 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Asymmetric metric learning for knowledge transfer
Jun 29, 2020
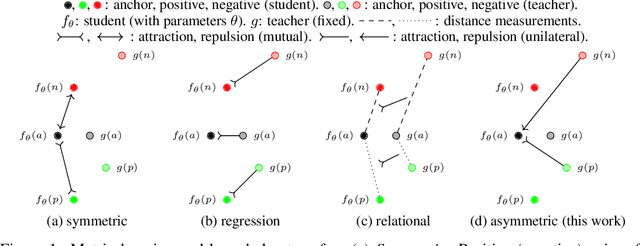
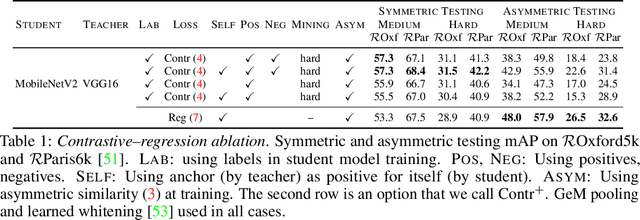
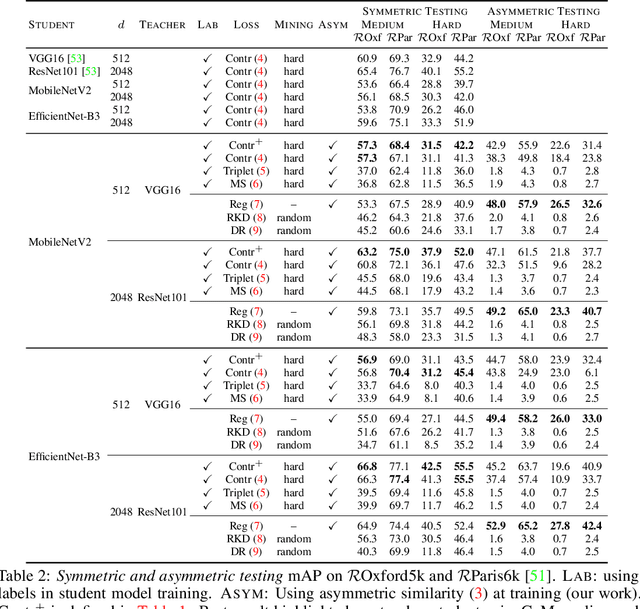

Knowledge transfer from large teacher models to smaller student models has recently been studied for metric learning, focusing on fine-grained classification. In this work, focusing on instance-level image retrieval, we study an asymmetric testing task, where the database is represented by the teacher and queries by the student. Inspired by this task, we introduce asymmetric metric learning, a novel paradigm of using asymmetric representations at training. This acts as a simple combination of knowledge transfer with the original metric learning task. We systematically evaluate different teacher and student models, metric learning and knowledge transfer loss functions on the new asymmetric testing as well as the standard symmetric testing task, where database and queries are represented by the same model. We find that plain regression is surprisingly effective compared to more complex knowledge transfer mechanisms, working best in asymmetric testing. Interestingly, our asymmetric metric learning approach works best in symmetric testing, allowing the student to even outperform the teacher.
