 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Boltzmann Machines and Denoising Autoencoders for Image Denoising
Mar 04, 2013

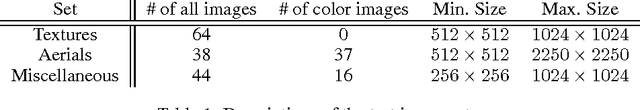
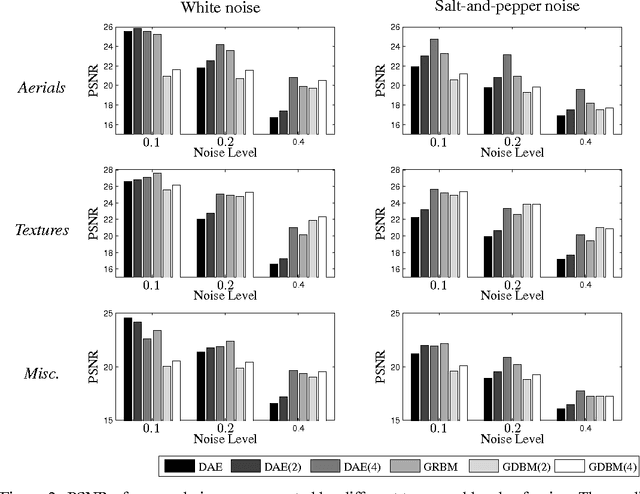

Image denoising based on a probabilistic model of local image patches has been employed by various researchers, and recently a deep (denoising) autoencoder has been proposed by Burger et al. [2012] and Xie et al. [2012] as a good model for this. In this paper, we propose that another popular family of models in the field of deep learning, called Boltzmann machines, can perform image denoising as well as, or in certain cases of high level of noise, better than denoising autoencoders. We empirically evaluate the two models on three different sets of images with different types and levels of noise. Throughout the experiments we also examine the effect of the depth of the models. The experiments confirmed our claim and revealed that the performance can be improved by adding more hidden layers, especially when the level of noise is high.
Distilled Hierarchical Neural Ensembles with Adaptive Inference Cost
Apr 01, 2020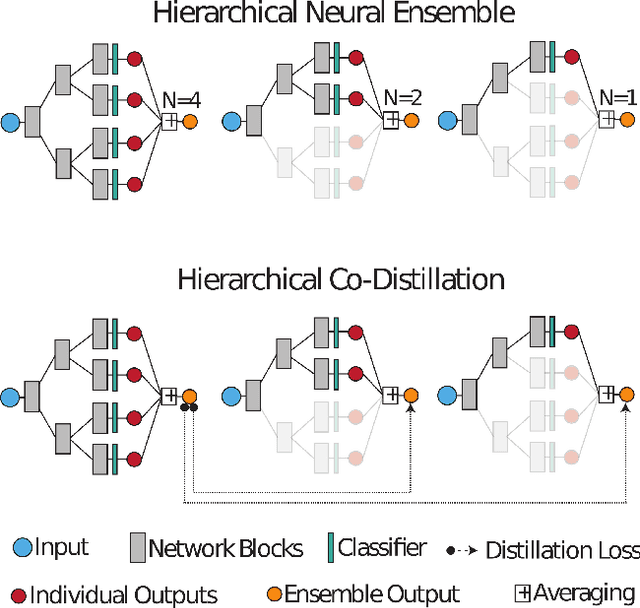
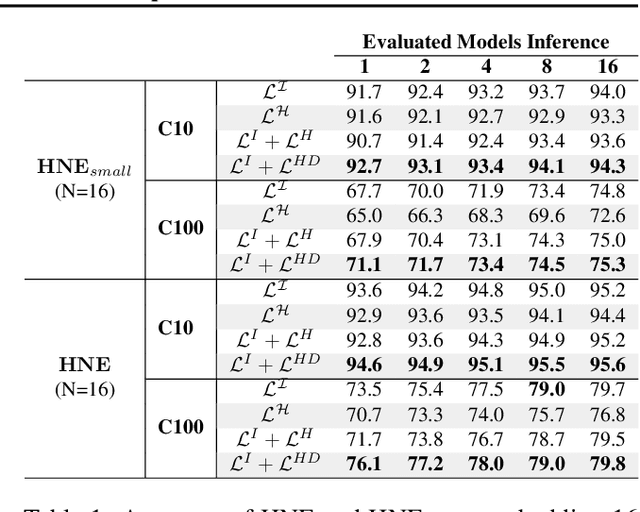
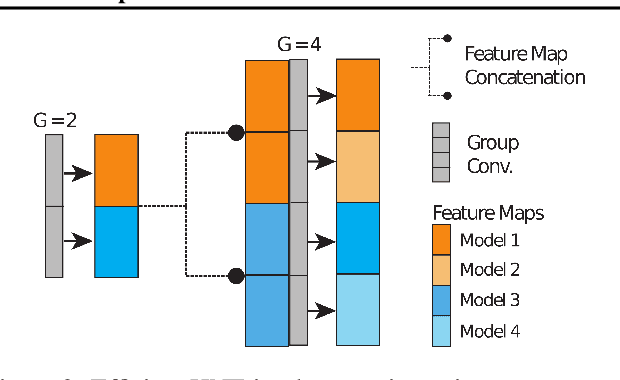
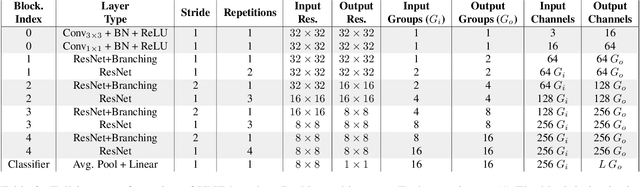
Deep neural networks form the basis of state-of-the-art models across a variety of application domains. Moreover, networks that are able to dynamically adapt the computational cost of inference are important in scenarios where the amount of compute or input data varies over time. In this paper, we propose Hierarchical Neural Ensembles (HNE), a novel framework to embed an ensemble of multiple networks by sharing intermediate layers using a hierarchical structure. In HNE we control the inference cost by evaluating only a subset of models, which are organized in a nested manner. Our second contribution is a novel co-distillation method to boost the performance of ensemble predictions with low inference cost. This approach leverages the nested structure of our ensembles, to optimally allocate accuracy and diversity across the ensemble members. Comprehensive experiments over the CIFAR and ImageNet datasets confirm the effectiveness of HNE in building deep networks with adaptive inference cost for image classification.
