 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Get More With Less: Near Real-Time Image Clustering on Mobile Phones
Dec 09, 2015

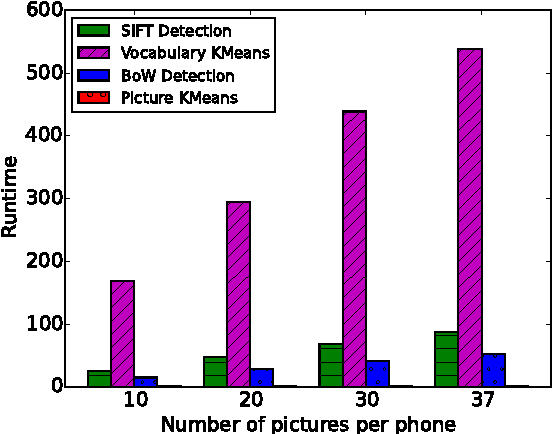
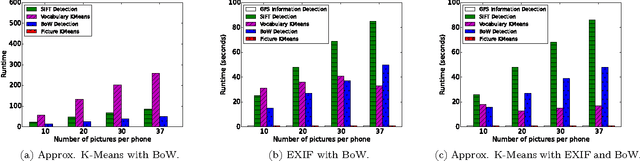
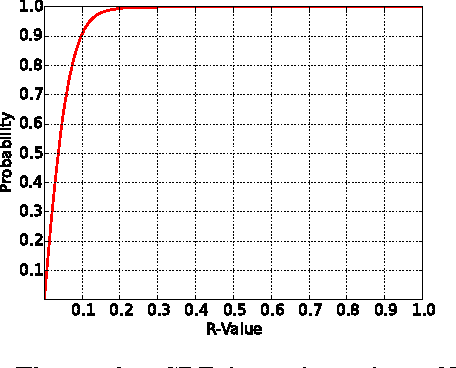
Machine learning algorithms, in conjunction with user data, hold the promise of revolutionizing the way we interact with our phones, and indeed their widespread adoption in the design of apps bear testimony to this promise. However, currently, the computationally expensive segments of the learning pipeline, such as feature extraction and model training, are offloaded to the cloud, resulting in an over-reliance on the network and under-utilization of computing resources available on mobile platforms. In this paper, we show that by combining the computing power distributed over a number of phones, judicious optimization choices, and contextual information it is possible to execute the end-to-end pipeline entirely on the phones at the edge of the network, efficiently. We also show that by harnessing the power of this combination, it is possible to execute a computationally expensive pipeline at near real-time. To demonstrate our approach, we implement an end-to-end image-processing pipeline -- that includes feature extraction, vocabulary learning, vectorization, and image clustering -- on a set of mobile phones. Our results show a 75% improvement over the standard, full pipeline implementation running on the phones without modification -- reducing the time to one minute under certain conditions. We believe that this result is a promising indication that fully distributed, infrastructure-less computing is possible on networks of mobile phones; enabling a new class of mobile applications that are less reliant on the cloud.
Collage Inference: Tolerating Stragglers in Distributed Neural Network Inference using Coding
Apr 27, 2019
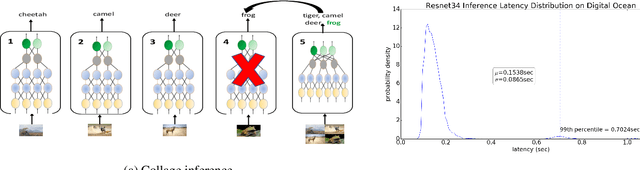

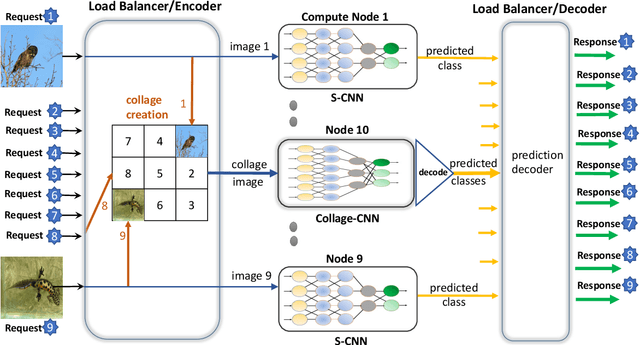
MLaaS (ML-as-a-Service) offerings by cloud computing platforms are becoming increasingly popular these days. Pre-trained machine learning models are deployed on the cloud to support prediction based applications and services. For achieving higher throughput, incoming requests are served by running multiple replicas of the model on different machines concurrently. Incidence of straggler nodes in distributed inference is a significant concern since it can increase inference latency, violate SLOs of the service. In this paper, we propose a novel coded inference model to deal with stragglers in distributed image classification. We propose modified single shot object detection models, Collage-CNN models, to provide necessary resilience efficiently. A Collage-CNN model takes collage images formed by combining multiple images as its input and performs multi-image classification in one shot. We generate custom training collages using images from standard image classification datasets and train the model to achieve high classification accuracy. Deploying the Collage-CNN models in the cloud, we demonstrate that the 99th percentile latency can be reduced by 1.45X to 2.46X compared to replication based approaches and without compromising prediction accuracy.
