 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Self-taught Learning for Remote Sensing Image Classification
Dec 19, 2017
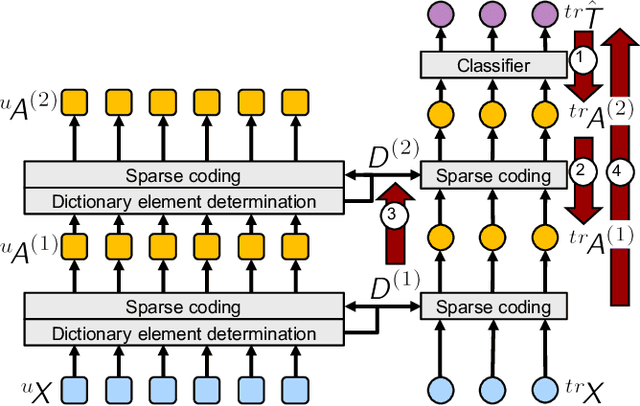
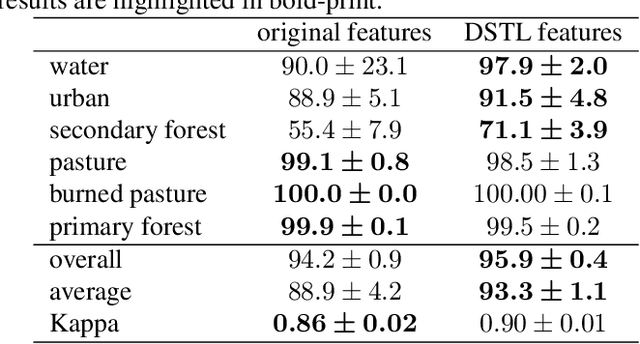


This paper addresses the land cover classification task for remote sensing images by deep self-taught learning. Our self-taught learning approach learns suitable feature representations of the input data using sparse representation and undercomplete dictionary learning. We propose a deep learning framework which extracts representations in multiple layers and use the output of the deepest layer as input to a classification algorithm. We evaluate our approach using a multispectral Landsat 5 TM image of a study area in the North of Novo Progresso (South America) and the Zurich Summer Data Set provided by the University of Zurich. Experiments indicate that features learned by a deep self-taught learning framework can be used for classification and improve the results compared to classification results using the original feature representation.
* This is a corrected version of the final paper published in the proceedings
Rethinking Softmax with Cross-Entropy: Neural Network Classifier as Mutual Information Estimator
Jan 13, 2020
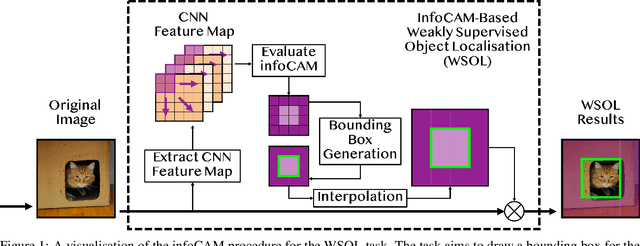
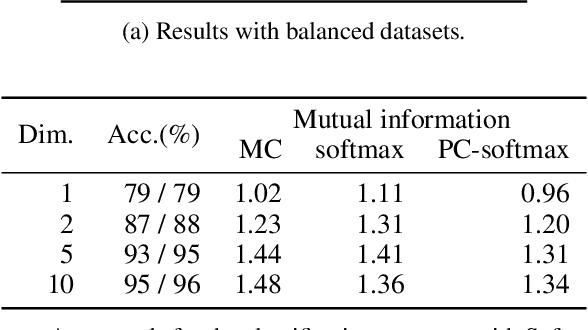

Mutual information is widely applied to learn latent representations of observations, whilst its implication in classification neural networks remain to be better explained. In this paper, we show that optimising the parameters of classification neural networks with softmax cross-entropy is equivalent to maximising the mutual information between inputs and labels under the balanced data assumption. Through the experiments on synthetic and real datasets, we show that softmax cross-entropy can estimate mutual information approximately. When applied to image classification, this relation helps approximate the point-wise mutual information between an input image and a label without modifying the network structure. In this end, we propose infoCAM, informative class activation map, which highlights regions of the input image that are the most relevant to a given label based on differences in information. The activation map helps localise the target object in an image. Through the experiments on the semi-supervised object localisation task with two real-world datasets, we evaluate the effectiveness of the information-theoretic approach.