A Hierarchical Deep Convolutional Neural Network and Gated Recurrent Unit Framework for Structural Damage Detection
May 29, 2020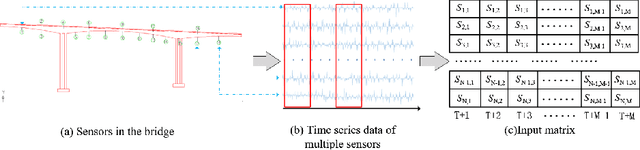

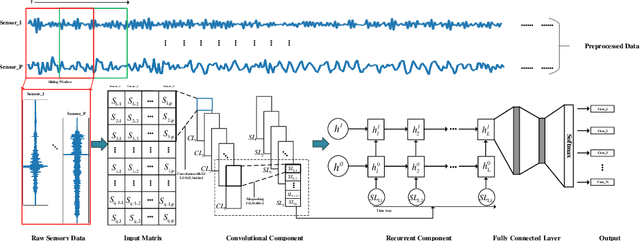

Structural damage detection has become an interdisciplinary area of interest for various engineering fields, while the available damage detection methods are being in the process of adapting machine learning concepts. Most machine learning based methods heavily depend on extracted ``hand-crafted" features that are manually selected in advance by domain experts and then, fixed. Recently, deep learning has demonstrated remarkable performance on traditional challenging tasks, such as image classification, object detection, etc., due to the powerful feature learning capabilities. This breakthrough has inspired researchers to explore deep learning techniques for structural damage detection problems. However, existing methods have considered either spatial relation (e.g., using convolutional neural network (CNN)) or temporal relation (e.g., using long short term memory network (LSTM)) only. In this work, we propose a novel Hierarchical CNN and Gated recurrent unit (GRU) framework to model both spatial and temporal relations, termed as HCG, for structural damage detection. Specifically, CNN is utilized to model the spatial relations and the short-term temporal dependencies among sensors, while the output features of CNN are fed into the GRU to learn the long-term temporal dependencies jointly. Extensive experiments on IASC-ASCE structural health monitoring benchmark and scale model of three-span continuous rigid frame bridge structure datasets have shown that our proposed HCG outperforms other existing methods for structural damage detection significantly.