NIT-Agartala-NLP-Team at SemEval-2020 Task 8: Building Multimodal Classifiers to tackle Internet Humor
May 16, 2020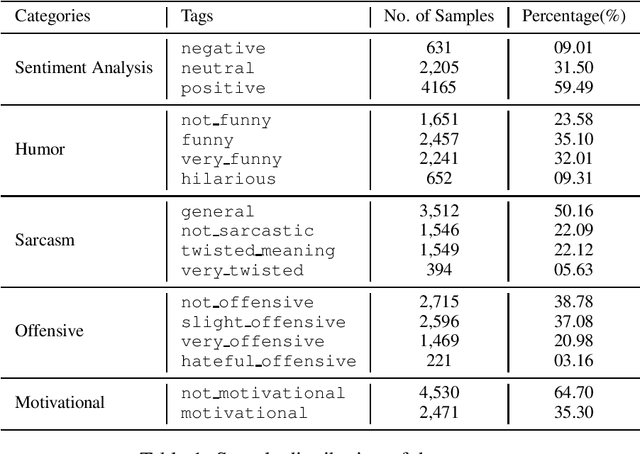
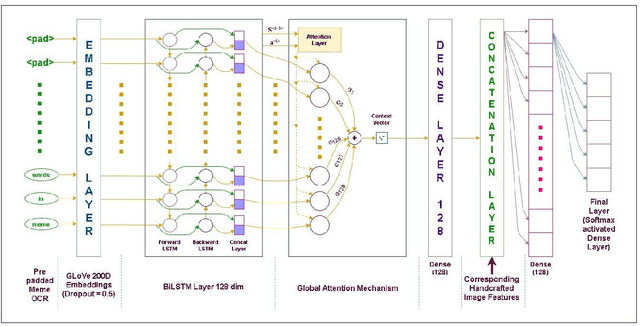


The paper describes the systems submitted to SemEval-2020 Task 8: Memotion by the `NIT-Agartala-NLP-Team'. A dataset of 8879 memes was made available by the task organizers to train and test our models. Our systems include a Logistic Regression baseline, a BiLSTM + Attention-based learner and a transfer learning approach with BERT. For the three sub-tasks A, B and C, we attained ranks 24/33, 11/29 and 15/26, respectively. We highlight our difficulties in harnessing image information as well as some techniques and handcrafted features we employ to overcome these issues. We also discuss various modelling issues and theorize possible solutions and reasons as to why these problems persist.
Weakly Supervised 3D Object Detection from Point Clouds
Jul 28, 2020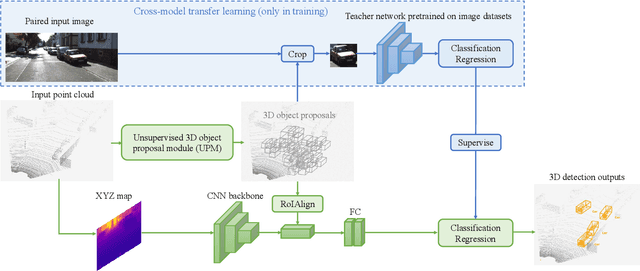
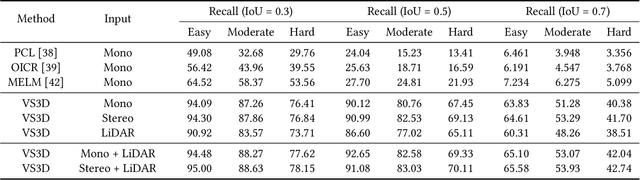
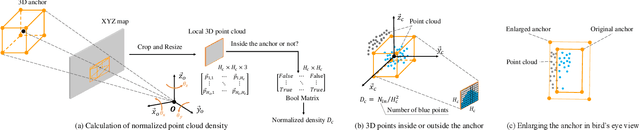
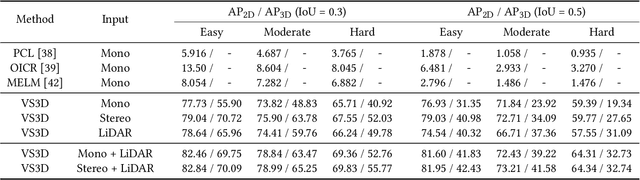
A crucial task in scene understanding is 3D object detection, which aims to detect and localize the 3D bounding boxes of objects belonging to specific classes. Existing 3D object detectors heavily rely on annotated 3D bounding boxes during training, while these annotations could be expensive to obtain and only accessible in limited scenarios. Weakly supervised learning is a promising approach to reducing the annotation requirement, but existing weakly supervised object detectors are mostly for 2D detection rather than 3D. In this work, we propose VS3D, a framework for weakly supervised 3D object detection from point clouds without using any ground truth 3D bounding box for training. First, we introduce an unsupervised 3D proposal module that generates object proposals by leveraging normalized point cloud densities. Second, we present a cross-modal knowledge distillation strategy, where a convolutional neural network learns to predict the final results from the 3D object proposals by querying a teacher network pretrained on image datasets. Comprehensive experiments on the challenging KITTI dataset demonstrate the superior performance of our VS3D in diverse evaluation settings. The source code and pretrained models are publicly available at https://github.com/Zengyi-Qin/Weakly-Supervised-3D-Object-Detection.
