 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
BiFNet: Bidirectional Fusion Network for Road Segmentation
Apr 18, 2020

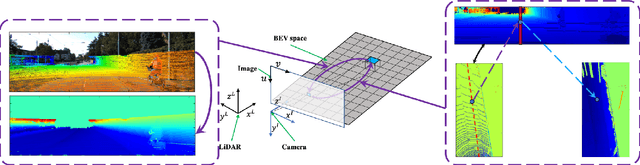
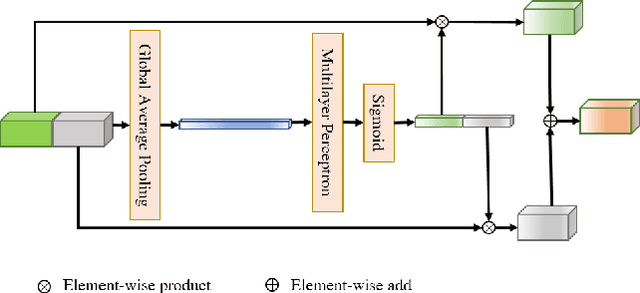
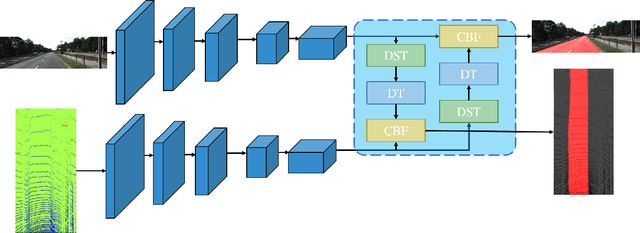
Multi-sensor fusion-based road segmentation plays an important role in the intelligent driving system since it provides a drivable area. The existing mainstream fusion method is mainly to feature fusion in the image space domain which causes the perspective compression of the road and damages the performance of the distant road. Considering the bird's eye views(BEV) of the LiDAR remains the space structure in horizontal plane, this paper proposes a bidirectional fusion network(BiFNet) to fuse the image and BEV of the point cloud. The network consists of two modules: 1) Dense space transformation module, which solves the mutual conversion between camera image space and BEV space. 2) Context-based feature fusion module, which fuses the different sensors information based on the scenes from corresponding features.This method has achieved competitive results on KITTI dataset.
Highway Driving Dataset for Semantic Video Segmentation
Nov 02, 2020
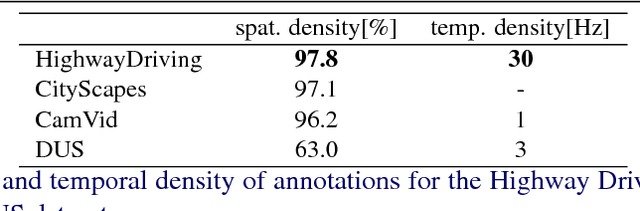
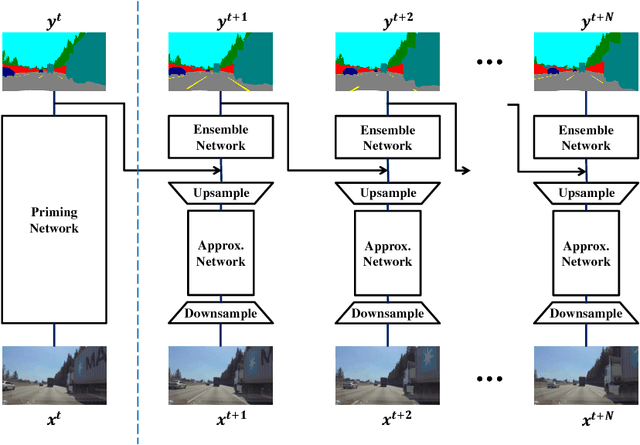
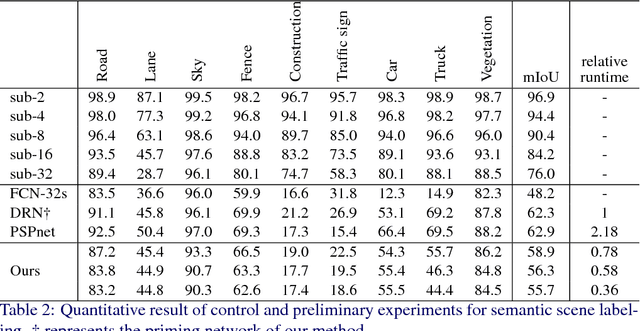
Scene understanding is an essential technique in semantic segmentation. Although there exist several datasets that can be used for semantic segmentation, they are mainly focused on semantic image segmentation with large deep neural networks. Therefore, these networks are not useful for real time applications, especially in autonomous driving systems. In order to solve this problem, we make two contributions to semantic segmentation task. The first contribution is that we introduce the semantic video dataset, the Highway Driving dataset, which is a densely annotated benchmark for a semantic video segmentation task. The Highway Driving dataset consists of 20 video sequences having a 30Hz frame rate, and every frame is densely annotated. Secondly, we propose a baseline algorithm that utilizes a temporal correlation. Together with our attempt to analyze the temporal correlation, we expect the Highway Driving dataset to encourage research on semantic video segmentation.