Recasting Residual-based Local Descriptors as Convolutional Neural Networks: an Application to Image Forgery Detection
Mar 14, 2017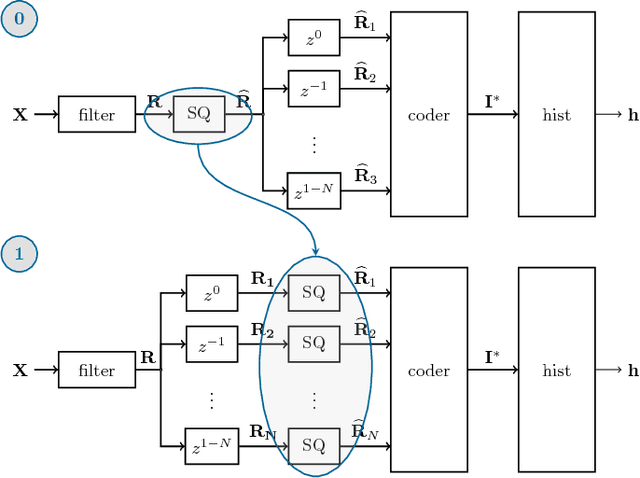
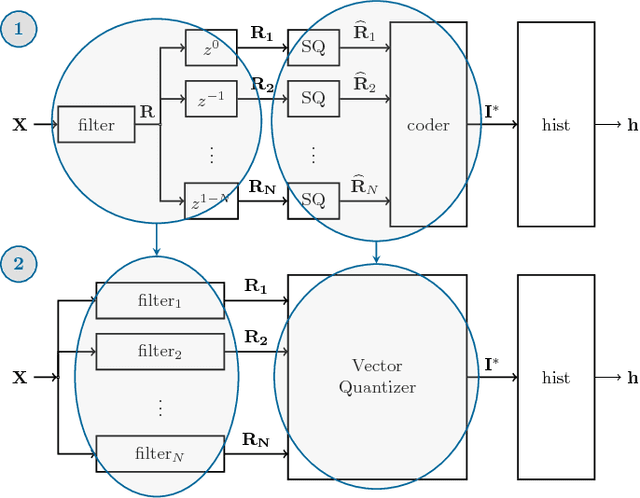
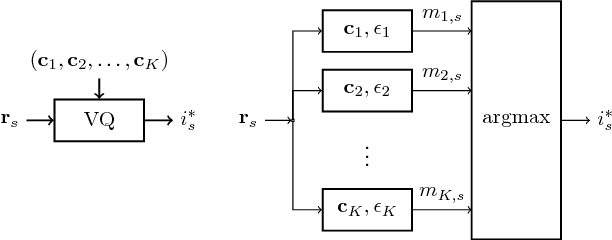
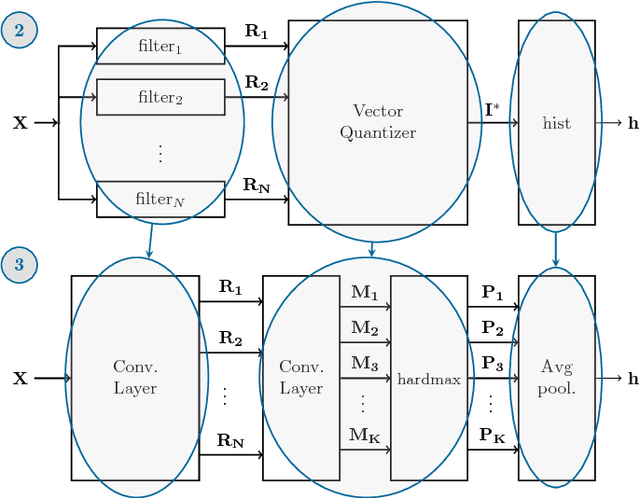
Local descriptors based on the image noise residual have proven extremely effective for a number of forensic applications, like forgery detection and localization. Nonetheless, motivated by promising results in computer vision, the focus of the research community is now shifting on deep learning. In this paper we show that a class of residual-based descriptors can be actually regarded as a simple constrained convolutional neural network (CNN). Then, by relaxing the constraints, and fine-tuning the net on a relatively small training set, we obtain a significant performance improvement with respect to the conventional detector.
