 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Adaptive Preferential Attached kNN Graph With Distribution-Awareness
Aug 04, 2023
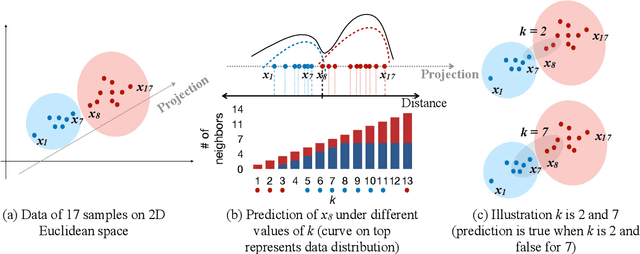
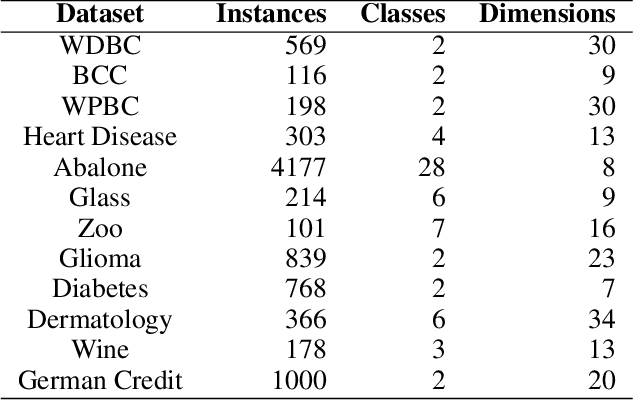
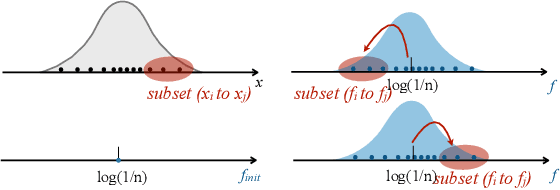
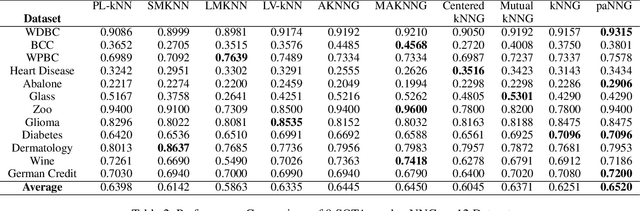
Graph-based kNN algorithms have garnered widespread popularity for machine learning tasks, due to their simplicity and effectiveness. However, the conventional kNN graph's reliance on a fixed value of k can hinder its performance, especially in scenarios involving complex data distributions. Moreover, like other classification models, the presence of ambiguous samples along decision boundaries often presents a challenge, as they are more prone to incorrect classification. To address these issues, we propose the Preferential Attached k-Nearest Neighbors Graph (paNNG), which combines adaptive kNN with distribution-based graph construction. By incorporating distribution information, paNNG can significantly improve performance for ambiguous samples by "pulling" them towards their original classes and hence enable enhanced overall accuracy and generalization capability. Through rigorous evaluations on diverse benchmark datasets, paNNG outperforms state-of-the-art algorithms, showcasing its adaptability and efficacy across various real-world scenarios.
