 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
RPGAN: GANs Interpretability via Random Routing
Feb 17, 2020
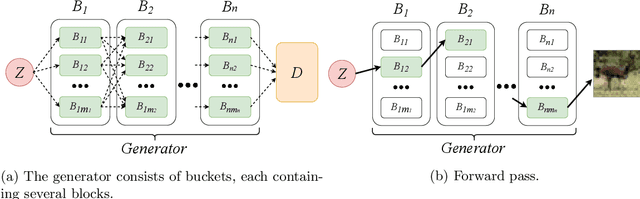

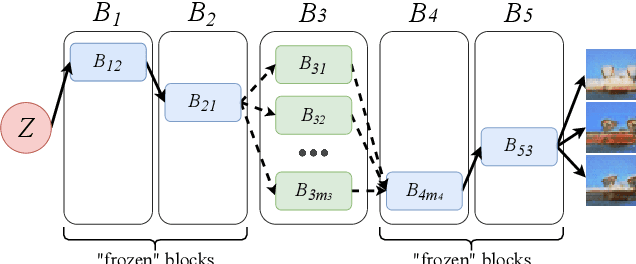

In this paper, we introduce Random Path Generative Adversarial Network (RPGAN) -- an alternative design of GANs that can serve as a tool for generative model analysis. While the latent space of a typical GAN consists of input vectors, randomly sampled from the standard Gaussian distribution, the latent space of RPGAN consists of random paths in a generator network. As we show, this design allows to understand factors of variation, captured by different generator layers, providing their natural interpretability. With experiments on standard benchmarks, we demonstrate that RPGAN reveals several interesting insights about the roles that different layers play in the image generation process. Aside from interpretability, the RPGAN model also provides competitive generation quality and allows efficient incremental learning on new data.
Face Image Analysis using AAM, Gabor, LBP and WD features for Gender, Age, Expression and Ethnicity Classification
Mar 29, 2016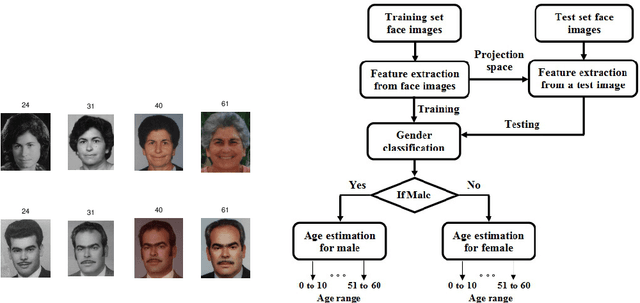
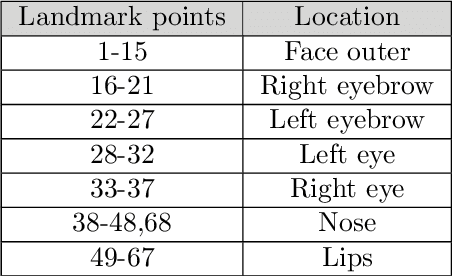
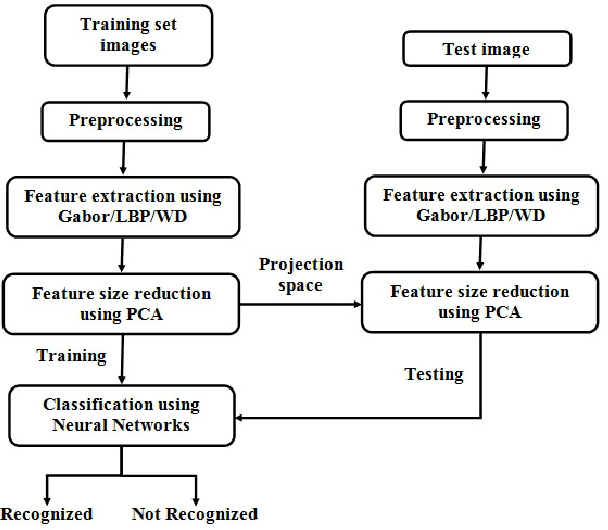
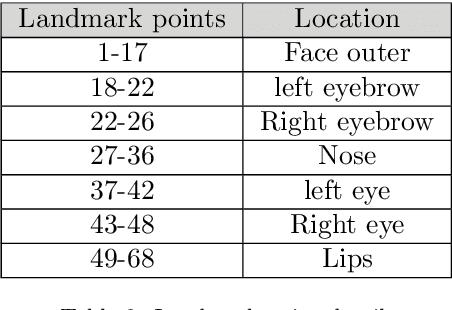
The growth in electronic transactions and human machine interactions rely on the information such as gender, age, expression and ethnicity provided by the face image. In order to obtain these information, feature extraction plays a major role. In this paper, retrieval of age, gender, expression and race information from an individual face image is analysed using different feature extraction methods. The performance of four major feature extraction methods such as Active Appearance Model (AAM), Gabor wavelets, Local Binary Pattern (LBP) and Wavelet Decomposition (WD) are analyzed for gender recognition, age estimation, expression recognition and racial recognition in terms of accuracy (recognition rate), time