Correcting Multi-focus Images via Simple Standard Deviation for Image Fusion
Sep 29, 2013
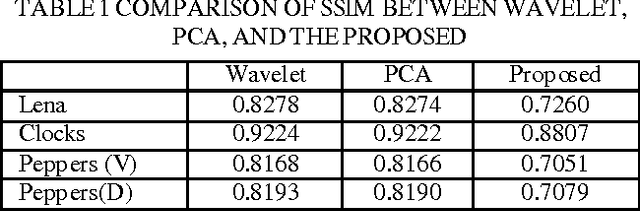
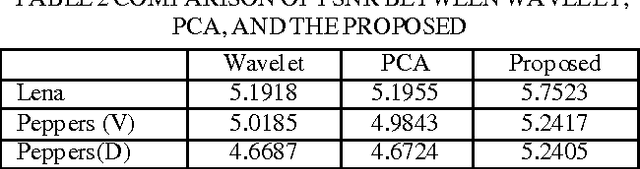

Image fusion is one of the recent trends in image registration which is an essential field of image processing. The basic principle of this paper is to fuse multi-focus images using simple statistical standard deviation. Firstly, the simple standard deviation for the k-by-k window inside each of the multi-focus images was computed. The contribution in this paper came from the idea that the focused part inside an image had high details rather than the unfocused part. Hence, the dispersion between pixels inside the focused part is higher than the dispersion inside the unfocused part. Secondly, a simple comparison between the standard deviation for each k-by-k window in the multi-focus images could be computed. The highest standard deviation between all the computed standard deviations for the multi-focus images could be treated as the optimal that is to be placed in the fused image. The experimental visual results show that the proposed method produces very satisfactory results in spite of its simplicity.
Semantic Deep Intermodal Feature Transfer: Transferring Feature Descriptors Between Imaging Modalities
Jul 26, 2019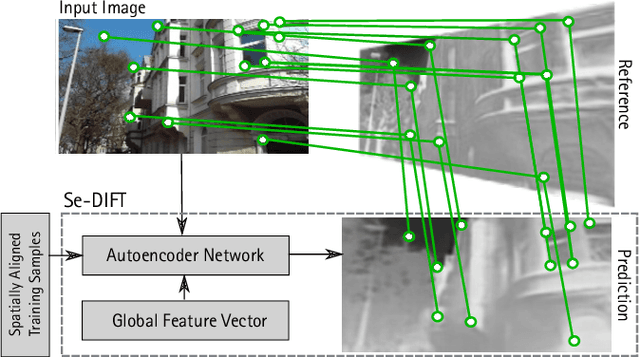



Under difficult environmental conditions, the view of RGB cameras may be restricted by fog, dust or difficult lighting situations. Because thermal cameras visualize thermal radiation, they are not subject to the same limitations as RGB cameras. However, because RGB and thermal imaging differ significantly in appearance, common, state-of-the-art feature descriptors are unsuitable for intermodal feature matching between these imaging modalities. As a consequence, visual maps created with an RGB camera can currently not be used for localization using a thermal camera. In this paper, we introduce the Semantic Deep Intermodal Feature Transfer (Se-DIFT), an approach for transferring image feature descriptors from the visual to the thermal spectrum and vice versa. For this purpose, we predict potential feature appearance in varying imaging modalities using a deep convolutional encoder-decoder architecture in combination with a global feature vector. Since the representation of a thermal image is not only affected by features which can be extracted from an RGB image, we introduce the global feature vector which augments the auto encoder's coding. The global feature vector contains additional information about the thermal history of a scene which is automatically extracted from external data sources. By augmenting the encoder's coding, we decrease the L1 error of the prediction by more than 7% compared to the prediction of a traditional U-Net architecture. To evaluate our approach, we match image feature descriptors detected in RGB and thermal images using Se-DIFT. Subsequently, we make a competitive comparison on the intermodal transferability of SIFT, SURF, and ORB features using our approach.
Feature selection of neural networks is skewed towards the less abstract cue
Aug 08, 2019


Artificial neural networks (ANNs) have become an important tool for image classification with many applications in research and industry. However, it remains largely unknown how relevant image features are selected and how data properties affect this process. In particular, we are interested whether the abstraction level of image cues correlating with class membership influences feature selection. We perform experiments with binary images that contain a combination of cues, representing two different levels of abstractions: one is a pattern drawn from a random distribution where class membership correlates with the statistics of the pattern, the other a combination of symbol-like entities, where the symbolic code correlates with class membership. When the network is trained with data in which both cues are equally significant, we observe that the cues at the lower abstraction level, i.e., the pattern, is learned, while the symbolic information is largely ignored, even in networks with many layers. Symbol-like entities are only learned if the importance of low-level cues is reduced compared to the high-level ones. These findings raise important questions about the relevance of features that are learned by deep ANNs and how learning could be shifted towards symbolic features.