InvVis: Large-Scale Data Embedding for Invertible Visualization
Aug 04, 2023
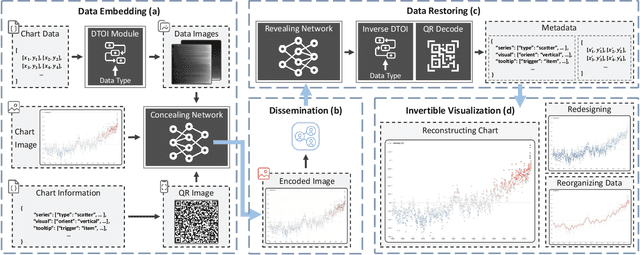
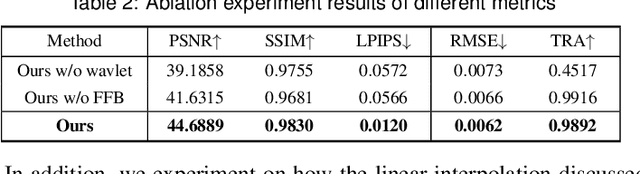
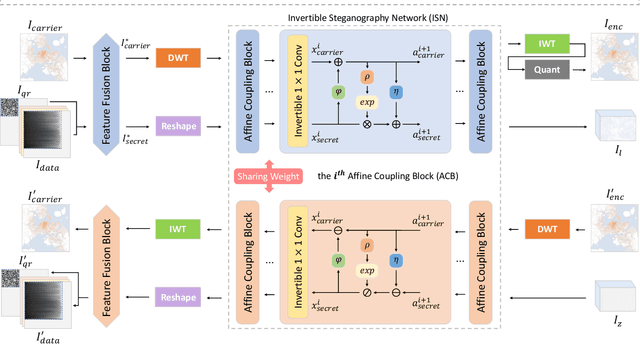
We present InvVis, a new approach for invertible visualization, which is reconstructing or further modifying a visualization from an image. InvVis allows the embedding of a significant amount of data, such as chart data, chart information, source code, etc., into visualization images. The encoded image is perceptually indistinguishable from the original one. We propose a new method to efficiently express chart data in the form of images, enabling large-capacity data embedding. We also outline a model based on the invertible neural network to achieve high-quality data concealing and revealing. We explore and implement a variety of application scenarios of InvVis. Additionally, we conduct a series of evaluation experiments to assess our method from multiple perspectives, including data embedding quality, data restoration accuracy, data encoding capacity, etc. The result of our experiments demonstrates the great potential of InvVis in invertible visualization.
Fluid Property Prediction Leveraging AI and Robotics
Aug 04, 2023Inferring liquid properties from vision is a challenging task due to the complex nature of fluids, both in behavior and detection. Nevertheless, the ability to infer their properties directly from visual information is highly valuable for autonomous fluid handling systems, as cameras are readily available. Moreover, predicting fluid properties purely from vision can accelerate the process of fluid characterization saving considerable time and effort in various experimental environments. In this work, we present a purely vision-based approach to estimate viscosity, leveraging the fact that the behavior of the fluid oscillations is directly related to the viscosity. Specifically, we utilize a 3D convolutional autoencoder to learn latent representations of different fluid-oscillating patterns present in videos. We leverage this latent representation to visually infer the category of fluid or the dynamics viscosity of fluid from video.
Adversaries with Limited Information in the Friedkin--Johnsen Model
Jun 17, 2023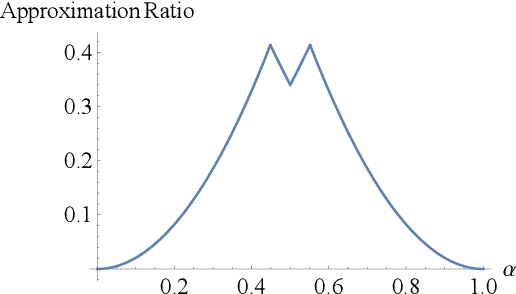
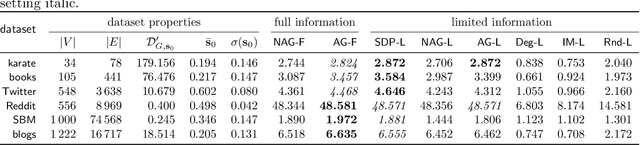
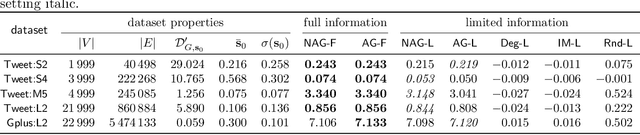
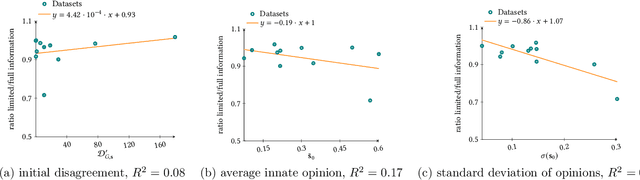
In recent years, online social networks have been the target of adversaries who seek to introduce discord into societies, to undermine democracies and to destabilize communities. Often the goal is not to favor a certain side of a conflict but to increase disagreement and polarization. To get a mathematical understanding of such attacks, researchers use opinion-formation models from sociology, such as the Friedkin--Johnsen model, and formally study how much discord the adversary can produce when altering the opinions for only a small set of users. In this line of work, it is commonly assumed that the adversary has full knowledge about the network topology and the opinions of all users. However, the latter assumption is often unrealistic in practice, where user opinions are not available or simply difficult to estimate accurately. To address this concern, we raise the following question: Can an attacker sow discord in a social network, even when only the network topology is known? We answer this question affirmatively. We present approximation algorithms for detecting a small set of users who are highly influential for the disagreement and polarization in the network. We show that when the adversary radicalizes these users and if the initial disagreement/polarization in the network is not very high, then our method gives a constant-factor approximation on the setting when the user opinions are known. To find the set of influential users, we provide a novel approximation algorithm for a variant of MaxCut in graphs with positive and negative edge weights. We experimentally evaluate our methods, which have access only to the network topology, and we find that they have similar performance as methods that have access to the network topology and all user opinions. We further present an NP-hardness proof, which was an open question by Chen and Racz [IEEE Trans. Netw. Sci. Eng., 2021].