for feature extraction, neural training and time to test an image. Each of this recognition system is compared with four feature extractors on same dataset (training and validation set) to get a better understanding in its performance. Experiments carried out on FG-NET, Cohn-Kanade, PAL face database shows that each method has its own merits and demerits. Hence it is practically impossible to define a method which is best at all circumstances with less computational complexity. Further, a detailed comparison of age estimation and age estimation using gender information is provided along with a solution to overcome aging effect in case of gender recognition. An attempt has been made in obtaining all (i.e. gender, age range, expression and ethnicity) information from a test image in a single go.
AlgebraNets
Jun 16, 2020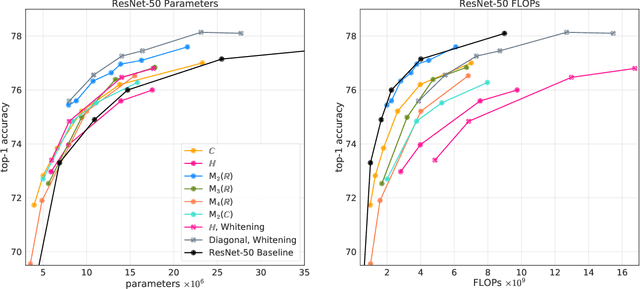
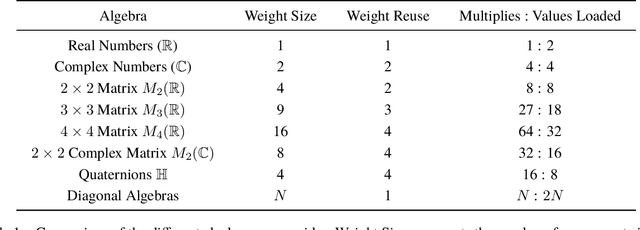
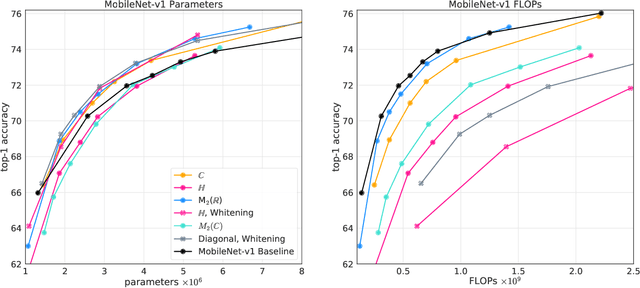

Neural networks have historically been built layerwise from the set of functions in ${f: \mathbb{R}^n \to \mathbb{R}^m }$, i.e. with activations and weights/parameters represented by real numbers, $\mathbb{R}$. Our work considers a richer set of objects for activations and weights, and undertakes a comprehensive study of alternative algebras as number representations by studying their performance on two challenging problems: large-scale image classification using the ImageNet dataset and language modeling using the enwiki8 and WikiText-103 datasets. We denote this broader class of models as AlgebraNets. Our findings indicate that the conclusions of prior work, which explored neural networks constructed from $\mathbb{C}$ (complex numbers) and $\mathbb{H}$ (quaternions) on smaller datasets, do not always transfer to these challenging settings. However, our results demonstrate that there are alternative algebras which deliver better parameter and computational efficiency compared with $\mathbb{R}$. We consider $\mathbb{C}$, $\mathbb{H}$, $M_{2}(\mathbb{R})$ (the set of $2\times2$ real-valued matrices), $M_{2}(\mathbb{C})$, $M_{3}(\mathbb{R})$ and $M_{4}(\mathbb{R})$. Additionally, we note that multiplication in these algebras has higher compute density than real multiplication, a useful property in situations with inherently limited parameter reuse such as auto-regressive inference and sparse neural networks. We therefore investigate how to induce sparsity within AlgebraNets. We hope that our strong results on large-scale, practical benchmarks will spur further exploration of these unconventional architectures which challenge the default choice of using real numbers for neural network weights and activations.
Comparison of Fuzzy and Neuro Fuzzy Image Fusion Techniques and its Applications
Dec 03, 2012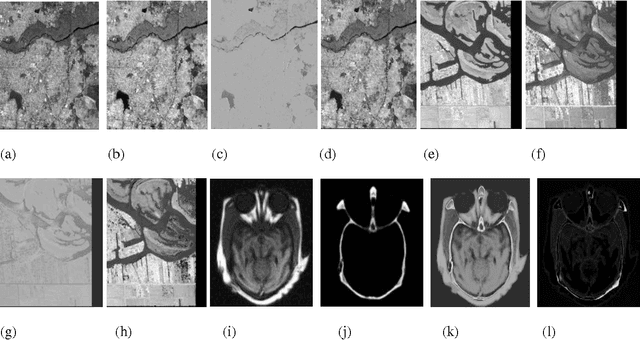
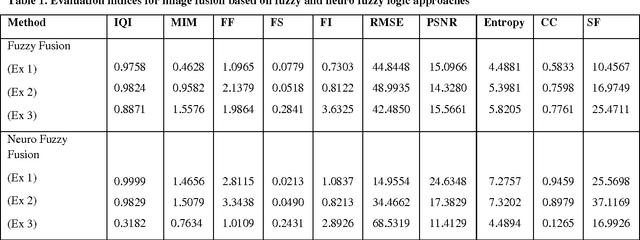
Image fusion is the process of integrating multiple images of the same scene into a single fused image to reduce uncertainty and minimizing redundancy while extracting all the useful information from the source images. Image fusion process is required for different applications like medical imaging, remote sensing, medical imaging, machine vision, biometrics and military applications where quality and critical information is required. In this paper, image fusion using fuzzy and neuro fuzzy logic approaches utilized to fuse images from different sensors, in order to enhance visualization. The proposed work further explores comparison between fuzzy based image fusion and neuro fuzzy fusion technique along with quality evaluation indices for image fusion like image quality index, mutual information measure, fusion factor, fusion symmetry, fusion index, root mean square error, peak signal to noise ratio, entropy, correlation coefficient and spatial frequency. Experimental results obtained from fusion process prove that the use of the neuro fuzzy based image fusion approach shows better performance in first two test cases while in the third test case fuzzy based image fusion technique gives better results.