Representation Learning with Video Deep InfoMax
Jul 27, 2020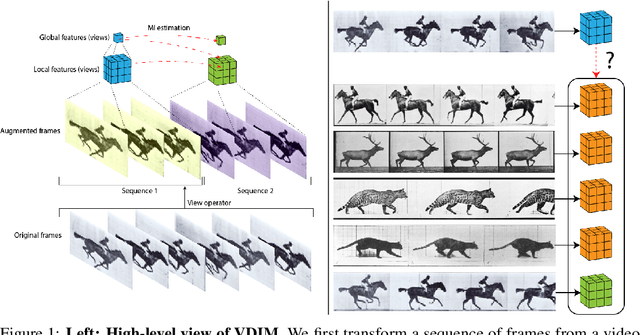
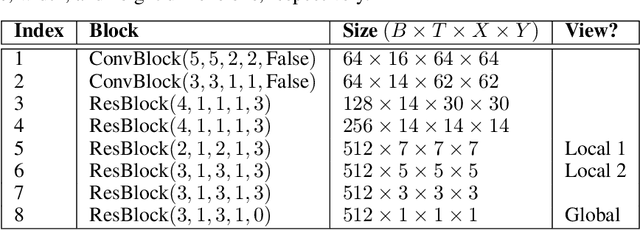
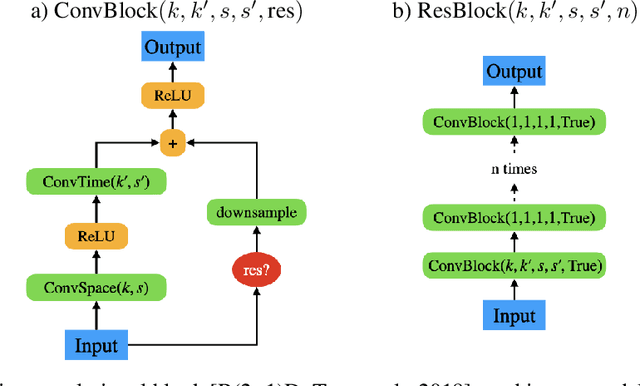
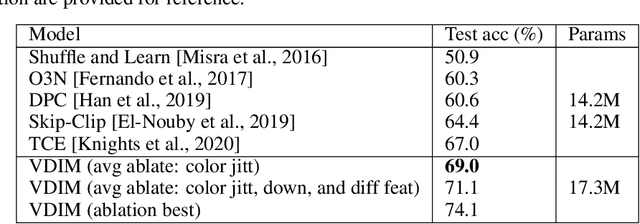
Self-supervised learning has made unsupervised pretraining relevant again for difficult computer vision tasks. The most effective self-supervised methods involve prediction tasks based on features extracted from diverse views of the data. DeepInfoMax (DIM) is a self-supervised method which leverages the internal structure of deep networks to construct such views, forming prediction tasks between local features which depend on small patches in an image and global features which depend on the whole image. In this paper, we extend DIM to the video domain by leveraging similar structure in spatio-temporal networks, producing a method we call Video Deep InfoMax(VDIM). We find that drawing views from both natural-rate sequences and temporally-downsampled sequences yields results on Kinetics-pretrained action recognition tasks which match or outperform prior state-of-the-art methods that use more costly large-time-scale transformer models. We also examine the effects of data augmentation and fine-tuning methods, accomplishingSoTA by a large margin when training only on the UCF-101 dataset.