Machine Learning, Deep Learning and Data Preprocessing Techniques for Detection, Prediction, and Monitoring of Stress and Stress-related Mental Disorders: A Scoping Review
Aug 08, 2023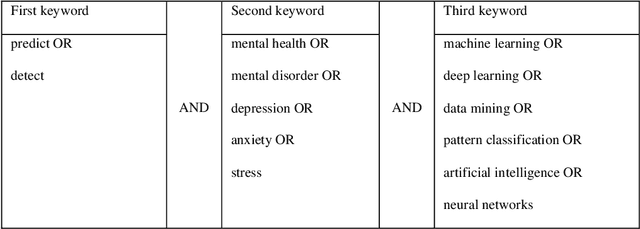
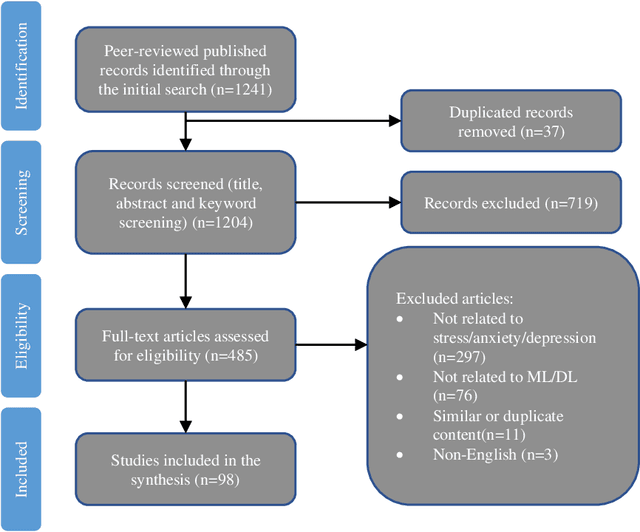
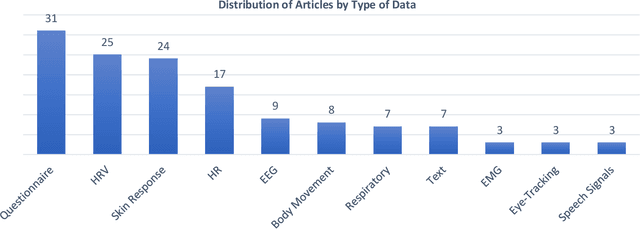
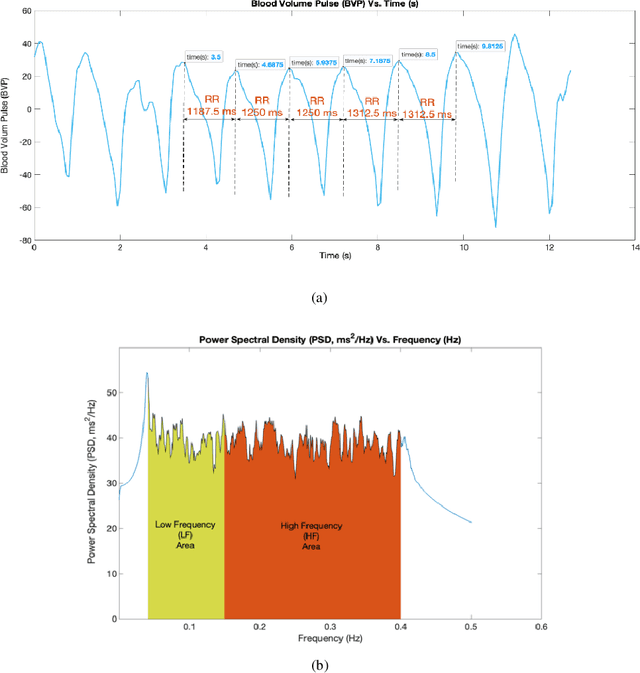
This comprehensive review systematically evaluates Machine Learning (ML) methodologies employed in the detection, prediction, and analysis of mental stress and its consequent mental disorders (MDs). Utilizing a rigorous scoping review process, the investigation delves into the latest ML algorithms, preprocessing techniques, and data types employed in the context of stress and stress-related MDs. The findings highlight that Support Vector Machine (SVM), Neural Network (NN), and Random Forest (RF) models consistently exhibit superior accuracy and robustness among all machine learning algorithms examined. Furthermore, the review underscores that physiological parameters, such as heart rate measurements and skin response, are prevalently used as stress predictors in ML algorithms. This is attributed to their rich explanatory information concerning stress and stress-related MDs, as well as the relative ease of data acquisition. Additionally, the application of dimensionality reduction techniques, including mappings, feature selection, filtering, and noise reduction, is frequently observed as a crucial step preceding the training of ML algorithms. The synthesis of this review identifies significant research gaps and outlines future directions for the field. These encompass areas such as model interpretability, model personalization, the incorporation of naturalistic settings, and real-time processing capabilities for detection and prediction of stress and stress-related MDs.
