully pretrained model, we show that the variance shrinkage effect still persists after extensive gradient updates. Our findings serve to justify the decision to discard positional embeddings and thus facilitate more efficient pretraining of transformer language models.
Intrinsic Appearance Decomposition Using Point Cloud Representation
Jul 20, 2023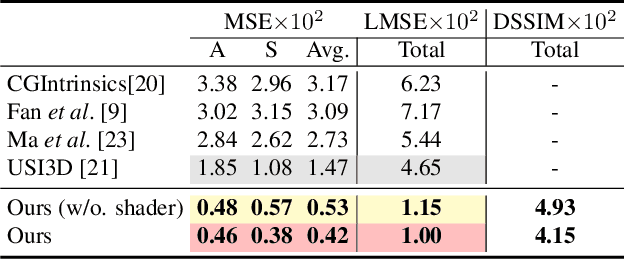
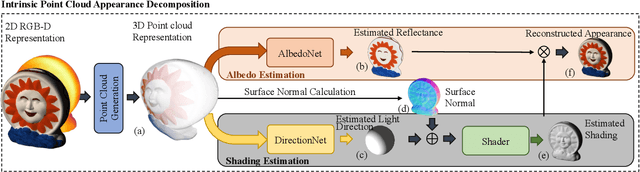
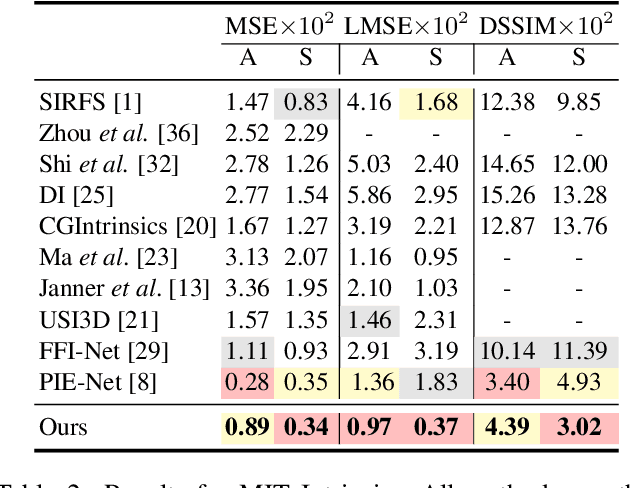

Intrinsic decomposition is to infer the albedo and shading from the image. Since it is a heavily ill-posed problem, previous methods rely on prior assumptions from 2D images, however, the exploration of the data representation itself is limited. The point cloud is known as a rich format of scene representation, which naturally aligns the geometric information and the color information of an image. Our proposed method, Point Intrinsic Net, in short, PoInt-Net, jointly predicts the albedo, light source direction, and shading, using point cloud representation. Experiments reveal the benefits of PoInt-Net, in terms of accuracy, it outperforms 2D representation approaches on multiple metrics across datasets; in terms of efficiency, it trains on small-scale point clouds and performs stably on any-scale point clouds; in terms of robustness, it only trains on single object level dataset, and demonstrates reasonable generalization ability for unseen objects and scenes.
Hypergraph Isomorphism Computation
Jul 26, 2023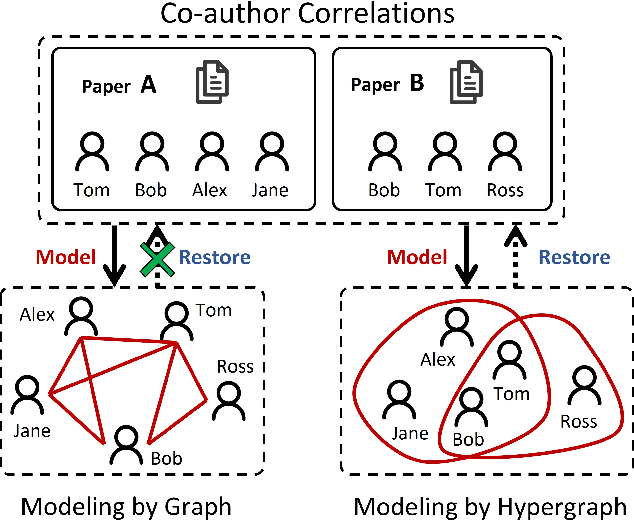
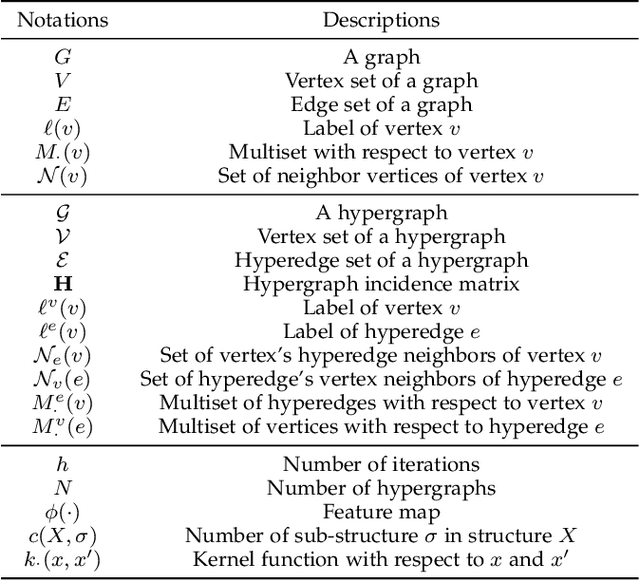

