Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT-VSE: Transformer-Based Visual Semantic Embedding
Paper and Code
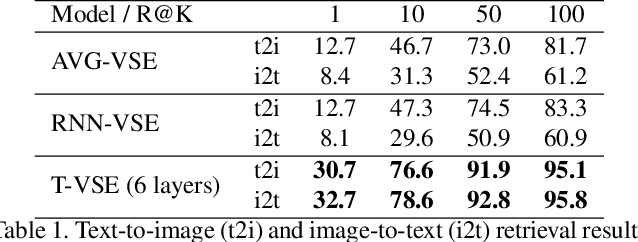
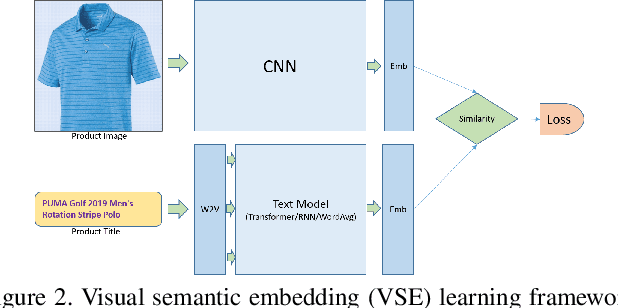
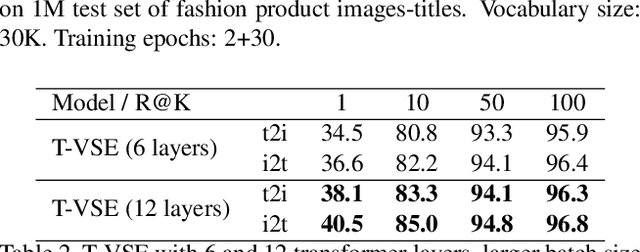
Transformer models have recently achieved impressive performance on NLP tasks, owing to new algorithms for self-supervised pre-training on very large text corpora. In contrast, recent literature suggests that simple average word models outperform more complicated language models, e.g., RNNs and Transformers, on cross-modal image/text search tasks on standard benchmarks, like MS COCO. In this paper, we show that dataset scale and training strategy are critical and demonstrate that transformer-based cross-modal embeddings outperform word average and RNN-based embeddings by a large margin, when trained on a large dataset of e-commerce product image-title pairs.
* To appear: CVPR 2020 Workshop on Computer Vision for Fashion, Art and
Design (CVFAD 2020)
View paper on