Actor-agnostic Multi-label Action Recognition with Multi-modal Query
Aug 08, 2023
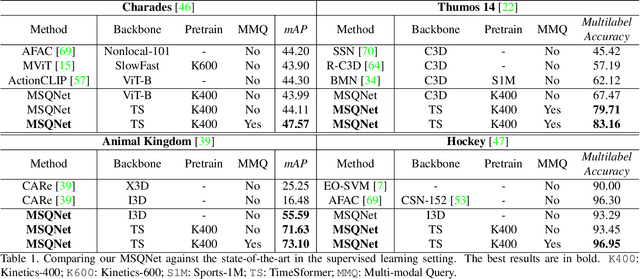
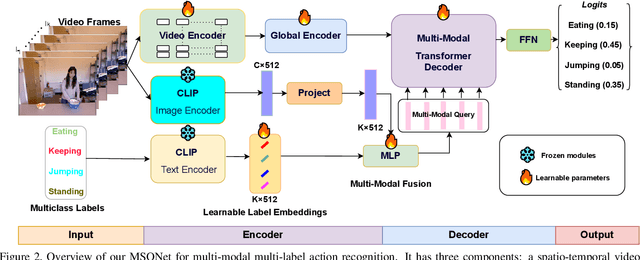

Existing action recognition methods are typically actor-specific due to the intrinsic topological and apparent differences among the actors. This requires actor-specific pose estimation (e.g., humans vs. animals), leading to cumbersome model design complexity and high maintenance costs. Moreover, they often focus on learning the visual modality alone and single-label classification whilst neglecting other available information sources (e.g., class name text) and the concurrent occurrence of multiple actions. To overcome these limitations, we propose a new approach called 'actor-agnostic multi-modal multi-label action recognition,' which offers a unified solution for various types of actors, including humans and animals. We further formulate a novel Multi-modal Semantic Query Network (MSQNet) model in a transformer-based object detection framework (e.g., DETR), characterized by leveraging visual and textual modalities to represent the action classes better. The elimination of actor-specific model designs is a key advantage, as it removes the need for actor pose estimation altogether. Extensive experiments on five publicly available benchmarks show that our MSQNet consistently outperforms the prior arts of actor-specific alternatives on human and animal single- and multi-label action recognition tasks by up to 50%. Code will be released at https://github.com/mondalanindya/MSQNet.
