 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An overview of deep learning in medical imaging focusing on MRI
Nov 25, 2018
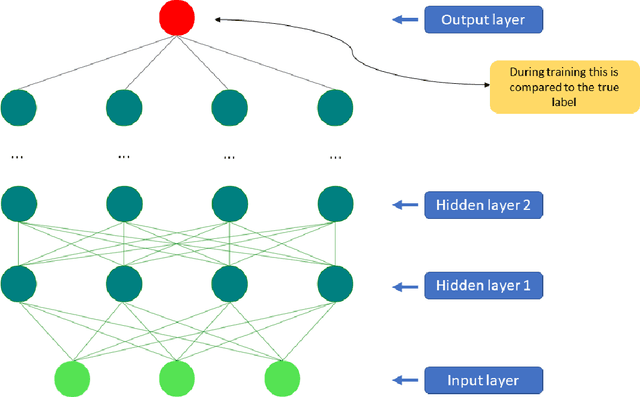
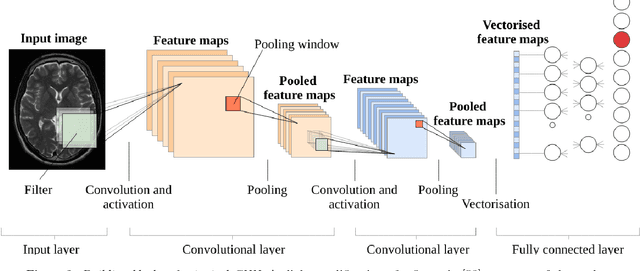
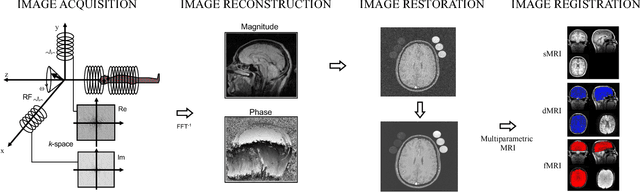

What has happened in machine learning lately, and what does it mean for the future of medical image analysis? Machine learning has witnessed a tremendous amount of attention over the last few years. The current boom started around 2009 when so-called deep artificial neural networks began outperforming other established models on a number of important benchmarks. Deep neural networks are now the state-of-the-art machine learning models across a variety of areas, from image analysis to natural language processing, and widely deployed in academia and industry. These developments have a huge potential for medical imaging technology, medical data analysis, medical diagnostics and healthcare in general, slowly being realized. We provide a short overview of recent advances and some associated challenges in machine learning applied to medical image processing and image analysis. As this has become a very broad and fast expanding field we will not survey the entire landscape of applications, but put particular focus on deep learning in MRI. Our aim is threefold: (i) give a brief introduction to deep learning with pointers to core references; (ii) indicate how deep learning has been applied to the entire MRI processing chain, from acquisition to image retrieval, from segmentation to disease prediction; (iii) provide a starting point for people interested in experimenting and perhaps contributing to the field of machine learning for medical imaging by pointing out good educational resources, state-of-the-art open-source code, and interesting sources of data and problems related medical imaging.