Listen to the Image
Apr 19, 2019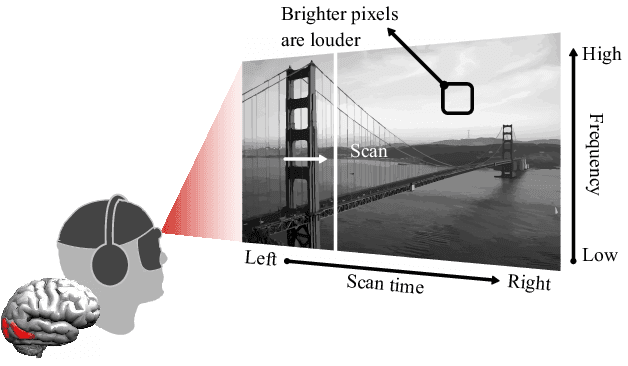
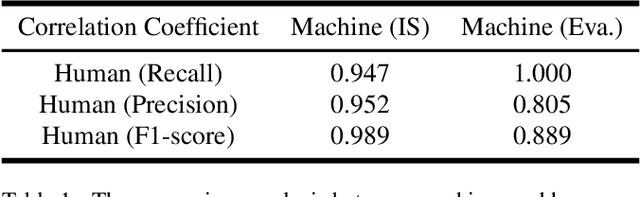
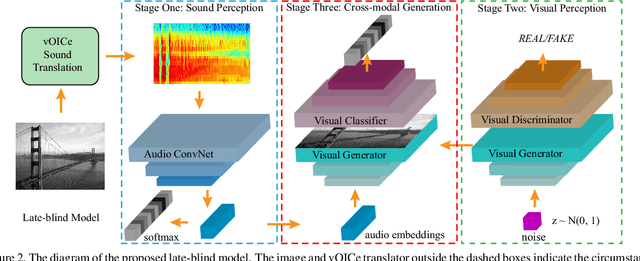

Visual-to-auditory sensory substitution devices can assist the blind in sensing the visual environment by translating the visual information into a sound pattern. To improve the translation quality, the task performances of the blind are usually employed to evaluate different encoding schemes. In contrast to the toilsome human-based assessment, we argue that machine model can be also developed for evaluation, and more efficient. To this end, we firstly propose two distinct cross-modal perception model w.r.t. the late-blind and congenitally-blind cases, which aim to generate concrete visual contents based on the translated sound. To validate the functionality of proposed models, two novel optimization strategies w.r.t. the primary encoding scheme are presented. Further, we conduct sets of human-based experiments to evaluate and compare them with the conducted machine-based assessments in the cross-modal generation task. Their highly consistent results w.r.t. different encoding schemes indicate that using machine model to accelerate optimization evaluation and reduce experimental cost is feasible to some extent, which could dramatically promote the upgrading of encoding scheme then help the blind to improve their visual perception ability.
Learning Image Relations with Contrast Association Networks
May 16, 2017

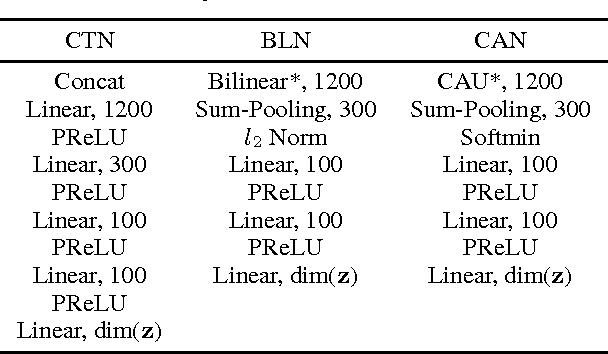
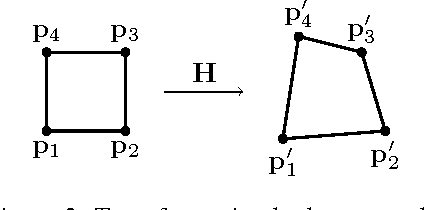
Inferring the relations between two images is an important class of tasks in computer vision. Examples of such tasks include computing optical flow and stereo disparity. We treat the relation inference tasks as a machine learning problem and tackle it with neural networks. A key to the problem is learning a representation of relations. We propose a new neural network module, contrast association unit (CAU), which explicitly models the relations between two sets of input variables. Due to the non-negativity of the weights in CAU, we adopt a multiplicative update algorithm for learning these weights. Experiments show that neural networks with CAUs are more effective in learning five fundamental image transformations than conventional neural networks.
