 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProduct units in gated recurrent units improve nuclear-mass prediction
Jun 05, 2026The prediction of masses of atomic nuclei using machine learning can complement theoretical models and advance the exploration of poorly known domains of the nuclear chart. We propose a machine learning technique based on gated recurrent units (GRU), which have demonstrated competitive performance in nuclear-mass prediction by exploiting long-term dependencies. By integrating multiplicative interactions and product-unit transformations within recurrent units, we report significant improvements in nuclear-mass prediction. Computations are performed in the complex domain to jointly capture amplitude and phase dynamics. For interpolation and temporal-extrapolation tasks based on the atomic mass evaluation (AME2016 and AME2020), the complex additive-multiplicative product-unit gated recurrent unit (AM-PU-GRU) model consistently achieves the lowest prediction errors, with an interpolation RMSE of 0.227 $\pm$ 0.004 MeV and an extrapolation RMSE of 0.179 $\pm$ 0.015 MeV. These results surpass other state-of-the-art machine learning models and also outperform the real-valued GRU baseline and product-unit ablation variants, while remaining robust to different theoretical priors, including WS4 and SEMF. Our findings establish complex-valued product-unit recurrent networks as a new benchmark for sequence-based nuclear-mass prediction.
Modeling Nonlinear Feature Interactions with Product-Unit Residual Networks
Jun 05, 2026Understanding nonlinear feature interactions is crucial in science and engineering, yet standard multilayer perceptrons (MLPs) often capture such interactions only implicitly, leading to entangled representations that can impair robustness and interpretability. We investigate product-unit residual networks (PURe) that integrate multiplicative product units with residual connections to explicitly model cross-feature couplings while stabilizing optimization. We conduct a systematic evaluation on an interaction-driven synthetic benchmark and two real-world datasets, assessing predictive accuracy, robustness to Gaussian feature noise, and performance under limited training data, and we compare real- and complex-valued variants under a matched parameter budget. Beyond accuracy, SHapley Additive exPlanations (SHAP)-based interaction analyses show that PURe learns more concentrated and structurally coherent interaction patterns than MLP baselines. Overall, PURe achieves competitive or improved performance, better robustness and sample efficiency in low-data regimes, and enhanced interaction-level interpretability.
Model discovery for dynamical systems with complex-valued product units
May 26, 2026Discovering the governing equations of a dynamical system from observed trajectories provides deeper insight into its structure than mere prediction of future states. We present a data-driven approach to model discovery based on complex-valued product-unit networks, in which each unit represents a complex monomial and the network output is a sparse linear combination of such monomials. In contrast to established library-based methods such as SINDy, our approach does not require a predefined set of candidate functions: the relevant monomials, including those with fractional or negative exponents, are learned directly from data. Across four chaotic benchmark systems (Lorenz63, Lorenz84, the Four-Wing attractor, and a fractional variant of Lorenz63), we recover the exact governing equations in 90% of trials for the first three systems, and in 70-90% of trials for the fractional case, using at least 3000 training points. Applied to real-world human-gait accelerometer signals, the model produced stable trajectories with bounded prediction errors, corresponding to an RMSE of approximately 12-14% of the signal amplitude range over a test horizon three times longer than the training interval, demonstrating its potential for high-dimensional systems in which analytic equations are unavailable.
Anatomy-Informed Deep Learning for Abdominal Aortic Aneurysm Segmentation
Apr 11, 2026In CT angiography, the accurate segmentation of abdominal aortic aneurysms (AAAs) is difficult due to large anatomical variability, low-contrast vessel boundaries, and the close proximity of organs whose intensities resemble vascular structures, often leading to false positives. To address these challenges, we propose an anatomy-aware segmentation framework that integrates organ exclusion masks derived from TotalSegmentator into the training process. These masks encode explicit anatomical priors by identifying non-vascular organsand penalizing aneurysm predictions within these regions, thereby guiding the U-Net to focus on the aorta and its pathological dilation while suppressing anatomically implausible predictions. Despite being trained on a relatively small dataset, the anatomy-aware model achieves high accuracy, substantially reduces false positives, and improves boundary consistency compared to a standard U-Net baseline. The results demonstrate that incorporating anatomical knowledge through exclusion masks provides an efficient mechanism to enhance robustness and generalization, enabling reliable AAA segmentation even with limited training data.
