 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Can LSH (Locality-Sensitive Hashing) Be Replaced by Neural Network?
Oct 15, 2023
With the rapid development of GPU (Graphics Processing Unit) technologies and neural networks, we can explore more appropriate data structures and algorithms. Recent progress shows that neural networks can partly replace traditional data structures. In this paper, we proposed a novel DNN (Deep Neural Network)-based learned locality-sensitive hashing, called LLSH, to efficiently and flexibly map high-dimensional data to low-dimensional space. LLSH replaces the traditional LSH (Locality-sensitive Hashing) function families with parallel multi-layer neural networks, which reduces the time and memory consumption and guarantees query accuracy simultaneously. The proposed LLSH demonstrate the feasibility of replacing the hash index with learning-based neural networks and open a new door for developers to design and configure data organization more accurately to improve information-searching performance. Extensive experiments on different types of datasets show the superiority of the proposed method in query accuracy, time consumption, and memory usage.
VLIS: Unimodal Language Models Guide Multimodal Language Generation
Oct 15, 2023Multimodal language generation, which leverages the synergy of language and vision, is a rapidly expanding field. However, existing vision-language models face challenges in tasks that require complex linguistic understanding. To address this issue, we introduce Visual-Language models as Importance Sampling weights (VLIS), a novel framework that combines the visual conditioning capability of vision-language models with the language understanding of unimodal text-only language models without further training. It extracts pointwise mutual information of each image and text from a visual-language model and uses the value as an importance sampling weight to adjust the token likelihood from a text-only model. VLIS improves vision-language models on diverse tasks, including commonsense understanding (WHOOPS, OK-VQA, and ScienceQA) and complex text generation (Concadia, Image Paragraph Captioning, and ROCStories). Our results suggest that VLIS represents a promising new direction for multimodal language generation.
Multi-Dimension-Embedding-Aware Modality Fusion Transformer for Psychiatric Disorder Clasification
Oct 04, 2023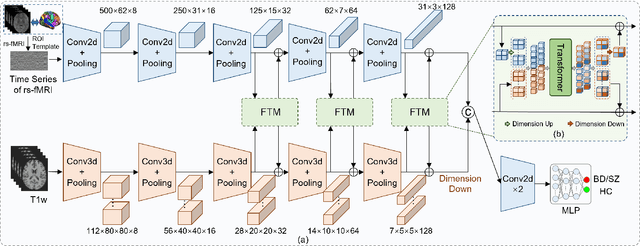
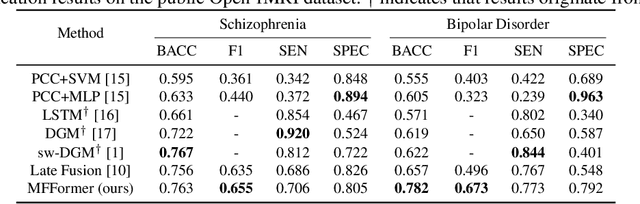
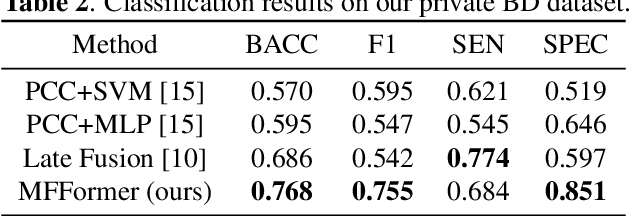
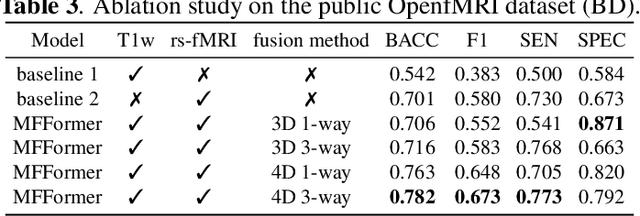
Deep learning approaches, together with neuroimaging techniques, play an important role in psychiatric disorders classification. Previous studies on psychiatric disorders diagnosis mainly focus on using functional connectivity matrices of resting-state functional magnetic resonance imaging (rs-fMRI) as input, which still needs to fully utilize the rich temporal information of the time series of rs-fMRI data. In this work, we proposed a multi-dimension-embedding-aware modality fusion transformer (MFFormer) for schizophrenia and bipolar disorder classification using rs-fMRI and T1 weighted structural MRI (T1w sMRI). Concretely, to fully utilize the temporal information of rs-fMRI and spatial information of sMRI, we constructed a deep learning architecture that takes as input 2D time series of rs-fMRI and 3D volumes T1w. Furthermore, to promote intra-modality attention and information fusion across different modalities, a fusion transformer module (FTM) is designed through extensive self-attention of hybrid feature maps of multi-modality. In addition, a dimension-up and dimension-down strategy is suggested to properly align feature maps of multi-dimensional from different modalities. Experimental results on our private and public OpenfMRI datasets show that our proposed MFFormer performs better than that using a single modality or multi-modality MRI on schizophrenia and bipolar disorder diagnosis.