Pose Proposal Critic: Robust Pose Refinement by Learning Reprojection Errors
May 13, 2020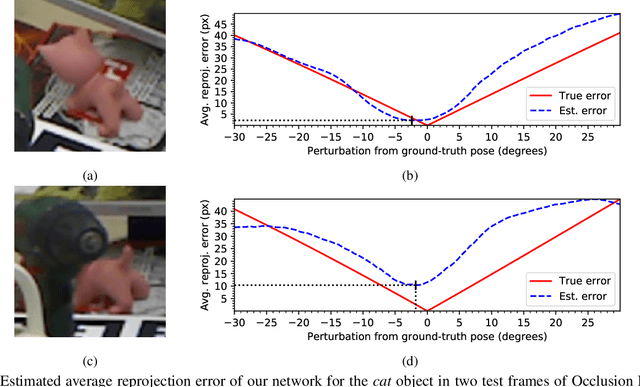
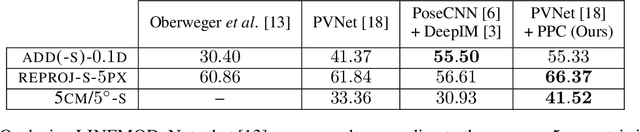
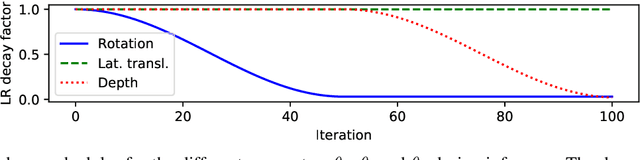

In recent years, considerable progress has been made for the task of rigid object pose estimation from a single RGB-image, but achieving robustness to partial occlusions remains a challenging problem. Pose refinement via rendering has shown promise in order to achieve improved results, in particular, when data is scarce. In this paper we focus our attention on pose refinement, and show how to push the state-of-the-art further in the case of partial occlusions. The proposed pose refinement method leverages on a simplified learning task, where a CNN is trained to estimate the reprojection error between an observed and a rendered image. We experiment by training on purely synthetic data as well as a mixture of synthetic and real data. Current state-of-the-art results are outperformed for two out of three metrics on the Occlusion LINEMOD benchmark, while performing on-par for the final metric.