Object Segmentation Tracking from Generic Video Cues
Oct 05, 2019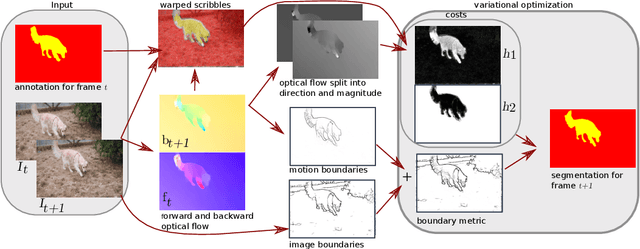
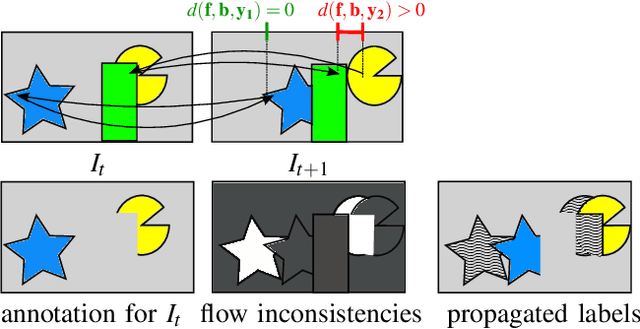
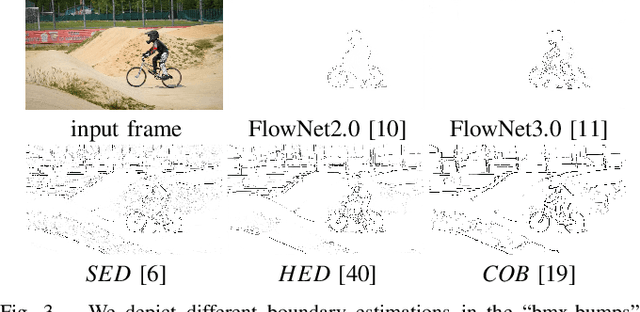

We propose a light-weight variational framework for online tracking of object segmentations in videos based on optical flow and image boundaries. While high-end computer vision methods on this task rely on sequence specific training of dedicated CNN architectures, we show the potential of a variational model, based on generic video information from motion and color. Such cues are usually required for tasks such as robot navigation or grasp estimation. We leverage them directly for video object segmentation and thus provide accurate segmentations at potentially very low extra cost. Furthermore, we show that our approach can be combined with state-of-the-art CNN-based segmentations in order to improve over their respective results. We evaluate our method on the datasets DAVIS16,17 and SegTrack v2.
AdaFilter: Adaptive Filter Fine-tuning for Deep Transfer Learning
Dec 09, 2019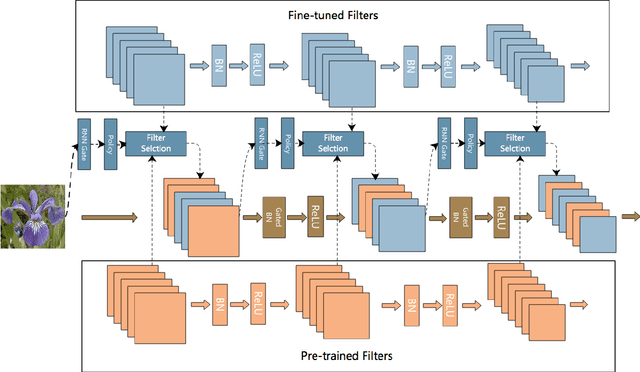
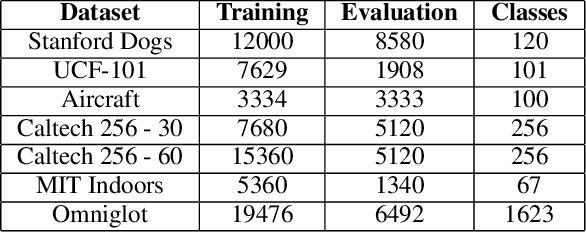
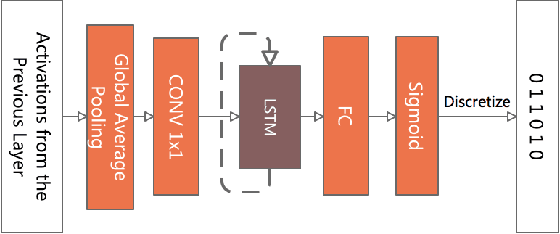

There is an increasing number of pre-trained deep neural network models. However, it is still unclear how to effectively use these models for a new task. Transfer learning, which aims to transfer knowledge from source tasks to a target task, is an effective solution to this problem. Fine-tuning is a popular transfer learning technique for deep neural networks where a few rounds of training are applied to the parameters of a pre-trained model to adapt them to a new task. Despite its popularity, in this paper, we show that fine-tuning suffers from several drawbacks. We propose an adaptive fine-tuning approach, called AdaFilter, which selects only a part of the convolutional filters in the pre-trained model to optimize on a per-example basis. We use a recurrent gated network to selectively fine-tune convolutional filters based on the activations of the previous layer. We experiment with 7 public image classification datasets and the results show that AdaFilter can reduce the average classification error of the standard fine-tuning by 2.54%.