Time-to-Pattern: Information-Theoretic Unsupervised Learning for Scalable Time Series Summarization
Aug 26, 2023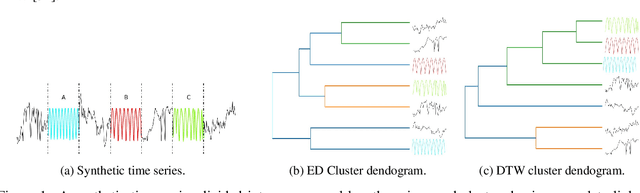
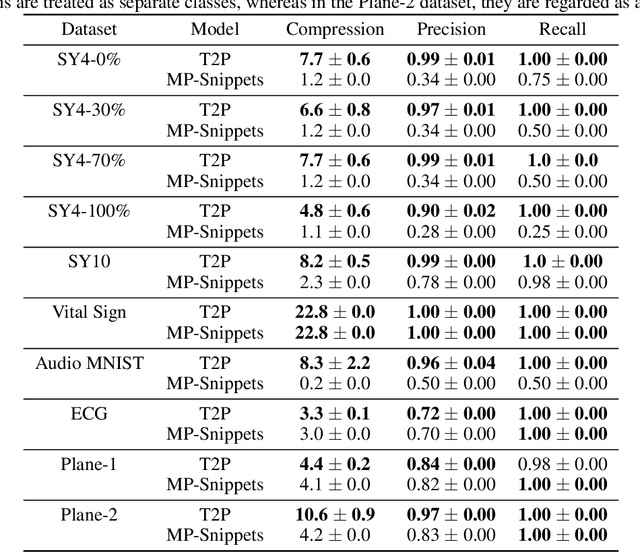
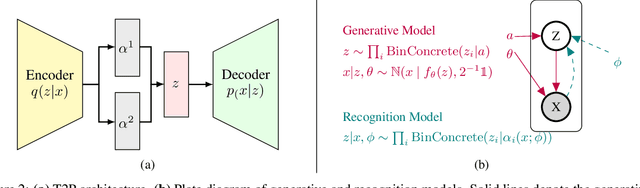

Data summarization is the process of generating interpretable and representative subsets from a dataset. Existing time series summarization approaches often search for recurring subsequences using a set of manually devised similarity functions to summarize the data. However, such approaches are fraught with limitations stemming from an exhaustive search coupled with a heuristic definition of series similarity. Such approaches affect the diversity and comprehensiveness of the generated data summaries. To mitigate these limitations, we introduce an approach to time series summarization, called Time-to-Pattern (T2P), which aims to find a set of diverse patterns that together encode the most salient information, following the notion of minimum description length. T2P is implemented as a deep generative model that learns informative embeddings of the discrete time series on a latent space specifically designed to be interpretable. Our synthetic and real-world experiments reveal that T2P discovers informative patterns, even in noisy and complex settings. Furthermore, our results also showcase the improved performance of T2P over previous work in pattern diversity and processing scalability, which conclusively demonstrate the algorithm's effectiveness for time series summarization.