Applying a random projection algorithm to optimize machine learning model for breast lesion classification
Sep 09, 2020
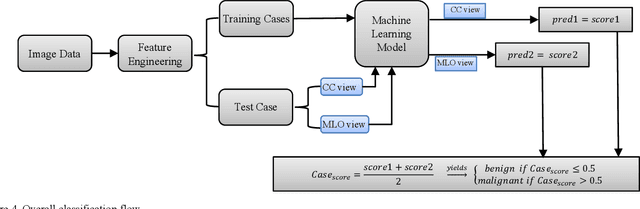
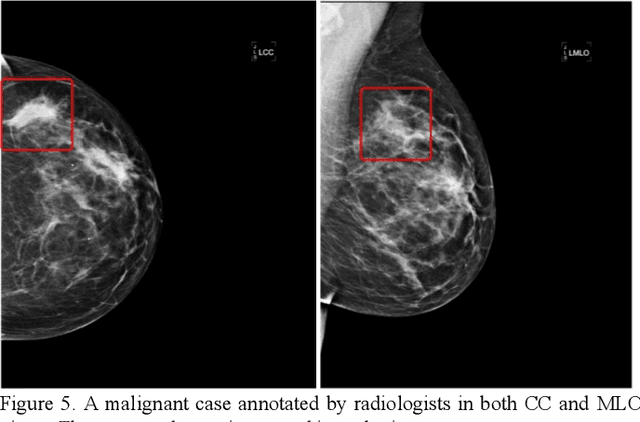
Machine learning is widely used in developing computer-aided diagnosis (CAD) schemes of medical images. However, CAD usually computes large number of image features from the targeted regions, which creates a challenge of how to identify a small and optimal feature vector to build robust machine learning models. In this study, we investigate feasibility of applying a random projection algorithm to build an optimal feature vector from the initially CAD-generated large feature pool and improve performance of machine learning model. We assemble a retrospective dataset involving 1,487 cases of mammograms in which 644 cases have confirmed malignant mass lesions and 843 have benign lesions. A CAD scheme is first applied to segment mass regions and initially compute 181 features. Then, support vector machine (SVM) models embedded with several feature dimensionality reduction methods are built to predict likelihood of lesions being malignant. All SVM models are trained and tested using a leave-one-case-out cross-validation method. SVM generates a likelihood score of each segmented mass region depicting on one-view mammogram. By fusion of two scores of the same mass depicting on two-view mammograms, a case-based likelihood score is also evaluated. Comparing with the principle component analyses, nonnegative matrix factorization, and Chi-squared methods, SVM embedded with the random projection algorithm yielded a significantly higher case-based lesion classification performance with the area under ROC curve of 0.84+0.01 (p<0.02). The study demonstrates that the random project algorithm is a promising method to generate optimal feature vectors to help improve performance of machine learning models of medical images.