Semi-supervised lung nodule retrieval
May 04, 2020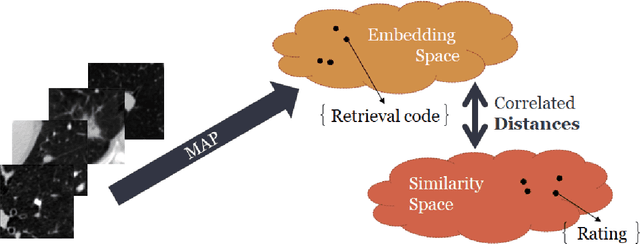
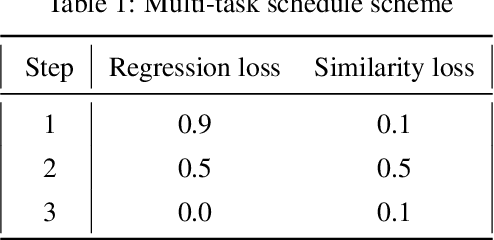
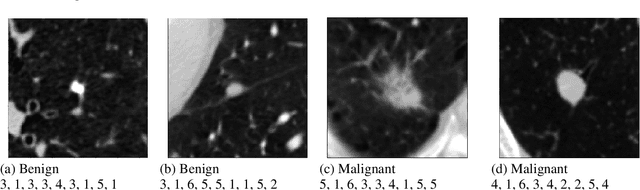
Content based image retrieval (CBIR) provides the clinician with visual information that can support, and hopefully improve, his or her decision making process. Given an input query image, a CBIR system provides as its output a set of images, ranked by similarity to the query image. Retrieved images may come with relevant information, such as biopsy-based malignancy labeling, or categorization. Ground truth on similarity between dataset elements (e.g. between nodules) is not readily available, thus greatly challenging machine learning methods. Such annotations are particularly difficult to obtain, due to the subjective nature of the task, with high inter-observer variability requiring multiple expert annotators. Consequently, past approaches have focused on manual feature extraction, while current approaches use auxiliary tasks, such as a binary classification task (e.g. malignancy), for which ground-true is more readily accessible. However, in a previous study, we have shown that binary auxiliary tasks are inferior to the usage of a rough similarity estimate that are derived from data annotations. The current study suggests a semi-supervised approach that involves two steps: 1) Automatic annotation of a given partially labeled dataset; 2) Learning a semantic similarity metric space based on the predicated annotations. The proposed system is demonstrated in lung nodule retrieval using the LIDC dataset, and shows that it is feasible to learn embedding from predicted ratings. The semi-supervised approach has demonstrated a significantly higher discriminative ability than the fully-unsupervised reference.
Restrained Generative Adversarial Network against Overfitting in Numeric Data Augmentation
Oct 26, 2020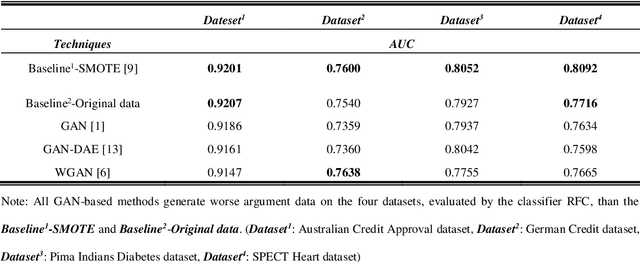
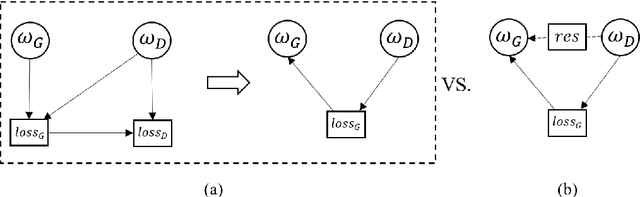
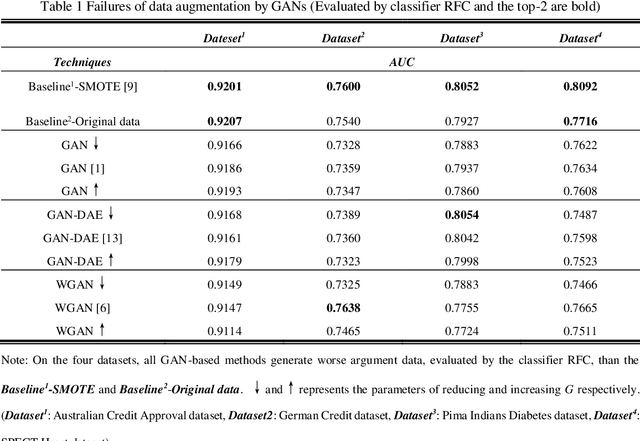

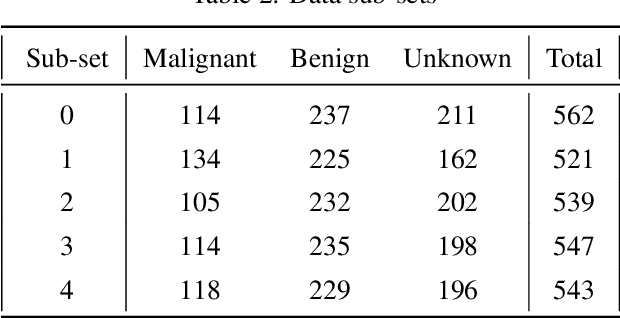