Localizing and Editing Knowledge in Text-to-Image Generative Models
Oct 20, 2023Text-to-Image Diffusion Models such as Stable-Diffusion and Imagen have achieved unprecedented quality of photorealism with state-of-the-art FID scores on MS-COCO and other generation benchmarks. Given a caption, image generation requires fine-grained knowledge about attributes such as object structure, style, and viewpoint amongst others. Where does this information reside in text-to-image generative models? In our paper, we tackle this question and understand how knowledge corresponding to distinct visual attributes is stored in large-scale text-to-image diffusion models. We adapt Causal Mediation Analysis for text-to-image models and trace knowledge about distinct visual attributes to various (causal) components in the (i) UNet and (ii) text-encoder of the diffusion model. In particular, we show that unlike generative large-language models, knowledge about different attributes is not localized in isolated components, but is instead distributed amongst a set of components in the conditional UNet. These sets of components are often distinct for different visual attributes. Remarkably, we find that the CLIP text-encoder in public text-to-image models such as Stable-Diffusion contains only one causal state across different visual attributes, and this is the first self-attention layer corresponding to the last subject token of the attribute in the caption. This is in stark contrast to the causal states in other language models which are often the mid-MLP layers. Based on this observation of only one causal state in the text-encoder, we introduce a fast, data-free model editing method Diff-QuickFix which can effectively edit concepts in text-to-image models. DiffQuickFix can edit (ablate) concepts in under a second with a closed-form update, providing a significant 1000x speedup and comparable editing performance to existing fine-tuning based editing methods.
Identification of Abnormality in Maize Plants From UAV Images Using Deep Learning Approaches
Oct 20, 2023Early identification of abnormalities in plants is an important task for ensuring proper growth and achieving high yields from crops. Precision agriculture can significantly benefit from modern computer vision tools to make farming strategies addressing these issues efficient and effective. As farming lands are typically quite large, farmers have to manually check vast areas to determine the status of the plants and apply proper treatments. In this work, we consider the problem of automatically identifying abnormal regions in maize plants from images captured by a UAV. Using deep learning techniques, we have developed a methodology which can detect different levels of abnormality (i.e., low, medium, high or no abnormality) in maize plants independently of their growth stage. The primary goal is to identify anomalies at the earliest possible stage in order to maximize the effectiveness of potential treatments. At the same time, the proposed system can provide valuable information to human annotators for ground truth data collection by helping them to focus their attention on a much smaller set of images only. We have experimented with two different but complimentary approaches, the first considering abnormality detection as a classification problem and the second considering it as a regression problem. Both approaches can be generalized to different types of abnormalities and do not make any assumption about the abnormality occurring at an early plant growth stage which might be easier to detect due to the plants being smaller and easier to separate. As a case study, we have considered a publicly available data set which exhibits mostly Nitrogen deficiency in maize plants of various growth stages. We are reporting promising preliminary results with an 88.89\% detection accuracy of low abnormality and 100\% detection accuracy of no abnormality.
Joint object detection and re-identification for 3D obstacle multi-camera systems
Oct 09, 2023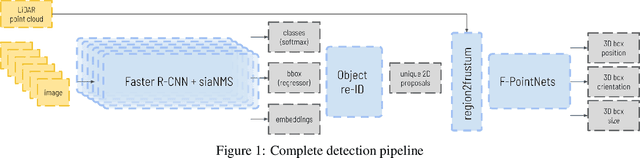
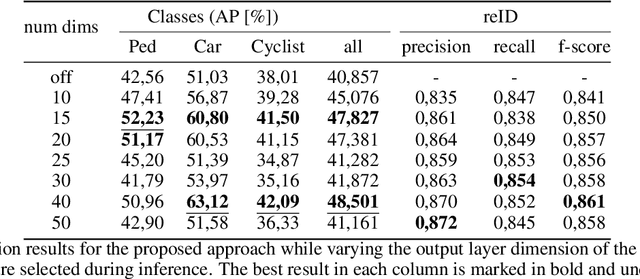
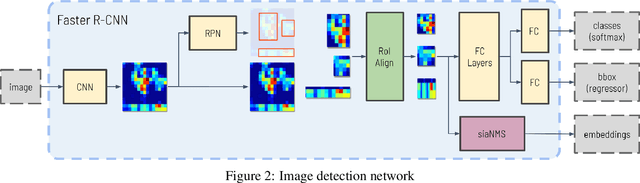
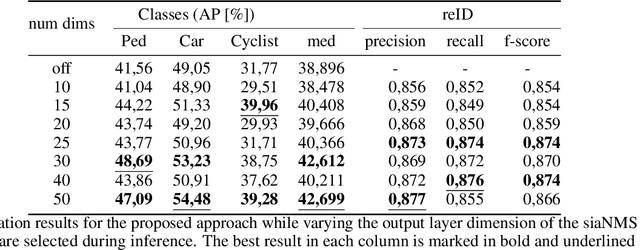
In recent years, the field of autonomous driving has witnessed remarkable advancements, driven by the integration of a multitude of sensors, including cameras and LiDAR systems, in different prototypes. However, with the proliferation of sensor data comes the pressing need for more sophisticated information processing techniques. This research paper introduces a novel modification to an object detection network that uses camera and lidar information, incorporating an additional branch designed for the task of re-identifying objects across adjacent cameras within the same vehicle while elevating the quality of the baseline 3D object detection outcomes. The proposed methodology employs a two-step detection pipeline: initially, an object detection network is employed, followed by a 3D box estimator that operates on the filtered point cloud generated from the network's detections. Extensive experimental evaluations encompassing both 2D and 3D domains validate the effectiveness of the proposed approach and the results underscore the superiority of this method over traditional Non-Maximum Suppression (NMS) techniques, with an improvement of more than 5\% in the car category in the overlapping areas.
