 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CoSMo: A constructor specification language for Abstract Wikipedia's content selection process
Aug 01, 2023
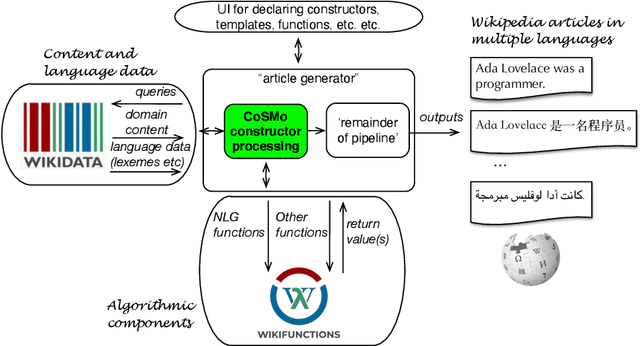
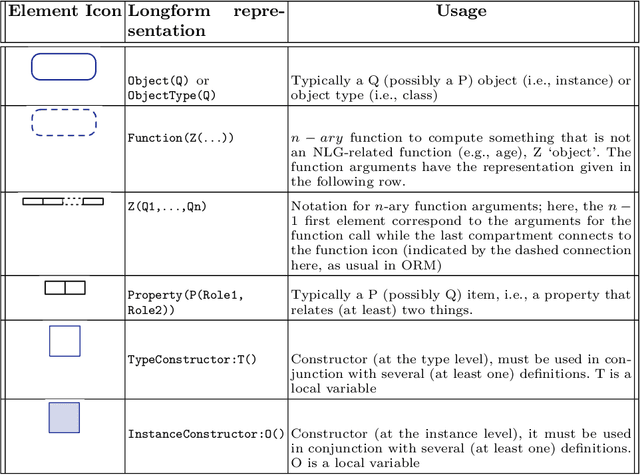
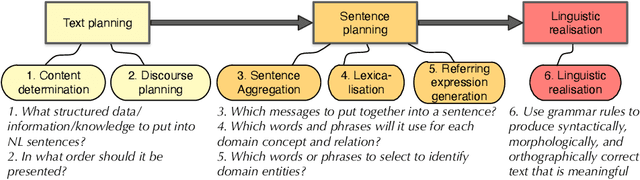
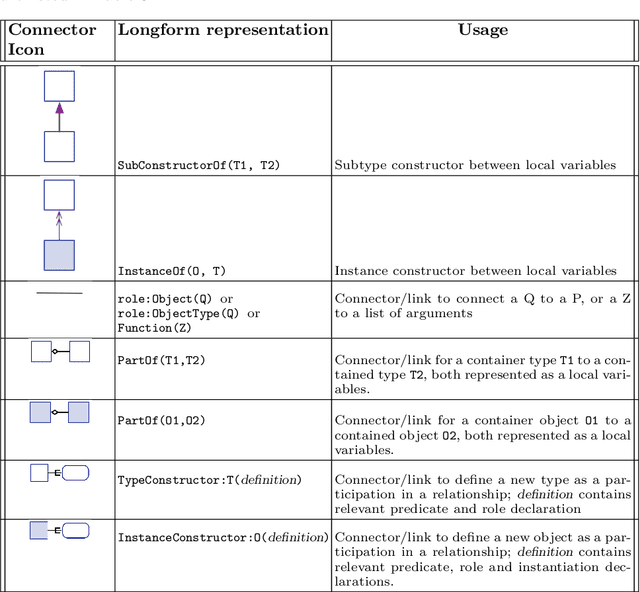
Representing snippets of information abstractly is a task that needs to be performed for various purposes, such as database view specification and the first stage in the natural language generation pipeline for generative AI from structured input, i.e., the content selection stage to determine what needs to be verbalised. For the Abstract Wikipedia project, requirements analysis revealed that such an abstract representation requires multilingual modelling, content selection covering declarative content and functions, and both classes and instances. There is no modelling language that meets either of the three features, let alone a combination. Following a rigorous language design process inclusive of broad stakeholder consultation, we created CoSMo, a novel {\sc Co}ntent {\sc S}election {\sc Mo}deling language that meets these and other requirements so that it may be useful both in Abstract Wikipedia as well as other contexts. We describe the design process, rationale and choices, the specification, and preliminary evaluation of the language.