In recent studies, Generative Adversarial Network (GAN) is one of the popular schemes to augment the image dataset. However, in our study we find the generator G in the GAN fails to generate numerical data in lower-dimensional spaces, and we address overfitting in the generation. By analyzing the Directed Graphical Model (DGM), we propose a theoretical restraint, independence on the loss function, to suppress the overfitting. Practically, as the Statically Restrained GAN (SRGAN) and Dynamically Restrained GAN (DRGAN), two frameworks are proposed to employ the theoretical restraint to the network structure. In the static structure, we predefined a pair of particular network topologies of G and D as the restraint, and quantify such restraint by the interpretable metric Similarity of the Restraint (SR). While for DRGAN we design an adjustable dropout module for the restraint function. In the widely carried out 20 group experiments, on four public numerical class imbalance datasets and five classifiers, the static and dynamic methods together produce the best augmentation results of 19 from 20; and both two methods simultaneously generate 14 of 20 groups of the top-2 best, proving the effectiveness and feasibility of the theoretical restraints.
3D Photography using Context-aware Layered Depth Inpainting
Apr 09, 2020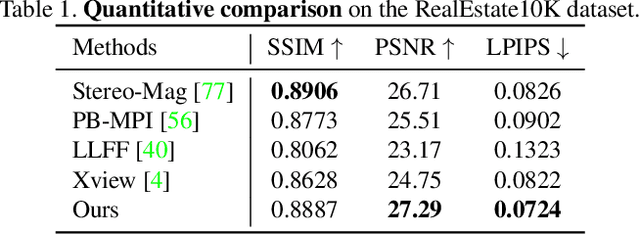
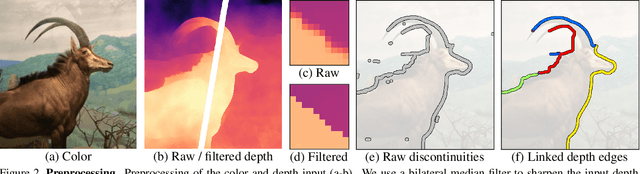
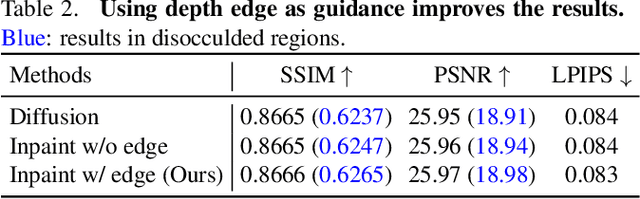

We propose a method for converting a single RGB-D input image into a 3D photo - a multi-layer representation for novel view synthesis that contains hallucinated color and depth structures in regions occluded in the original view. We use a Layered Depth Image with explicit pixel connectivity as underlying representation, and present a learning-based inpainting model that synthesizes new local color-and-depth content into the occluded region in a spatial context-aware manner. The resulting 3D photos can be efficiently rendered with motion parallax using standard graphics engines. We validate the effectiveness of our method on a wide range of challenging everyday scenes and show fewer artifacts compared with the state of the arts.
