 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Extreme Sparse Multinomial Logistic Regression: A Fast and Robust Framework for Hyperspectral Image Classification
Sep 27, 2017
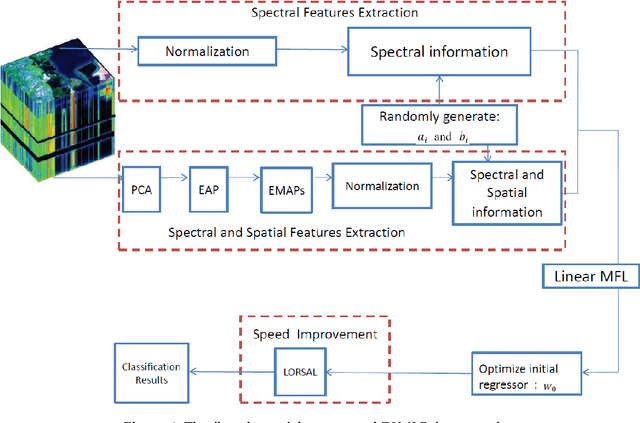
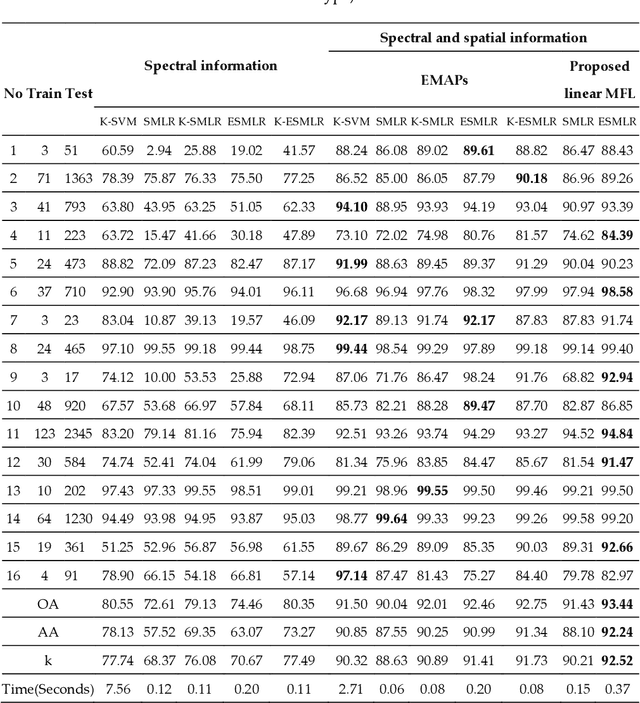
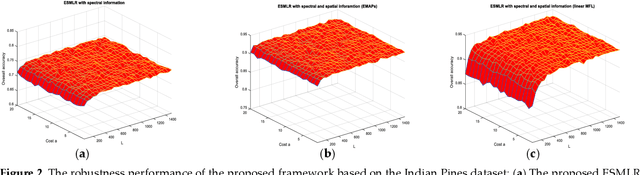
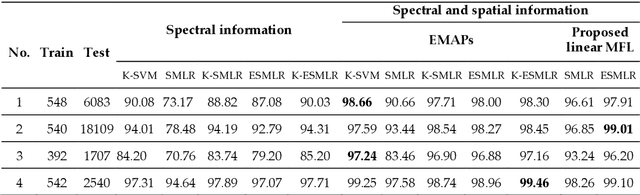
Although the sparse multinomial logistic regression (SMLR) has provided a useful tool for sparse classification, it suffers from inefficacy in dealing with high dimensional features and manually set initial regressor values. This has significantly constrained its applications for hyperspectral image (HSI) classification. In order to tackle these two drawbacks, an extreme sparse multinomial logistic regression (ESMLR) is proposed for effective classification of HSI. First, the HSI dataset is projected to a new feature space with randomly generated weight and bias. Second, an optimization model is established by the Lagrange multiplier method and the dual principle to automatically determine a good initial regressor for SMLR via minimizing the training error and the regressor value. Furthermore, the extended multi-attribute profiles (EMAPs) are utilized for extracting both the spectral and spatial features. A combinational linear multiple features learning (MFL) method is proposed to further enhance the features extracted by ESMLR and EMAPs. Finally, the logistic regression via the variable splitting and the augmented Lagrangian (LORSAL) is adopted in the proposed framework for reducing the computational time. Experiments are conducted on two well-known HSI datasets, namely the Indian Pines dataset and the Pavia University dataset, which have shown the fast and robust performance of the proposed ESMLR framework.