* (0975 8887). arXiv admin note: text overlap with arXiv:1209.4535 by other authors
Detecting Pancreatic Adenocarcinoma in Multi-phase CT Scans via Alignment Ensemble
Mar 18, 2020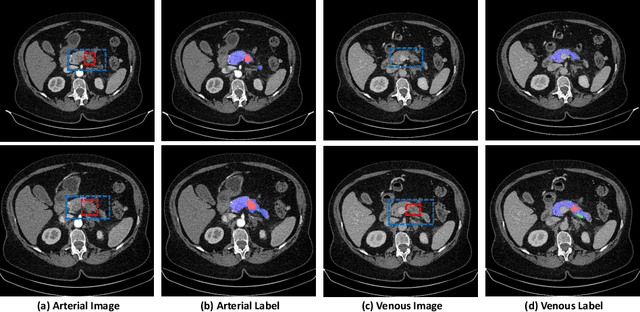
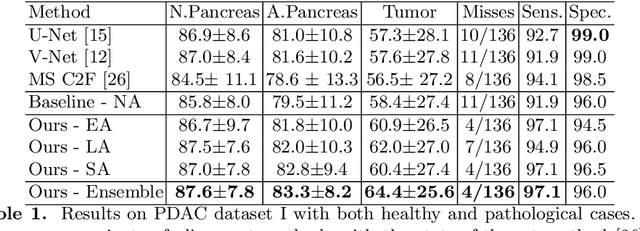
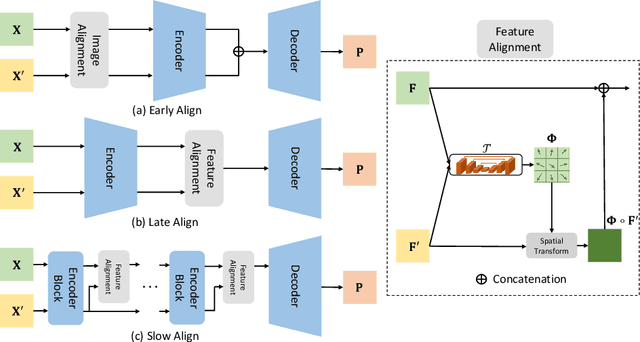
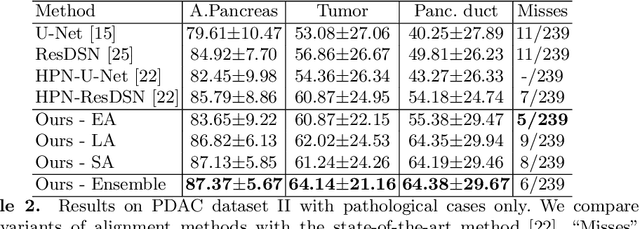
Pancreatic ductal adenocarcinoma (PDAC) is one of the most lethal cancers among population. Screening for PDACs in dynamic contrast-enhanced CT is beneficial for early diagnose. In this paper, we investigate the problem of automated detecting PDACs in multi-phase (arterial and venous) CT scans. Multiple phases provide more information than single phase, but they are unaligned and inhomogeneous in texture, making it difficult to combine cross-phase information seamlessly. We study multiple phase alignment strategies, i.e., early alignment (image registration), late alignment (high-level feature registration) and slow alignment (multi-level feature registration), and suggest an ensemble of all these alignments as a promising way to boost the performance of PDAC detection. We provide an extensive empirical evaluation on two PDAC datasets and show that the proposed alignment ensemble significantly outperforms previous state-of-the-art approaches, illustrating strong potential for clinical use.