Iterative Graph Filtering Network for 3D Human Pose Estimation
Aug 07, 2023
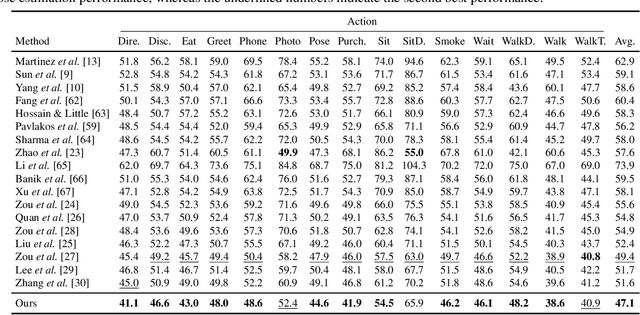

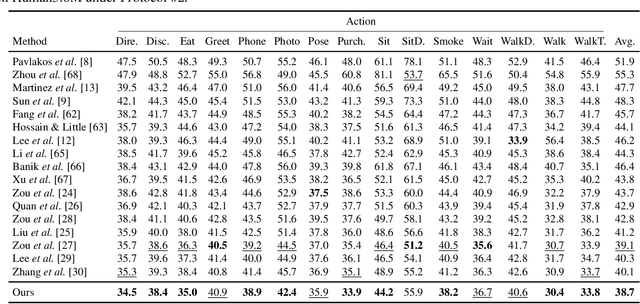
Graph convolutional networks (GCNs) have proven to be an effective approach for 3D human pose estimation. By naturally modeling the skeleton structure of the human body as a graph, GCNs are able to capture the spatial relationships between joints and learn an efficient representation of the underlying pose. However, most GCN-based methods use a shared weight matrix, making it challenging to accurately capture the different and complex relationships between joints. In this paper, we introduce an iterative graph filtering framework for 3D human pose estimation, which aims to predict the 3D joint positions given a set of 2D joint locations in images. Our approach builds upon the idea of iteratively solving graph filtering with Laplacian regularization via the Gauss-Seidel iterative method. Motivated by this iterative solution, we design a Gauss-Seidel network (GS-Net) architecture, which makes use of weight and adjacency modulation, skip connection, and a pure convolutional block with layer normalization. Adjacency modulation facilitates the learning of edges that go beyond the inherent connections of body joints, resulting in an adjusted graph structure that reflects the human skeleton, while skip connections help maintain crucial information from the input layer's initial features as the network depth increases. We evaluate our proposed model on two standard benchmark datasets, and compare it with a comprehensive set of strong baseline methods for 3D human pose estimation. Our experimental results demonstrate that our approach outperforms the baseline methods on both datasets, achieving state-of-the-art performance. Furthermore, we conduct ablation studies to analyze the contributions of different components of our model architecture and show that the skip connection and adjacency modulation help improve the model performance.
Establishing Trust in ChatGPT BioMedical Generated Text: An Ontology-Based Knowledge Graph to Validate Disease-Symptom Links