* 14 pages,7 figures,4 tables
Explaining Motion Relevance for Activity Recognition in Video Deep Learning Models
Mar 31, 2020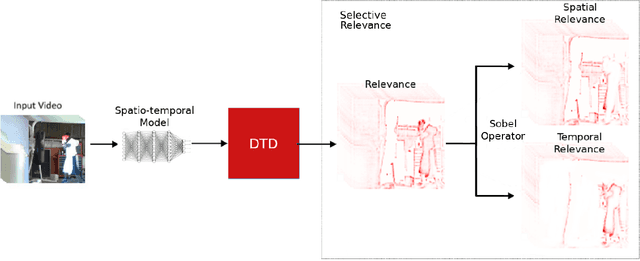
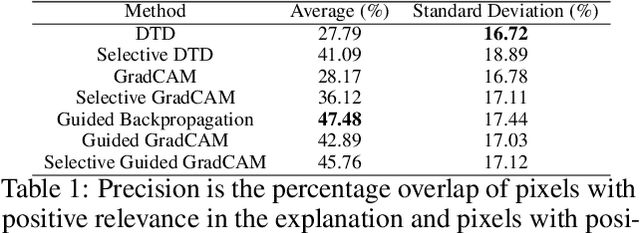
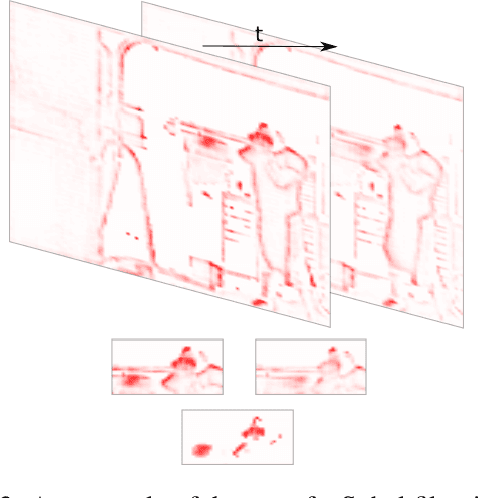

A small subset of explainability techniques developed initially for image recognition models has recently been applied for interpretability of 3D Convolutional Neural Network models in activity recognition tasks. Much like the models themselves, the techniques require little or no modification to be compatible with 3D inputs. However, these explanation techniques regard spatial and temporal information jointly. Therefore, using such explanation techniques, a user cannot explicitly distinguish the role of motion in a 3D model's decision. In fact, it has been shown that these models do not appropriately factor motion information into their decision. We propose a selective relevance method for adapting the 2D explanation techniques to provide motion-specific explanations, better aligning them with the human understanding of motion as conceptually separate from static spatial features. We demonstrate the utility of our method in conjunction with several widely-used 2D explanation methods, and show that it improves explanation selectivity for motion. Our results show that the selective relevance method can not only provide insight on the role played by motion in the model's decision -- in effect, revealing and quantifying the model's spatial bias -- but the method also simplifies the resulting explanations for human consumption.