Hierarchical Expert Networks for Meta-Learning
Nov 07, 2019

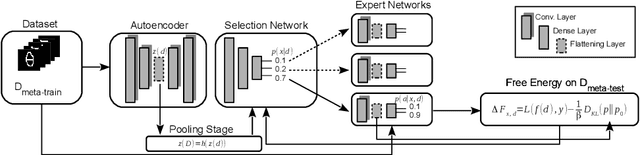
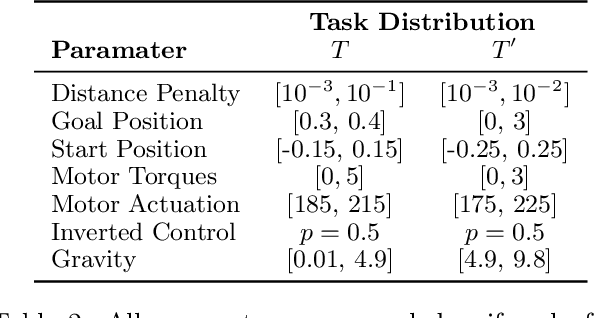
The goal of meta-learning is to train a model on a variety of learning tasks, such that it can adapt to new problems within only a few iterations. Here we propose a principled information-theoretic model that optimally partitions the underlying problem space such that the resulting partitions are processed by specialized expert decision-makers. To drive this specialization we impose the same kind of information processing constraints both on the partitioning and the expert decision-makers. We argue that this specialization leads to efficient adaptation to new tasks. To demonstrate the generality of our approach we evaluate on three meta-learning domains: image classification, regression, and reinforcement learning.
Identifying Table Structure in Documents using Conditional Generative Adversarial Networks
Jan 13, 2020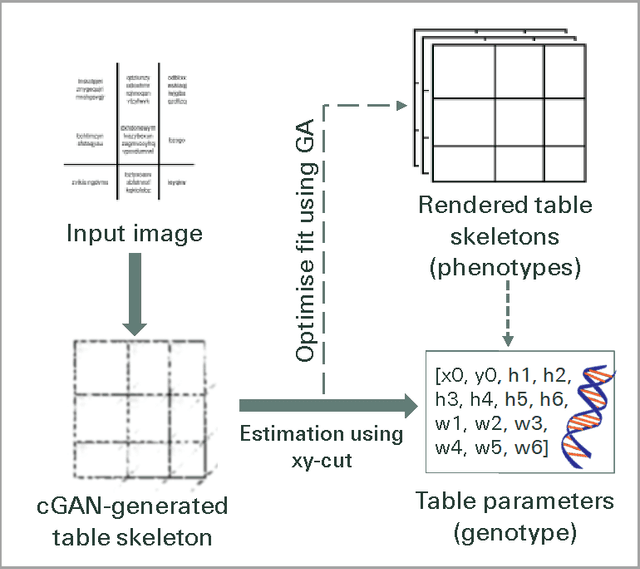

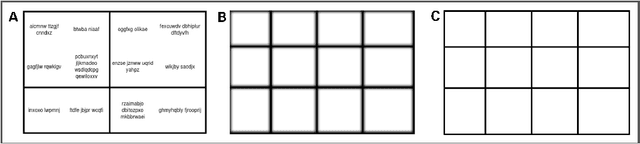
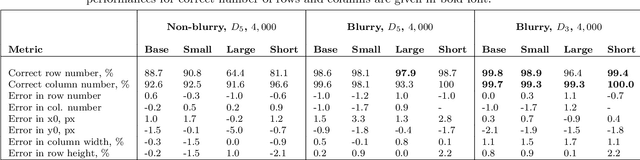
In many industries, as well as in academic research, information is primarily transmitted in the form of unstructured documents (this article, for example). Hierarchically-related data is rendered as tables, and extracting information from tables in such documents presents a significant challenge. Many existing methods take a bottom-up approach, first integrating lines into cells, then cells into rows or columns, and finally inferring a structure from the resulting 2-D layout. But such approaches neglect the available prior information relating to table structure, namely that the table is merely an arbitrary representation of a latent logical structure. We propose a top-down approach, first using a conditional generative adversarial network to map a table image into a standardised `skeleton' table form denoting approximate row and column borders without table content, then deriving latent table structure using xy-cut projection and Genetic Algorithm optimisation. The approach is easily adaptable to different table configurations and requires small data set sizes for training.