Restricting the Flow: Information Bottlenecks for Attribution
Jan 02, 2020
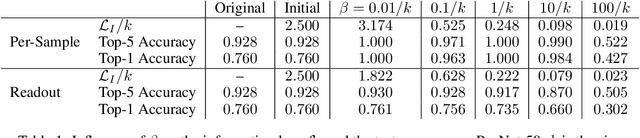
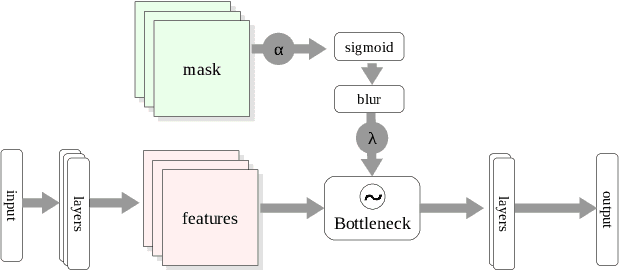
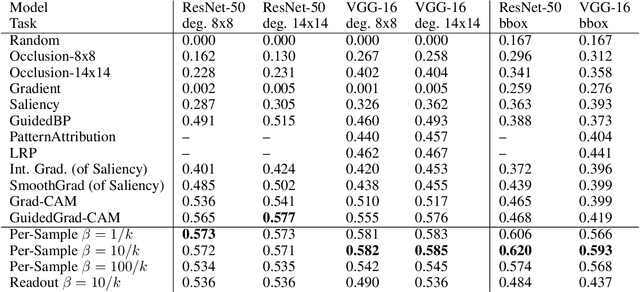
Attribution methods provide insights into the decision-making of machine learning models like artificial neural networks. For a given input sample, they assign a relevance score to each individual input variable, such as the pixels of an image. In this work we adapt the information bottleneck concept for attribution. By adding noise to intermediate feature maps we restrict the flow of information and can quantify (in bits) how much information image regions provide. We compare our method against ten baselines using three different metrics on VGG-16 and ResNet-50, and find that our methods outperform all baselines in five out of six settings. The method's information-theoretic foundation provides an absolute frame of reference for attribution values (bits) and a guarantee that regions scored close to zero are not necessary for the network's decision.
Variational Autoencoders with Normalizing Flow Decoders
Apr 12, 2020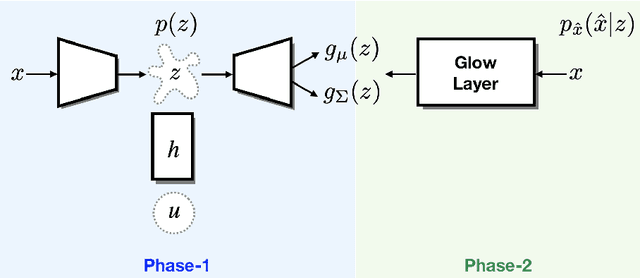
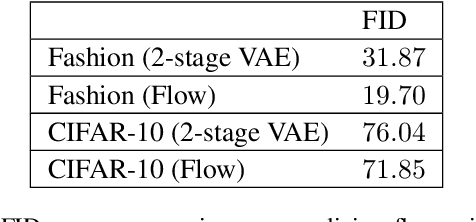

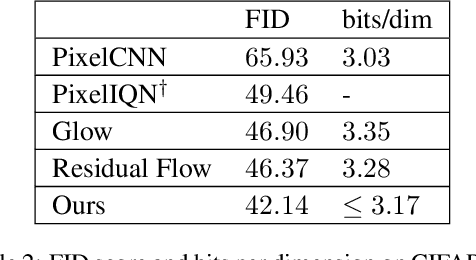
Recently proposed normalizing flow models such as Glow have been shown to be able to generate high quality, high dimensional images with relatively fast sampling speed. Due to their inherently restrictive architecture, however, it is necessary that they are excessively deep in order to train effectively. In this paper we propose to combine Glow with an underlying variational autoencoder in order to counteract this issue. We demonstrate that our proposed model is competitive with Glow in terms of image quality and test likelihood while requiring far less time for training.