Deep residual learning with product units
May 07, 2025



We propose a deep product-unit residual neural network (PURe) that integrates product units into residual blocks to improve the expressiveness and parameter efficiency of deep convolutional networks. Unlike standard summation neurons, product units enable multiplicative feature interactions, potentially offering a more powerful representation of complex patterns. PURe replaces conventional convolutional layers with 2D product units in the second layer of each residual block, eliminating nonlinear activation functions to preserve structural information. We validate PURe on three benchmark datasets. On Galaxy10 DECaLS, PURe34 achieves the highest test accuracy of 84.89%, surpassing the much deeper ResNet152, while converging nearly five times faster and demonstrating strong robustness to Poisson noise. On ImageNet, PURe architectures outperform standard ResNet models at similar depths, with PURe34 achieving a top-1 accuracy of 80.27% and top-5 accuracy of 95.78%, surpassing deeper ResNet variants (ResNet50, ResNet101) while utilizing significantly fewer parameters and computational resources. On CIFAR-10, PURe consistently outperforms ResNet variants across varying depths, with PURe272 reaching 95.01% test accuracy, comparable to ResNet1001 but at less than half the model size. These results demonstrate that PURe achieves a favorable balance between accuracy, efficiency, and robustness. Compared to traditional residual networks, PURe not only achieves competitive classification performance with faster convergence and fewer parameters, but also demonstrates greater robustness to noise. Its effectiveness across diverse datasets highlights the potential of product-unit-based architectures for scalable and reliable deep learning in computer vision.
Predicting nuclear masses with product-unit networks
May 08, 2023



Accurate estimation of nuclear masses and their prediction beyond the experimentally explored domains of the nuclear landscape are crucial to an understanding of the fundamental origin of nuclear properties and to many applications of nuclear science, most notably in quantifying the $r$-process of stellar nucleosynthesis. Neural networks have been applied with some success to the prediction of nuclear masses, but they are known to have shortcomings in application to extrapolation tasks. In this work, we propose and explore a novel type of neural network for mass prediction in which the usual neuron-like processing units are replaced by complex-valued product units that permit multiplicative couplings of inputs to be learned from the input data. This generalized network model is tested on both interpolation and extrapolation data sets drawn from the Atomic Mass Evaluation. Its performance is compared with that of several neural-network architectures, substantiating its suitability for nuclear mass prediction. Additionally, a prediction-uncertainty measure for such complex-valued networks is proposed that serves to identify regions of expected low prediction error.