SiamSNN: Spike-based Siamese Network for Energy-Efficient and Real-time Object Tracking
Mar 17, 2020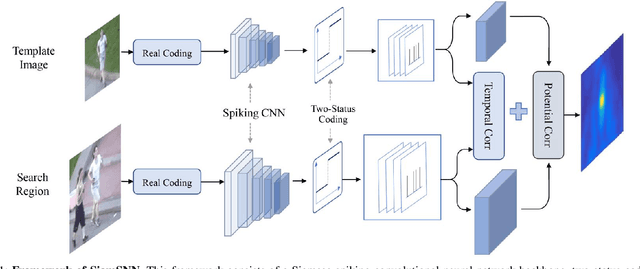
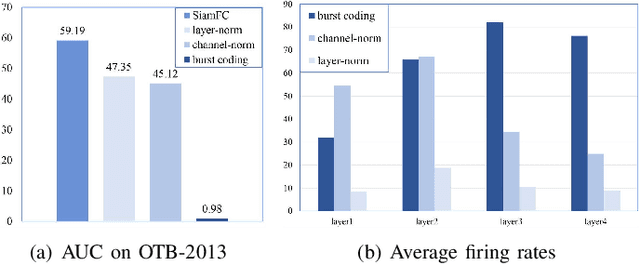
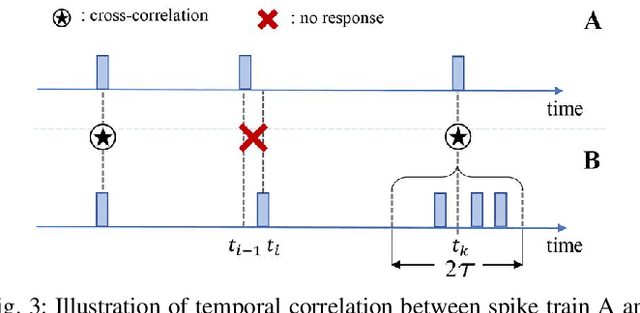
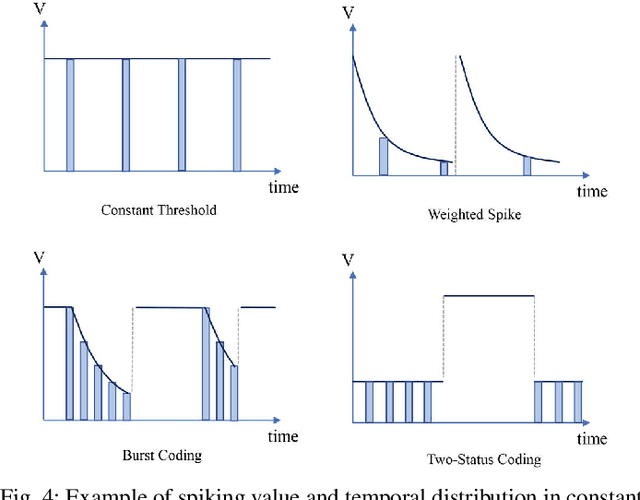
Although deep neural networks (DNNs) have achieved fantastic success in various scenarios, it's difficult to employ DNNs on many systems with limited resources due to their high energy consumption. It's well known that spiking neural networks (SNNs) are attracting more attention due to the capability of energy-efficient computing. Recently many works focus on converting DNNs into SNNs with little accuracy degradation in image classification on MNIST, CIFAR-10/100. However, few studies on shortening latency, and spike-based modules of more challenging tasks on complex datasets. In this paper, we focus on the similarity matching method of deep spike features and present a first spike-based Siamese network for object tracking called SiamSNN. Specifically, we propose a hybrid spiking similarity matching method with membrane potential and time step to evaluate the response map between exemplar and candidate images, with the same function as correlation layer in SiamFC. Then we present a coding scheme for utilizing temporal information of spike trains, and implement it in output spiking layers to improve the performance and shorten the latency. Our experiments show that SiamSNN achieves short latency and low precision loss of the original SiamFC on the tracking datasets OTB-2013, OTB-2015 and VOT2016. Moreover, SiamSNN achieves real-time (50 FPS) and extremely low energy consumption on TrueNorth.