Aug 07, 2023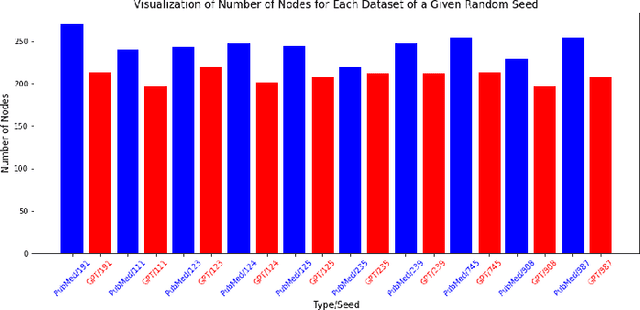
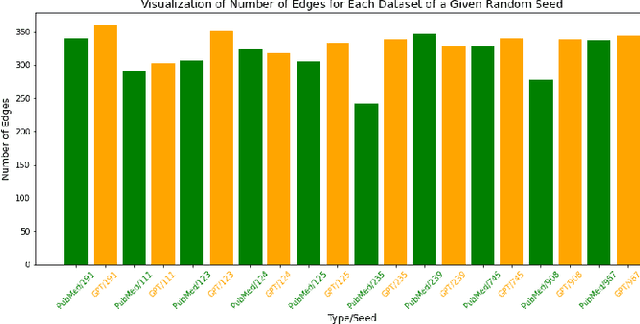
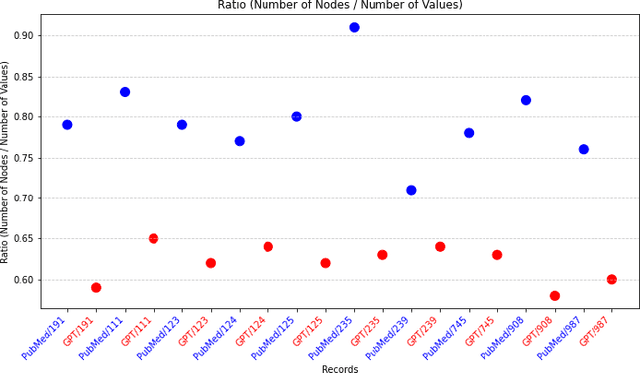
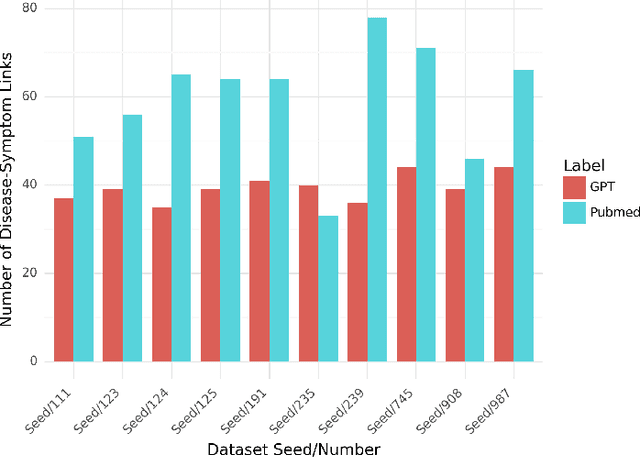
Methods: Through an innovative approach, we construct ontology-based knowledge graphs from authentic medical literature and AI-generated content. Our goal is to distinguish factual information from unverified data. We compiled two datasets: one from biomedical literature using a "human disease and symptoms" query, and another generated by ChatGPT, simulating articles. With these datasets (PubMed and ChatGPT), we curated 10 sets of 250 abstracts each, selected randomly with a specific seed. Our method focuses on utilizing disease ontology (DOID) and symptom ontology (SYMP) to build knowledge graphs, robust mathematical models that facilitate unbiased comparisons. By employing our fact-checking algorithms and network centrality metrics, we conducted GPT disease-symptoms link analysis to quantify the accuracy of factual knowledge amid noise, hypotheses, and significant findings. Results: The findings obtained from the comparison of diverse ChatGPT knowledge graphs with their PubMed counterparts revealed some interesting observations. While PubMed knowledge graphs exhibit a wealth of disease-symptom terms, it is surprising to observe that some ChatGPT graphs surpass them in the number of connections. Furthermore, some GPT graphs are demonstrating supremacy of the centrality scores, especially for the overlapping nodes. This striking contrast indicates the untapped potential of knowledge that can be derived from AI-generated content, awaiting verification. Out of all the graphs, the factual link ratio between any two graphs reached its peak at 60%. Conclusions: An intriguing insight from our findings was the striking number of links among terms in the knowledge graph generated from ChatGPT datasets, surpassing some of those in its PubMed counterpart. This early discovery has prompted further investigation using universal network metrics to unveil the new knowledge the links may hold.