Woodbury Transformations for Deep Generative Flows
Feb 27, 2020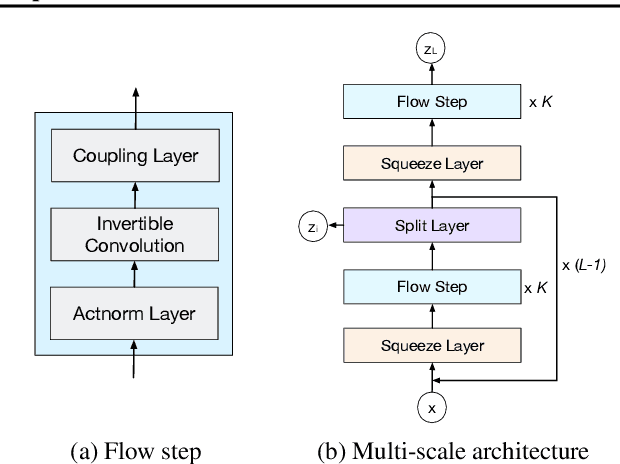
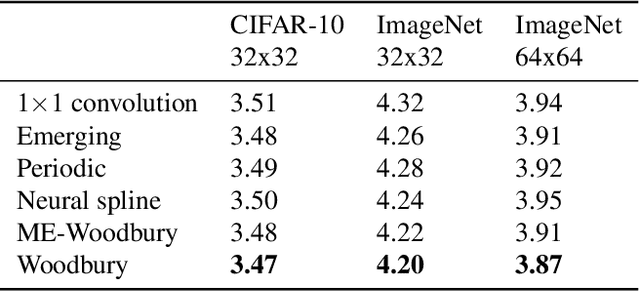
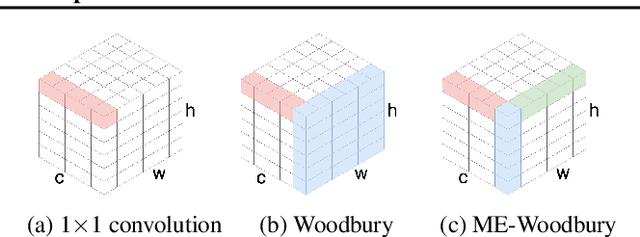
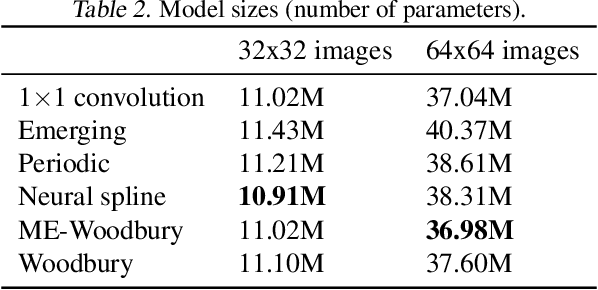
Normalizing flows are deep generative models that allow efficient likelihood calculation and sampling. The core requirement for this advantage is that they are constructed using functions that can be efficiently inverted and for which the determinant of the function's Jacobian can be efficiently computed. Researchers have introduced various such flow operations, but few of these allow rich interactions among variables without incurring significant computational costs. In this paper, we introduce Woodbury transformations, which achieve efficient invertibility via the Woodbury matrix identity and efficient determinant calculation via Sylvester's determinant identity. In contrast with other operations used in state-of-the-art normalizing flows, Woodbury transformations enable (1) high-dimensional interactions, (2) efficient sampling, and (3) efficient likelihood evaluation. Other similar operations, such as 1x1 convolutions, emerging convolutions, or periodic convolutions allow at most two of these three advantages. In our experiments on multiple image datasets, we find that Woodbury transformations allow learning of higher-likelihood models than other flow architectures while still enjoying their efficiency advantages.