Pose Estimation from a Single Depth Image for Arbitrary Kinematic Skeletons
Jun 27, 2011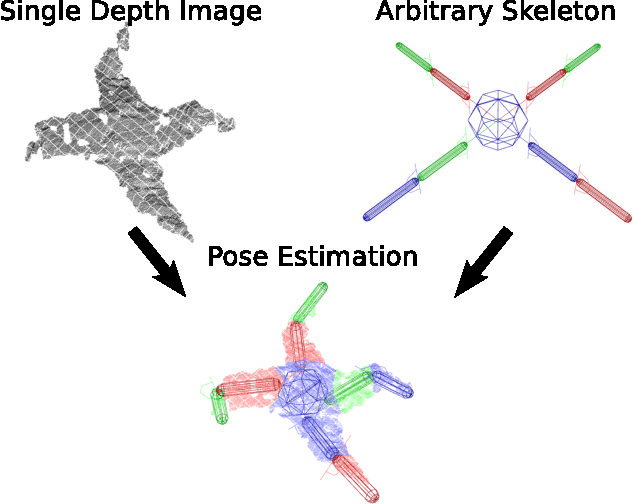

We present a method for estimating pose information from a single depth image given an arbitrary kinematic structure without prior training. For an arbitrary skeleton and depth image, an evolutionary algorithm is used to find the optimal kinematic configuration to explain the observed image. Results show that our approach can correctly estimate poses of 39 and 78 degree-of-freedom models from a single depth image, even in cases of significant self-occlusion.
SkeleMotion: A New Representation of Skeleton Joint Sequences Based on Motion Information for 3D Action Recognition
Jul 30, 2019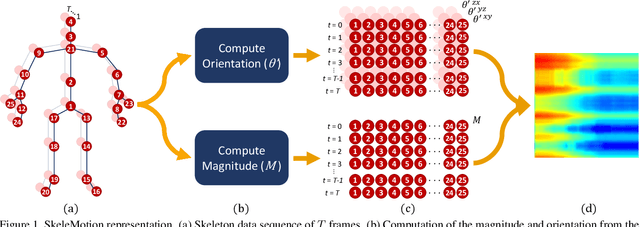
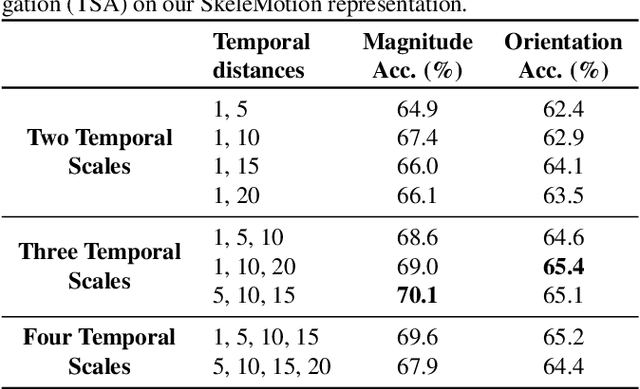
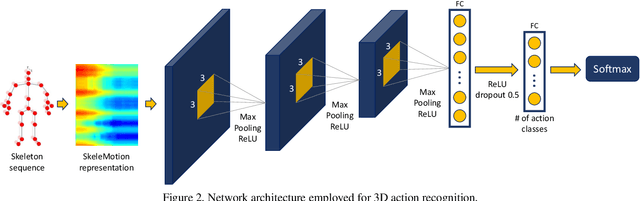
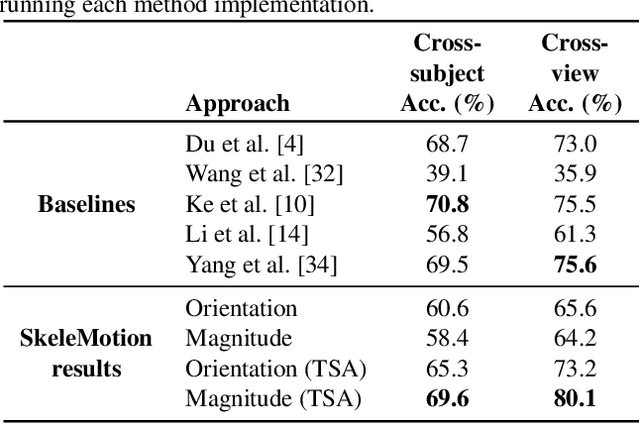
Due to the availability of large-scale skeleton datasets, 3D human action recognition has recently called the attention of computer vision community. Many works have focused on encoding skeleton data as skeleton image representations based on spatial structure of the skeleton joints, in which the temporal dynamics of the sequence is encoded as variations in columns and the spatial structure of each frame is represented as rows of a matrix. To further improve such representations, we