Texture Hallucination for Large-Scale Painting Super-Resolution
Dec 01, 2019
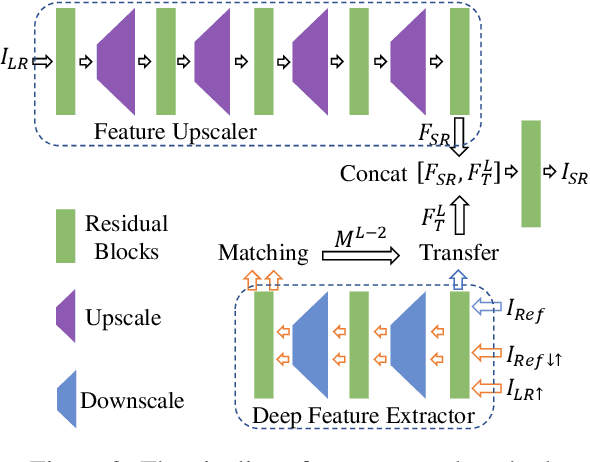
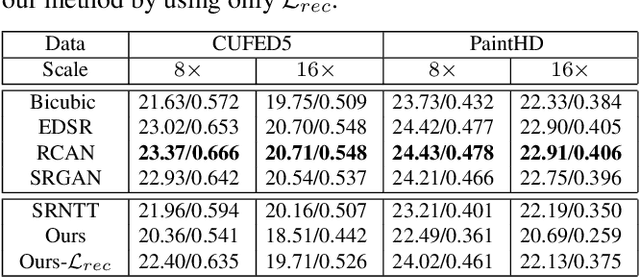
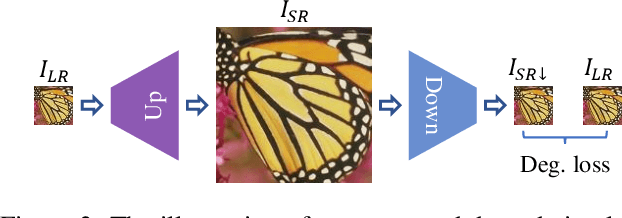
We aim to super-resolve digital paintings, synthesizing realistic details from high-resolution reference painting materials for very large scaling factors (e.g., 8x, 16x). However, previous single image super-resolution (SISR) methods would either lose textural details or introduce unpleasing artifacts. On the other hand, reference-based SR (Ref-SR) methods can transfer textures to some extent, but is still impractical to handle very large scales and keep fidelity with original input. To solve these problems, we propose an efficient high-resolution hallucination network for very large scaling factors with efficient network structure and feature transferring. To transfer more detailed textures, we design a wavelet texture loss, which helps to enhance more high-frequency components. At the same time, to reduce the smoothing effect brought by the image reconstruction loss, we further relax the reconstruction constraint with a degradation loss which ensures the consistency between downscaled super-resolution results and low-resolution inputs. We also collected a high-resolution (e.g., 4K resolution) painting dataset PaintHD by considering both physical size and image resolution. We demonstrate the effectiveness of our method with extensive experiments on PaintHD by comparing with SISR and Ref-SR state-of-the-art methods.
Anchor-free Small-scale Multispectral Pedestrian Detection
Aug 20, 2020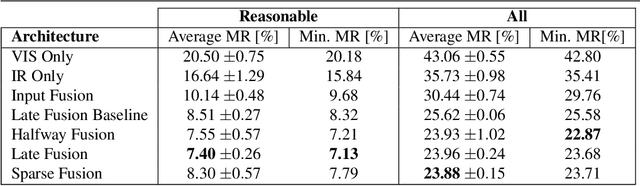

Multispectral images consisting of aligned visual-optical (VIS) and thermal infrared (IR) image pairs are well-suited for practical applications like autonomous driving or visual surveillance. Such data can be used to increase the performance of pedestrian detection especially for weakly illuminated, small-scaled, or partially occluded instances. The current state-of-the-art is based on variants of Faster R-CNN and thus passes through two stages: a proposal generator network with handcrafted anchor boxes for object localization and a classification network for verifying the object category. In this paper we propose a method for effective and efficient multispectral fusion of the two modalities in an adapted single-stage anchor-free base architecture. We aim at learning pedestrian representations based on object center and scale rather than direct bounding box predictions. In this way, we can both simplify the network architecture and achieve higher detection performance, especially for pedestrians under occlusion or at low object resolution. In addition, we provide a study on well-suited multispectral data augmentation techniques that improve the commonly used augmentations. The results show our method's effectiveness in detecting small-scaled pedestrians. We achieve 5.68% log-average miss rate in comparison to the best current state-of-the-art of 7.49% (25% improvement) on the challenging KAIST Multispectral Pedestrian Detection Benchmark. Code: https://github.com/HensoldtOptronicsCV/MultispectralPedestrianDetection