OmniDataComposer: A Unified Data Structure for Multimodal Data Fusion and Infinite Data Generation
Aug 08, 2023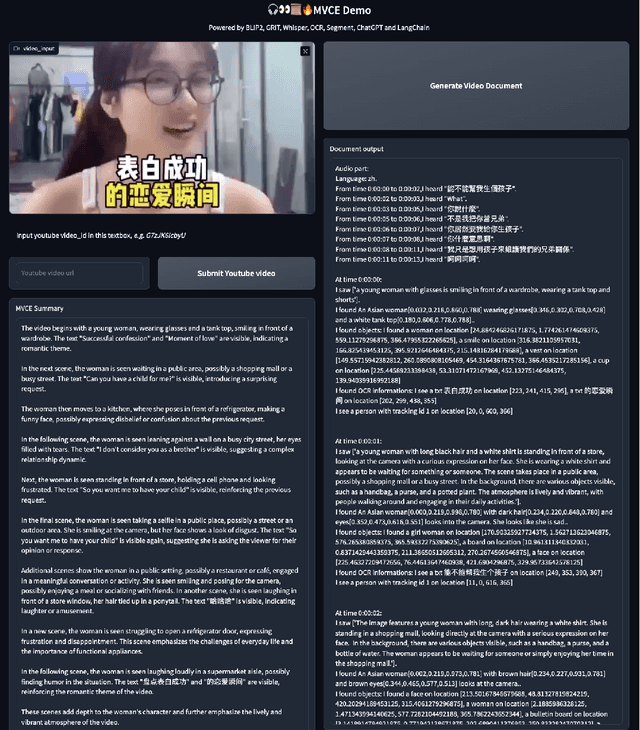
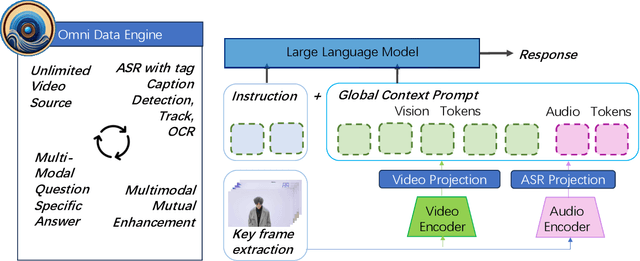

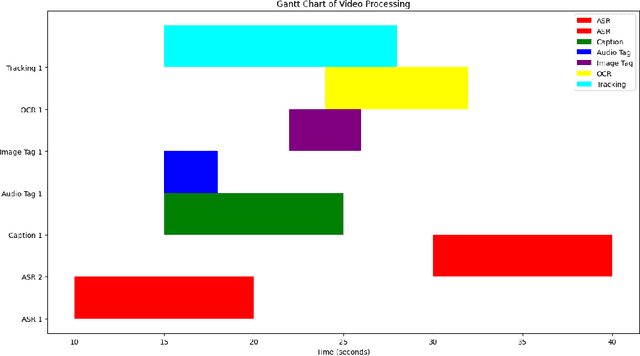
This paper presents OmniDataComposer, an innovative approach for multimodal data fusion and unlimited data generation with an intent to refine and uncomplicate interplay among diverse data modalities. Coming to the core breakthrough, it introduces a cohesive data structure proficient in processing and merging multimodal data inputs, which include video, audio, and text. Our crafted algorithm leverages advancements across multiple operations such as video/image caption extraction, dense caption extraction, Automatic Speech Recognition (ASR), Optical Character Recognition (OCR), Recognize Anything Model(RAM), and object tracking. OmniDataComposer is capable of identifying over 6400 categories of objects, substantially broadening the spectrum of visual information. It amalgamates these diverse modalities, promoting reciprocal enhancement among modalities and facilitating cross-modal data correction. \textbf{The final output metamorphoses each video input into an elaborate sequential document}, virtually transmuting videos into thorough narratives, making them easier to be processed by large language models. Future prospects include optimizing datasets for each modality to encourage unlimited data generation. This robust base will offer priceless insights to models like ChatGPT, enabling them to create higher quality datasets for video captioning and easing question-answering tasks based on video content. OmniDataComposer inaugurates a new stage in multimodal learning, imparting enormous potential for augmenting AI's understanding and generation of complex, real-world data.