Reconstruction of turbulent data with deep generative models for semantic inpainting from TURB-Rot database
Jun 16, 2020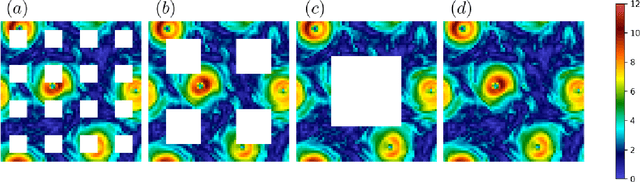
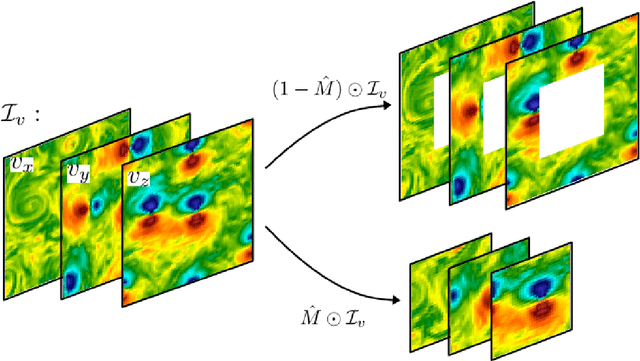
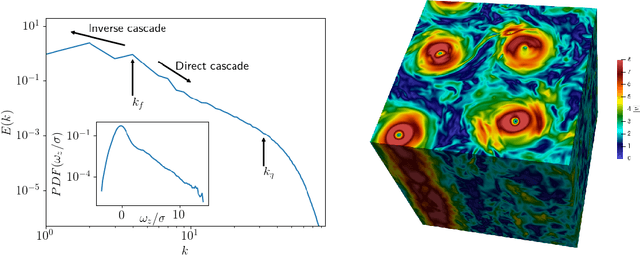
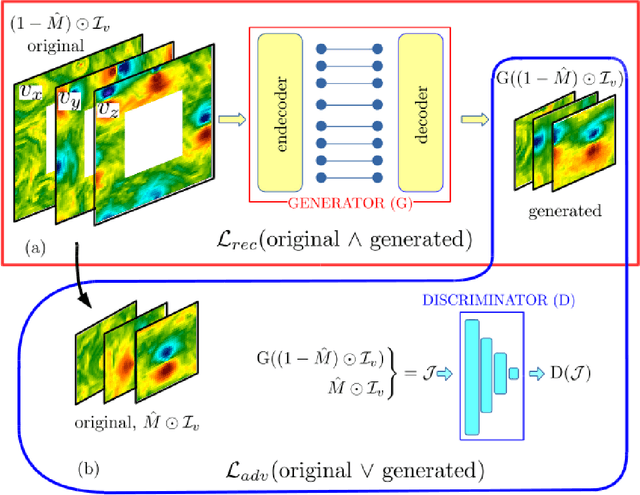
We study the applicability of tools developed by the computer vision community for features learning and semantic image inpainting to perform data reconstruction of fluid turbulence configurations. The aim is twofold. First, we explore on a quantitative basis, the capability of Convolutional Neural Networks embedded in a Deep Generative Adversarial Model (Deep-GAN) to generate missing data in turbulence, a paradigmatic high dimensional chaotic system. In particular, we investigate their use in reconstructing two-dimensional damaged snapshots extracted from a large database of numerical configurations of 3d turbulence in the presence of rotation, a case with multi-scale random features where both large-scale organised structures and small-scale highly intermittent and non-Gaussian fluctuations are present. Second, following a reverse engineering approach, we aim to rank the input flow properties (features) in terms of their qualitative and quantitative importance to obtain a better set of reconstructed fields. We present two approaches both based on Context Encoders. The first one infers the missing data via a minimization of the L2 pixel-wise reconstruction loss, plus a small adversarial penalisation. The second searches for the closest encoding of the corrupted flow configuration from a previously trained generator. Finally, we present a comparison with a different data assimilation tool, based on Nudging, an equation-informed unbiased protocol, well known in the numerical weather prediction community. The TURB-Rot database, \url{http://smart-turb.roma2.infn.it}, of roughly 300K 2d turbulent images is released and details on how to download it are given.