3D object reconstruction and 6D-pose estimation from 2D shape for robotic grasping of objects
Mar 02, 2022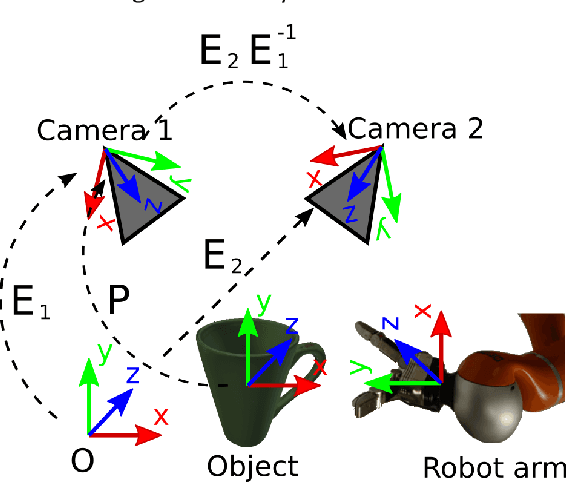

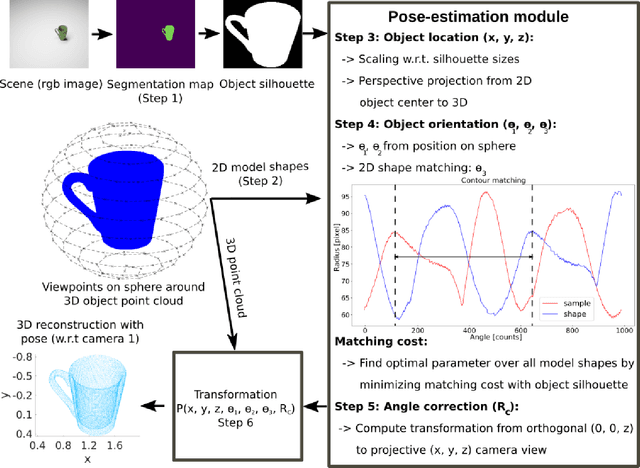
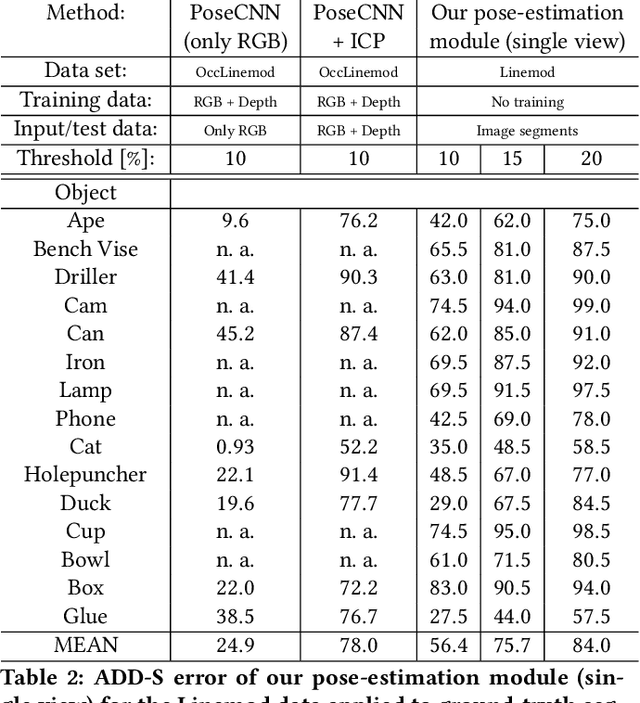
We propose a method for 3D object reconstruction and 6D-pose estimation from 2D images that uses knowledge about object shape as the primary key. In the proposed pipeline, recognition and labeling of objects in 2D images deliver 2D segment silhouettes that are compared with the 2D silhouettes of projections obtained from various views of a 3D model representing the recognized object class. By computing transformation parameters directly from the 2D images, the number of free parameters required during the registration process is reduced, making the approach feasible. Furthermore, 3D transformations and projective geometry are employed to arrive at a full 3D reconstruction of the object in camera space using a calibrated set up. Inclusion of a second camera allows resolving remaining ambiguities. The method is quantitatively evaluated using synthetic data and tested with real data, and additional results for the well-known Linemod data set are shown. In robot experiments, successful grasping of objects demonstrates its usability in real-world environments, and, where possible, a comparison with other methods is provided. The method is applicable to scenarios where 3D object models, e.g., CAD-models or point clouds, are available and precise pixel-wise segmentation maps of 2D images can be obtained. Different from other methods, the method does not use 3D depth for training, widening the domain of application.
Feature selection of neural networks is skewed towards the less abstract cue
Aug 08, 2019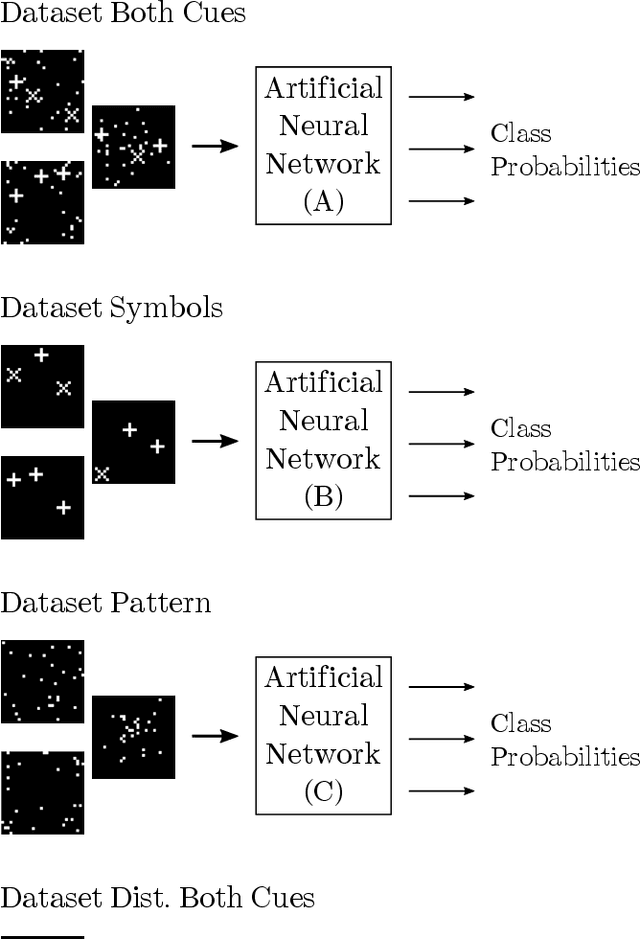


Artificial neural networks (ANNs) have become an important tool for image classification with many applications in research and industry. However, it remains largely unknown how relevant image features are selected and how data properties affect this process. In particular, we are interested whether the abstraction level of image cues correlating with class membership influences feature selection. We perform experiments with binary images that contain a combination of cues, representing two different levels of abstractions: one is a pattern drawn from a random distribution where class membership correlates with the statistics of the pattern, the other a combination of symbol-like entities, where the symbolic code correlates with class membership. When the network is trained with data in which both cues are equally significant, we observe that the cues at the lower abstraction level, i.e., the pattern, is learned, while the symbolic information is largely ignored, even in networks with many layers. Symbol-like entities are only learned if the importance of low-level cues is reduced compared to the high-level ones. These findings raise important questions about the relevance of features that are learned by deep ANNs and how learning could be shifted towards symbolic features.