 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multiresolution Elastic Medical Image Registration in Standard Intensity Scale
Jul 12, 2009
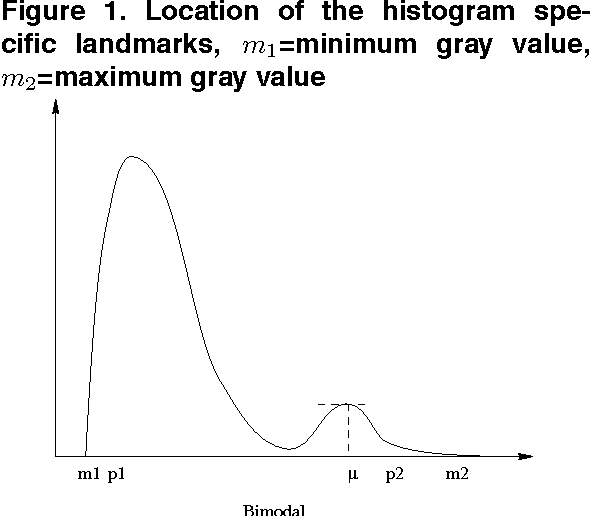
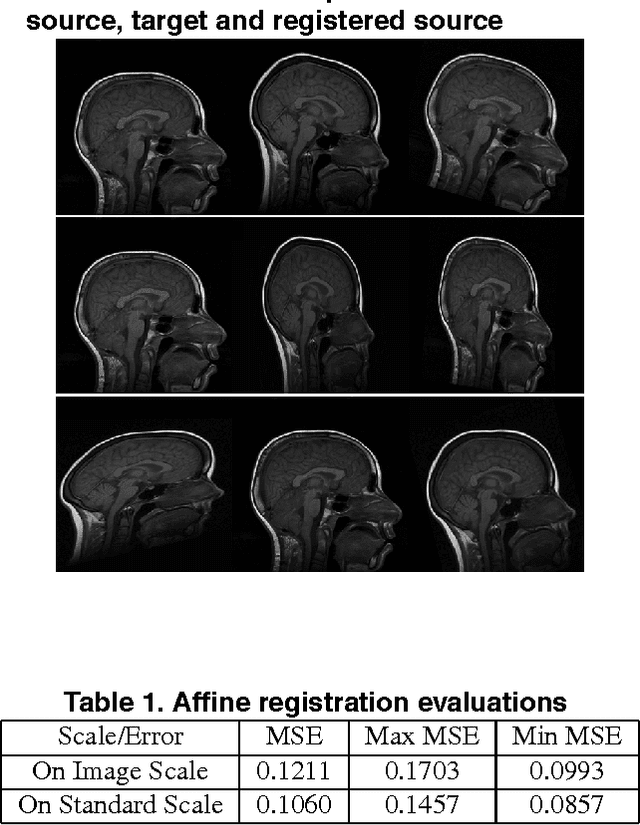
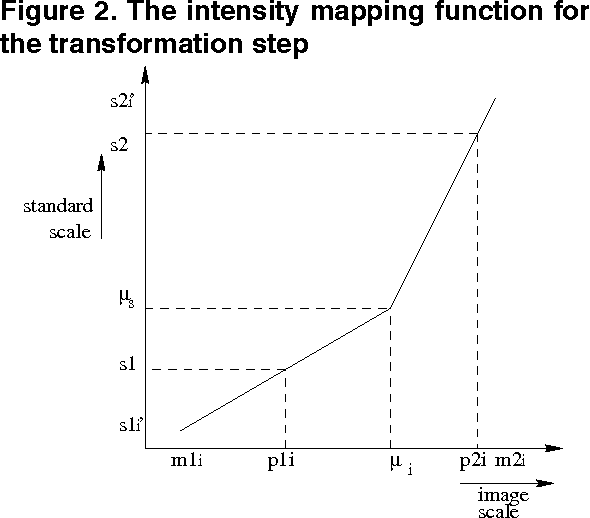
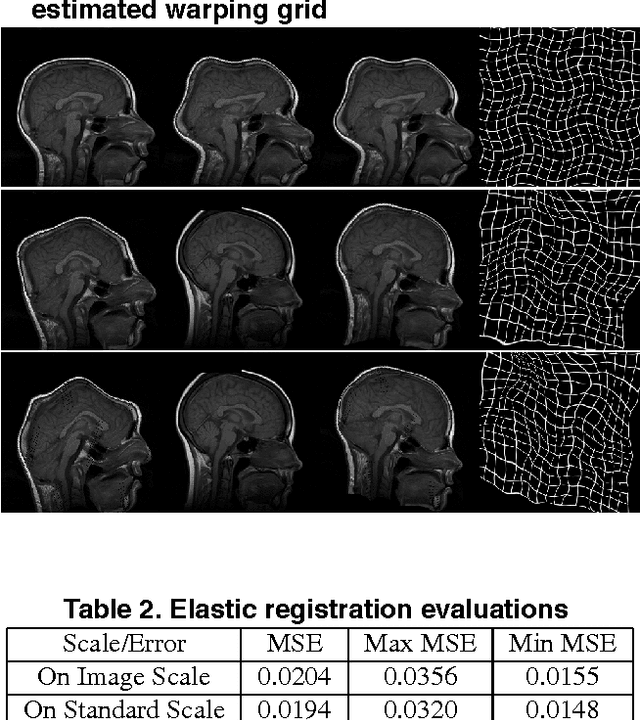
Medical image registration is a difficult problem. Not only a registration algorithm needs to capture both large and small scale image deformations, it also has to deal with global and local image intensity variations. In this paper we describe a new multiresolution elastic image registration method that challenges these difficulties in image registration. To capture large and