Multi-task Learning with Crowdsourced Features Improves Skin Lesion Diagnosis
Apr 28, 2020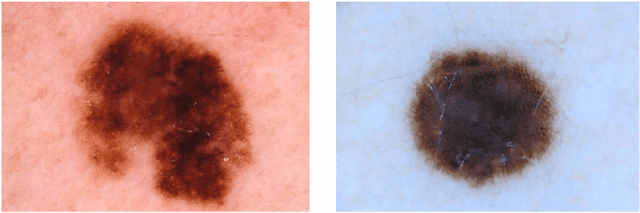
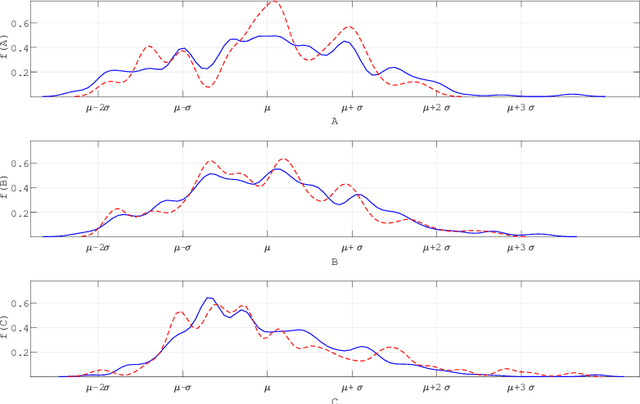
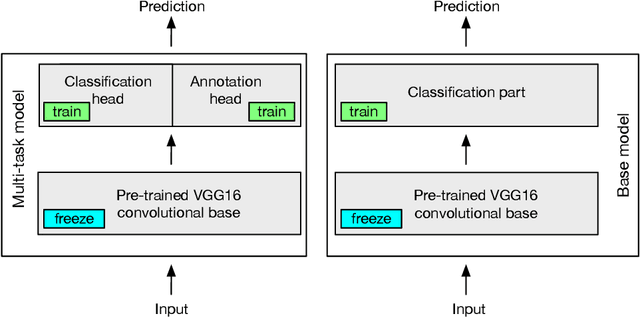
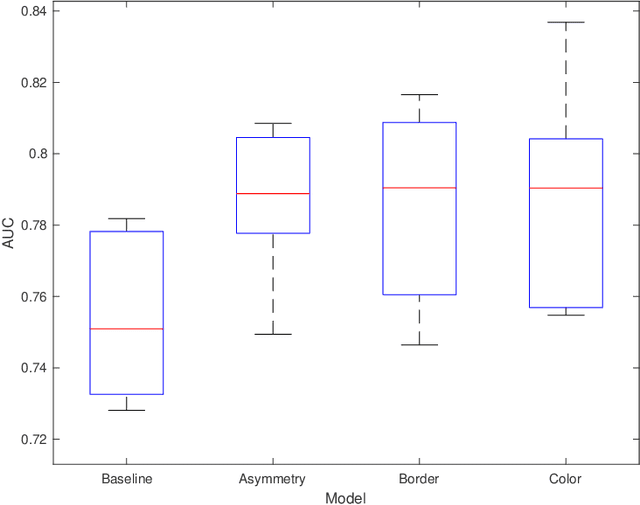
Machine learning has a recognised need for large amounts of annotated data. Due to the high cost of expert annotations, crowdsourcing, where non-experts are asked to label or outline images, has been proposed as an alternative. Although many promising results are reported, the quality of diagnostic crowdsourced labels is still lacking. We propose to address this by instead asking the crowd about visual features of the images, which can be provided more intuitively, and by using these features in a multi-task learning framework. We compare our proposed approach to a baseline model with a set of 2000 skin lesions from the ISIC 2017 challenge dataset. The baseline model only predicts a binary label from the skin lesion image, while our multi-task model also predicts one of the following features: asymmetry of the lesion, border irregularity and color. We show that crowd features in combination with multi-task learning leads to improved generalisation. The area under the receiver operating characteristic curve is 0.754 for the baseline model and 0.782, 0.785 and 0.789 for multi-task models with border, color and asymmetry respectively. Finally, we discuss the findings, identify some limitations and recommend directions for further research.