Epistemic Planning for Heterogeneous Robotic Systems
Aug 03, 2023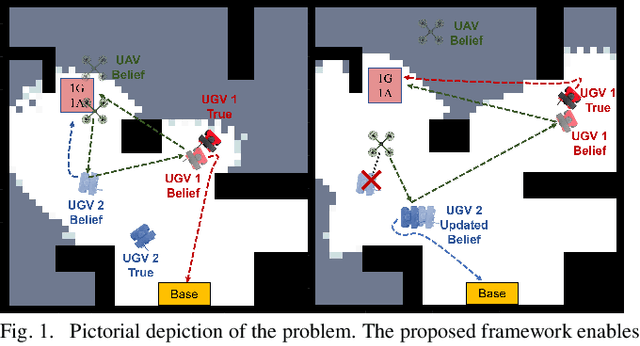
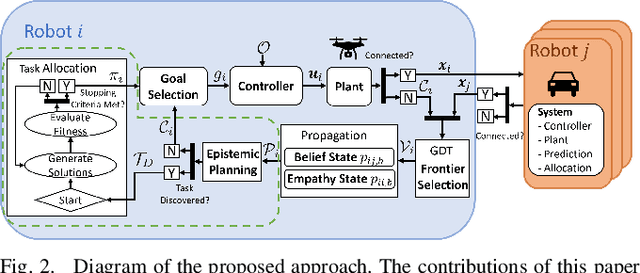
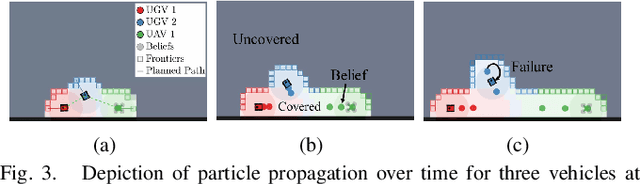
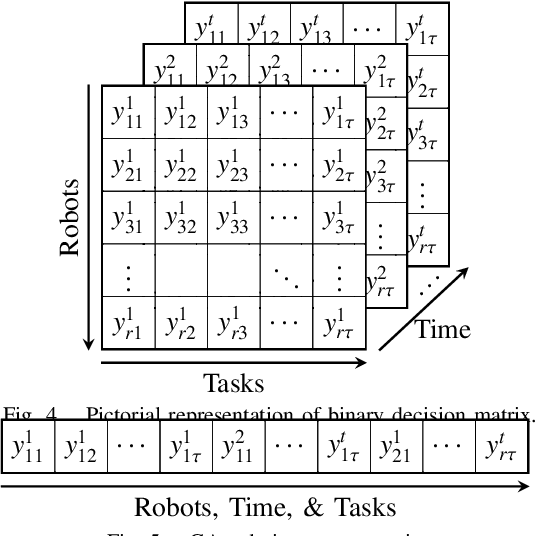
In applications such as search and rescue or disaster relief, heterogeneous multi-robot systems (MRS) can provide significant advantages for complex objectives that require a suite of capabilities. However, within these application spaces, communication is often unreliable, causing inefficiencies or outright failures to arise in most MRS algorithms. Many researchers tackle this problem by requiring all robots to either maintain communication using proximity constraints or assuming that all robots will execute a predetermined plan over long periods of disconnection. The latter method allows for higher levels of efficiency in a MRS, but failures and environmental uncertainties can have cascading effects across the system, especially when a mission objective is complex or time-sensitive. To solve this, we propose an epistemic planning framework that allows robots to reason about the system state, leverage heterogeneous system makeups, and optimize information dissemination to disconnected neighbors. Dynamic epistemic logic formalizes the propagation of belief states, and epistemic task allocation and gossip is accomplished via a mixed integer program using the belief states for utility predictions and planning. The proposed framework is validated using simulations and experiments with heterogeneous vehicles.
Model Calibration in Dense Classification with Adaptive Label Perturbation
Aug 03, 2023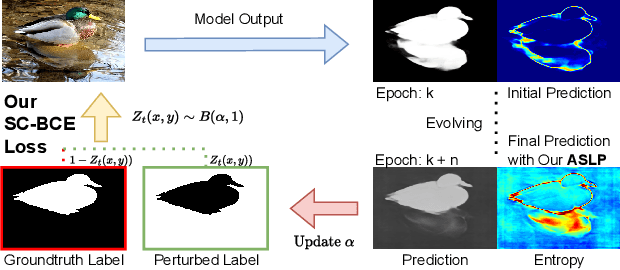
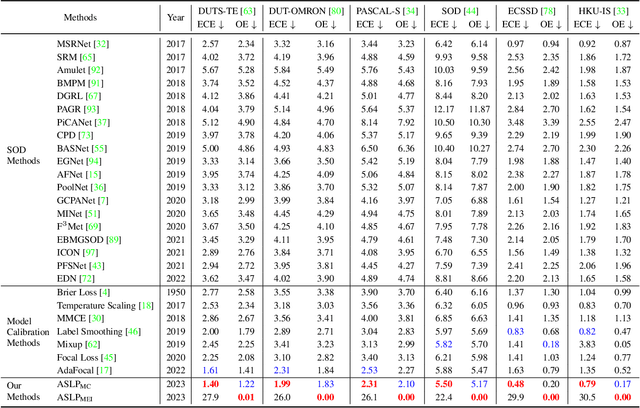
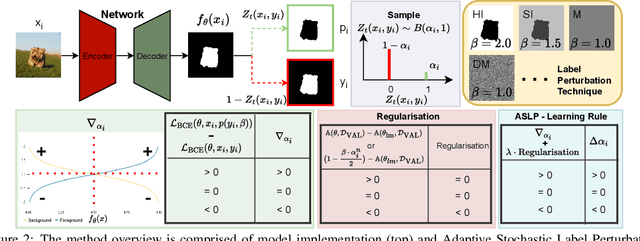
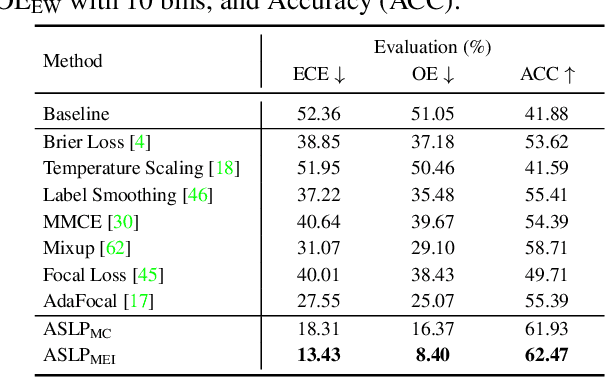
For safety-related applications, it is crucial to produce trustworthy deep neural networks whose prediction is associated with confidence that can represent the likelihood of correctness for subsequent decision-making. Existing dense binary classification models are prone to being over-confident. To improve model calibration, we propose Adaptive Stochastic Label Perturbation (ASLP) which learns a unique label perturbation level for each training image. ASLP employs our proposed Self-Calibrating Binary