Predicting Ovarian Cancer Treatment Response in Histopathology using Hierarchical Vision Transformers and Multiple Instance Learning
Oct 19, 2023
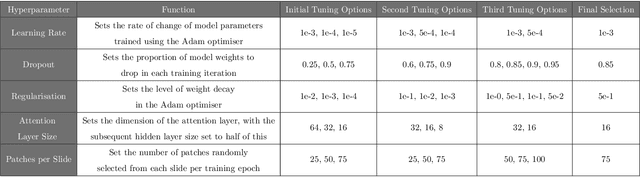
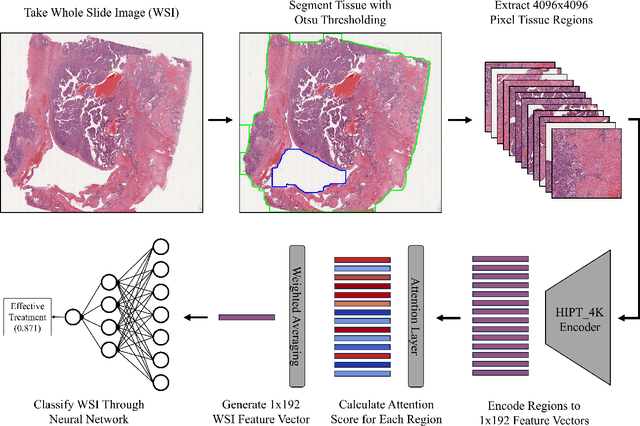

For many patients, current ovarian cancer treatments offer limited clinical benefit. For some therapies, it is not possible to predict patients' responses, potentially exposing them to the adverse effects of treatment without any therapeutic benefit. As part of the automated prediction of treatment effectiveness in ovarian cancer using histopathological images (ATEC23) challenge, we evaluated the effectiveness of deep learning to predict whether a course of treatment including the antiangiogenic drug bevacizumab could contribute to remission or prevent disease progression for at least 6 months in a set of 282 histopathology whole slide images (WSIs) from 78 ovarian cancer patients. Our approach used a pretrained Hierarchical Image Pyramid Transformer (HIPT) to extract region-level features and an attention-based multiple instance learning (ABMIL) model to aggregate features and classify whole slides. The optimal HIPT-ABMIL model had an internal balanced accuracy of 60.2% +- 2.9% and an AUC of 0.646 +- 0.033. Histopathology-specific model pretraining was found to be beneficial to classification performance, though hierarchical transformers were not, with a ResNet feature extractor achieving similar performance. Due to the dataset being small and highly heterogeneous, performance was variable across 5-fold cross-validation folds, and there were some extreme differences between validation and test set performance within folds. The model did not generalise well to tissue microarrays, with accuracy worse than random chance. It is not yet clear whether ovarian cancer WSIs contain information that can be used to accurately predict treatment response, with further validation using larger, higher-quality datasets required.
