 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefensive Approximation: Enhancing CNNs Security through Approximate Computing
Paper and Code
Jun 13, 2020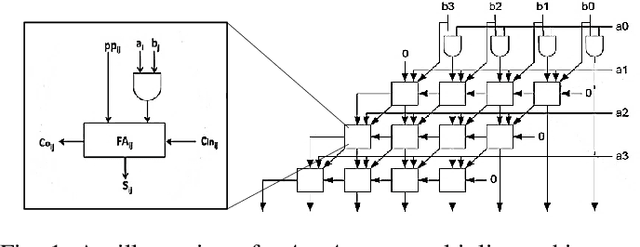
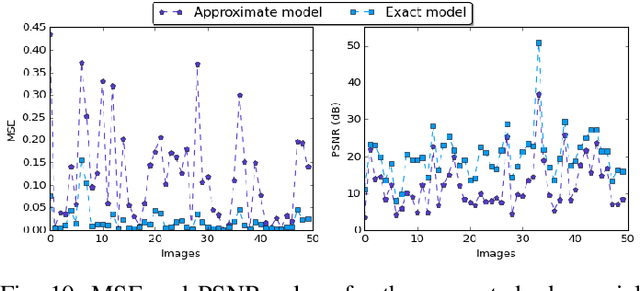
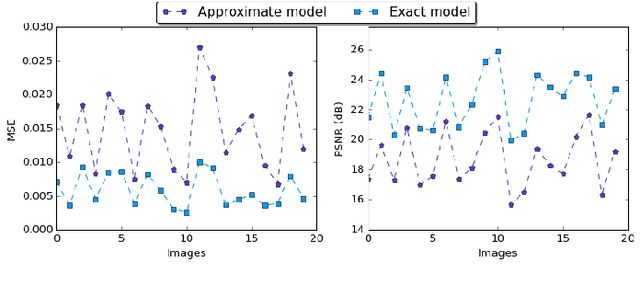
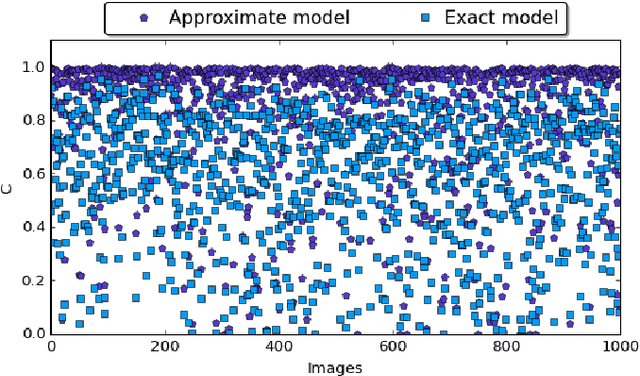
In the past few years, an increasing number of machine-learning and deep learning structures, such as Convolutional Neural Networks (CNNs), have been applied to solving a wide range of real-life problems. However, these architectures are vulnerable to adversarial attacks. In this paper, we propose for the first time to use hardware-supported approximate computing to improve the robustness of machine learning classifiers. We show that our approximate computing implementation achieves robustness across a wide range of attack scenarios. Specifically, for black-box and grey-box attack scenarios, we show that successful adversarial attacks against the exact classifier have poor transferability to the approximate implementation. Surprisingly, the robustness advantages also apply to white-box attacks where the attacker has access to the internal implementation of the approximate classifier. We explain some of the possible reasons for this robustness through analysis of the internal operation of the approximate implementation. Furthermore, our approximate computing model maintains the same level in terms of classification accuracy, does not require retraining, and reduces resource utilization and energy consumption of the CNN. We conducted extensive experiments on a set of strong adversarial attacks; We empirically show that the proposed implementation increases the robustness of a LeNet-5 and an Alexnet CNNs by up to 99% and 87%, respectively for strong grey-box adversarial attacks along with up to 67% saving in energy consumption due to the simpler nature of the approximate logic. We also show that a white-box attack requires a remarkably higher noise budget to fool the approximate classifier, causing an average of 4db degradation of the PSNR of the input image relative to the images that succeed in fooling the exact classifier