Kernel Anomalous Change Detection for Remote Sensing Imagery
Dec 09, 2020
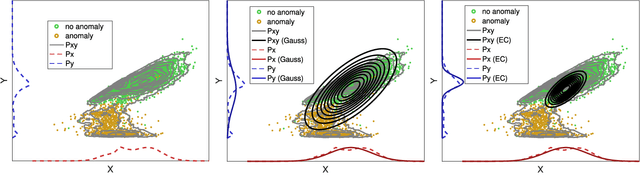
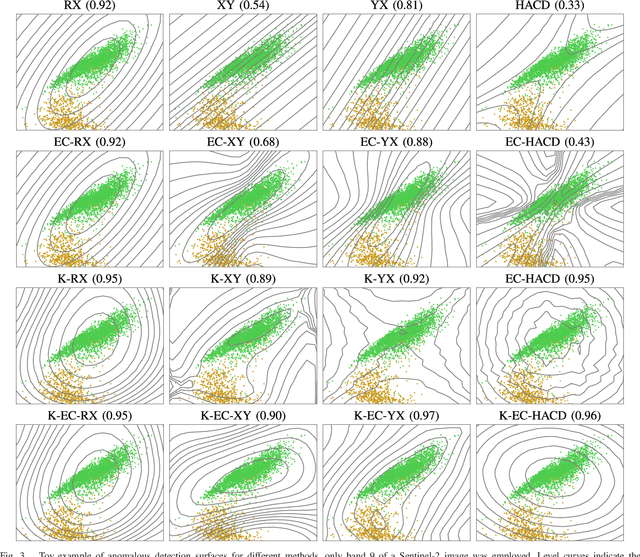

Anomalous change detection (ACD) is an important problem in remote sensing image processing. Detecting not only pervasive but also anomalous or extreme changes has many applications for which methodologies are available. This paper introduces a nonlinear extension of a full family of anomalous change detectors. In particular, we focus on algorithms that utilize Gaussian and elliptically contoured (EC) distribution and extend them to their nonlinear counterparts based on the theory of reproducing kernels' Hilbert space. We illustrate the performance of the kernel methods introduced in both pervasive and ACD problems with real and simulated changes in multispectral and hyperspectral imagery with different resolutions (AVIRIS, Sentinel-2, WorldView-2, and Quickbird). A wide range of situations is studied in real examples, including droughts, wildfires, and urbanization. Excellent performance in terms of detection accuracy compared to linear formulations is achieved, resulting in improved detection accuracy and reduced false-alarm rates. Results also reveal that the EC assumption may be still valid in Hilbert spaces. We provide an implementation of the algorithms as well as a database of natural anomalous changes in real scenarios http://isp.uv.es/kacd.html.