Cross Entropy (SC-BCE) loss, which unifies label perturbation processes including stochastic approaches (like DisturbLabel), and label smoothing, to correct calibration while maintaining classification rates. ASLP follows Maximum Entropy Inference of classic statistical mechanics to maximise prediction entropy with respect to missing information. It performs this while: (1) preserving classification accuracy on known data as a conservative solution, or (2) specifically improves model calibration degree by minimising the gap between the prediction accuracy and expected confidence of the target training label. Extensive results demonstrate that ASLP can significantly improve calibration degrees of dense binary classification models on both in-distribution and out-of-distribution data. The code is available on https://github.com/Carlisle-Liu/ASLP.
Modelling and simulation of a commercially available dielectric elastomer actuator
Aug 03, 2023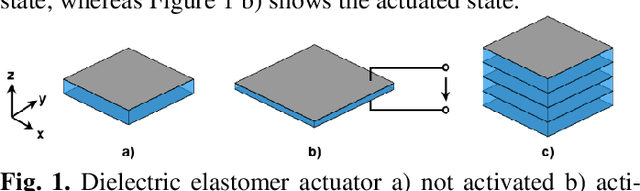
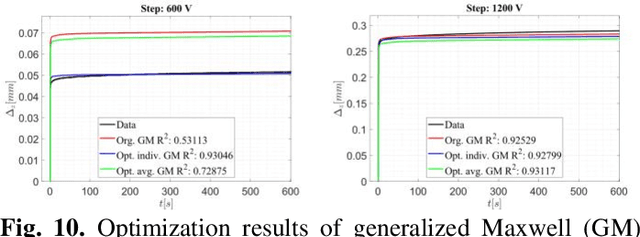
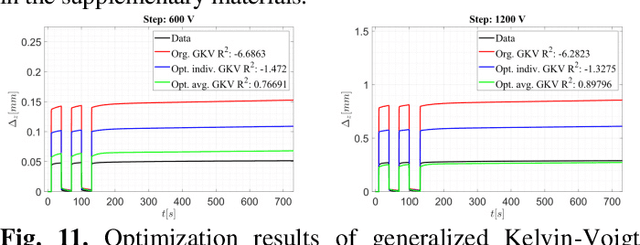
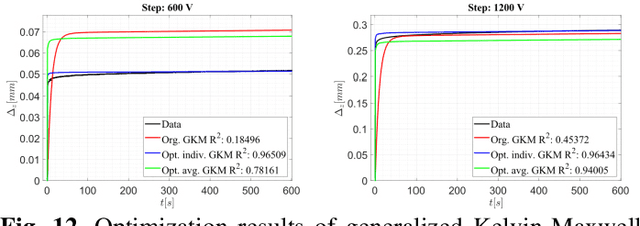
In order to fully harness the potential of dielectric elastomer actu-ators (DEAs) in soft robots, advanced control methods are need-ed. An important groundwork for this is the development of a control-oriented model that can adequately describe the underly-ing dynamics of a DEA. A common feature of existing models is that always custom-made DEAs were investigated. This makes the modelling process easier, as all specifications and the struc-ture of the actuator are well known. In the case of a commercial actuator, however, only the information from the manufacturer is available and must be checked or completed during the modelling process. The aim of this paper is to explore how a commercial stacked silicone-based DEA can be modelled and how complex the model should be to properly replicate the features of the actu-ator. The static description has demonstrated the suitability of Hooke's law. In the case of dynamic description, it is shown that no viscoelastic model is needed for control-oriented modelling. However, if all features of the DEA are considered, the general-ized Kelvin-Maxwell model with three Maxwell elements shows good results, stability and computational efficiency.