Efficient Video Semantic Segmentation with Labels Propagation and Refinement
Dec 26, 2019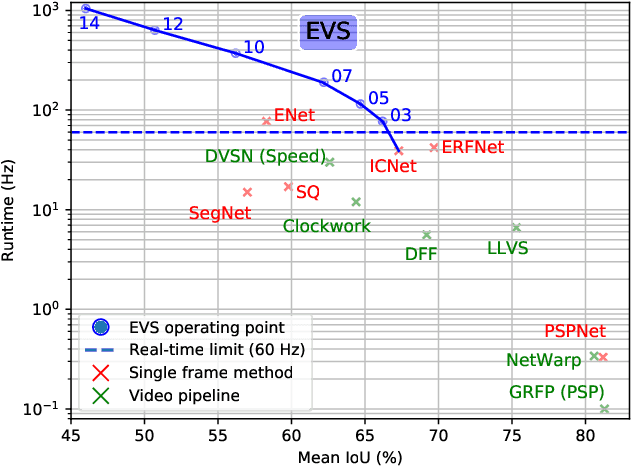

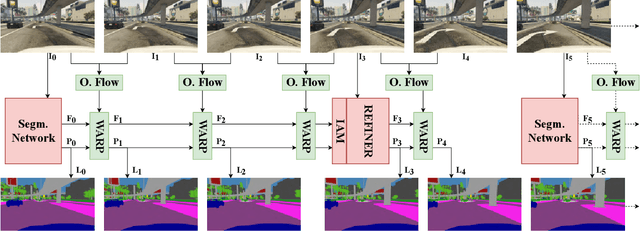
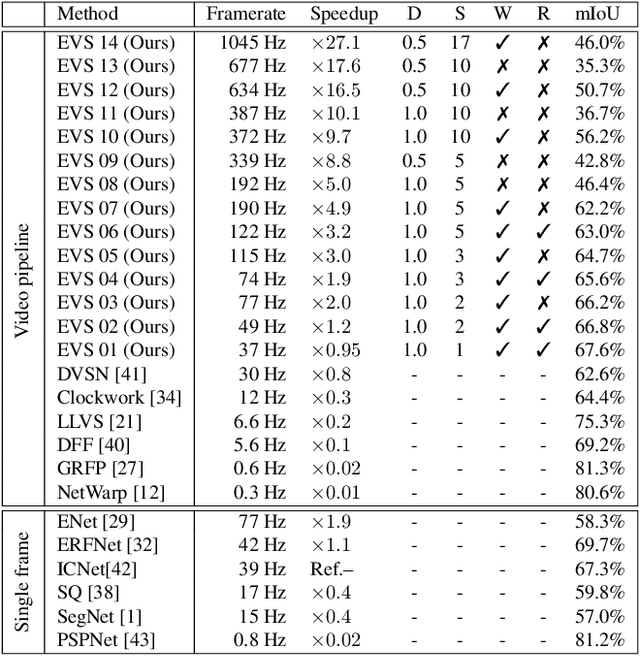
This paper tackles the problem of real-time semantic segmentation of high definition videos using a hybrid GPU / CPU approach. We propose an Efficient Video Segmentation(EVS) pipeline that combines: (i) On the CPU, a very fast optical flow method, that is used to exploit the temporal aspect of the video and propagate semantic information from one frame to the next. It runs in parallel with the GPU. (ii) On the GPU, two Convolutional Neural Networks: A main segmentation network that is used to predict dense semantic labels from scratch, and a Refiner that is designed to improve predictions from previous frames with the help of a fast Inconsistencies Attention Module (IAM). The latter can identify regions that cannot be propagated accurately. We suggest several operating points depending on the desired frame rate and accuracy. Our pipeline achieves accuracy levels competitive to the existing real-time methods for semantic image segmentation(mIoU above 60%), while achieving much higher frame rates. On the popular Cityscapes dataset with high resolution frames (2048 x 1024), the proposed operating points range from 80 to 1000 Hz on a single GPU and CPU.