A Survey on Assessing the Generalization Envelope of Deep Neural Networks at Inference Time for Image Classification
Aug 21, 2020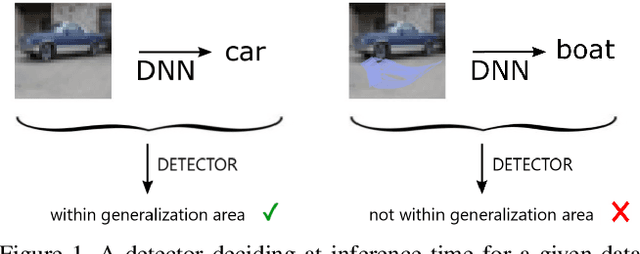

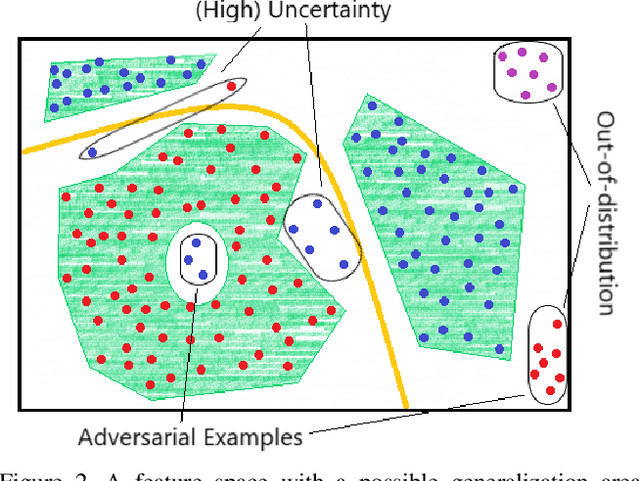
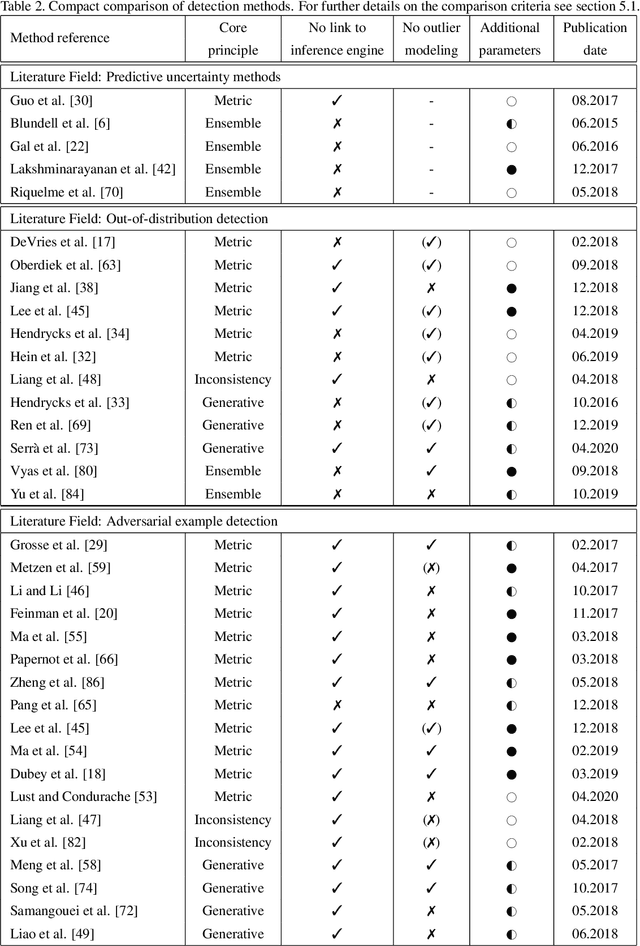
Deep Neural Networks (DNNs) achieve state-of-the-art performance on numerous problem set-ups. However, humans are not able to tell beforehand if a DNN receiving an input will deliver the desired output since their decision criteria are usually non-transparent. A DNN delivers the desired output if the input is within its generalization envelope. In this case, the information contained in the input sample is processed reasonably by the network. Since common DNNs fail to provide relevant information to assess the generalization envelope at inference time, additional methods or adaptations to the DNN have to be performed. Existing methods are evaluated using different set-ups respectively connected to three literature fields: predictive uncertainty, out-of-distribution detection and adversarial example detection. This survey connects those fields and gives an overview of the adaptations and methods that provide at inference time information if the current input is within the generalization area of a DNN.