small scale image deformations, we use both global and local affine transformation algorithms. To address global and local image intensity variations, we apply an image intensity standardization algorithm to correct image intensity variations. This transforms image intensities into a standard intensity scale, which allows highly accurate registration of medical images.
* IEEE Sibgrapi 2007 submission
Image segmentation with superpixel-based covariance descriptors in low-rank representation
May 18, 2016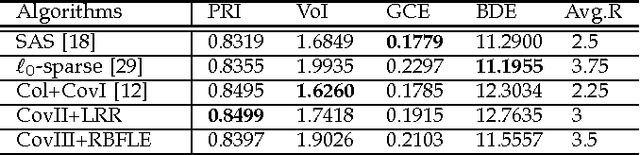
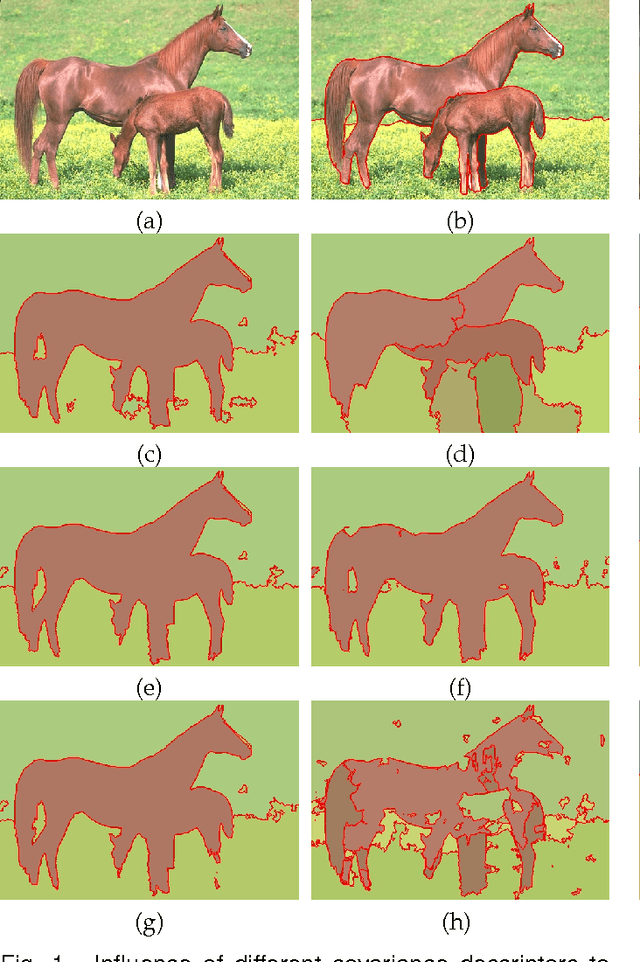
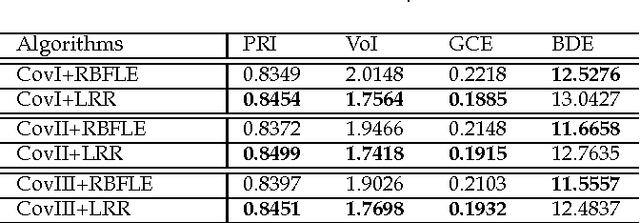
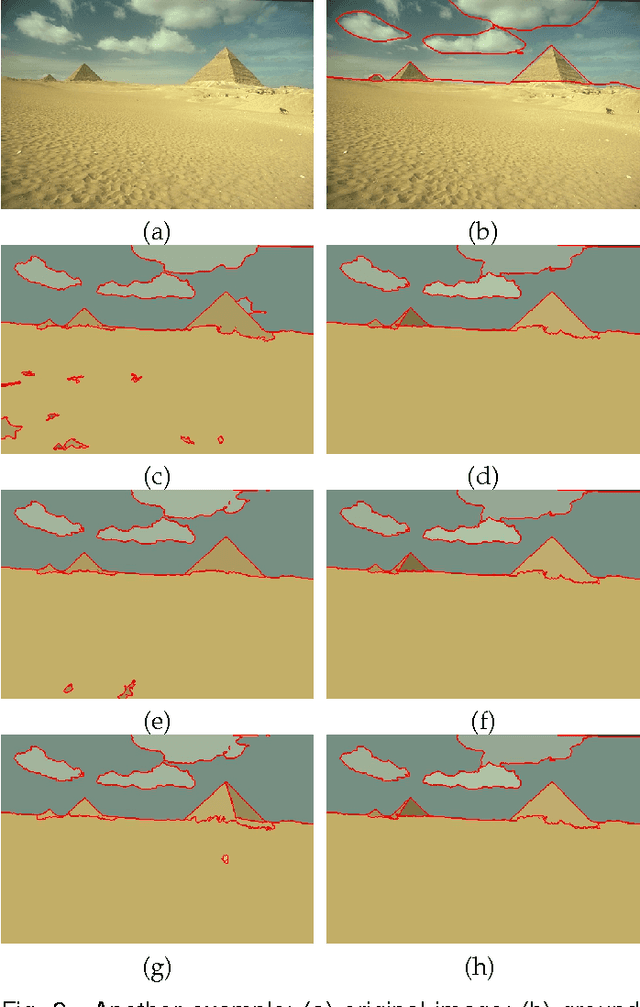
This paper investigates the problem of image segmentation using superpixels. We propose two approaches to enhance the discriminative ability of the superpixel's covariance descriptors. In the first one, we employ the Log-Euclidean distance as the metric on the covariance manifolds, and then use the RBF kernel to measure the similarities between covariance descriptors. The second method is focused on extracting the subspace structure of the set of covariance descriptors by extending a low rank representation algorithm on to the covariance manifolds. Experiments are carried out with the Berkly Segmentation Dataset, and compared with the state-of-the-art segmentation algorithms, both methods are competitive.