Real-time and robust multiple-view gender classification using gait features in video surveillance
May 03, 2019
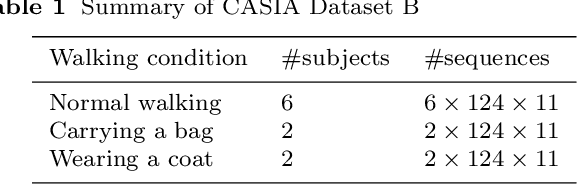
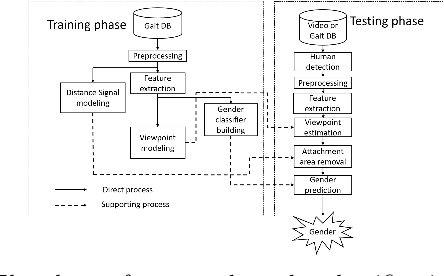
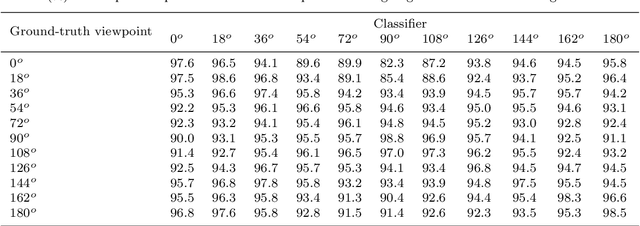
It is common to view people in real applications walking in arbitrary directions, holding items, or wearing heavy coats. These factors are challenges in gait-based application methods because they significantly change a person's appearance. This paper proposes a novel method for classifying human gender in real time using gait information. The use of an average gait image (AGI), rather than a gait energy image (GEI), allows this method to be computationally efficient and robust against view changes. A viewpoint (VP) model is created for automatically determining the viewing angle during the testing phase. A distance signal (DS) model is constructed to remove any areas with an attachment (carried items, worn coats) from a silhouette to reduce the interference in the resulting classification. Finally, the human gender is classified using multiple view-dependent classifiers trained using a support vector machine. Experiment results confirm that the proposed method achieves a high accuracy of 98.8% on the CASIA Dataset B and outperforms the recent state-of-the-art methods.
Bivariate Beta LSTM
May 25, 2019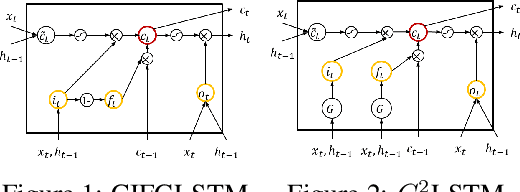
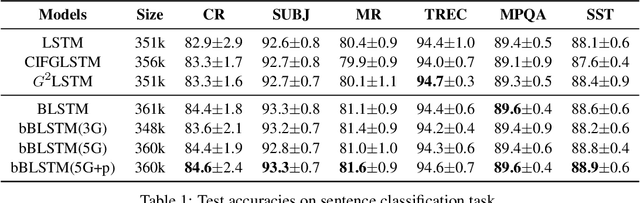
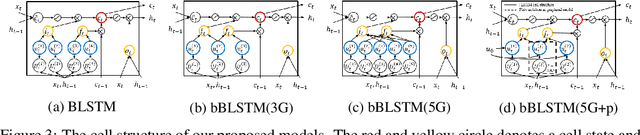
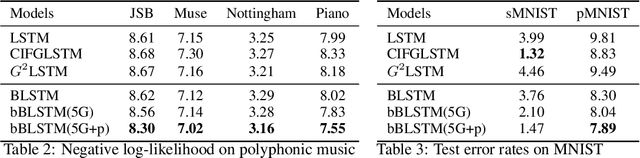
Long Short-Term Memory (LSTM) infers the long term dependency through a cell state maintained by the input and the forget gate structures, which models a gate output as a value in [0,1] through a sigmoid function. However, due to the graduality of the sigmoid function, the sigmoid gate is not flexible in representing multi-modality or skewness. Besides, the previous models lack correlation modeling between the gates, which would be a new method to adopt domain knowledge. This paper proposes a new gate structure with the bivariate Beta distribution. The proposed gate structure enables hierarchical probabilistic modeling on the gates within the LSTM cell, so the modelers can customize the cell state flow. Also, we observed that our structured flexible gate modeling is enabled by the probability density estimation. Moreover, we theoretically show and empirically experiment that the bivariate Beta distribution gate structure alleviates the gradient vanishing problem. We demonstrate the effectiveness of bivariate Beta gate structure on the sentence classification, image classification, polyphonic music modeling, and image caption generation.