Disrupting Deepfakes with an Adversarial Attack that Survives Training
Jun 17, 2020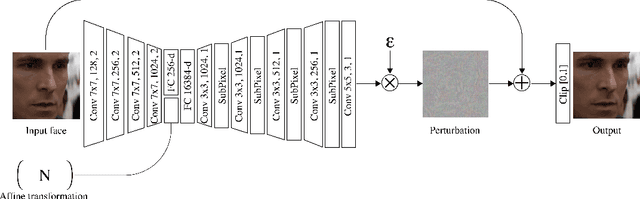



The rapid progress in generative models and autoencoders has given rise to effective video tampering techniques, used for generating deepfakes. Mitigation research is mostly focused on post-factum deepfake detection and not prevention. We complement these efforts by proposing a prevention technique against face-swapping autoencoders. Our technique consists of a novel training-resistant adversarial attack that can be applied to a video to disrupt face-swapping manipulations. Our attack introduces spatial-temporal distortions to the output of the face-swapping autoencoders, and it holds whether or not our adversarial images have been included in the training set of said autoencoders. To implement the attack, we construct a bilevel optimization problem, where we train a generator and a face-swapping model instance against each other. Specifically, we pair each input image with a target distortion, and feed them into a generator that produces an adversarial image. This image will exhibit the distortion when a face-swapping autoencoder is applied to it. We solve the optimization problem by training the generator and the face-swapping model simultaneously using an iterative process of alternating optimization. Finally, we validate our attack using a popular implementation of FaceSwap, and show that our attack transfers across different models and target faces. More broadly, these results demonstrate the existence of training-resistant adversarial attacks, potentially applicable to a wide range of domains.
Learning to Learn Parameterized Classification Networks for Scalable Input Images
Jul 13, 2020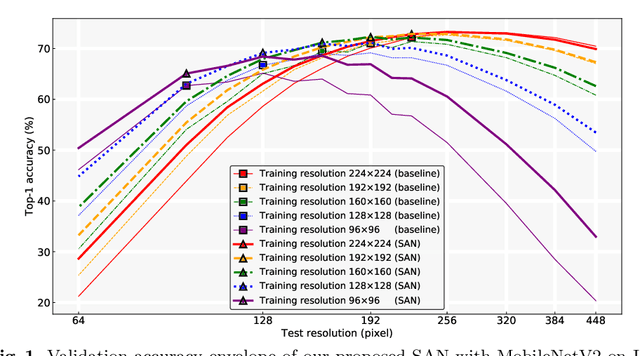
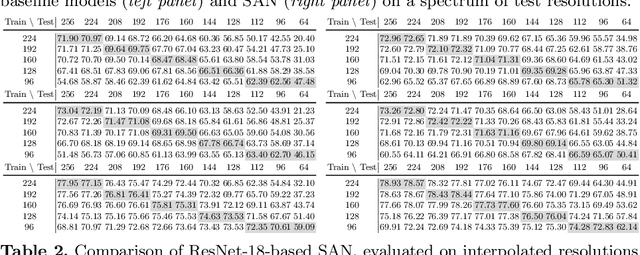
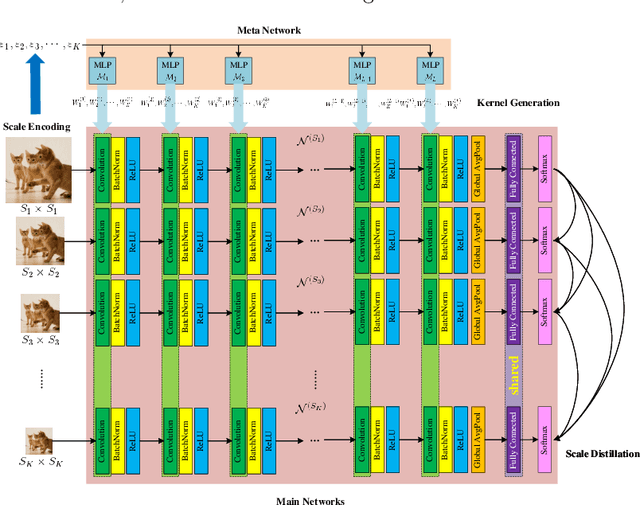

Convolutional Neural Networks (CNNs) do not have a predictable recognition behavior with respect to the input resolution change. This prevents the feasibility of deployment on different input image resolutions for a specific model. To achieve efficient and flexible image classification at runtime, we employ meta learners to generate convolutional weights of main networks for various input scales and maintain privatized Batch Normalization layers per scale. For improved training performance, we further utilize knowledge distillation on the fly over model predictions based on different input resolutions. The learned meta network could dynamically parameterize main networks to act on input images of arbitrary size with consistently better accuracy compared to individually trained models. Extensive experiments on the ImageNet demonstrate that our method achieves an improved accuracy-efficiency trade-off during the adaptive inference process. By switching executable input resolutions, our method could satisfy the requirement of fast adaption in different resource-constrained environments. Code and models are available at https://github.com/d-li14/SAN.