Application for White Spot Syndrome Virus (WSSV) Monitoring using Edge Machine Learning
Aug 08, 2023The aquaculture industry, strongly reliant on shrimp exports, faces challenges due to viral infections like the White Spot Syndrome Virus (WSSV) that severely impact output yields. In this context, computer vision can play a significant role in identifying features not immediately evident to skilled or untrained eyes, potentially reducing the time required to report WSSV infections. In this study, the challenge of limited data for WSSV recognition was addressed. A mobile application dedicated to data collection and monitoring was developed to facilitate the creation of an image dataset to train a WSSV recognition model and improve country-wide disease surveillance. The study also includes a thorough analysis of WSSV recognition to address the challenge of imbalanced learning and on-device inference. The models explored, MobileNetV3-Small and EfficientNetV2-B0, gained an F1-Score of 0.72 and 0.99 respectively. The saliency heatmaps of both models were also observed to uncover the "black-box" nature of these models and to gain insight as to what features in the images are most important in making a prediction. These results highlight the effectiveness and limitations of using models designed for resource-constrained devices and balancing their performance in accurately recognizing WSSV, providing valuable information and direction in the use of computer vision in this domain.
Multi-level Map Construction for Dynamic Scenes
Aug 08, 2023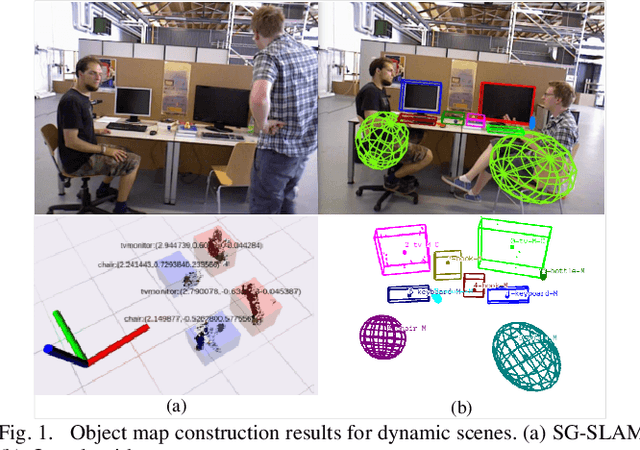
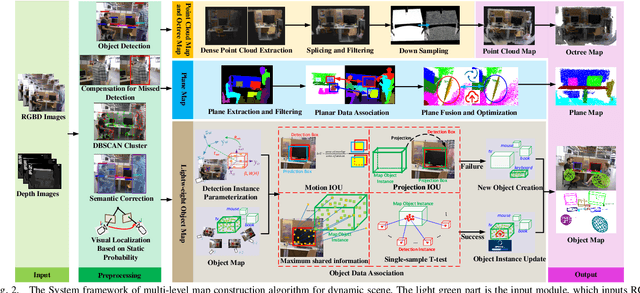
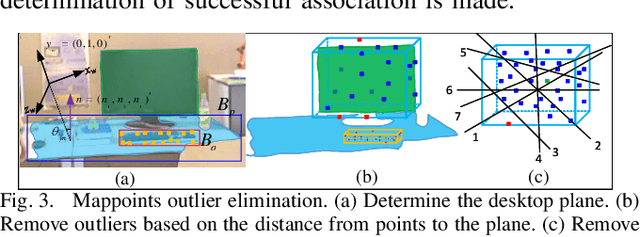

In dynamic scenes, both localization and mapping in visual SLAM face significant challenges. In recent years, numerous outstanding research works have proposed effective solutions for the localization problem. However, there has been a scarcity of excellent works focusing on constructing long-term consistent maps in dynamic scenes, which severely hampers map applications. To address this issue, we have designed a multi-level map construction system tailored for dynamic scenes. In this system, we employ multi-object tracking algorithms, DBSCAN clustering algorithm, and depth information to rectify the results of object detection, accurately extract static point clouds, and construct dense point cloud maps and octree maps. We propose a plane map construction algorithm specialized for dynamic scenes, involving the extraction, filtering, data association, and fusion optimization of planes in dynamic environments, thus creating a plane map. Additionally, we introduce an object map construction algorithm targeted at dynamic scenes, which includes object parameterization, data association, and update optimization. Extensive experiments on public datasets and real-world scenarios validate the accuracy of the multi-level maps constructed in this study and the robustness of the proposed algorithms. Furthermore, we demonstrate the practical application prospects of our algorithms by utilizing the constructed object maps for dynamic object tracking.