MUTATT: Visual-Textual Mutual Guidance for Referring Expression Comprehension
Mar 20, 2020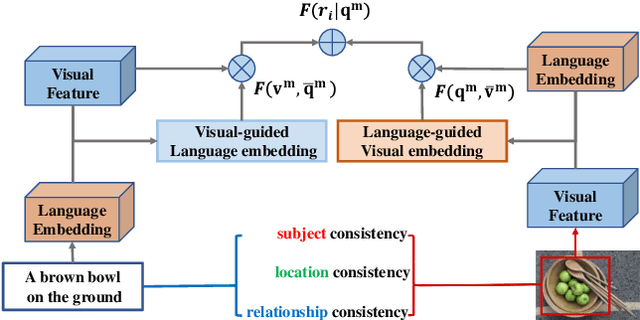
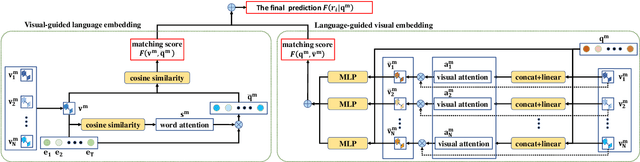
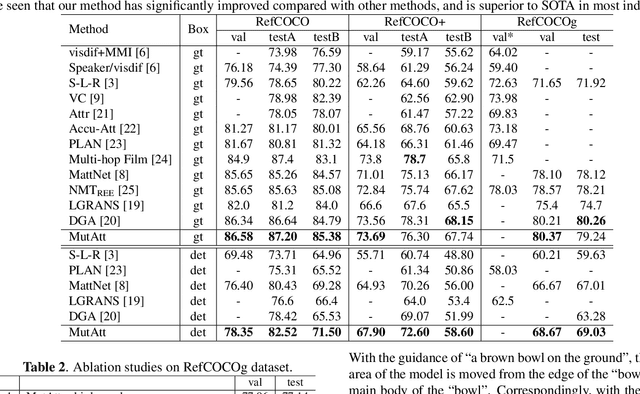
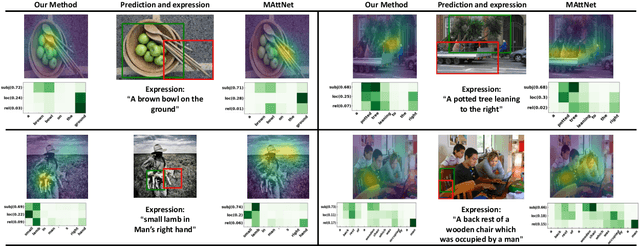
Referring expression comprehension (REC) aims to localize a text-related region in a given image by a referring expression in natural language. Existing methods focus on how to build convincing visual and language representations independently, which may significantly isolate visual and language information. In this paper, we argue that for REC the referring expression and the target region are semantically correlated and subject, location and relationship consistency exist between vision and language.On top of this, we propose a novel approach called MutAtt to construct mutual guidance between vision and language, which treat vision and language equally thus yield compact information matching. Specifically, for each module of subject, location and relationship, MutAtt builds two kinds of attention-based mutual guidance strategies. One strategy is to generate vision-guided language embedding for the sake of matching relevant visual feature. The other reversely generates language-guided visual feature to match relevant language embedding. This mutual guidance strategy can effectively guarantees the vision-language consistency in three modules. Experiments on three popular REC datasets demonstrate that the proposed approach outperforms the current state-of-the-art methods.
Using the quantization error from Self-Organized Map (SOM) output for detecting critical variability in large bodies of image time series in less than a minute
Oct 29, 2017



The quantization error (QE) from SOM applied on time series of spatial contrast images with variable relative amount of white and dark pixel contents, as in monochromatic medical images or satellite images, is proven a reliable indicator of potentially critical changes in image homogeneity. The QE is shown to increase linearly with the variability in spatial contrast contents across time when contrast intensity is kept constant.
Detecting Bias with Generative Counterfactual Face Attribute Augmentation
Jun 18, 2019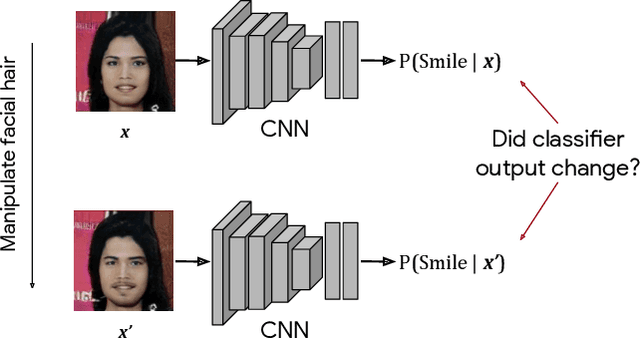

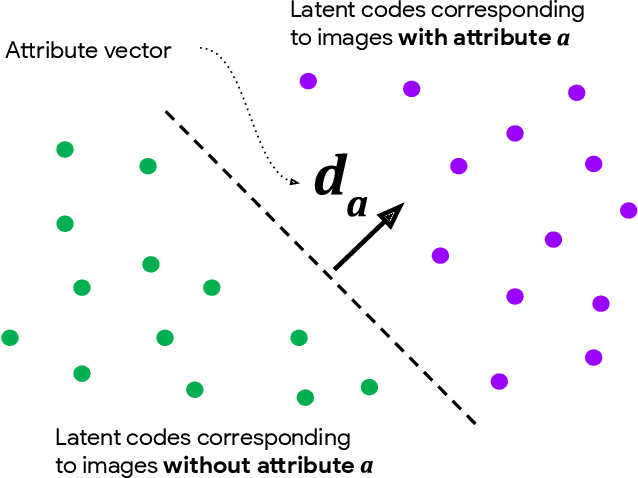
We introduce a simple framework for identifying biases of a smiling attribute classifier. Our method poses counterfactual questions of the form: how would the prediction change if this face characteristic had been different? We leverage recent advances in generative adversarial networks to build a realistic generative model of face images that affords controlled manipulation of specific image characteristics. We introduce a set of metrics that measure the effect of manipulating a specific property of an image on the output of a trained classifier. Empirically, we identify several different factors of variation that affect the predictions of a smiling classifier trained on CelebA.