DeepWeeds: A Multiclass Weed Species Image Dataset for Deep Learning
Oct 09, 2018
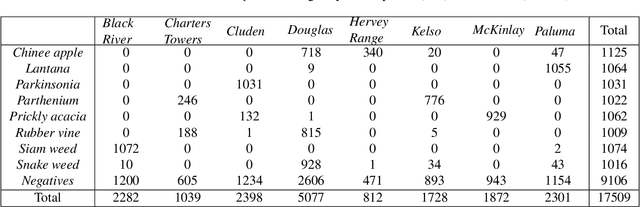

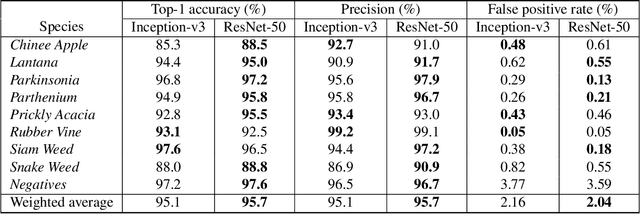
Robotic weed control has seen increased research in the past decade with its potential for boosting productivity in agriculture. Majority of works focus on developing robotics for arable croplands, ignoring the significant weed management problems facing rangeland stock farmers. Perhaps the greatest obstacle to widespread uptake of robotic weed control is the robust detection of weed species in their natural environment. The unparalleled successes of deep learning make it an ideal candidate for recognising various weed species in the highly complex Australian rangeland environment. This work contributes the first large, public, multiclass image dataset of weed species from the Australian rangelands; allowing for the development of robust detection methods to make robotic weed control viable. The DeepWeeds dataset consists of 17,509 labelled images of eight nationally significant weed species native to eight locations across northern Australia. This paper also presents a baseline for classification performance on the dataset using the benchmark deep learning models, Inception-v3 and ResNet-50. These models achieved an average classification performance of 87.9% and 90.5%, respectively. This strong result bodes well for future field implementation of robotic weed control methods in the Australian rangelands.
T-VSE: Transformer-Based Visual Semantic Embedding
May 17, 2020
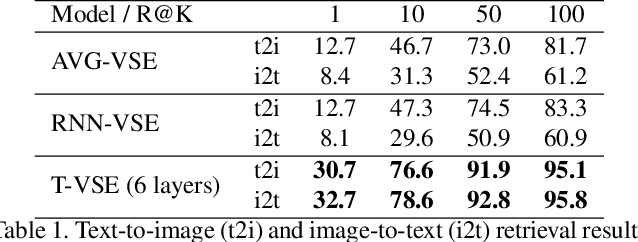
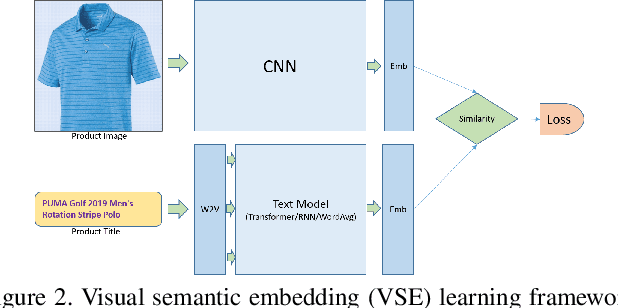
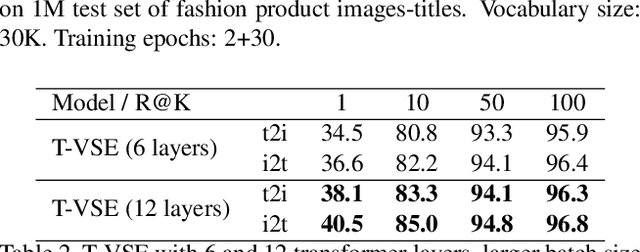
Transformer models have recently achieved impressive performance on NLP tasks, owing to new algorithms for self-supervised pre-training on very large text corpora. In contrast, recent literature suggests that simple average word models outperform more complicated language models, e.g., RNNs and Transformers, on cross-modal image/text search tasks on standard benchmarks, like MS COCO. In this paper, we show that dataset scale and training strategy are critical and demonstrate that transformer-based cross-modal embeddings outperform word average and RNN-based embeddings by a large margin, when trained on a large dataset of e-commerce product image-title pairs.