introduce a novel skeleton image representation to be used as input of Convolutional Neural Networks (CNNs), named SkeleMotion. The proposed approach encodes the temporal dynamics by explicitly computing the magnitude and orientation values of the skeleton joints. Different temporal scales are employed to compute motion values to aggregate more temporal dynamics to the representation making it able to capture longrange joint interactions involved in actions as well as filtering noisy motion values. Experimental results demonstrate the effectiveness of the proposed representation on 3D action recognition outperforming the state-of-the-art on NTU RGB+D 120 dataset.
Deep Cerebellar Nuclei Segmentation via Semi-Supervised Deep Context-Aware Learning from 7T Diffusion MRI
Apr 21, 2020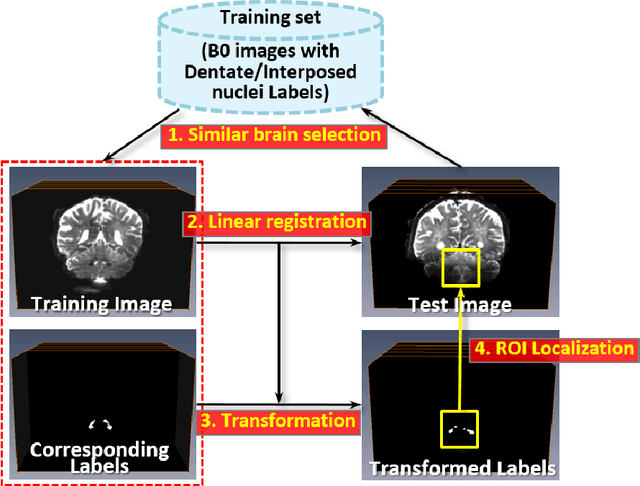
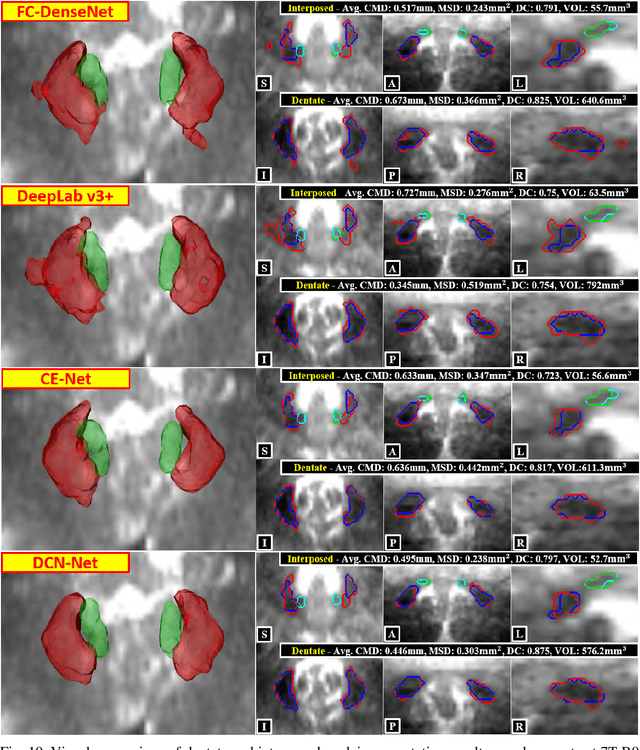
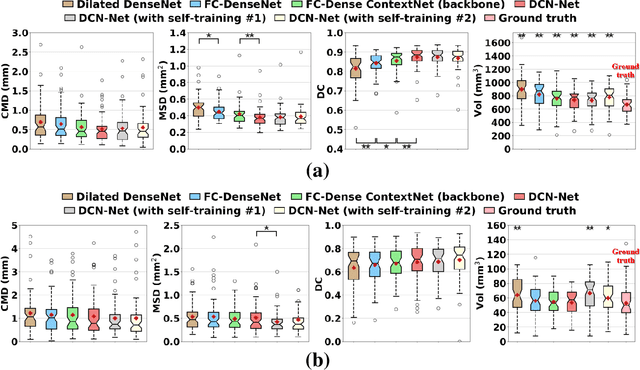
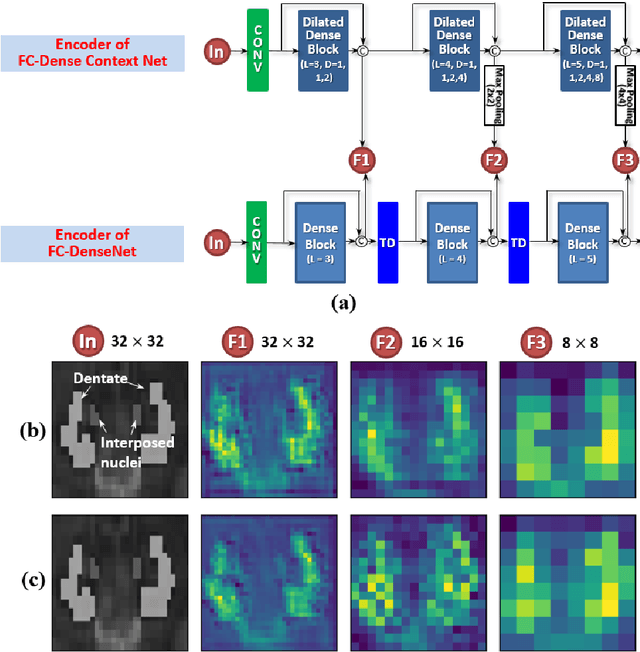
Deep cerebellar nuclei are a key structure of the cerebellum that are involved in processing motor and sensory information. It is thus a crucial step to precisely segment deep cerebellar nuclei for the understanding of the cerebellum system and its utility in deep brain stimulation treatment. However, it is challenging to clearly visualize such small nuclei under standard clinical magnetic resonance imaging (MRI) protocols and therefore an automatic patient-specific segmentation is not feasible. Recent advances in 7 Tesla (T) MRI technology and great potential of deep neural networks facilitate automatic, fast, and accurate segmentation. In this paper, we propose a novel deep learning framework (referred to as DCN-Net) for the segmentation of deep cerebellar dentate and interposed nuclei on 7T diffusion MRI. DCN-Net effectively encodes contextual information on the image patches without consecutive pooling operations and adding complexity via proposed dilated dense blocks. During the end-to-end training, label probabilities of dentate and interposed nuclei are independently learned with a hybrid loss, handling highly imbalanced data. Finally, we utilize self-training strategies to cope with the problem of limited labeled data. To this end, auxiliary dentate and interposed nuclei labels are created on unlabeled data by using DCN-Net trained on manual labels. We validate the proposed framework using 7T B0 MRIs from 60 subjects. Experimental results demonstrate that DCN-Net provides better segmentation than atlas-based deep cerebellar nuclei segmentation tools and other state-of-the-art deep neural networks in terms of accuracy and consistency. We further prove the effectiveness of the proposed components within DCN-Net in dentate and interposed nuclei segmentation.