Defensive Approximation: Enhancing CNNs Security through Approximate Computing
Jun 13, 2020
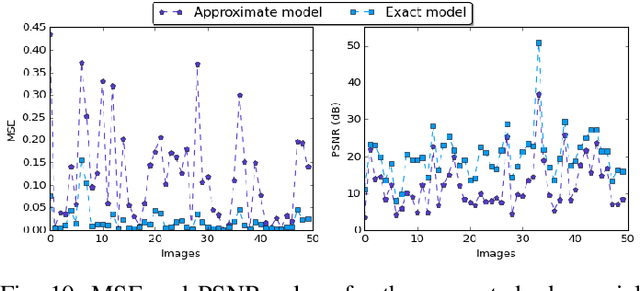
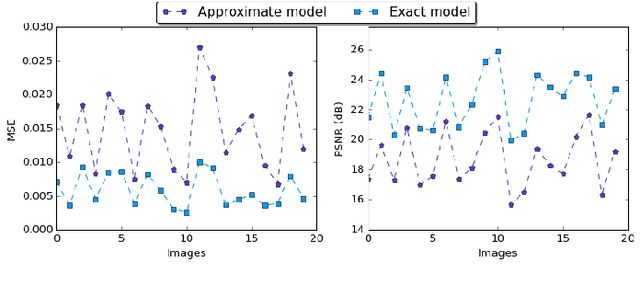
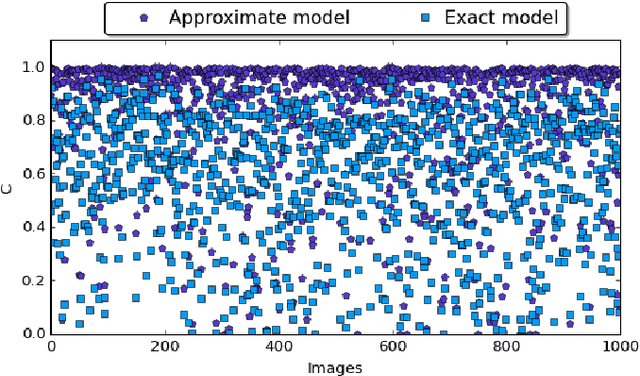
In the past few years, an increasing number of machine-learning and deep learning structures, such as Convolutional Neural Networks (CNNs), have been applied to solving a wide range of real-life problems. However, these architectures are vulnerable to adversarial attacks. In this paper, we propose for the first time to use hardware-supported approximate computing to improve the robustness of machine learning classifiers. We show that our approximate computing implementation achieves robustness across a wide range of attack scenarios. Specifically, for black-box and grey-box attack scenarios, we show that successful adversarial attacks against the exact classifier have poor transferability to the approximate implementation. Surprisingly, the robustness advantages also apply to white-box attacks where the attacker has access to the internal implementation of the approximate classifier. We explain some of the possible reasons for this robustness through analysis of the internal operation of the approximate implementation. Furthermore, our approximate computing model maintains the same level in terms of classification accuracy, does not require retraining, and reduces resource utilization and energy consumption of the CNN. We conducted extensive experiments on a set of strong adversarial attacks; We empirically show that the proposed implementation increases the robustness of a LeNet-5 and an Alexnet CNNs by up to 99% and 87%, respectively for strong grey-box adversarial attacks along with up to 67% saving in energy consumption due to the simpler nature of the approximate logic. We also show that a white-box attack requires a remarkably higher noise budget to fool the approximate classifier, causing an average of 4db degradation of the PSNR of the input image relative to the images that succeed in fooling the exact classifier
Local Features and Visual Words Emerge in Activations
May 15, 2019
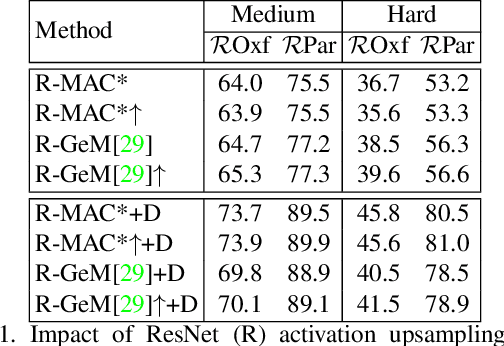

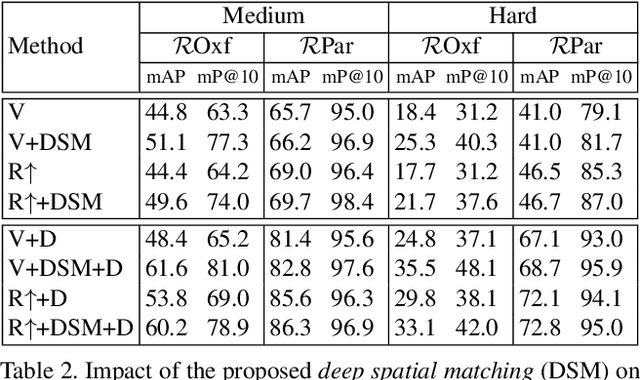