Localization with Limited Annotation for Chest X-rays
Oct 10, 2019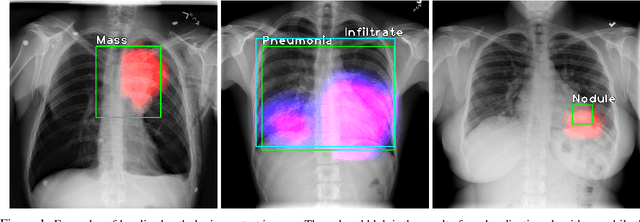
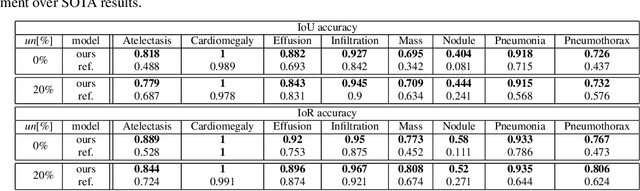
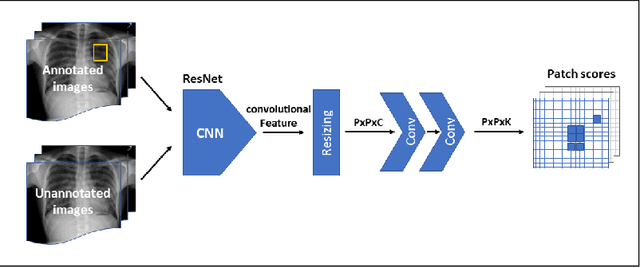
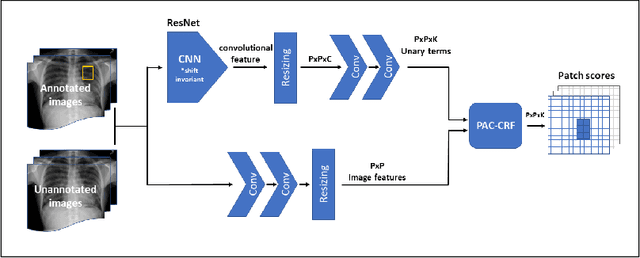
Localization of an object within an image is a common task in medical imaging. Learning to localize or detect objects typically requires the collection of data which has been labelled with bounding boxes or similar annotations, which can be very time consuming and expensive. A technique which could perform such learning with much less annotation would, therefore, be quite valuable. We present such a technique for localization with limited annotation, in which the number of images with bounding boxes can be a small fraction of the total dataset (e.g. less than 1%); all other images only possess a whole image label and no bounding box. We propose a novel loss function for tackling this problem; the loss is a continuous relaxation of a well-defined discrete formulation of weakly supervised learning and is numerically well-posed. Furthermore, we propose a new architecture which accounts for both patch dependence and shift-invariance, through the inclusion of CRF layers and anti-aliasing filters, respectively. We apply our technique to the localization of thoracic diseases in chest X-ray images and demonstrate state-of-the-art localization performance on the ChestX-ray14 dataset.
Inverting Gradients -- How easy is it to break privacy in federated learning?
Mar 31, 2020
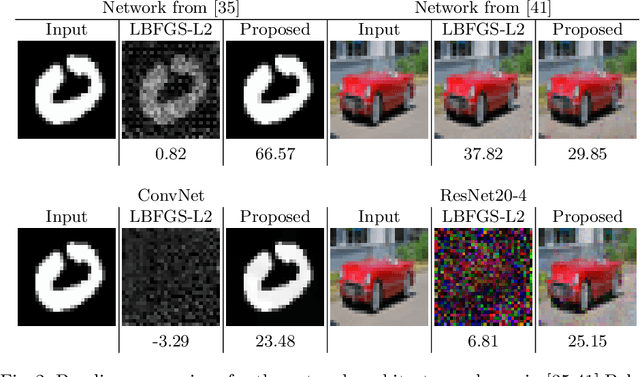

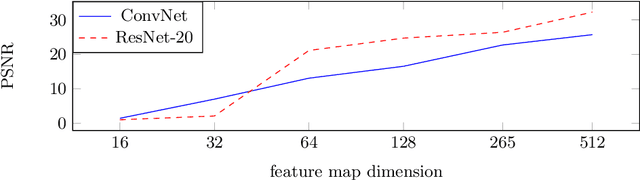
The idea of federated learning is to collaboratively train a neural network on a server. Each user receives the current weights of the network and in turns sends parameter updates (gradients) based on local data. This protocol has been designed not only to train neural networks data-efficiently, but also to provide privacy benefits for users, as their input data remains on device and only parameter gradients are shared. In this paper we show that sharing parameter gradients is by no means secure: By exploiting a cosine similarity loss along with optimization methods from adversarial attacks, we are able to faithfully reconstruct images at high resolution from the knowledge of their parameter gradients, and demonstrate that such a break of privacy is possible even for trained deep networks. Moreover, we analyze the effects of architecture as well as parameters on the difficulty of reconstructing the input image, prove that any input to a fully connected layer can be reconstructed analytically independent of the remaining architecture, and show numerically that even averaging gradients over several iterations or several images does not protect the user's privacy in federated learning applications in computer vision.