ERNet Family: Hardware-Oriented CNN Models for Computational Imaging Using Block-Based Inference
Oct 13, 2019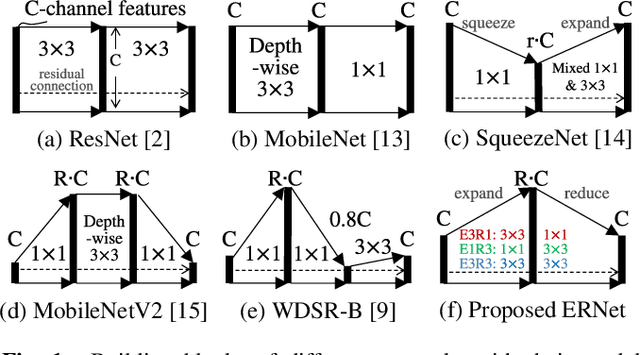
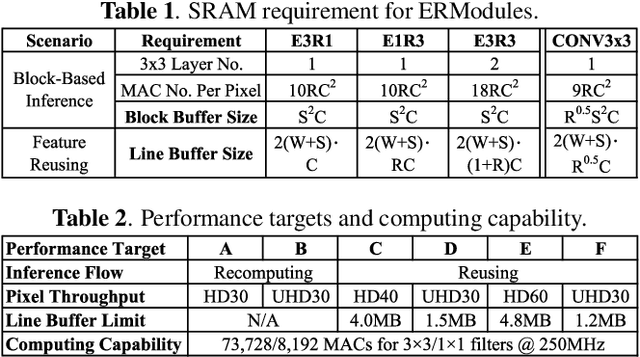
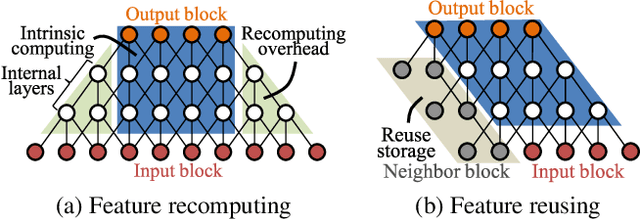
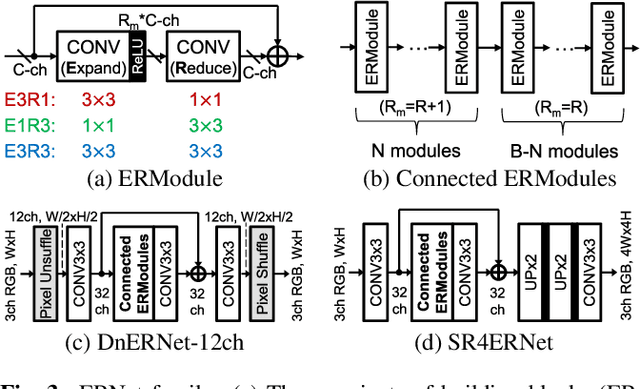
Convolutional neural networks (CNNs) demand huge DRAM bandwidth for computational imaging tasks, and block-based processing has recently been applied to greatly reduce the bandwidth. However, the induced additional computation for feature recomputing or the large SRAM for feature reusing will degrade the performance or even forbid the usage of state-of-the-art models. In this paper, we address these issues by considering the overheads and hardware constraints in advance when constructing CNNs. We investigate a novel model family---ERNet---which includes temporary layer expansion as another means for increasing model capacity. We analyze three ERNet variants in terms of hardware requirement and introduce a hardware-aware model optimization procedure. Evaluations on Full HD and 4K UHD applications will be given to show the effectiveness in terms of image quality, pixel throughput, and SRAM usage. The results also show that, for block-based inference, ERNet can outperform the state-of-the-art FFDNet and EDSR-baseline models for image denoising and super-resolution respectively.