Deep Convolutional Neural Networks: A survey of the foundations, selected improvements, and some current applications
Nov 25, 2020
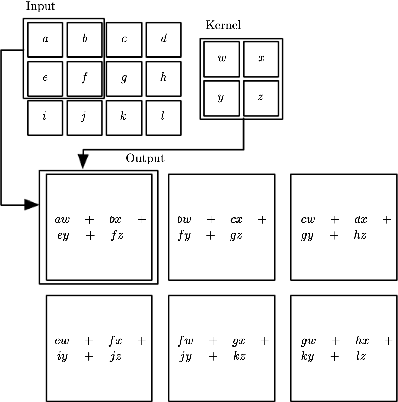
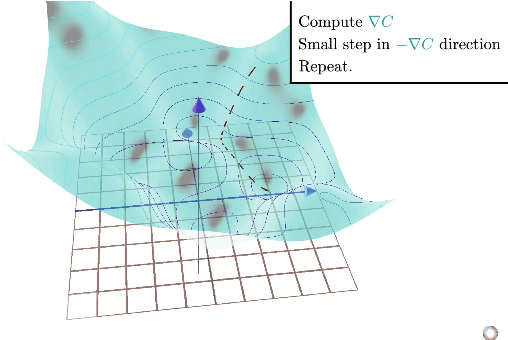
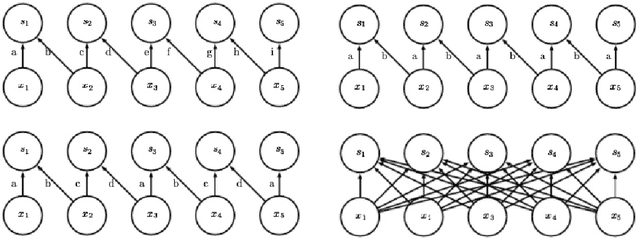
Within the world of machine learning there exists a wide range of different methods with respective advantages and applications. This paper seeks to present and discuss one such method, namely Convolutional Neural Networks (CNNs). CNNs are deep neural networks that use a special linear operation called convolution. This operation represents a key and distinctive element of CNNs, and will therefore be the focus of this method paper. The discussion starts with the theoretical foundations that underlie convolutions and CNNs. Then, the discussion proceeds to discuss some improvements and augmentations that can be made to adapt the method to estimate a wider set of function classes. The paper mainly investigates two ways of improving the method: by using locally connected layers, which can make the network less invariant to translation, and tiled convolution, which allows for the learning of more complex invariances than standard convolution. Furthermore, the use of the Fast Fourier Transform can improve the computational efficiency of convolution. Subsequently, this paper discusses two applications of convolution that have proven to be very effective in practice. First, the YOLO architecture is a state of the art neural network for image object classification, which accurately predicts bounding boxes around objects in images. Second, tumor detection in mammography may be performed using CNNs, accomplishing 7.2% higher specificity than actual doctors with only .3% less sensitivity. Finally, the invention of technology that outperforms humans in different fields also raises certain ethical and regulatory questions that are briefly discussed.
Greenery Segmentation In Urban Images By Deep Learning
Dec 12, 2019
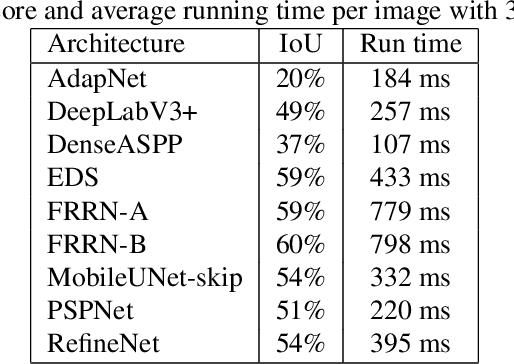
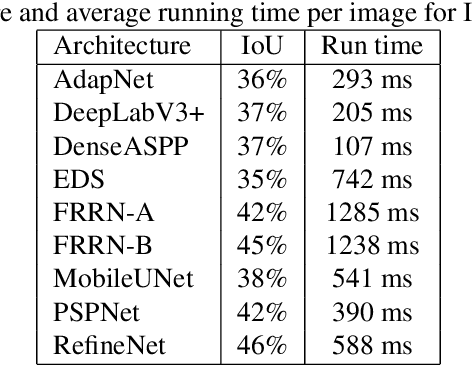

Vegetation is a relevant feature in the urban scenery and its awareness can be measured in an image by the Green View Index (GVI). Previous approaches to estimate the GVI were based upon heuristics image processing approaches and recently by deep learning networks (DLN). By leveraging some recent DLN architectures tuned to the image segmentation problem and exploiting a weighting strategy in the loss function (LF) we improved previously reported results in similar datasets.