We propose a novel method of deep spatial matching (DSM) for image retrieval. Initial ranking is based on image descriptors extracted from convolutional neural network activations by global pooling, as in recent state-of-the-art work. However, the same sparse 3D activation tensor is also approximated by a collection of local features. These local features are then robustly matched to approximate the optimal alignment of the tensors. This happens without any network modification, additional layers or training. No local feature detection happens on the original image. No local feature descriptors and no visual vocabulary are needed throughout the whole process. We experimentally show that the proposed method achieves the state-of-the-art performance on standard benchmarks across different network architectures and different global pooling methods. The highest gain in performance is achieved when diffusion on the nearest-neighbor graph of global descriptors is initiated from spatially verified images.
Object Detection in Optical Remote Sensing Images: A Survey and A New Benchmark
Aug 31, 2019Substantial efforts have been devoted more recently to presenting various methods for object detection in optical remote sensing images. However, the current survey of datasets and deep learning based methods for object detection in optical remote sensing images is not adequate. Moreover, most of the existing datasets have some shortcomings, for example, the numbers of images and object categories are small scale, and the image diversity and variations are insufficient. These limitations greatly affect the development of deep learning based object detection methods. In the paper, we provide a comprehensive review of the recent deep learning based object detection progress in both the computer vision and earth observation communities. Then, we propose a large-scale, publicly available benchmark for object DetectIon in Optical Remote sensing images, which we name as DIOR. The dataset contains 23463 images and 190288 instances, covering 20 object classes. The proposed DIOR dataset 1) is large-scale on the object categories, on the object instance number, and on the total image number; 2) has a large range of object size variations, not only in terms of spatial resolutions, but also in the aspect of inter- and intra-class size variability across objects; 3) holds big variations as the images are obtained with different imaging conditions, weathers, seasons, and image quality; and 4) has high inter-class similarity and intra-class diversity. The proposed benchmark can help the researchers to develop and validate their data-driven methods. Finally, we evaluate several state-of-the-art approaches on our DIOR dataset to establish a baseline for future research.