Monocular Depth Estimation with Self-supervised Instance Adaptation
Apr 13, 2020
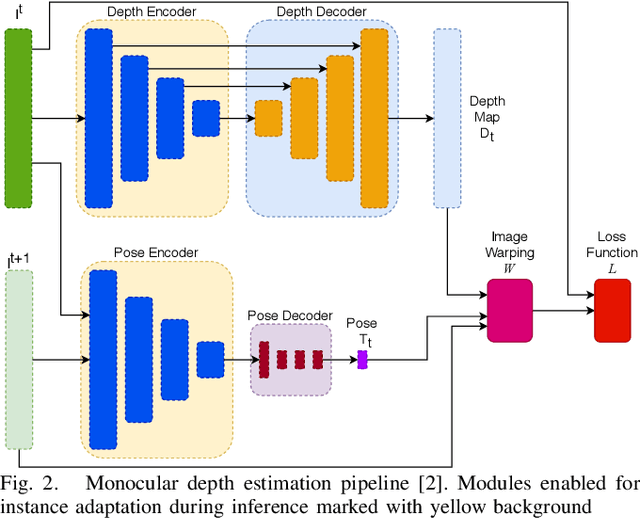
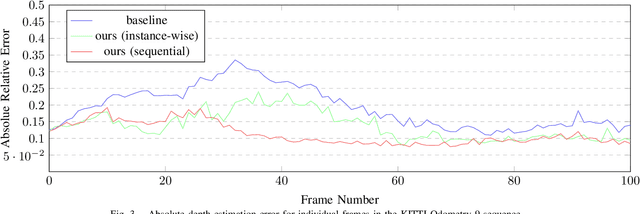
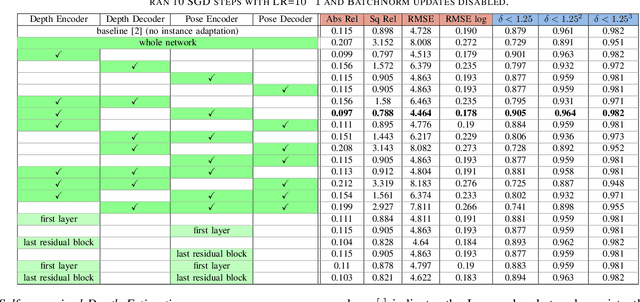
Recent advances in self-supervised learning havedemonstrated that it is possible to learn accurate monoculardepth reconstruction from raw video data, without using any 3Dground truth for supervision. However, in robotics applications,multiple views of a scene may or may not be available, depend-ing on the actions of the robot, switching between monocularand multi-view reconstruction. To address this mixed setting,we proposed a new approach that extends any off-the-shelfself-supervised monocular depth reconstruction system to usemore than one image at test time. Our method builds on astandard prior learned to perform monocular reconstruction,but uses self-supervision at test time to further improve thereconstruction accuracy when multiple images are available.When used to update the correct components of the model, thisapproach is highly-effective. On the standard KITTI bench-mark, our self-supervised method consistently outperformsall the previous methods with an average 25% reduction inabsolute error for the three common setups (monocular, stereoand monocular+stereo), and comes very close in accuracy whencompared to the fully-supervised state-of-the-art methods.
