 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeML-misfit: Learning a robust misfit function for full-waveform inversion using machine learning
Mar 18, 2020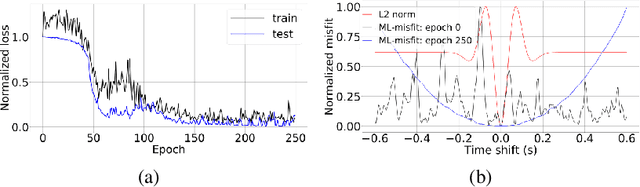
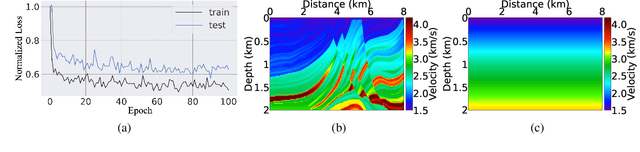
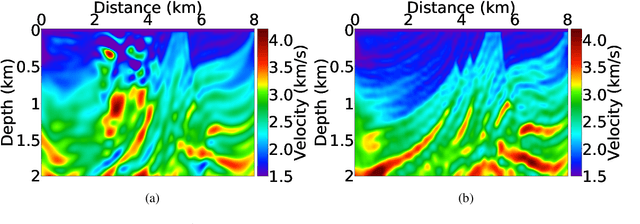
Most of the available advanced misfit functions for full waveform inversion (FWI) are hand-crafted, and the performance of those misfit functions is data-dependent. Thus, we propose to learn a misfit function for FWI, entitled ML-misfit, based on machine learning. Inspired by the optimal transport of the matching filter misfit, we design a neural network (NN) architecture for the misfit function in a form similar to comparing the mean and variance for two distributions. To guarantee the resulting learned misfit is a metric, we accommodate the symmetry of the misfit with respect to its input and a Hinge loss regularization term in a meta-loss function to satisfy the "triangle inequality" rule. In the framework of meta-learning, we train the network by running FWI to invert for randomly generated velocity models and update the parameters of the NN by minimizing the meta-loss, which is defined as accumulated difference between the true and inverted models. We first illustrate the basic principle of the ML-misfit for learning a convex misfit function for travel-time shifted signals. Further, we train the NN on 2D horizontally layered models, and we demonstrate the effectiveness and robustness of the learned ML-misfit by applying it to the well-known Marmousi model.
A data-driven choice of misfit function for FWI using reinforcement learning
Feb 08, 2020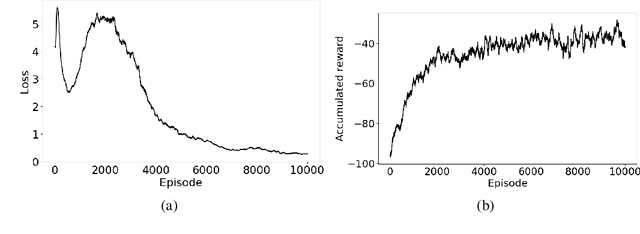
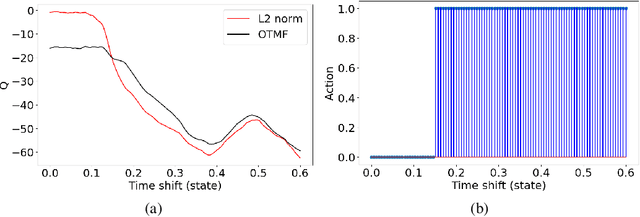
In the workflow of Full-Waveform Inversion (FWI), we often tune the parameters of the inversion to help us avoid cycle skipping and obtain high resolution models. For example, typically start by using objective functions that avoid cycle skipping, like tomographic and image based or using only low frequency, and then later, we utilize the least squares misfit to admit high resolution information. We also may perform an isotropic (acoustic) inversion to first update the velocity model and then switch to multi-parameter anisotropic (elastic) inversions to fully recover the complex physics. Such hierarchical approaches are common in FWI, and they often depend on our manual intervention based on many factors, and of course, results depend on experience. However, with the large data size often involved in the inversion and the complexity of the process, making optimal choices is difficult even for an experienced practitioner. Thus, as an example, and within the framework of reinforcement learning, we utilize a deep-Q network (DQN) to learn an optimal policy to determine the proper timing to switch between different misfit functions. Specifically, we train the state-action value function (Q) to predict when to use the conventional L2-norm misfit function or the more advanced optimal-transport matching-filter (OTMF) misfit to mitigate the cycle-skipping and obtain high resolution, as well as improve convergence. We use a simple while demonstrative shifted-signal inversion examples to demonstrate the basic principles of the proposed method.