Revisiting Deformable Convolution for Depth Completion
Aug 03, 2023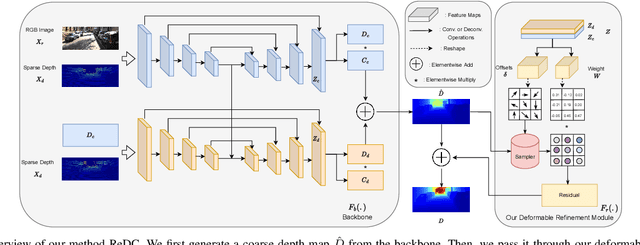

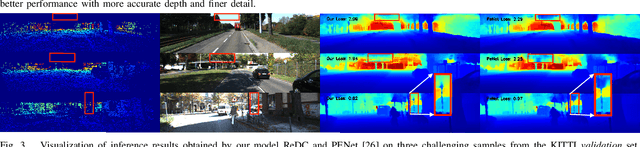
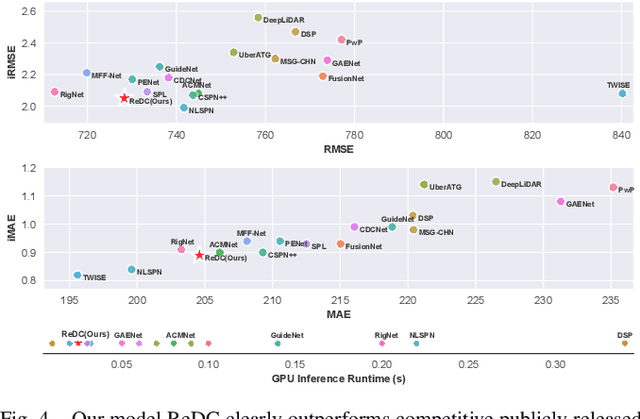
Depth completion, which aims to generate high-quality dense depth maps from sparse depth maps, has attracted increasing attention in recent years. Previous work usually employs RGB images as guidance, and introduces iterative spatial propagation to refine estimated coarse depth maps. However, most of the propagation refinement methods require several iterations and suffer from a fixed receptive field, which may contain irrelevant and useless information with very sparse input. In this paper, we address these two challenges simultaneously by revisiting the idea of deformable convolution. We propose an effective architecture that leverages deformable kernel convolution as a single-pass refinement module, and empirically demonstrate its superiority. To better understand the function of deformable convolution and exploit it for depth completion, we further systematically investigate a variety of representative strategies. Our study reveals that, different from prior work, deformable convolution needs to be applied on an estimated depth map with a relatively high density for better performance. We evaluate our model on the large-scale KITTI dataset and achieve state-of-the-art level performance in both accuracy and inference speed. Our code is available at https://github.com/AlexSunNik/ReDC.