V-DETR: DETR with Vertex Relative Position Encoding for 3D Object Detection
Aug 08, 2023
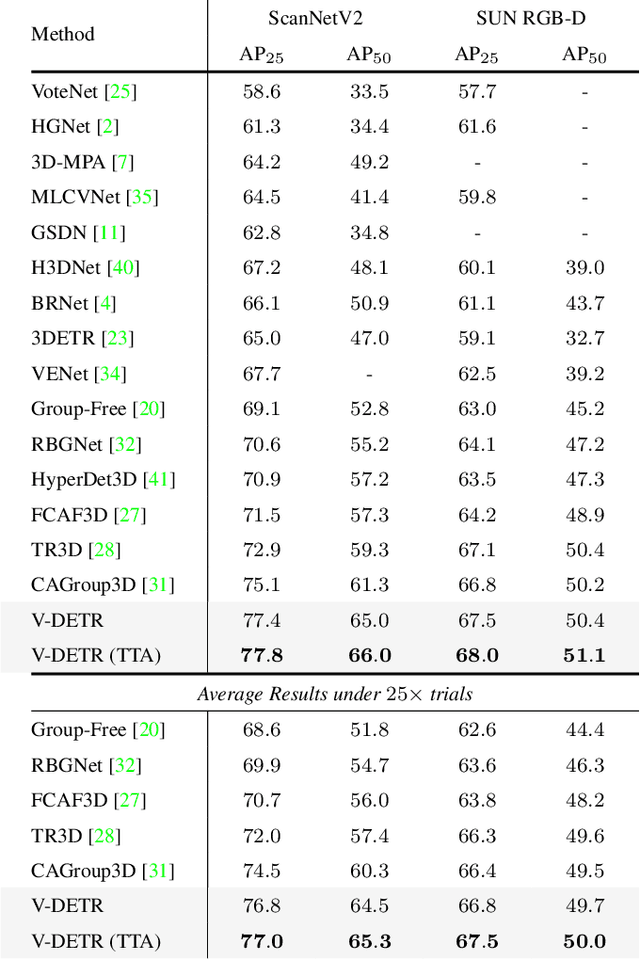

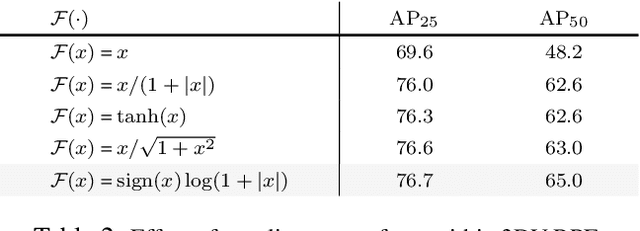
We introduce a highly performant 3D object detector for point clouds using the DETR framework. The prior attempts all end up with suboptimal results because they fail to learn accurate inductive biases from the limited scale of training data. In particular, the queries often attend to points that are far away from the target objects, violating the locality principle in object detection. To address the limitation, we introduce a novel 3D Vertex Relative Position Encoding (3DV-RPE) method which computes position encoding for each point based on its relative position to the 3D boxes predicted by the queries in each decoder layer, thus providing clear information to guide the model to focus on points near the objects, in accordance with the principle of locality. In addition, we systematically improve the pipeline from various aspects such as data normalization based on our understanding of the task. We show exceptional results on the challenging ScanNetV2 benchmark, achieving significant improvements over the previous 3DETR in $\rm{AP}_{25}$/$\rm{AP}_{50}$ from 65.0\%/47.0\% to 77.8\%/66.0\%, respectively. In addition, our method sets a new record on ScanNetV2 and SUN RGB-D datasets.Code will be released at http://github.com/yichaoshen-MS/V-DETR.