Back to the Future: Joint Aware Temporal Deep Learning 3D Human Pose Estimation
Feb 22, 2020
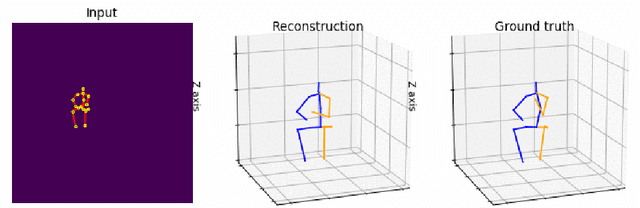
We propose a new deep learning network that introduces a deeper CNN channel filter and constraints as losses to reduce joint position and motion errors for 3D video human body pose estimation. Our model outperforms the previous best result from the literature based on mean per-joint position error, velocity error, and acceleration errors on the Human 3.6M benchmark corresponding to a new state-of-the-art mean error reduction in all protocols and motion metrics. Mean per joint error is reduced by 1%, velocity error by 7% and acceleration by 13% compared to the best results from the literature. Our contribution increasing positional accuracy and motion smoothness in video can be integrated with future end to end networks without increasing network complexity. Our model and code are available at https://vnmr.github.io/ Keywords: 3D, human, image, pose, action, detection, object, video, visual, supervised, joint, kinematic
A Deep Learning Approach to Object Affordance Segmentation
Apr 18, 2020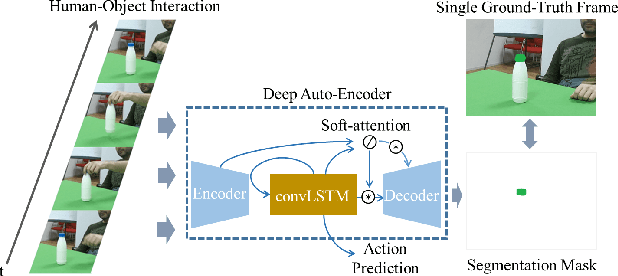

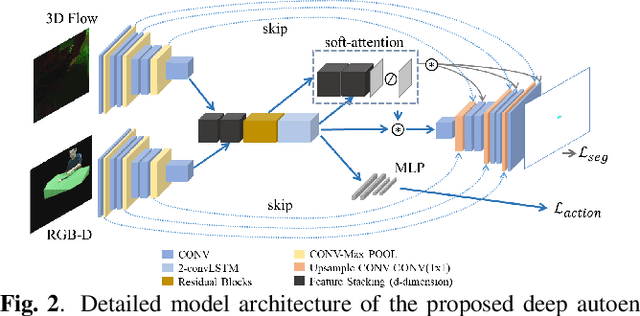
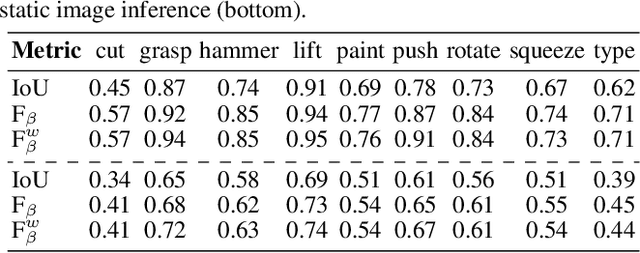
Learning to understand and infer object functionalities is an important step towards robust visual intelligence. Significant research efforts have recently focused on segmenting the object parts that enable specific types of human-object interaction, the so-called "object affordances". However, most works treat it as a static semantic segmentation problem, focusing solely on object appearance and relying on strong supervision and object detection. In this paper, we propose a novel approach that exploits the spatio-temporal nature of human-object interaction for affordance segmentation. In particular, we design an autoencoder that is trained using ground-truth labels of only the last frame of the sequence, and is able to infer pixel-wise affordance labels in both videos and static images. Our model surpasses the need for object labels and bounding boxes by using a soft-attention mechanism that enables the implicit localization of the interaction hotspot. For evaluation purposes, we introduce the SOR3D-AFF corpus, which consists of human-object interaction sequences and supports 9 types of affordances in terms of pixel-wise annotation, covering typical manipulations of tool-like objects. We show that our model achieves competitive results compared to strongly supervised methods on SOR3D-AFF, while being able to predict affordances for similar unseen objects in two affordance image-only datasets.