COVID-19 Infection Map Generation and Detection from Chest X-Ray Images
Sep 26, 2020



Computer-aided diagnosis has become a necessity for accurate and immediate coronavirus disease 2019 (COVID-19) detection to aid treatment and prevent the spread of the virus. Compared to other diagnosis methodologies, chest X-ray (CXR) imaging is an advantageous tool since it is fast, low-cost, and easily accessible. Thus, CXR has a great potential not only to help diagnose COVID-19 but also to track the progression of the disease. Numerous studies have proposed to use Deep Learning techniques for COVID-19 diagnosis. However, they have used very limited CXR image repositories for evaluation with a small number, a few hundreds, of COVID-19 samples. Moreover, these methods can neither localize nor grade the severity of COVID-19 infection. For this purpose, recent studies proposed to explore the activation maps of deep networks. However, they remain inaccurate for localizing the actual infestation making them unreliable for clinical use. This study proposes a novel method for the joint localization, severity grading, and detection of COVID-19 from CXR images by generating the so-called infection maps that can accurately localize and grade the severity of COVID-19 infection. To accomplish this, we have compiled the largest COVID-19 dataset up to date with 2951 COVID-19 CXR images, where the annotation of the ground-truth segmentation masks is performed on CXRs by a novel collaborative expert human-machine approach. Furthermore, we publicly release the first CXR dataset with the ground-truth segmentation masks of the COVID-19 infected regions. A detailed set of experiments show that state-of-the-art segmentation networks can learn to localize COVID-19 infection with an F1-score of 85.81%, that is significantly superior to the activation maps created by the previous methods. Finally, the proposed approach achieved a COVID-19 detection performance with 98.37% sensitivity and 99.16% specificity.
Switchblade -- a Neural Network for Hard 2D Tasks
Jun 29, 2020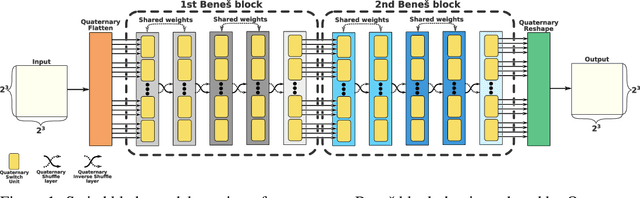

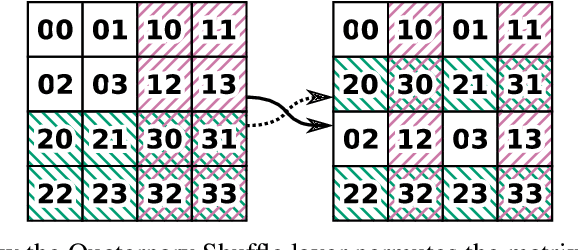
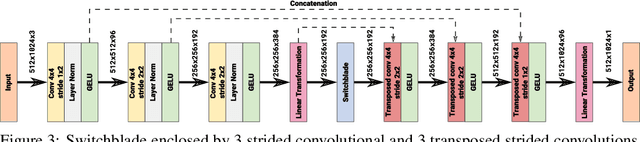
Convolutional neural networks have become the main tools for processing two-dimensional data. They work well for images, yet convolutions have a limited receptive field that prevents its applications to more complex 2D tasks. We propose a new neural network model, named Switchblade, that can efficiently exploit long-range dependencies in 2D data and solve much more challenging tasks. It has close-to-optimal $\mathcal{O}(n^2 \log{n})$ complexity for processing $n \times n$ data matrix. Besides the common image classification and segmentation, we consider a diverse set of algorithmic tasks on matrices and graphs. Switchblade can infer highly complex matrix squaring and graph triangle finding algorithms purely from input-output examples. We show that our model is likewise suitable for logical reasoning tasks -- it attains perfect accuracy on Sudoku puzzle solving. Additionally, we introduce a new dataset for predicting the checkmating move in chess on which our model achieves 72.5% accuracy.