 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenefiting Deep Latent Variable Models via Learning the Prior and Removing Latent Regularization
Jul 16, 2020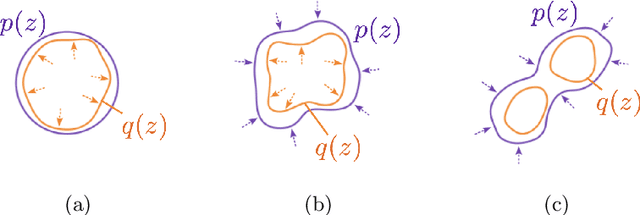
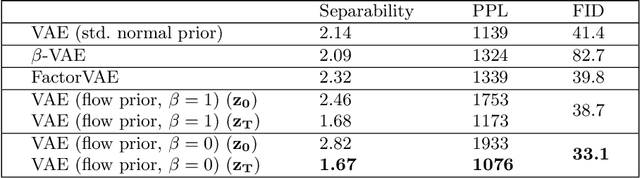
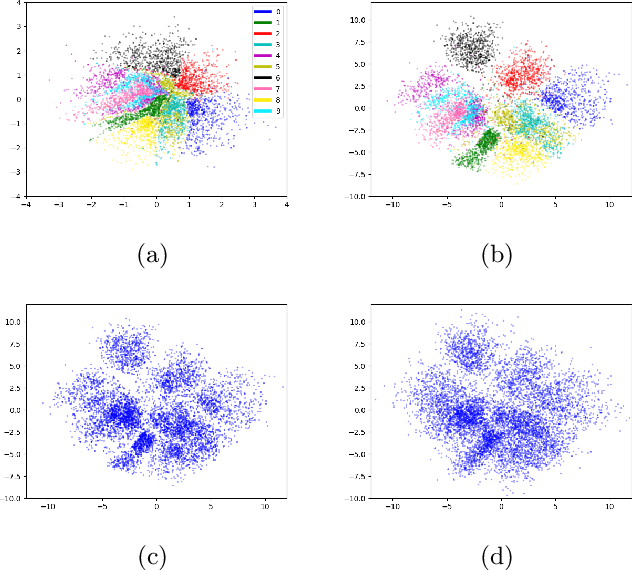

There exist many forms of deep latent variable models, such as the variational autoencoder and adversarial autoencoder. Regardless of the specific class of model, there exists an implicit consensus that the latent distribution should be regularized towards the prior, even in the case where the prior distribution is learned. Upon investigating the effect of latent regularization on image generation our results indicate that in the case where a sufficiently expressive prior is learned, latent regularization is not necessary and may in fact be harmful insofar as image quality is concerned. We additionally investigate the benefit of learned priors on two common problems in computer vision: latent variable disentanglement, and diversity in image-to-image translation.
Variational Autoencoders with Normalizing Flow Decoders
Apr 12, 2020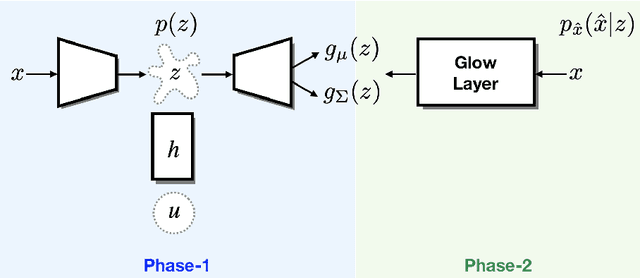
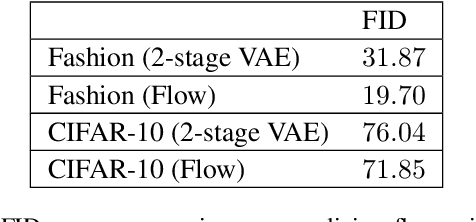

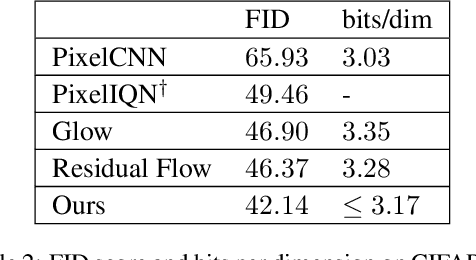
Recently proposed normalizing flow models such as Glow have been shown to be able to generate high quality, high dimensional images with relatively fast sampling speed. Due to their inherently restrictive architecture, however, it is necessary that they are excessively deep in order to train effectively. In this paper we propose to combine Glow with an underlying variational autoencoder in order to counteract this issue. We demonstrate that our proposed model is competitive with Glow in terms of image quality and test likelihood while requiring far less time for training.