3D Object Detection From LiDAR Data Using Distance Dependent Feature Extraction
Mar 03, 2020
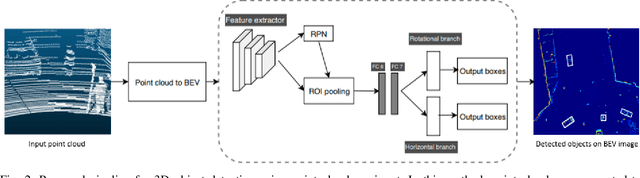
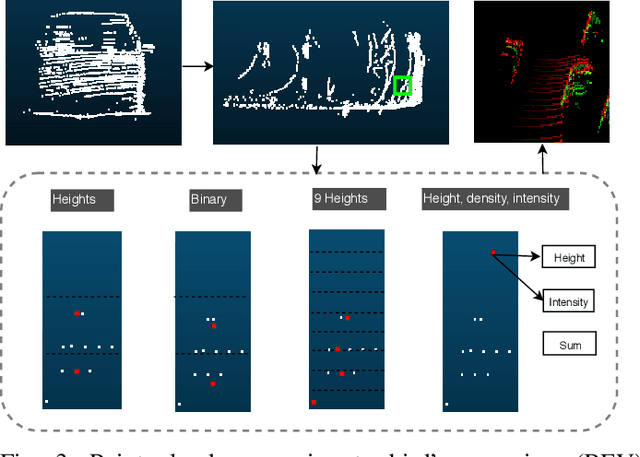

This paper presents a new approach to 3D object detection that leverages the properties of the data obtained by a LiDAR sensor. State-of-the-art detectors use neural network architectures based on assumptions valid for camera images. However, point clouds obtained from LiDAR are fundamentally different. Most detectors use shared filter kernels to extract features which do not take into account the range dependent nature of the point cloud features. To show this, different detectors are trained on two splits of the KITTI dataset: close range (objects up to 25 meters from LiDAR) and long-range. Top view images are generated from point clouds as input for the networks. Combined results outperform the baseline network trained on the full dataset with a single backbone. Additional research compares the effect of using different input features when converting the point cloud to image. The results indicate that the network focuses on the shape and structure of the objects, rather than exact values of the input. This work proposes an improvement for 3D object detectors by taking into account the properties of LiDAR point clouds over distance. Results show that training separate networks for close-range and long-range objects boosts performance for all KITTI benchmark difficulties.
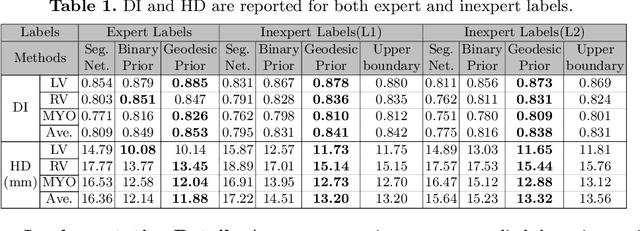
Weakly Supervised Segmentation by A Deep Geodesic Prior
Aug 18, 2019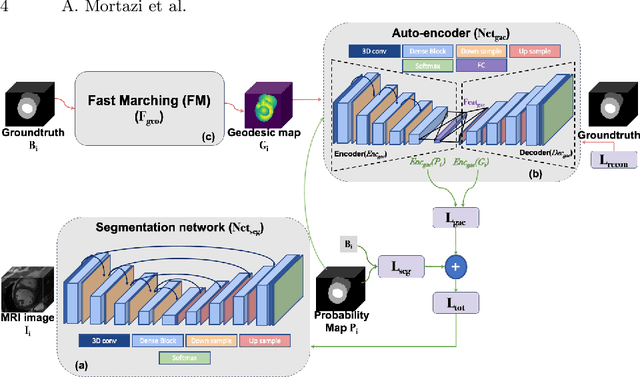
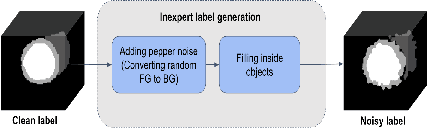
The performance of the state-of-the-art image segmentation methods heavily relies on the high-quality annotations, which are not easily affordable, particularly for medical data. To alleviate this limitation, in this study, we propose a weakly supervised image segmentation method based on a deep geodesic prior. We hypothesize that integration of this prior information can reduce the adverse effects of weak labels in segmentation accuracy. Our proposed algorithm is based on a prior information, extracted from an auto-encoder, trained to map objects geodesic maps to their corresponding binary maps. The obtained information is then used as an extra term in the loss function of the segmentor. In order to show efficacy of the proposed strategy, we have experimented segmentation of cardiac substructures with clean and two levels of noisy labels (L1, L2). Our experiments showed that the proposed algorithm boosted the performance of baseline deep learning-based segmentation for both clean and noisy labels by 4.4%, 4.6%(L1), and 6.3%(L2) in dice score, respectively. We also showed that the proposed method was more robust in the presence of high-level noise due to the existence of shape priors.