Consistency Regularization for Generalizable Source-free Domain Adaptation
Aug 03, 2023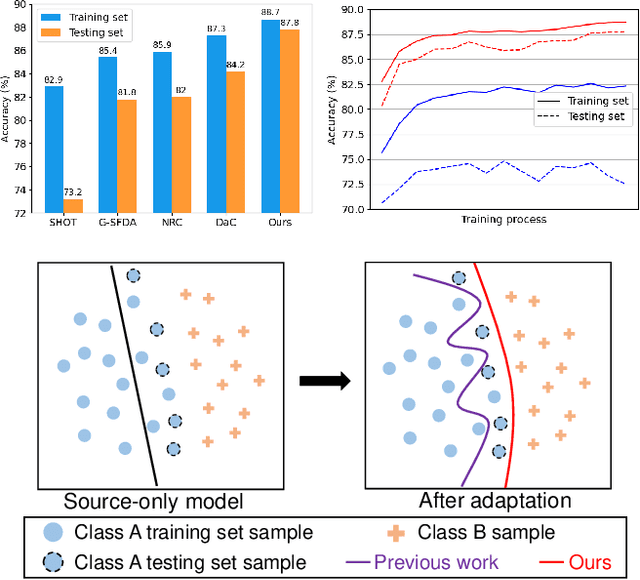
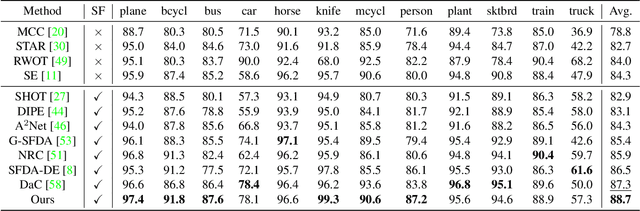
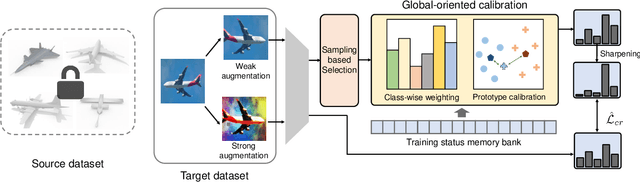
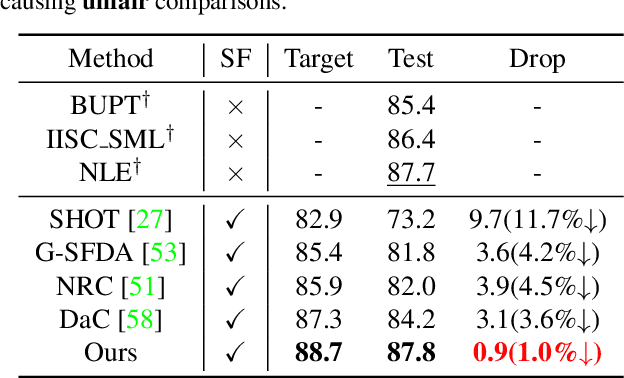
Source-free domain adaptation (SFDA) aims to adapt a well-trained source model to an unlabelled target domain without accessing the source dataset, making it applicable in a variety of real-world scenarios. Existing SFDA methods ONLY assess their adapted models on the target training set, neglecting the data from unseen but identically distributed testing sets. This oversight leads to overfitting issues and constrains the model's generalization ability. In this paper, we propose a consistency regularization framework to develop a more generalizable SFDA method, which simultaneously boosts model performance on both target training and testing datasets. Our method leverages soft pseudo-labels generated from weakly augmented images to supervise strongly augmented images, facilitating the model training process and enhancing the generalization ability of the adapted model. To leverage more potentially useful supervision, we present a sampling-based pseudo-label selection strategy, taking samples with severer domain shift into consideration. Moreover, global-oriented calibration methods are introduced to exploit global class distribution and feature cluster information, further improving the adaptation process. Extensive experiments demonstrate our method achieves state-of-the-art performance on several SFDA benchmarks, and exhibits robustness on unseen testing datasets.
NeuroSwarm: Multi-Agent Neural 3D Scene Reconstruction and Segmentation with UAV for Optimal Navigation of Quadruped Robot
Aug 03, 2023
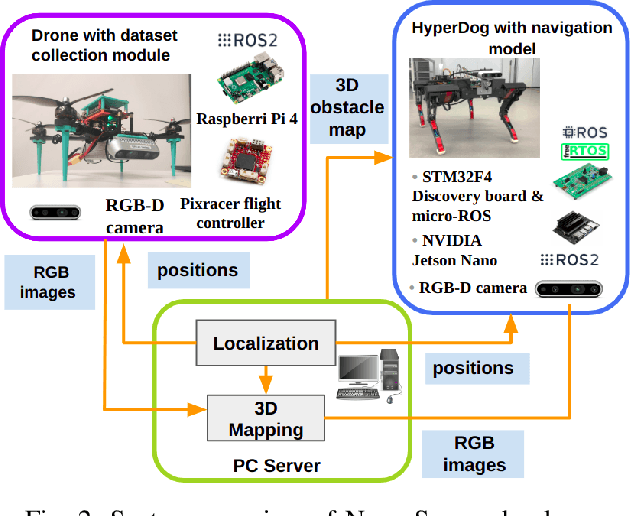
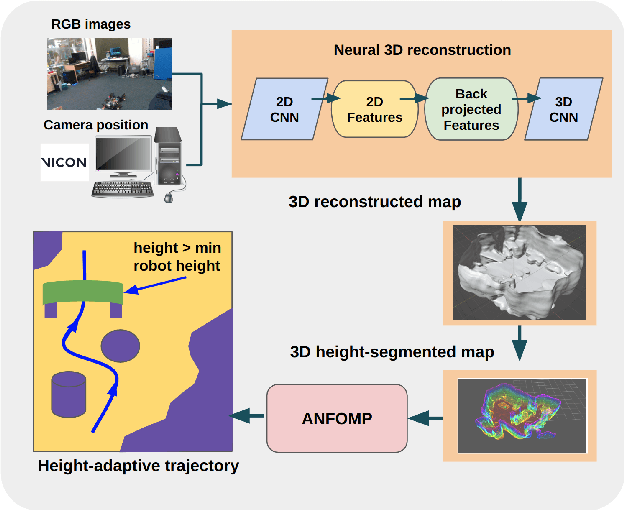

Quadruped robots have the distinct ability to adapt their body and step height to navigate through cluttered environments. Nonetheless, for these robots to utilize their full potential in real-world scenarios, they require awareness of their environment and obstacle geometry. We propose a novel multi-agent robotic system that incorporates cutting-edge technologies. The proposed solution features a 3D neural