Deep Metric Learning Beyond Binary Supervision
Apr 21, 2019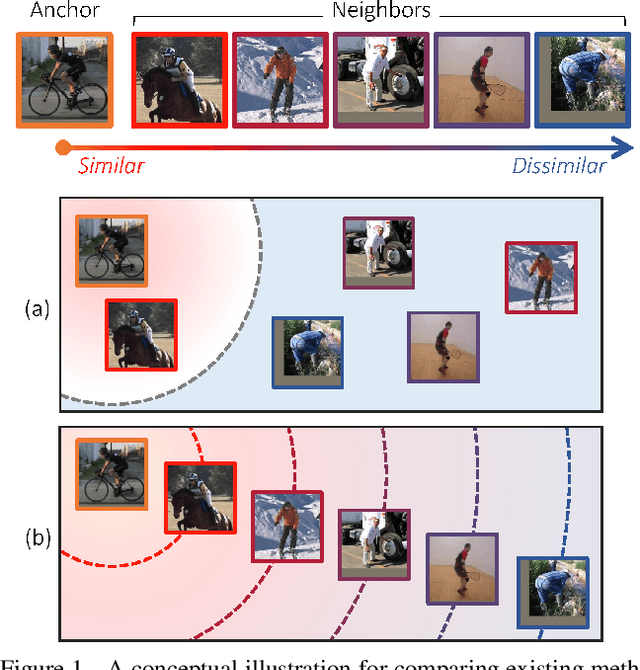
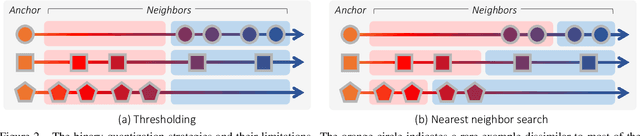
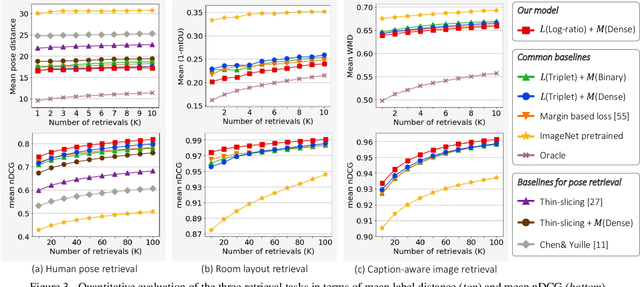
Metric Learning for visual similarity has mostly adopted binary supervision indicating whether a pair of images are of the same class or not. Such a binary indicator covers only a limited subset of image relations, and is not sufficient to represent semantic similarity between images described by continuous and/or structured labels such as object poses, image captions, and scene graphs. Motivated by this, we present a novel method for deep metric learning using continuous labels. First, we propose a new triplet loss that allows distance ratios in the label space to be preserved in the learned metric space. The proposed loss thus enables our model to learn the degree of similarity rather than just the order. Furthermore, we design a triplet mining strategy adapted to metric learning with continuous labels. We address three different image retrieval tasks with continuous labels in terms of human poses, room layouts and image captions, and demonstrate the superior performance of our approach compared to previous methods.
FoCL: Feature-Oriented Continual Learning for Generative Models
Mar 09, 2020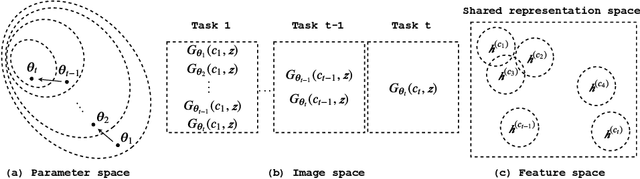



In this paper, we propose a general framework in continual learning for generative models: Feature-oriented Continual Learning (FoCL). Unlike previous works that aim to solve the catastrophic forgetting problem by introducing regularization in the parameter space or image space, FoCL imposes regularization in the feature space. We show in our experiments that FoCL has faster adaptation to distributional changes in sequentially arriving tasks, and achieves the state-of-the-art performance for generative models in task incremental learning. We discuss choices of combined regularization spaces towards different use case scenarios for boosted performance, e.g., tasks that have high variability in the background. Finally, we introduce a forgetfulness measure that fairly evaluates the degree to which a model suffers from forgetting. Interestingly, the analysis of our proposed forgetfulness score also implies that FoCL tends to have a mitigated forgetting for future tasks.