From Two Graphs to N Questions: A VQA Dataset for Compositional Reasoning on Vision and Commonsense
Aug 08, 2019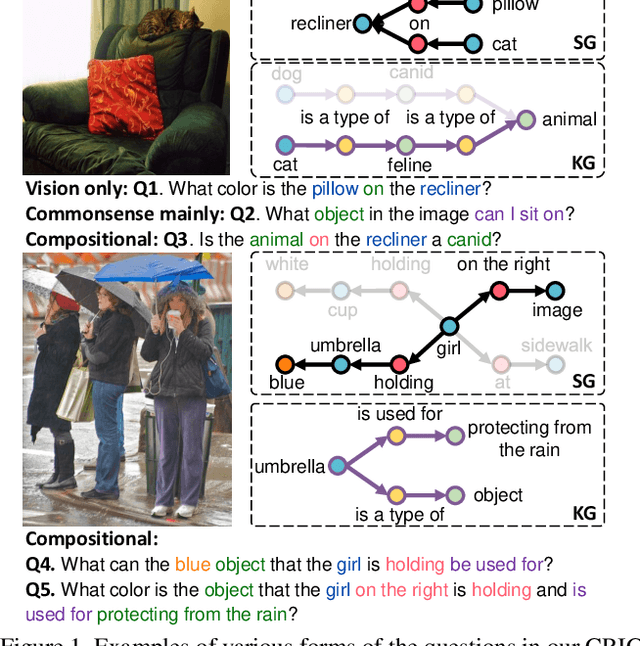
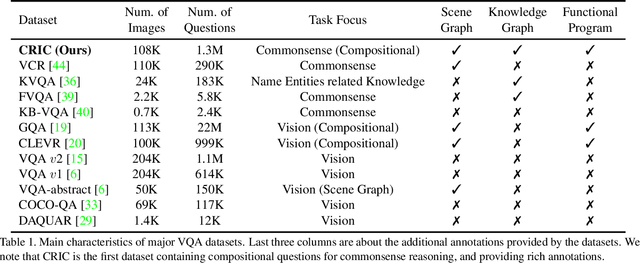
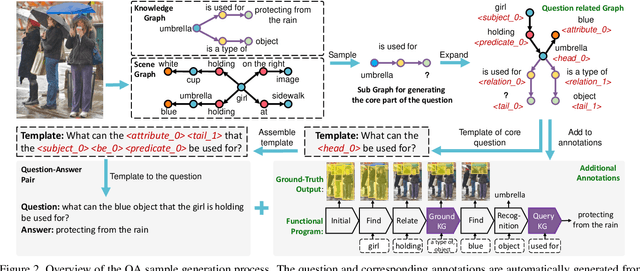
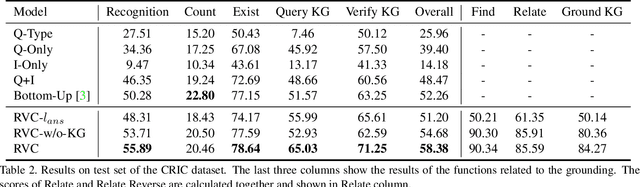
Visual Question Answering (VQA) is a challenging task for evaluating the ability of comprehensive understanding of the world. Existing benchmarks usually focus on the reasoning abilities either only on the vision or mainly on the knowledge with relatively simple abilities on vision. However, the ability of answering a question that requires alternatively inferring on the image content and the commonsense knowledge is crucial for an advanced VQA system. In this paper, we introduce a VQA dataset that provides more challenging and general questions about Compositional Reasoning on vIsion and Commonsense, which is named as CRIC. To create this dataset, we develop a powerful method to automatically generate compositional questions and rich annotations from both the scene graph of a given image and some external knowledge graph. Moreover, this paper presents a new compositional model that is capable of implementing various types of reasoning functions on the image content and the knowledge graph. Further, we analyze several baselines, state-of-the-art and our model on CRIC dataset. The experimental results show that the proposed task is challenging, where state-of-the-art obtains 52.26% accuracy and our model obtains 58.38%.
KeystoneDepth: Visualizing History in 3D
Aug 21, 2019


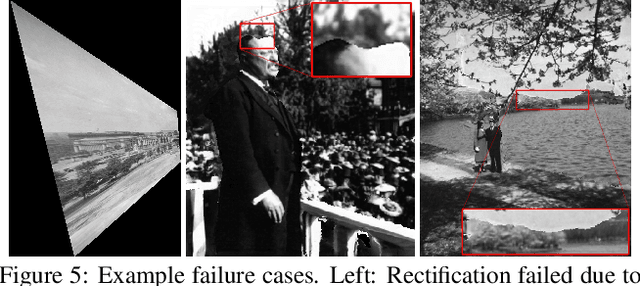
This paper introduces the largest and most diverse collection of rectified stereo image pairs to the research community, KeystoneDepth, consisting of tens of thousands of stereographs of historical people, events, objects, and scenes between 1860 and 1963. Leveraging the Keystone-Mast raw scans from the California Museum of Photography, we apply multiple processing steps to produce clean stereo image pairs, complete with calibration data, rectification transforms, and depthmaps. A second contribution is a novel approach for view synthesis that runs at real-time rates on a mobile device, simulating the experience of looking through an open window into these historical scenes. We produce results for thousands of antique stereographs, capturing many important historical moments.