Frozen Transformers in Language Models Are Effective Visual Encoder Layers
Oct 19, 2023This paper reveals that large language models (LLMs), despite being trained solely on textual data, are surprisingly strong encoders for purely visual tasks in the absence of language. Even more intriguingly, this can be achieved by a simple yet previously overlooked strategy -- employing a frozen transformer block from pre-trained LLMs as a constituent encoder layer to directly process visual tokens. Our work pushes the boundaries of leveraging LLMs for computer vision tasks, significantly departing from conventional practices that typically necessitate a multi-modal vision-language setup with associated language prompts, inputs, or outputs. We demonstrate that our approach consistently enhances performance across a diverse range of tasks, encompassing pure 2D and 3D visual recognition tasks (e.g., image and point cloud classification), temporal modeling tasks (e.g., action recognition), non-semantic tasks (e.g., motion forecasting), and multi-modal tasks (e.g., 2D/3D visual question answering and image-text retrieval). Such improvements are a general phenomenon, applicable to various types of LLMs (e.g., LLaMA and OPT) and different LLM transformer blocks. We additionally propose the information filtering hypothesis to explain the effectiveness of pre-trained LLMs in visual encoding -- the pre-trained LLM transformer blocks discern informative visual tokens and further amplify their effect. This hypothesis is empirically supported by the observation that the feature activation, after training with LLM transformer blocks, exhibits a stronger focus on relevant regions. We hope that our work inspires new perspectives on utilizing LLMs and deepening our understanding of their underlying mechanisms. Code is available at https://github.com/ziqipang/LM4VisualEncoding.
Canonical normalizing flows for manifold learning
Oct 19, 2023
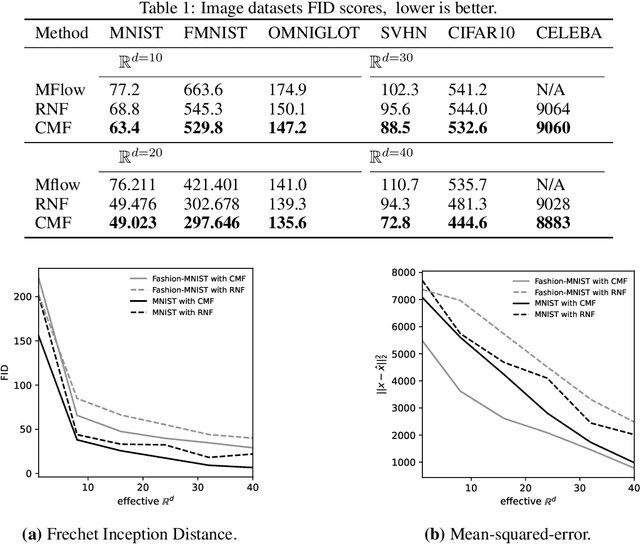
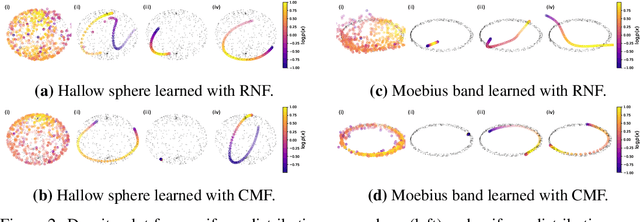
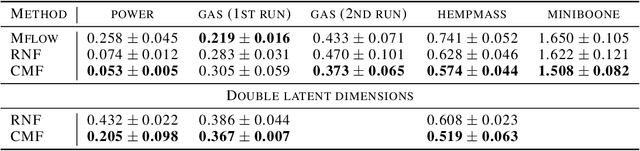
Manifold learning flows are a class of generative modelling techniques that assume a low-dimensional manifold description of the data. The embedding of such manifold into the high-dimensional space of the data is achieved via learnable invertible transformations. Therefore, once the manifold is properly aligned via a reconstruction loss, the probability density is tractable on the manifold and maximum likelihood can be used optimize the network parameters. Naturally, the lower-dimensional representation of the data requires an injective-mapping. Recent approaches were able to enforce that density aligns with the modelled manifold, while efficiently calculating the density volume-change term when embedding to the higher-dimensional space. However, unless the injective-mapping is analytically predefined, the learned manifold is not necessarily an efficient representation of the data. Namely, the latent dimensions of such models frequently learn an entangled intrinsic basis with degenerate information being stored in each dimension. Alternatively, if a locally orthogonal and/or sparse basis is to be learned, here coined canonical intrinsic basis, it can serve in learning a more compact latent space representation. Towards this end, we propose a canonical manifold learning flow method, where a novel optimization objective enforces the transformation matrix to have few prominent and orthogonal basis functions. Canonical manifold flow yields a more efficient use of the latent space, automatically generating fewer prominent and distinct dimensions to represent data, and consequently a better approximation of target distributions than other manifold flow methods in most experiments we conducted, resulting in lower FID scores.