Arbitrary Style Transfer with Style-Attentional Networks
Dec 10, 2018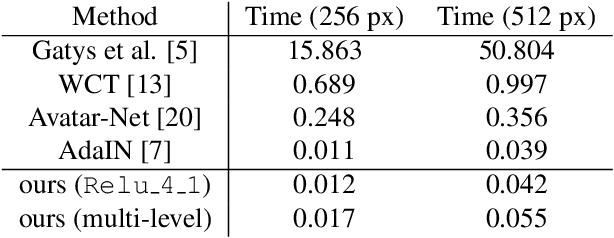
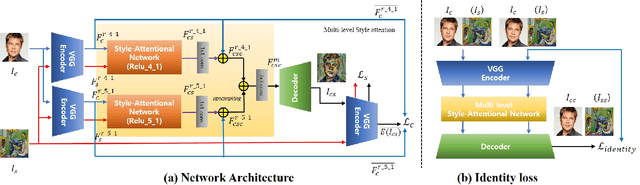
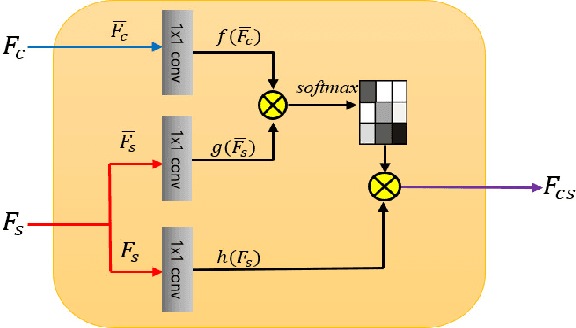
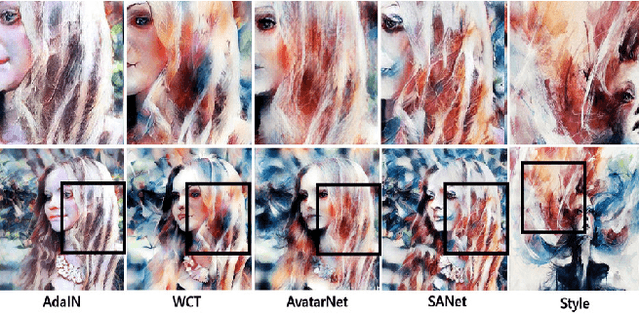
Arbitrary style transfer aims to synthesize a content image with style of an image that has never been seen before. Recent arbitrary style transfer algorithms have trade-off between the content structure and the style patterns, or maintaining the global and local style patterns at the same time is difficult due to the patch-based mechanism. In this paper, we introduce a novel style-attentional network (SANet), which efficiently and flexibly decorates the local style patterns according to the semantic spatial distribution of the content image. A new identity loss function and a multi-level features embedding also make our SANet and decoder preserve the content structure as much as possible while enriching the style patterns. Experimental results demonstrate that our algorithm synthesizes higher-quality stylized images in real-time than the state-of-the-art-algorithms.