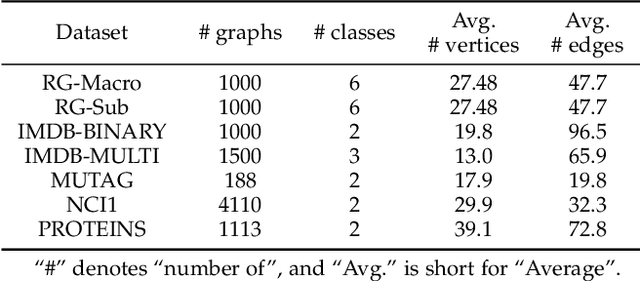
The isomorphism problem is a fundamental problem in network analysis, which involves capturing both low-order and high-order structural information. In terms of extracting low-order structural information, graph isomorphism algorithms analyze the structural equivalence to reduce the solver space dimension, which demonstrates its power in many applications, such as protein design, chemical pathways, and community detection. For the more commonly occurring high-order relationships in real-life scenarios, the problem of hypergraph isomorphism, which effectively captures these high-order structural relationships, cannot be straightforwardly addressed using graph isomorphism methods. Besides, the existing hypergraph kernel methods may suffer from high memory consumption or inaccurate sub-structure identification, thus yielding sub-optimal performance. In this paper, to address the abovementioned problems, we first propose the hypergraph Weisfiler-Lehman test algorithm for the hypergraph isomorphism test problem by generalizing the Weisfiler-Lehman test algorithm from graphs to hypergraphs. Secondly, based on the presented algorithm, we propose a general hypergraph Weisfieler-Lehman kernel framework and implement two instances, which are Hypergraph Weisfeiler-Lehamn Subtree Kernel and Hypergraph Weisfeiler-Lehamn Hyperedge Kernel. In order to fulfill our research objectives, a comprehensive set of experiments was meticulously designed, including seven graph classification datasets and 12 hypergraph classification datasets. Results on hypergraph classification datasets show significant improvements compared to other typical kernel-based methods, which demonstrates the effectiveness of the proposed methods. In our evaluation, we found that our proposed methods outperform the second-best method in terms of runtime, running over 80 times faster when handling complex hypergraph structures.
Cross-modal & Cross-domain Learning for Unsupervised LiDAR Semantic Segmentation
Aug 05, 2023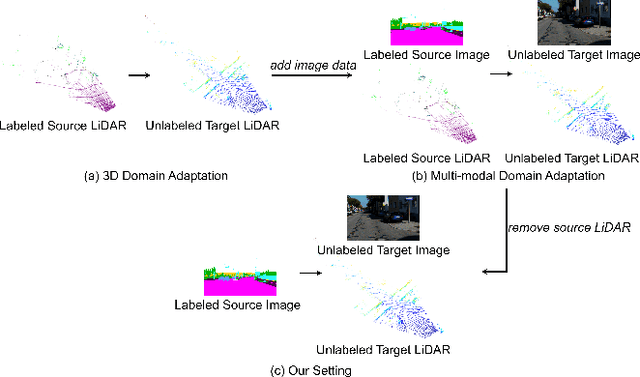
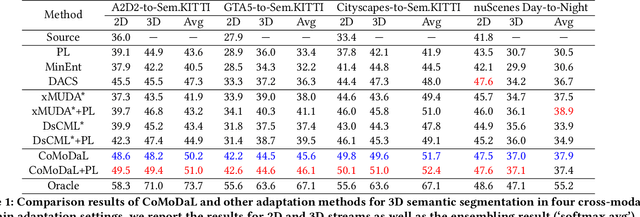
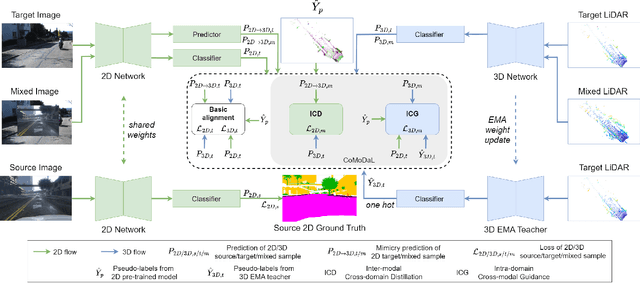

In recent years, cross-modal domain adaptation has been studied on the paired 2D image and 3D LiDAR data to ease the labeling costs for 3D LiDAR semantic segmentation (3DLSS) in the target domain. However, in such a setting the paired 2D and 3D data in the source domain are still collected with additional effort. Since the 2D-3D projections can enable the 3D model to learn semantic information from the 2D counterpart, we ask whether we could further remove the need of source 3D data and only rely on the source 2D images. To answer it, this paper studies a new 3DLSS setting where a 2D dataset (source) with semantic annotations and a paired but unannotated 2D image and 3D LiDAR data (target) are available. To achieve 3DLSS in this scenario, we propose Cross-Modal and Cross-Domain Learning (CoMoDaL). Specifically, our CoMoDaL aims at modeling 1) inter-modal cross-domain distillation between the unpaired source 2D image and target 3D LiDAR data, and 2) the intra-domain cross-modal guidance between the target 2D image and 3D LiDAR data pair. In CoMoDaL, we propose to apply several constraints, such as point-to-pixel and prototype-to-pixel alignments, to associate the semantics in different modalities and domains by constructing mixed samples in two modalities. The experimental results on several datasets show that in the proposed setting, the developed CoMoDaL can achieve segmentation without the supervision of labeled LiDAR data. Ablations are also conducted to provide more analysis. Code will be available publicly.