reconstruction algorithm that enables navigation of a quadruped robot in both static and semi-static environments. The prior areas of the environment are also segmented according to the quadruped robots' abilities to pass them. Moreover, we have developed an adaptive neural field optimal motion planner (ANFOMP) that considers both collision probability and obstacle height in 2D space.Our new navigation and mapping approach enables quadruped robots to adjust their height and behavior to navigate under arches and push through obstacles with smaller dimensions. The multi-agent mapping operation has proven to be highly accurate, with an obstacle reconstruction precision of 82%. Moreover, the quadruped robot can navigate with 3D obstacle information and the ANFOMP system, resulting in a 33.3% reduction in path length and a 70% reduction in navigation time.
Causal thinking for decision making on Electronic Health Records: why and how
Aug 03, 2023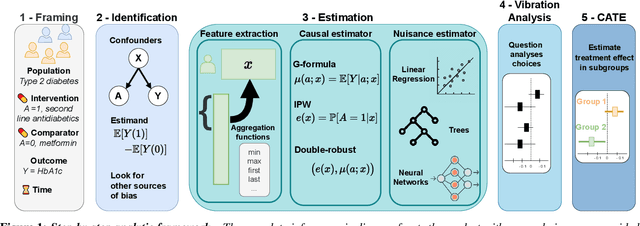

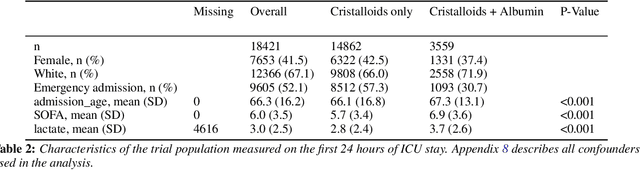
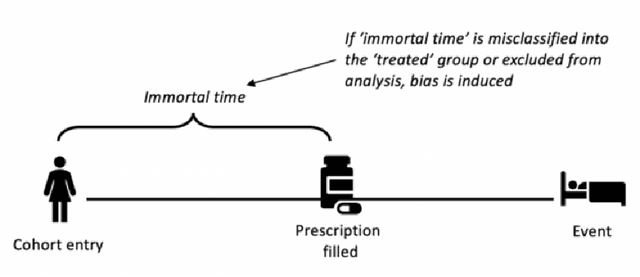
Accurate predictions, as with machine learning, may not suffice to provide optimal healthcare for every patient. Indeed, prediction can be driven by shortcuts in the data, such as racial biases. Causal thinking is needed for data-driven decisions. Here, we give an introduction to the key elements, focusing on routinely-collected data, electronic health records (EHRs) and claims data. Using such data to assess the value of an intervention requires care: temporal dependencies and existing practices easily confound the causal effect. We present a step-by-step framework to help build valid decision making from real-life patient records by emulating a randomized trial before individualizing decisions, eg with machine learning. Our framework highlights the most important pitfalls and considerations in analysing EHRs or claims data to draw causal conclusions. We illustrate the various choices in studying the effect of albumin on sepsis mortality in the Medical Information Mart for Intensive Care database (MIMIC-IV). We study the impact of various choices at every step, from feature extraction to causal-estimator selection. In a tutorial spirit, the code and the data are openly available.