A data-driven choice of misfit function for FWI using reinforcement learning
Feb 08, 2020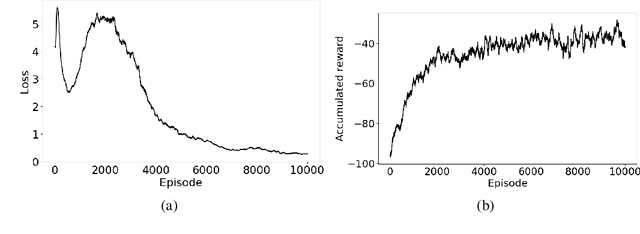
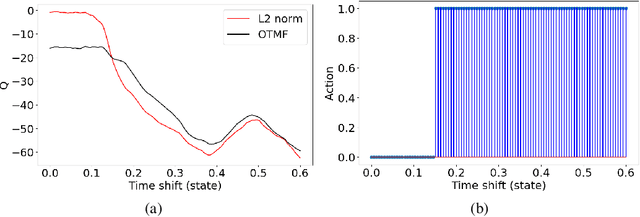
In the workflow of Full-Waveform Inversion (FWI), we often tune the parameters of the inversion to help us avoid cycle skipping and obtain high resolution models. For example, typically start by using objective functions that avoid cycle skipping, like tomographic and image based or using only low frequency, and then later, we utilize the least squares misfit to admit high resolution information. We also may perform an isotropic (acoustic) inversion to first update the velocity model and then switch to multi-parameter anisotropic (elastic) inversions to fully recover the complex physics. Such hierarchical approaches are common in FWI, and they often depend on our manual intervention based on many factors, and of course, results depend on experience. However, with the large data size often involved in the inversion and the complexity of the process, making optimal choices is difficult even for an experienced practitioner. Thus, as an example, and within the framework of reinforcement learning, we utilize a deep-Q network (DQN) to learn an optimal policy to determine the proper timing to switch between different misfit functions. Specifically, we train the state-action value function (Q) to predict when to use the conventional L2-norm misfit function or the more advanced optimal-transport matching-filter (OTMF) misfit to mitigate the cycle-skipping and obtain high resolution, as well as improve convergence. We use a simple while demonstrative shifted-signal inversion examples to demonstrate the basic principles of the proposed method.
OCCER- One-Class Classification by Ensembles of Regression models
Dec 26, 2019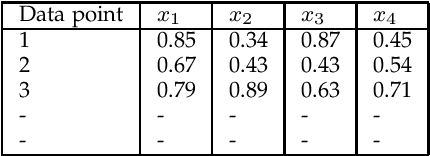
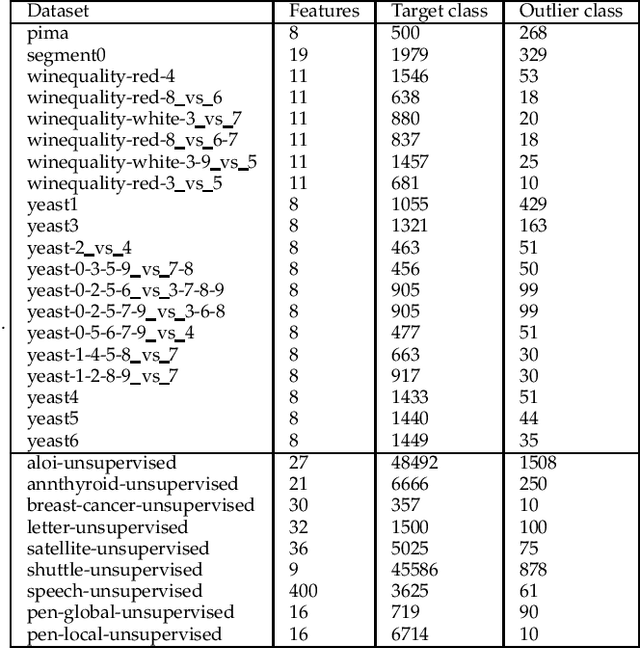
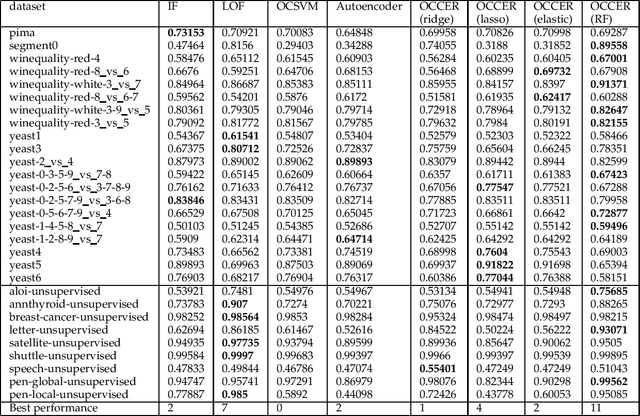
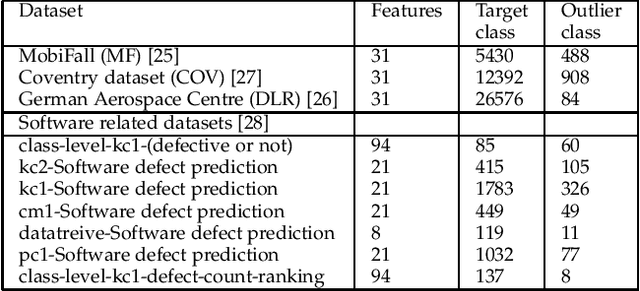