Convolutional Neural Networks learn compact local image descriptors
Jun 02, 2013
A standard deep convolutional neural network paired with a suitable loss function learns compact local image descriptors that perform comparably to state-of-the art approaches.
Iterative training of neural networks for intra prediction
Mar 15, 2020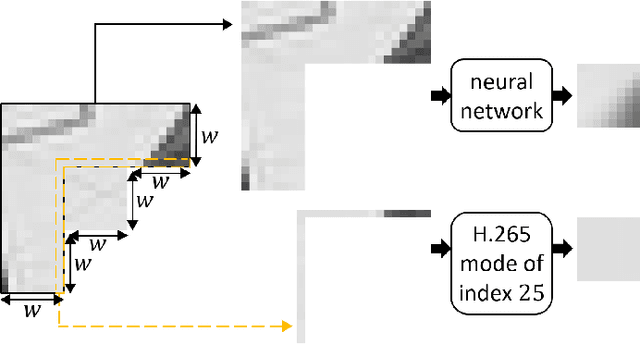



This paper presents an iterative training of neural networks for intra prediction in a block-based image and video codec. First, the neural networks are trained on blocks arising from the codec partitioning of images, each paired with its context. Then, iteratively, blocks are collected from the partitioning of images via the codec including the neural networks trained at the previous iteration, each paired with its context, and the neural networks are retrained on the new pairs. Thanks to this training, the neural networks can learn intra prediction functions that both stand out from those already in the initial codec and boost the codec in terms of rate-distortion. Moreover, the iterative process allows the design of training data cleansings essential for the neural network training. When the iteratively trained neural networks are put into H.265 (HM-16.15), -4.2% of mean dB-rate reduction is obtained, that is -1.8% above the state-of-the-art. By moving them into H.266 (VTM-5.0), the mean dB-rate reduction reaches -1.9%.
Accurate and robust image superresolution by neural processing of local image representations
Oct 03, 2005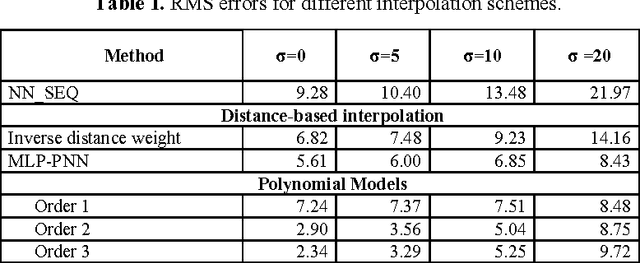
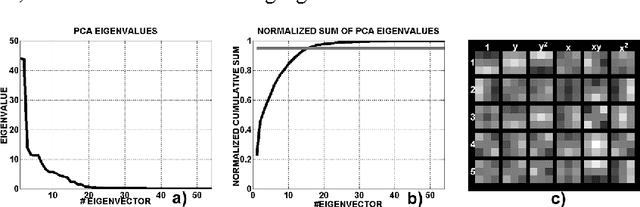
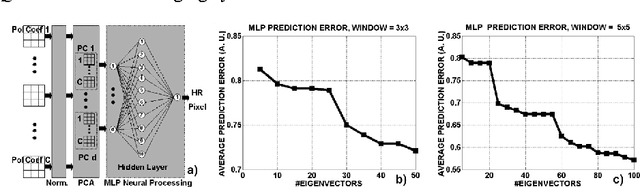

Image superresolution involves the processing of an image sequence to generate a still image with higher resolution. Classical approaches, such as bayesian MAP methods, require iterative minimization procedures, with high computational costs. Recently, the authors proposed a method to tackle this problem, based on the use of a hybrid MLP-PNN architecture. In this paper, we present a novel superresolution method, based on an evolution of this concept, to incorporate the use of local image models. A neural processing stage receives as input the value of model coefficients on local windows. The data dimensionality is firstly reduced by application of PCA. An MLP, trained on synthetic sequences with various amounts of noise, estimates the high-resolution image data. The effect of varying the dimension of the network input space is examined, showing a complex, structured behavior. Quantitative results are presented showing the accuracy and robustness of the proposed method.