Deriving Visual Semantics from Spatial Context: An Adaptation of LSA and Word2Vec to generate Object and Scene Embeddings from Images
Sep 20, 2020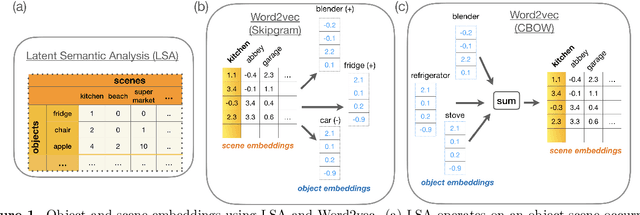
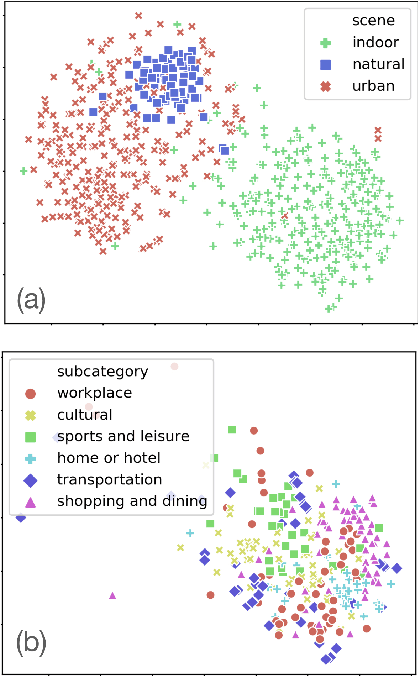
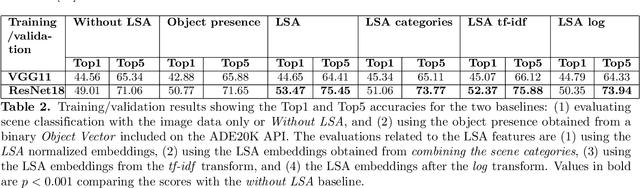

Embeddings are an important tool for the representation of word meaning. Their effectiveness rests on the distributional hypothesis: words that occur in the same context carry similar semantic information. Here, we adapt this approach to index visual semantics in images of scenes. To this end, we formulate a distributional hypothesis for objects and scenes: Scenes that contain the same objects (object context) are semantically related. Similarly, objects that appear in the same spatial context (within a scene or subregions of a scene) are semantically related. We develop two approaches for learning object and scene embeddings from annotated images. In the first approach, we adapt LSA and Word2vec's Skipgram and CBOW models to generate two sets of embeddings from object co-occurrences in whole images, one for objects and one for scenes. The representational space spanned by these embeddings suggests that the distributional hypothesis holds for images. In an initial application of this approach, we show that our image-based embeddings improve scene classification models such as ResNet18 and VGG-11 (3.72\% improvement on Top5 accuracy, 4.56\% improvement on Top1 accuracy). In the second approach, rather than analyzing whole images of scenes, we focus on co-occurrences of objects within subregions of an image. We illustrate that this method yields a sensible hierarchical decomposition of a scene into collections of semantically related objects. Overall, these results suggest that object and scene embeddings from object co-occurrences and spatial context yield semantically meaningful representations as well as computational improvements for downstream applications such as scene classification.