One-class classification (OCC) deals with the classification problem in which the training data has data points belonging to target class only. In this paper, we present a one-class classification algorithm; One-Class Classification by Ensembles of Regression models (OCCER) that uses regression methods to address OCC problems. The OCCEM algorithm coverts a OCC problem into many regression problems in the original feature space such that each feature of the original feature space is used as the target variable in one of the regression problems. Other features are used as the variables on which the dependent variable is depend upon. The errors of regression of a data point by all the regression models are used to compute the outlier score of the data point. An extensive comparison of the OCCER to the state-of-the-art OCC algorithms on several datasets was carried out to show the effectiveness of the proposed approach. We also show that OCCER algorithm can work well with the latent feature space created by autoencoders for image datasets. The implementation of OCCER is available at https://github.com/srikanthBezawada/OCCER.
Simultaneous reconstruction of the initial pressure and sound speed in photoacoustic tomography using a deep-learning approach
Jul 23, 2019
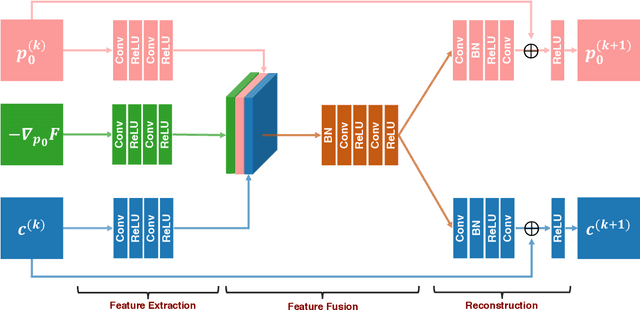
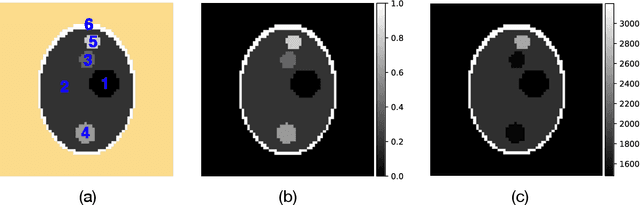
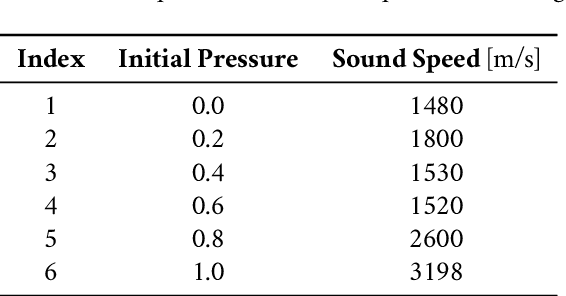
Photoacoustic tomography seeks to reconstruct an acoustic initial pressure distribution from the measurement of the ultrasound waveforms. Conventional methods assume a-prior knowledge of the sound speed distribution, which practically is unknown. One way to circumvent the issue is to simultaneously reconstruct both the acoustic initial pressure and speed. In this article, we develop a novel data-driven method that integrates an advanced deep neural network through model-based iteration. The image of the initial pressure is significantly improved in our numerical simulation.