* 6 pages with 3 figures. ICANN 2005
Unsupervised Object Segmentation with Explicit Localization Module
Nov 21, 2019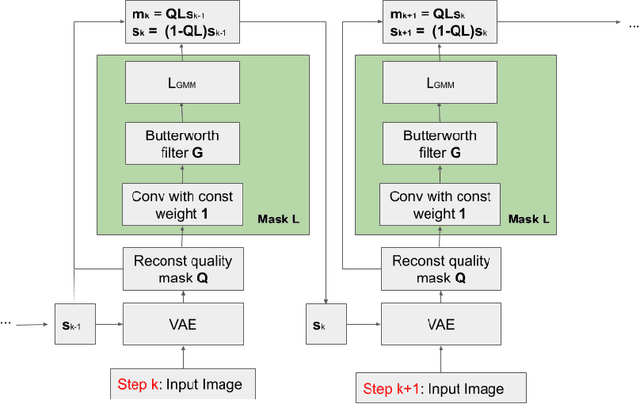


In this paper, we propose a novel architecture that iteratively discovers and segments out the objects of a scene based on the image reconstruction quality. Different from other approaches, our model uses an explicit localization module that localizes objects of the scene based on the pixel-level reconstruction qualities at each iteration, where simpler objects tend to be reconstructed better at earlier iterations and thus are segmented out first. We show that our localization module improves the quality of the segmentation, especially on a challenging background.
Using a thousand optimization tasks to learn hyperparameter search strategies
Feb 27, 2020
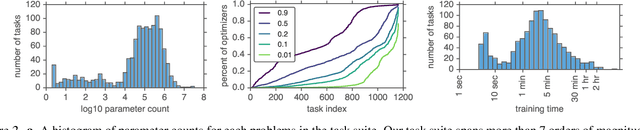
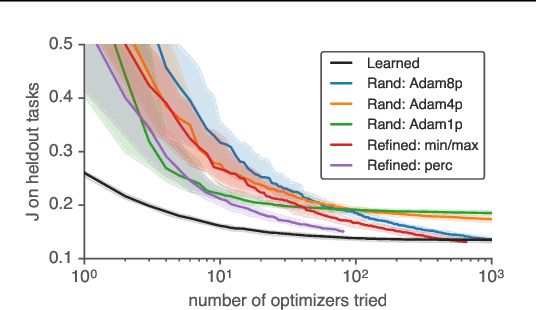
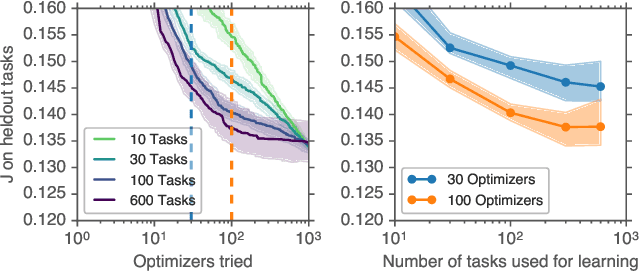
We present TaskSet, a dataset of tasks for use in training and evaluating optimizers. TaskSet is unique in its size and diversity, containing over a thousand tasks ranging from image classification with fully connected or convolutional neural networks, to variational autoencoders, to non-volume preserving flows on a variety of datasets. As an example application of such a dataset we explore meta-learning an ordered list of hyperparameters to try sequentially. By learning this hyperparameter list from data generated using TaskSet we achieve large speedups in sample efficiency over random search. Next we use the diversity of the TaskSet and our method for learning hyperparameter lists to empirically explore the generalization of these lists to new optimization tasks in a variety of settings including ImageNet classification with Resnet50 and LM1B language modeling with transformers. As part of this work we have opensourced code for all tasks, as well as ~29 million training curves for these problems and the corresponding hyperparameters.